
Database NoSQL: Impala
Pubblicato: 2023-03-03NoSQL è un termine utilizzato per descrivere un database che non utilizza la tradizionale struttura di database relazionale. Invece, i database NoSQL sono spesso progettati per fornire una soluzione più semplice e scalabile.
Impala è un database NoSQL progettato per fornire una soluzione rapida e scalabile per la gestione di set di dati di grandi dimensioni. Impala si basa sul modello di dati di Google Bigtable e utilizza un formato di archiviazione a colonne. Impala è disponibile come progetto open source ed è supportato da Cloudera.
Apache Impala è un motore di query SQL open source installato su un cluster Hadoop ed esegue MPP (Massive Parallel Processing) per i dati archiviati nel sistema. Originariamente sviluppato nel 2012, il progetto open source è noto come "Microsoft Formula 1".
La piattaforma Impala consente agli utenti di eseguire query SQL a bassa latenza sui dati Hadoop archiviati in HDFS e Apache HBase senza dover spostare o trasformare i dati.
È basato su Impala Sql?
Impala è un motore di query basato su SQL che viene eseguito su Apache Hadoop. Consente agli utenti di interrogare i dati archiviati in HDFS e HBase utilizzando SQL. Impala offre prestazioni elevate e bassa latenza rispetto ad altri motori di query Hadoop come Hive e Pig.
Il database MPP analitico di Impala fornisce il tempo di analisi più rapido del settore. È integrato con CDH ed è accessibile tramite Cloudera Enterprise. I database MPP per Apache Hadoop, come Impala, utilizzano HDFS per fornire un time-to-insight più rapido.
Impala è un database
È un database che credo.
Impala è uno strumento Etl?
Impala non è uno strumento ETL, è un motore di query SQL che può essere utilizzato per eseguire query SQL dopo che i dati sono stati puliti attraverso un processo.
A cosa serve Apache Impala?
Utilizzando query simili a SQL, possiamo leggere i dati da una varietà di fonti utilizzando Impala. Apache Impala offre prestazioni migliori rispetto a Hive e altri motori SQL quando si tratta di accedere ai dati archiviati nel file system distribuito Hadoop . Utilizziamo Impala per archiviare i dati in Hadoop HBase, HDFS e Amazon S3.
19 aziende che utilizzano Apache Impala nei loro stack tecnologici
Apache Impala è un popolare motore di elaborazione dati per una varietà di grandi aziende. Secondo i rapporti, 19 aziende tecnologiche, tra cui Stripe, Agoda e Expedia.com, utilizzano Apache Impala. La piattaforma Impala è flessibile ed efficiente, in grado di gestire grandi set di dati in modo rapido ed efficace. L'uso diffuso di questo strumento dimostra quanto sia utile e quanto sia utile nell'elaborazione dei dati.
Quali sono le differenze tra Sql Hive e Impala?
L'obiettivo di Hive è gestire query a esecuzione prolungata che richiedono più trasformazioni e join. A causa della sua bassa latenza e della capacità di gestire query più piccole, il motore di elaborazione delle query Impala è ideale per l'elaborazione interattiva. Spark supporta sia query a breve che a lungo termine, oltre a query a breve e lungo termine.
Hive è più adatto per processi batch a esecuzione prolungata
Lo scopo principale degli strumenti non è elaborare i batch. Hive è più adatto al lavoro in batch a lungo termine rispetto a Impulsa, che può gestire set di dati più piccoli.
Impala è un database
Un impala è un database che memorizza i dati in un formato a colonne. È progettato per essere scalabile e per fornire prestazioni elevate per set di dati di grandi dimensioni.
Nella versione iniziale di Impala, sono supportati i seguenti tipi di dati della colonna principale: STRING, VARCHAR, VARCHar2, INT e FLOAT anziché numero e non è supportato alcun tipo BLOB. Impala SQL-92 include alcuni miglioramenti agli standard degli standard SQL, ma non li incorpora tutti. Quando i dati sono troppo grandi per essere prodotti, manipolati e analizzati su un singolo server, Impala offre prestazioni migliori rispetto ad altri data warehouse ed è maggiormente abilitato alla scalabilità. Non è necessario rimuovere la posizione originale dei file di dati durante il caricamento di Impala perché è leggero. Il primo passo per conoscere i test delle prestazioni, la scalabilità e le configurazioni dei cluster multi-nodo è in genere raccogliere grandi quantità di dati. Cloudera Impala è ottimizzato per il caricamento dei dati e la lettura in blocco in set di dati di grandi dimensioni, consentendoti di fare di più con meno. La dimensione del blocco multimegabyte di HDFS consente a Impala di elaborare enormi quantità di dati in parallelo su più server in rete.
