
Database NoSQL: un'alternativa ai tradizionali database relazionali
Pubblicato: 2023-01-13I database NoSQL stanno diventando sempre più popolari come alternativa ai tradizionali database relazionali. Un database NoSQL non richiede uno schema fisso ed è facile da scalare. Una coda è un tipo di archivio dati NoSQL. Una coda è una struttura di dati che memorizza i dati in un modo FIFO (first-in, first-out). Una coda viene spesso utilizzata per archiviare i dati che devono essere elaborati in ordine sequenziale, ad esempio un elenco di attività da completare. Una coda è un tipo di archivio dati NoSQL perché non richiede uno schema fisso. Una coda può essere facilmente ridimensionata all'aumentare del numero di attività.
Se userò MongoDB o RavenDB come coda di messaggi , quale preferirò? L'oggetto messaggio può essere inviato a un servizio Web tramite il client e quindi recuperato dal servizio Web. Il servizio che sta eseguendo il lavoro può quindi selezionare un tipo di messaggio in base a qualsiasi criterio possa sorgere. Posso creare indici basati sugli scenari per velocizzare le cose. Se stai solo creando una coda, dovresti considerare NoSQL per nient'altro. Molto probabilmente avrà un impatto maggiore su prestazioni, affidabilità ed efficienza se decidi quale implementazione desideri utilizzare.
I database NoSQL (noti anche come SQL) memorizzano i dati in modo diverso rispetto ai database relazionali oltre ad essere non tabulari. Un database NoSQL può essere disponibile in una varietà di tipi diversi in base al suo modello di dati. I tipi di documento, i tipi di valore-chiave, i tipi di colonne larghe e i grafici sono i più comunemente utilizzati.
Datastore è un database NoSQL altamente scalabile che supporta un'ampia gamma di applicazioni. Di conseguenza, Datastore gestisce automaticamente il partizionamento orizzontale e la replica, consentendoti di utilizzare un database durevole e altamente disponibile che si ridimensiona automaticamente per gestire il carico delle tue applicazioni.
Che cos'è un datastore Nosql?
Esistono molti tipi diversi di archivi dati NoSQL, ciascuno con i propri punti di forza e di debolezza. Gli archivi dati NoSQL più popolari sono MongoDB, Cassandra e HBase.
I database NoSQL basati su documenti archiviano i dati in modo più efficiente rispetto ai database relazionali. Sono pensati per essere adattabili, scalabili e in grado di rispondere rapidamente ai requisiti aziendali per la gestione dei dati. I tipi di database comunemente indicati come NoSQL includono database di documenti puri, archivi di valori-chiave, database a colonne larghe e database a grafo. Le aziende Global 2000 stanno rapidamente adottando i database NoSQL per potenziare le applicazioni mission-critical. Ciò è dovuto a cinque tendenze che presentano sfide tecniche che rendono difficile l'utilizzo della maggior parte dei database relazionali. La gestione del database è un ostacolo importante allo sviluppo agile perché manca la capacità di supportare il modello di dati fisso che è essenziale per lo sviluppo agile. Il modello di applicazione definisce il modello di dati in NoSQL.
La modellazione dei dati in NoSQL non è statica. Il formato JSON è il formato predefinito per l'archiviazione dei dati in un database orientato ai documenti. Ciò elimina la necessità di framework ORM e migliora il processo di sviluppo. N1QL (pronunciato nickel), un potente linguaggio di query che estende SQL a JSON, è stato rilasciato come parte di Couchbase Server 4.0. Inoltre, include il supporto per le istruzioni standard SELECT / FROM / WHERE, nonché l'aggregazione (GROUP BY), l'ordinamento (SORT BY), i join (LEFT OUTER / INNER) e altri. Grazie alla sua architettura scale-out e all'assenza di un singolo punto di errore, i database distribuiti NoSQL presentano notevoli vantaggi operativi. La disponibilità sta diventando un problema importante poiché sempre più clienti interagiscono con le aziende online e tramite app mobili.
