
Fattori decisionali del frammento del database NoSQL
Pubblicato: 2023-02-13Quando eseguire lo shard in un database NoSQL è una decisione che deve essere presa in base a una serie di fattori, inclusi ma non limitati a: dimensione dei dati e tasso di crescita, carico e complessità delle query, requisiti di disponibilità e scalabilità e modello di dati. Non esiste una risposta univoca e la decisione va presa caso per caso. Tuttavia, ci sono alcune linee guida generali che possono essere seguite. Se il set di dati è piccolo e il carico di query non è eccessivo, il partizionamento orizzontale potrebbe non essere necessario. In questo caso, una singola istanza di database NoSQL può probabilmente gestire il carico. Man mano che il set di dati cresce e il carico di query aumenta, il partizionamento orizzontale può diventare necessario per mantenere buone prestazioni. Il modello di dati può anche dettare quando partizionare. Se i dati sono strutturati in modo tale da poter essere facilmente divisi in partizioni separate, lo sharding può essere una buona opzione. D'altra parte, se il modello di dati è complesso e interconnesso, lo sharding potrebbe non essere possibile o potrebbe non essere l'opzione migliore. Infine, devono essere presi in considerazione i requisiti di disponibilità e scalabilità. Se i dati devono essere altamente disponibili e sempre accessibili, potrebbe essere necessario lo sharding per fornire ridondanza ed eliminare i singoli punti di errore. Se la scalabilità è una preoccupazione importante, lo sharding può aiutare a distribuire il carico su più server.
Quando dovrei iniziare lo sharding?
Non esiste una risposta definitiva alla domanda su quando iniziare lo sharding. La decisione dipende da una serie di fattori, tra cui la quantità di dati archiviati, la velocità con cui i dati vengono aggiunti, la crescita futura prevista del set di dati, il livello di prestazioni desiderato e le risorse disponibili. In generale, lo sharding dovrebbe essere preso in considerazione quando il set di dati è troppo grande o sta crescendo troppo rapidamente per essere gestito in modo efficace da un singolo server di database.
Perché lo sharding del tuo MongoDB è essenziale per set di dati di grandi dimensioni
Quando dovrei iniziare a partizionare MongoDB? Quando un singolo database può gestire o archiviare una grande quantità di dati in crescita, la rivendita è un'ottima opzione. Un aumento di dieci volte della capacità di archiviazione del database migliora le prestazioni di un'applicazione. Anch'esso aggiunge complessità al tuo sistema. Lo sharding migliora le prestazioni? L'uso dell'hashing per migliorare le prestazioni del database è stato uno dei primi metodi. Il prodotto è diventato uno dei migliori grazie ai recenti progressi tecnologici. Nonostante i dati siano la risorsa più preziosa di un'azienda, i database stanno ricevendo maggiore attenzione. Perché lo sharding è migliore della replica? Se riesci a leggere i dati che non sono i più recenti, la replica potrebbe essere utile per il ridimensionamento orizzontale delle letture. In un pool di dati condiviso, i dati vengono distribuiti su più server con l'ausilio di una chiave condivisa, consentendo il ridimensionamento orizzontale. La scelta della chiave di partizione corretta è fondamentale. Perché partizioniamo MongoDB? Con MongoDB, le distribuzioni con un numero elevato di set di dati e operazioni a throughput elevato possono essere supportate con lo sharding. Un sistema di database che contiene grandi quantità di dati o ha un gran numero di utenti simultanei può essere difficile da gestire su un singolo server. È possibile che un server esaurisca le risorse della CPU quando vengono rilevati tassi di query elevati. Perché è necessario lo sharding? La normalizzazione si riferisce alla partizione del database orizzontale (per righe), mentre la partizione epocale si riferisce alla partizione orizzontale (per righe). I frammenti di dati sono divisi in parti più piccole, più veloci e più facili da gestire di database molto grandi in questo modo. è un esempio di come si possono ottenere sistemi distribuiti Quale db è il migliore per lo sharding? L'utilizzo di Sharding, noto anche come partizionamento orizzontale, come metodo di ridimensionamento è un approccio comune per i database. Amazon RDS è un servizio di database relazionale gestito basato su cloud che include numerose funzionalità che semplificano l'esecuzione dello sharding su più cloud.
Lo sharding è necessario in Nosql?