Invece di pianificare indici normalizzati e il tempo e lo sforzo necessari per crearli, lo farai in Impala. Il motore di query di Impala è in grado di gestire grandi quantità di dati provenienti dai data warehouse. Analizza un cluster e distribuisce le attività tra i nodi per ridurre la quantità di risorse consumate. Il partizionamento di un data warehouse è un concetto familiare in Impala. Il partizionamento riduce l'I/O del disco e aumenta la scalabilità delle query in Impala. I file di dati sono richiesti poiché non sarai in grado di accedere a nessuna tabella integrata in Impala. INSERT è una delle opzioni disponibili.
Per costruire due tavoli giocattolo, usa una dichiarazione di valore. Se hai utilizzato software orientato ai batch, puoi provarlo. È possibile incorporare la tecnologia SQL-on-hadoop nella configurazione di Apache Hive. Le tabelle Hive in Impala non vengono caricate o convertite in modo dispendioso in termini di tempo.
Impala: un potente strumento di gestione dei dati per Hadoop
La sintassi SQL è familiare agli utenti di Impala, che possono eseguire query sui dati archiviati in HDFS e Apache HBase. In questo modo è possibile utilizzare Hadoop e Impulsa al posto dei tradizionali database relazionali . Inoltre, è un potente strumento di gestione dei dati grazie alle sue funzionalità. Inoltre, le sue capacità per set di dati di grandi dimensioni sono impressionanti e può gestirle con grande facilità.
Impala nei Big Data
Impala è un motore di query SQL MPP open source che funziona su Apache Hadoop. Fornisce query SQL rapide e interattive sui dati archiviati in HDFS e HBase. Impala è progettato per migliorare le prestazioni di Apache Hadoop fornendo un'interfaccia SQL rapida e interattiva per i dati archiviati in HDFS e HBase.
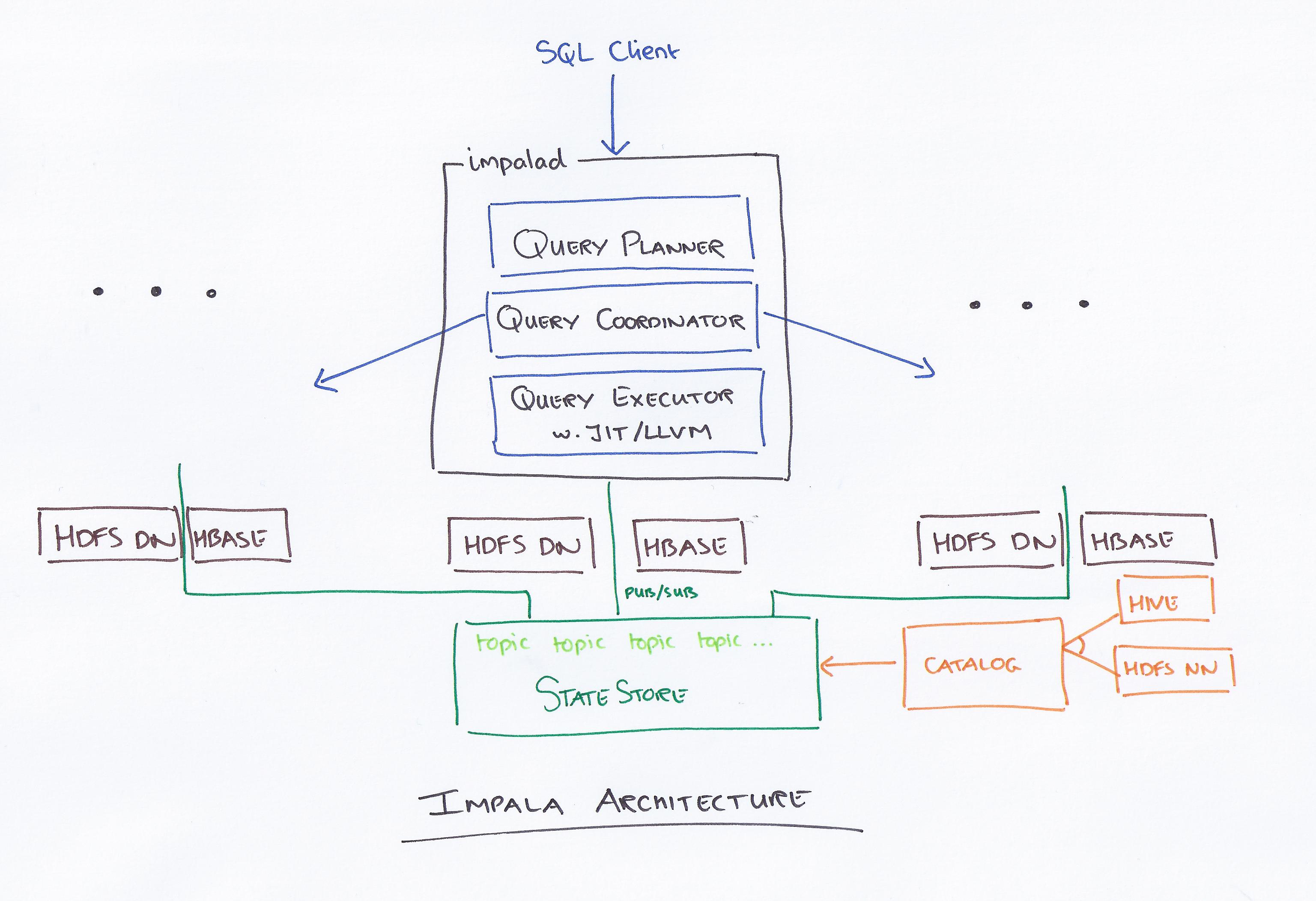
Impala, guidato da Cloudera, è un nuovo sistema di query. Hadoop ha HDFS e HBase, quindi può interrogare i big data a livello di PB archiviati lì. Questa tecnologia si basa su hive e memoria per il calcolo, oltre a tenere conto del data warehouse, e fornisce l'elaborazione batch in tempo reale e l'elaborazione simultanea multipla. Un client invia una richiesta di query a un nodo all'interno di una rete impalad, dove viene restituito un ID query per le successive operazioni