I database NoSQL sono semplici da installare, configurare e scalare. Con le loro letture, scritture e archiviazione distribuite, sono stati progettati per semplificare la lettura, la scrittura e l'archiviazione. Possono operare su un'ampia gamma di scale, comprese quelle che gestiscono e monitorano cluster di varie dimensioni. Non è necessario sviluppare software per la replica tra data center; un database NoSQL distribuito include la replica integrata tra data center. Inoltre, consente alle applicazioni di eseguire il proprio failover anziché attendere che il database rilevi un problema ed esegua un processo di ripristino basato sul database. I database NoSQL sono sempre più utilizzati nelle applicazioni Web, mobili e IoT grazie alla loro facilità d'uso e facilità di integrazione.
L'archiviazione tabelle è un'ottima soluzione per i dati che non sono archiviati in un database relazionale. L'archiviazione tabelle consente di archiviare i dati in un contenitore sufficientemente flessibile per adattarsi alla crescita dell'applicazione. Un sistema di archiviazione tabella può essere utilizzato per archiviare dati difficili da archiviare in un modello relazionale, ad esempio dati video o immagini.
Database Nosql di Azure: Documentdb, Graph e Keyvalue
I tre tipi di database NoSQL in Azure sono Azure DocumentDB, Azure Graph e Azure KeyValue. Con Azure DocumentDB non è necessario gestire i file di dati sul server o recuperarli dagli archivi; è serverless, valore-chiave e può gestire fino a milioni di richieste al secondo. Si tratta di un database grafico che può essere utilizzato per interrogare e gestire i dati su più livelli in un'applicazione. Azure Graph è un database a grafo che può essere usato per eseguire query e gestire i dati su più livelli in un'applicazione. Consente di organizzare e filtrare i dati negli elenchi ordinati e filtrati di Azure KeyValue.
Una coda è un database?
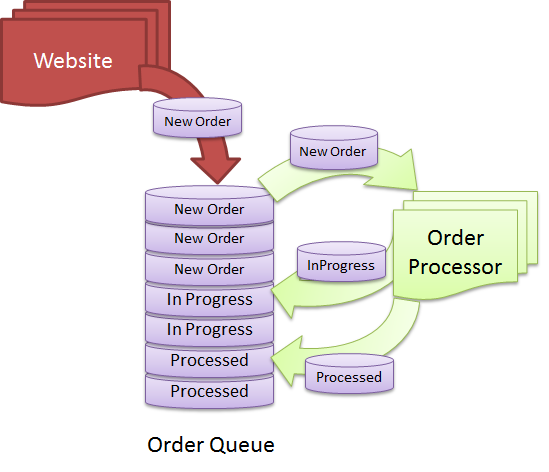
Non esiste una risposta definitiva a questa domanda in quanto dipende da come si definisce un database. In generale, un database è una raccolta di dati organizzata in un modo specifico in modo che sia possibile accedervi e aggiornarli secondo necessità. Una coda è una struttura di dati che consente di archiviare e recuperare i dati in un ordine specifico. Quindi, se consideri una coda come una raccolta di dati, potrebbe essere considerata un database. Tuttavia, se consideri un database solo come una raccolta di dati a cui è possibile accedere e aggiornare, una coda non sarà considerata un database.
Qual è il momento giusto per utilizzare un database per un sistema basato su code? È fondamentale mantenere una coda ordinata e organizzata affinché tutte le richieste vengano elaborate il più rapidamente possibile. Esiste una coda di messaggi progettata per gestire questo tipo di situazione, semplificando l'eliminazione dalla coda o l' accodamento dei messaggi . Immagina di avere centinaia di richieste di creazione di PDF nel tuo database in un dato momento. È auspicabile poter elaborare più richieste al secondo su base continua. Non è necessario connettere più worker (processi che gestiscono le richieste) perché puoi ridimensionare la tua soluzione. Per ricevere la richiesta, il lavoratore dovrà fornire un'ulteriore informazione.
Le code di messaggi non richiedono all'utente di eseguire alcuna transazione per garantire che i messaggi vengano archiviati ed elaborati. Invece di eseguire manualmente il polling dei messaggi da un database, le code dei messaggi vengono inviate in tempo reale. Se si esaurisce la potenza della CPU durante la connessione a troppe connessioni o l'esecuzione di altre attività che richiedono molta CPU, è possibile utilizzare più potenza della CPU per alimentare il server della coda dei messaggi. Nei casi in cui è richiesto un numero elevato di messaggi asincroni, è fortemente consigliata una coda di messaggi. Se un lavoratore muore durante l'esecuzione di un'attività, deve essere tenuto in coda fino a quando la richiesta non viene risolta. Quando un messaggio viene ricevuto ed elaborato, un lavoratore invia un riconoscimento alla coda dei messaggi per informarli dell'avanzamento.