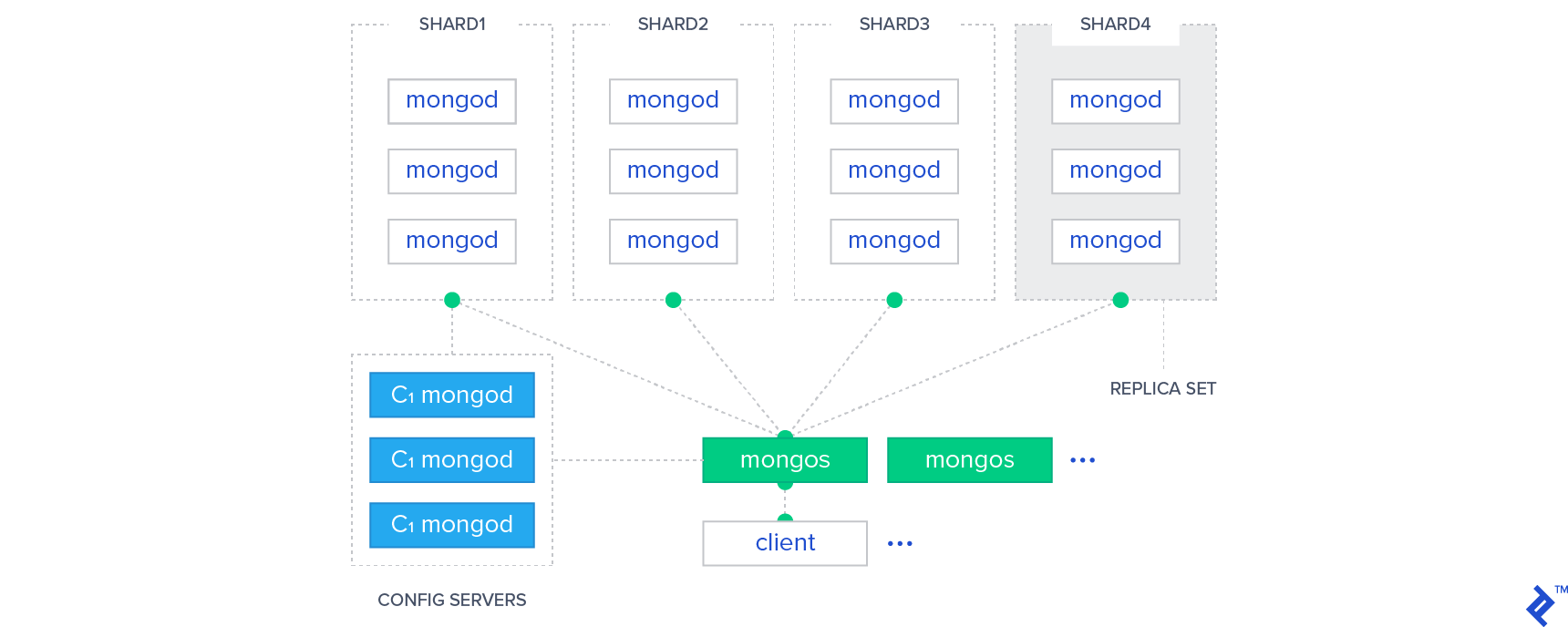
In NoSQL, il modello Sharding viene utilizzato per partizionare i dati. Il partizionamento è un metodo per collocare ciascuna partizione in server potenzialmente separati sparsi in tutto il mondo. Lo scale-out consente alle persone di accedere al set di dati in vari punti del mondo senza problemi.
MongoDB ha uno strumento importante nel suo database noto come Sharding. Può essere utilizzato per migliorare le prestazioni distribuendo grandi set di dati su più server. Un pezzo di dati su un server viene identificato come un pezzo di dati su un altro server utilizzando una chiave di partizione. Di conseguenza, i dati possono essere copiati sui server senza doverli reindicizzare.
Sharding è la soluzione giusta per il tuo database?
Di conseguenza, se il singolo database della tua applicazione non è in grado di gestire o archiviare una grande quantità di dati in crescita, archiviarli in un'istanza Sharding è un'ottima opzione. La presenza di Sharding migliora le prestazioni del database e ridimensiona l'applicazione. Di conseguenza, tuttavia, vi è una certa complessità aggiuntiva nel sistema. Se non sei ancora sicuro che lo sharding sia la soluzione giusta per te, tieni presente che MongoDB può supportare anche il ridimensionamento orizzontale.