del client. Durante la prima fase del processo di creazione dell'analizzatore, viene generato un piano di esecuzione autonomo (piano macchina singola, piano di esecuzione distribuito) e verrà eseguito anche SQL, ad esempio modifiche dell'ordine di unione, push down del predicato e così via. Tutti i nodi conservano una copia delle informazioni sui metadati più recenti per garantire che tu non sia escluso dal giro. Prima di utilizzare Hadoop, Hive o Impurbia, è necessario installare il software di elaborazione dei dati necessario.

Il file di configurazione di Impala può essere modificato. Ogni nodo esegue una modifica della configurazione in Impala. Tutti i nodi sono responsabili della connessione del pacchetto driver MySQL a un database. I nodi cambiano il percorso Java di Bigtop.
Un confronto tra alveare e impala
Ci sono anche alcune piccole differenze, oltre a queste tre principali. In Hive è presente un sottoinsieme di HiveQL, mentre in Implicit è presente un sottoinsieme di HiveQL. Hive e Impala vengono utilizzati rispettivamente per il data warehousing e le query interattive. Hive, a differenza di Impala, non è destinato al calcolo interattivo.
Cos'è Impala In Hadoop
Impala è un motore di query SQL open source per i dati archiviati in un cluster Hadoop. È progettato per fornire query SQL rapide e interattive sui dati archiviati in HDFS, HBase o qualsiasi altra origine dati Hadoop .
Impala utilizza un'ampia gamma di componenti Hadoop familiari . INSERT può solo scrivere dati del tipo che Impala può leggere, mentre SELECT può leggere dati del tipo che Impala può leggere. Quando si utilizza un formato di file Avro, RCFile o SequenceFile, i dati vengono caricati in Hive. Le statistiche di tabella e le statistiche di colonna possono essere utilizzate in aggiunta alle statistiche di tabella e colonna. Tutte le istruzioni DDL e DML vengono aggiornate automaticamente utilizzando il demone catalogato in Impala 1.2 e versioni successive se vengono inviate tramite il demone catalogato. Il metodo INVALIDATE METADATA restituisce i metadati per tutte le tabelle nel metastore a cui è stato effettuato l'accesso. I file di dati vengono memorizzati nelle directory per una nuova tabella e vengono letti indipendentemente dal nome del file quando Impala è in esecuzione.