Una coda è una struttura di dati che può memorizzare una raccolta di elementi in un ordine logico. Gli elementi inseriti in una coda vengono elaborati non appena possibile dopo essere stati aggiunti alla coda. Una coda può essere utile quando si desidera elaborare elementi in un ordine specifico. Un'istruzione SELECT è un metodo che può essere utilizzato per modificare il contenuto di una coda. Un'istruzione SELECT è un metodo che consente di selezionare gli elementi da una coda e di inviarli a un'altra posizione, se lo si desidera. L'istruzione SELECT viene utilizzata anche per inviare elementi da un'altra posizione a una coda appropriata , nonché per inserirli in una coda. Un'istruzione INSERT, UPDATE, DELETE o TRUNCATE non può tentare di indirizzare una coda. Se devi elaborare gli articoli in un ordine specifico, è utile una coda; tuttavia, non modificare gli elementi nella coda.

L'importanza dei sistemi di coda nei sistemi di database
Un database con meccanismi di coda è un'aggiunta eccellente a qualsiasi data center. È fondamentale disporre della funzionalità DBMS per i sistemi di coda perché possono essere utilizzati per una varietà di scopi. Integrando la funzionalità della coda in un sistema di database standard , altre applicazioni possono ottenere un maggiore accesso ad esse. Con questo aggiornamento, i sistemi di coda sono più potenti e versatili e la loro utilità e potenzialità sono aumentate.
MongoDB ha una coda?
Una coda è una raccolta di documenti che vengono inseriti in un database MongoDB in un ordine crescente basato sui dati di creazione del documento o una classifica dei documenti basata su una data priorità.
Se stai già utilizzando MongoDB, puoi utilizzare questo metodo per creare code con una bella API. Se si dispone di un driver MongoDB v3 o di un database precedente, si consiglia l' opzione mongodb- [email protected] . Questo pacchetto è classificato come funzionalità completa e stabile. Nonostante il suo uso diffuso, ci sono pochissimi nuovi sviluppi in corso. Fateci sapere se avete problemi o se lo usate in modo errato. Ogni coda che crei sarà una delle sue. È possibile creare una raccolta MongoDB chiamata ridimensionamento-immagine-coda o notifica-proprietario-coda, entrambi utilizzabili.
Se non ricevi un messaggio entro 30 secondi dalla ricezione, viene rimesso in coda in modo che possa essere recuperato. Esegui il polling della tua coda inattiva per vedere se sono stati trovati messaggi inattivi. Quando restituiamo tutti i messaggi dalla coda originale alla coda inattiva when.get(), il payload della coda inattiva è il messaggio. Se un elemento viene rimosso dalla coda ma non viene confermato, verrà spostato in questa coda inattiva al successivo tentativo di uscita. Se un elemento viene rimosso dalla coda ma non viene confermato, verrà spostato in questa coda inattiva al successivo tentativo di uscita. La coda può ancora essere visualizzata eseguendo il ping di un messaggio per dirgli che sei vivo e stai elaborando la richiesta. Il tempo di visibilità che passi all'operazione di ping è determinato anche dal metodo // tempo di visibilità (in questo caso, questa coda ha visto%d messaggi%d messaggi%d conteggi; ); // queue.ping(msg.ack, (err, id) = Il numero di messaggi che sono stati in coda nelle ultime 24 ore, così come i messaggi correnti.
Possiamo calcolare il numero di nuovi messaggi ricevuti ma non ancora attivati. Dovrebbe essere possibile get.total() se si sommano up.size() +.inFlight() +.done() ma questo sarà solo approssimativo perché le due sono operazioni diverse utilizzate per calcolare il totale. A volte le stagioni sono molto diverse. Utilizzare l'opzione setInterval per pulire regolarmente il sistema. Console.log('I messaggi elaborati sono stati eliminati dalla coda')*).