Quando dovresti Shard MongoDB?
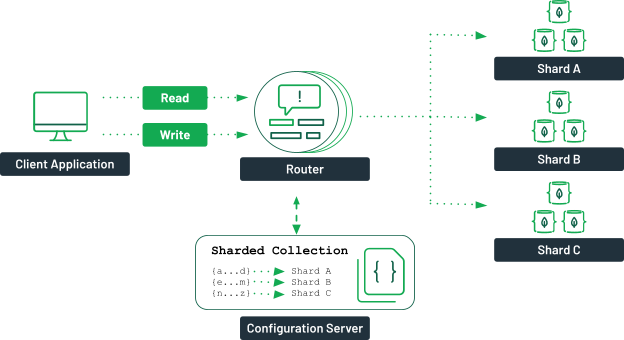
MongoDB dovrebbe essere partizionato quando le dimensioni dei dati superano la capacità di un singolo server e quando sono richieste prestazioni di query elevate.
Quando condividere il tuo database MongoDB
Dovresti prendere in considerazione lo sharding del tuo database MongoDB? Dovresti considerare diversi fattori quando decidi se utilizzare o meno uno shard per il tuo database MongoDB. Innanzitutto, se la tua applicazione MongoDB sta riscontrando tassi di query elevati, è una buona idea utilizzare lo sharding. Sraving può anche aiutare ad espandere il database se necessario. Prima di decidere se utilizzare lo sharding, è necessario considerare i vantaggi e i costi di esso. Come si fa a Shard MongoDB? Se prevedi di partizionare il tuo database MongoDB, ti consigliamo di utilizzare Amazon Relational Database Service (Amazon RDS). Le funzionalità di Amazon RDS rendono lo sharding semplice da usare nel cloud e ha anche il potenziale per la scalabilità.
Perché dovresti dividere un database?
Cos'è lo sharding del database ? Un set di dati di esempio può essere distribuito su più database utilizzando la tecnica dello scambio di epoche, che viene quindi memorizzato su più macchine. La capacità di archiviazione totale del sistema verrà aumentata in seguito alla divisione di set di dati più grandi in blocchi più piccoli e all'archiviazione in più nodi di dati.
Lo sharding è la risposta ai problemi del tuo database?
Perché è necessario partizionare un database? Lo sharding è un'ottima soluzione quando il singolo database nella tua applicazione non è in grado di gestire/archiviare una grande quantità di dati in crescita. In generale, ridimensionando il database, puoi migliorare le prestazioni della tua applicazione. Inoltre, aggiunge complessità al tuo sistema. Cos'è uno shard in un database? L'obiettivo della replica del database è suddividere un numero elevato di set di dati in partizioni o frammenti. Ogni nodo può archiviare la propria riga di dati all'interno di ogni shard sotto forma di righe univoche, che vengono archiviate separatamente l'una dall'altra. Lo schema o la progettazione del database originale è condiviso da tutti gli shard, ma i nodi che eseguono gli shard differiscono leggermente. Puoi usare un server sql per lo sharding? Utilizzando i blocchi, un set di dati di grandi dimensioni può essere ridimensionato e gestito in modo più efficace. Esistono numerosi metodi per suddividere un set di dati in frammenti. Un database NoSQL o SQL può essere utilizzato per eseguire Sharding. Possiamo condividere il database MySQL? In un cluster, le righe di partizioni (cluster) vengono eseguite automaticamente tra i nodi, consentendo ai database di scalare orizzontalmente su hardware a basso costo per gestire carichi di lavoro intensivi in lettura e scrittura, nonché API SQL e NoSQL direttamente dal server. Lo sharding per database relazionali è possibile solo? Uno dei metodi di scalabilità orizzontale più diffusi per i database relazionali è il metodo Sharding di scalabilità orizzontale. Amazon Relational Database Service (Amazon RDS) è un servizio di database relazionale gestito che semplifica lo sharding nel cloud grazie alle sue ampie funzionalità.

Perché abbiamo bisogno di Sharding in MongoDB?
Il processo di distribuzione dei dati su più macchine è noto come hashing. Con MongoDB, le distribuzioni con set di dati di grandi dimensioni e operazioni ad alta velocità possono trarre vantaggio dall'uso dello sharding. Un sistema di database con una grande quantità di dati o un'applicazione in grado di gestire un numero elevato di richieste può essere difficile da eseguire su un singolo server.