Nel complesso, Apache Hive funziona bene come piattaforma di data warehousing, mentre Impala è più adatto all'elaborazione parallela. L'alveare è tollerante ai guasti, mentre l'Impulsa no.
Apache Impala
Apache Impala è un motore di query SQL veloce e interattivo per Apache Hadoop. Consente agli utenti di inviare query SQL a bassa latenza ai dati archiviati in HDFS e Apache HBase senza richiedere lo spostamento o la trasformazione dei dati.
Il concetto di architettura di Impala consente di gestire le query interattive utilizzando HDFS in modo più efficiente rispetto a qualsiasi altro motore di query. Hive è molto più lento a causa delle sue operazioni di I/O su disco, ma Apache è molto più veloce perché è un motore completamente diverso. Non c'è distinzione tra Impulsa e Presto perché Impulsa utilizza una tecnologia molto più veloce e Presto utilizza un'architettura simile. Quando si tratta di lime per parquet, Impala offre le migliori prestazioni. Determina quali dati dovresti partizionare in base alle query dei tuoi analisti. Con Compute Stats Statistics, le tue query saranno molto più semplici, soprattutto se coinvolgono più di una tabella (join). Abbiamo avuto un arresto anomalo del server del catalogo Impala quattro volte alla settimana e le nostre query hanno richiesto troppo tempo per essere completate.
Inoltre, la quantità di file che creiamo influisce notevolmente sulle prestazioni delle nostre query. Di conseguenza, abbiamo iniziato a gestire le nostre partizioni e ad unirle nella dimensione ottimale del file di circa 256 MB. Si afferma che ogni partizione ha un solo file (a meno che la sua dimensione non sia > 256 MB). Il tipo di colonna più appropriato dovrebbe essere scelto tra tutti i tipi di dati supportati da Implicit. Per limitare il numero di query simultanee o la memoria Y a cui un utente accede, utilizzare Impala Admission Control. Se una query dura più di 30 minuti, è considerata morta.
Il miglior motore per i Big Data: Impala
Il motore Impala è un motore di elaborazione dati Hadoop progettato specificamente per cluster di grandi dimensioni. Utilizza molta meno energia e consuma molte meno risorse rispetto al motore MapReduce standard di Hadoop. Implicit utilizza il file system distribuito HDFS come supporto di archiviazione dei dati principale, basandosi sulla ridondanza di HDFS per prevenire interruzioni dell'hardware o della rete nodo per nodo. I file di dati che rappresentano i dati della tabella sono fisicamente rappresentati da formati di file HDFS familiari e codec di compressione.
Motore di query per l'elaborazione parallela
Un motore di query con elaborazione parallela è un tipo di motore di database progettato per elaborare le query in parallelo. Questo può essere fatto utilizzando più processori, più core o più macchine. L'elaborazione parallela può migliorare notevolmente le prestazioni di un motore di query, in particolare per le query complesse.
Un computer multiprocessore viene utilizzato per trasformare query complesse in piani di esecuzione che possono essere eseguiti contemporaneamente, consentendogli di elaborare grandi quantità di dati contemporaneamente. Per prestazioni elevate è necessaria un'esecuzione efficiente, ad esempio un buon tempo di risposta delle query o un throughput elevato delle query. Si ottiene attraverso l'uso di efficienti tecniche di esecuzione parallela e ottimizzazione delle query.
Elaborazione parallela: il futuro di Etl?
Una query di alto livello può essere trasformata in un piano di esecuzione che può essere eseguito in modo efficiente da un computer multiprocessore utilizzando l'elaborazione parallela delle query. L'elaborazione parallela impiega la tecnica di combinazione di dati paralleli e distribuiti, nonché le varie tecniche di esecuzione fornite dal sistema di database parallelo . L'elaborazione parallela delle query viene implementata in ETL dividendo l'insieme di record in ciascuna tabella di origine assegnata al trasferimento in blocchi della stessa dimensione e quindi eseguendo il processo di trasformazione dei dati per ciascuna tabella di origine in un ciclo, selezionando i dati consecutivamente, blocco per blocco .