Coda MongoDB
Le code MongoDB (o code di messaggi) forniscono un meccanismo per archiviare i messaggi in modo ordinato, first-in-first-out. I messaggi possono essere inseriti nella coda in qualsiasi momento e verranno elaborati nell'ordine in cui vengono ricevuti. Ciò rende le code MongoDB ideali per l'elaborazione di attività che devono essere eseguite in un ordine specifico o per attività che possono essere elaborate in modo asincrono.
La missione di FloQast è consentire ai team di prodotto di accelerare e automatizzare lo sviluppo di prodotti innovativi. Tradizionalmente, AWS SQS è stato il nostro servizio di coda dei messaggi . Ciò ha comportato problemi in termini di mantenimento della lavorabilità e duplicazione. Invece, abbiamo scelto MongoDB come coda dei messaggi. In AWS Lambda, puoi facilmente aggiungere messaggi a qualsiasi coda. Elimina la necessità di aggiornare i servizi esistenti per utilizzare un Lambda separato. Quando si accede a una coda, il servizio utilizza il metodo atomic findAndModify di MongoDB per acquisire il primo elemento e richiamare Lambda in base alle istruzioni dello sviluppatore.
Che cos'è il flusso di modifiche in MongoDB?
In tempo reale, gli sviluppatori di applicazioni possono vedere i cambiamenti nei dati senza timore di seguire il loro oplog o dover affrontare la complessità e i rischi di strutture di dati complesse. Un flusso di modifiche può essere utilizzato da un'applicazione per sottoscrivere tutte le modifiche ai dati su qualsiasi raccolta, database o distribuzione e reagire immediatamente.
Utilizzare i trigger per automatizzare le operazioni del database
Utilizzando i meccanismi di trigger, puoi automatizzare le operazioni del database e rendere il tuo sistema più efficiente. Quando un documento viene aggiunto, aggiornato o rimosso da un cluster MongoDB Atlas collegato, i trigger possono gestire la logica lato server. Sarai in grado di mantenere il tuo sistema in esecuzione senza intoppi e, di conseguenza, automatizzare le operazioni del database.
Database di documenti Nosql
Un database NoSQL, chiamato anche database non relazionale, è un database che non utilizza la tradizionale struttura di database relazionale basata su tabelle. I database NoSQL sono spesso usati per big data e applicazioni web in tempo reale.
Un database orientato ai documenti è un modo moderno di archiviare i dati in JSON anziché utilizzare colonne e righe tradizionali. Questi dati semistrutturati possono essere utilizzati per affrontare problemi difficili che altrimenti richiederebbero un RDBMS. Gli archivi di documenti costituiscono una soluzione naturale e flessibile che può essere utilizzata dagli sviluppatori che desiderano lavorare più rapidamente con un software agile. Puoi eseguire query in vari modi con il linguaggio di query espressivo e le versatili funzionalità di indicizzazione. Un database relazionale ha una serie di garanzie che conosci durante l'esecuzione di transazioni ACID. Avere sistemi distribuiti ti consente di ridimensionare e proteggere i tuoi dati in modo più efficiente e adattabile. Ogni documento è distribuito su più server in un'unità indipendente, il che riduce la necessità di località dei dati.
I database di documenti sono intuitivi e semplici da usare, con velocità di dati più elevate rispetto ai database relazionali. La qualità dei dati sarà inferiore e le tabelle saranno rigide. Poiché la scalabilità orizzontale nativa non può essere eseguita, è necessario pagare costosi sistemi di scalabilità verticale se si desidera partizionare il database relazionale tradizionale. È possibile scegliere tra un'ampia gamma di tipi di documenti nei database orientati ai documenti; tuttavia, i campi presenti in ogni negozio potrebbero essere facoltativi. Ogni documento ha la stessa struttura, ma i suoi campi sono diversi. Ogni documento ha il proprio ID univoco che può essere utilizzato per aggiungere, modificare, eliminare e richiedere informazioni. In genere si pensa che la codifica dei documenti sia il processo di conversione dei dati (o informazioni) incapsulati in un formato standard.
Una struttura di database orientata ai documenti è meno rigida e quindi meno soggetta a incoerenze. Quando si interrogano le informazioni direttamente dal documento anziché dalle colonne all'interno del database, i dati vengono archiviati più direttamente nel documento. I dati possono essere aggiunti all'archivio documenti con un singolo campo che contiene campi di informazioni relativi ai dati.