Abbiamo bisogno di sharding in Nosql?
Il partizionamento orizzontale del database è necessario per ridimensionare i database SQL e NoSQL , che sono sia database SQL che NoSQL. Stiamo suddividendo il database in più parti (frammenti) come suggerisce il nome. Ogni frammento ha il proprio indice, che viene utilizzato per determinare quali dati archivia.
I vantaggi dello sharding
L'atto di distribuire i dati su più server in un cluster viene definito sharding. È possibile migliorare le prestazioni di un database distribuendo il lavoro che deve eseguire su più server.
Il servizio MongoDB utilizza una chiave di partizione per distribuire i documenti da una raccolta all'altra. MongoDB divide i dati in blocchi, che sono suddivisi in intervalli non sovrapposti in base all'intervallo dei valori chiave. Il backend MongoDB tenta di distribuire questi blocchi in modo uniforme tra i cluster.
Non esiste un unico modo per utilizzare Cassandra per lo sharding. In MongoDB, ogni nodo secondario memorizza tutti i dati del nodo primario, mentre in Cassandra, ogni nodo secondario conserva solo poche partizioni chiave. Se Cassandra è partizionata, può raggiungere gli stessi livelli di prestazioni di MongoDB senza la necessità di un nodo secondario.
Perché abbiamo bisogno dello sharding nei database relazionali?
Grazie alla migliore distribuzione dei dati e del carico di lavoro in un'architettura di database ben progettata, tutti i frammenti di database possono essere distribuiti equamente. Ogni volta che una query viene passata attraverso un diverso set di shard, è coerente con le aspettative di prestazioni.
Quale Db è il migliore per lo sharding?
Il partizionamento del database è possibile in Cassandra, HBase, HDFS, MongoDB e Redis. MySQL, PostgreSQL, Memcached, Zookeeper e Sqlite sono solo alcuni dei database che non supportano nativamente lo sharding di PostgreSQL e MySQL. Quando un database non supporta la logica di sharding incorporata, deve essere archiviato nell'applicazione.
Sharding in Nosql
Esistono diversi modi per affrontare lo sharding in un database NoSQL. Il più comune consiste nell'usare una funzione hash per determinare su quale shard deve essere memorizzato un particolare pezzo di dati. Questo può essere fatto a livello di applicazione oa livello di database. Un altro approccio consiste nell'utilizzare lo sharding basato su intervallo, che prevede l'archiviazione dei dati su diversi shard in base all'intervallo di valori in cui rientrano. Questo è spesso usato per cose come i dati delle serie temporali. Ci sono anche alcuni altri approcci meno comuni, ma questi sono i due più comuni.
Perché lo sharding è la chiave per ridimensionare un database Cassandra
Quando si ridimensiona un database nosql, la chiave è utilizzare lo sharding. Il database è suddiviso in più parti note come lastre, a cui è quindi possibile accedere da più macchine. Il sistema può archiviare set di dati più grandi in blocchi e cluster di nodi più piccoli, aumentando la capacità di archiviazione totale.
Sraving, in particolare, può assumere la forma di sharding basato su chiavi e automatizzare la distribuzione dei dati tra i nodi in Cassandra. Per dirla in altro modo, Cassandra è in grado di gestire set di dati di grandi dimensioni senza richiedere hardware o software aggiuntivo.
Su quale categoria di database Nosql è consigliabile non condividere i dati?
Non esiste una risposta definitiva a questa domanda in quanto dipende dalle esigenze specifiche dell'applicazione. Tuttavia, in genere si consiglia di non condividere i dati su archivi di valori-chiave o database orientati ai documenti.
Nosql Sharding vs partizionamento
Il partizionamento e lo sharding sono entrambi metodi per suddividere una grande quantità di dati in sottoinsiemi più piccoli. Il partizionamento differisce dallo sharding in quanto comporta la divisione dei dati in più computer anziché la loro distribuzione su di essi. La funzione di partizione di un'istanza di database viene utilizzata per dividere sottoinsiemi di dati tra di essa.
Ridimensionamento del database con lo sharding
I database Nosql possono scalare orizzontalmente replicando lo schema e dividendolo in frammenti. Il partizionamento dei database è il processo di replica dello schema, quindi di divisione in varie parti in base a un identificatore di chiave su un'istanza del server di database separata per distribuire il carico. Ogni tabella distribuita contiene una chiave di partizione.
È possibile gestire set di dati di grandi dimensioni inserendoli e archiviandoli in microservizi. Esistono numerosi modi per suddividere una grande quantità di dati in piccoli pezzi. I database SQL e NoSQL possono essere utilizzati per combinare ed eliminare i dati.
Entrambi i database SQL e NoSQL si distinguono per la loro capacità di gestire la scalabilità e l'eterogeneità dei dati, mentre i database SQL traggono vantaggio dalla capacità di partizionamento del motore di database. Lo Shrsiting è un metodo efficiente per gestire i dati, indipendentemente dal fatto che sia necessario aumentare o diminuire le dimensioni.
Qual è un modo in cui un database Nosql distribuito di solito frammenta i dati?
Esistono diversi modi in cui un database NoSQL distribuito può partizionare i dati, ma un approccio comune consiste nell'utilizzare una funzione hash. Questa funzione viene utilizzata per determinare su quale nodo del database deve essere memorizzato un dato. Quando arriva un nuovo pezzo di dati, la funzione hash viene utilizzata per determinare su quale nodo deve essere memorizzato. Se il nodo è già pieno, i dati vengono inviati al nodo successivo nel database.
Il frammento in un database
Che cos'è uno shard in un database?
Il frammento di un server di database è un sottoinsieme di dati archiviati su quel server. Una raccolta di dati, nota come Shard, è composta da parti uguali. Poiché i set di dati più grandi possono essere archiviati su più server più piccoli, i client possono accedervi più rapidamente.
Mongodb Sharding
Lo sharding MongoDB è un processo di distribuzione dei dati su più macchine. È un modo per ridimensionare un database mongodb suddividendo i dati in parti più piccole e distribuendoli su più server. Ciò consente il ridimensionamento orizzontale del database, il che significa che è possibile aggiungere più server al sistema secondo necessità per far fronte all'aumento del traffico.
Sharding del tuo database
È disponibile una varietà di tipi di sharding, inclusi quelli a distanza/dinamici, algoritmici/hash, basati su entità/relazioni e basati sulla geografia. La suddivisione dei dati in intervalli e l'assegnazione di server a ciascuno di essi avviene tramite lo sharding dinamico . Il server viene spostato in regioni diverse man mano che i dati vengono aggiunti all'array, a seconda delle dimensioni dell'array. Lo sharding algoritmico/con hash divide i dati in bucket e assegna un server a ciascun bucket. Se i dati vengono aggiunti al bucket, viene assegnato un valore hash al server. Un metodo di sharding basato sulle relazioni divide i dati in entità e relazioni tra entità. Ogni entità ha un elenco di tutte le entità a cui si connette. Lo sharding basato sulla geografia divide i dati in regioni, assegna a ciascuna regione un server e quindi suddivide i dati in regioni.
Strategia di partizione della gamma di chiavi
Una strategia di partizione dell'intervallo di chiavi definisce il modo in cui i dati in una tabella partizionata vengono distribuiti su più partizioni fisiche. L'intervallo di chiavi si basa sui valori di una colonna di partizionamento e a ogni partizione viene assegnato un intervallo di valori basato sulle chiavi di partizionamento. Questa strategia viene spesso utilizzata per distribuire i dati in modo uniforme su più server o per garantire che i dati vengano archiviati nella stessa posizione fisica.
Partizionamento dell'intervallo: l'approccio del servizio di integrazione alla distribuzione dei dati
Il servizio di integrazione, che distribuisce righe di dati in base a una porta o un insieme di porte definite come chiavi di partizione, utilizza il partizionamento dell'intervallo per distribuire le righe di dati. Gli intervalli di valori per ogni porta sono specificati nel seguente formato. Di conseguenza, Integration Service utilizza la chiave e l'intervallo per inviare le righe alla partizione appropriata.
Il servizio di integrazione distribuisce righe di dati in base a una porta o un set di porte definito come chiave di partizione utilizzando il partizionamento dell'intervallo.
Quando carichi nuovi dati e rimuovi quelli vecchi, questo è un ottimo modo per farlo. Il processo di partizione dell'intervallo è facilitato da esso. Il roll-out dei dati, ad esempio, è una pratica comune, mantenendo online i dati dei 36 mesi precedenti.