
Database NoSQL: Big Table
Pubblicato: 2023-01-04I database NoSQL stanno diventando sempre più popolari grazie alla loro flessibilità, scalabilità e prestazioni. Un database NoSQL non richiede uno schema predefinito e può archiviare dati in qualsiasi formato. Ciò lo rende ideale per le applicazioni che devono archiviare grandi quantità di dati in continua evoluzione. La grande tabella è un tipo di database NoSQL progettato per archiviare grandi quantità di dati. Big table è utilizzato da molte grandi organizzazioni, come Google, Facebook e Amazon. Big table è altamente scalabile e può gestire miliardi di righe e milioni di colonne. Big table è anche molto veloce e può fornire accesso in tempo reale ai dati.
Google ha rilasciato una serie di aggiornamenti generalmente disponibili per il suo servizio di database Cloud Bigtable . Come risultato dei nuovi aggiornamenti, è ora disponibile fino a cinque volte più spazio di archiviazione per nodo. Google ha anche aggiunto funzionalità di scalabilità automatica migliorate che consentono a un cluster di database di crescere o ridursi automaticamente in base alle sue esigenze. Una nuova metrica di utilizzo della CPU e il routing dei gruppi di cluster consentono una maggiore visibilità su come vengono utilizzate le risorse di un'applicazione. A causa della separazione tra elaborazione e archiviazione, ogni tipo di risorsa può essere ridimensionato autonomamente su Bigtable. Gli utenti possono ora gestire facilmente le distribuzioni ad alta disponibilità e migliorare la gestione del carico di lavoro grazie alle nuove funzionalità.
NoSQL è una scelta popolare per l'archiviazione di grandi quantità di dati. Questo tipo di database sta diventando sempre più popolare tra le web company oggi. I fautori delle soluzioni NoSQL affermano che offrono una scalabilità più semplice e prestazioni migliori rispetto ai database tradizionali.
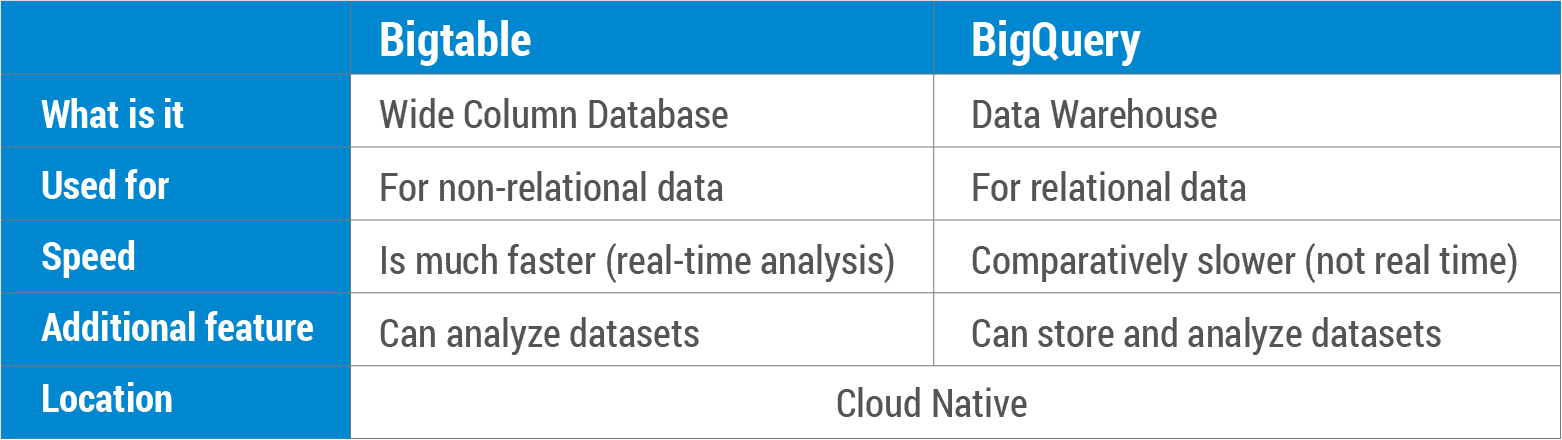
Bigtable è un tipo di servizio di database NoSQL che può essere utilizzato sia dagli sviluppatori che dagli amministratori di database. BigQuery è un ibrido, perché utilizza i dialetti SQL e si basa sulla tecnologia di elaborazione dei dati di Google, Dremel.
Bigtable Sql o Nosql?
Non esiste una risposta definitiva a questa domanda in quanto dipende da come si definisce ciascun termine. Tuttavia, se prendiamo una definizione ampia di SQL come qualsiasi database che utilizza un linguaggio di query strutturato e NoSQL come qualsiasi database che non utilizza un linguaggio di query strutturato, allora Bigtable sarebbe considerato un database NoSQL.
Che cos'è un confronto tra Bigtable e BigQuery? Bigtable è un database NoSQL che consente di archiviare i dati in modo sicuro e scalabile. BigQuery è un data warehouse relazionale che memorizza enormi quantità di dati in un database SQL. Bigtable è stato integrato nei prodotti Google come Analytics, Finance, Ricerca personalizzata, Earth e Writely per le loro operazioni quotidiane. Bigtable, un database NoSQL di dati mutabili , funziona bene con gli scenari OLTP. BigQuery è un data warehouse SQL relazionale che può essere utilizzato per le applicazioni OLAP. Sia Bigtable che BigQuery sono cloud-native, con contratti di servizio leader del settore. Inoltre, offrono backup automatico (con replica) nonché scalabilità infinita, sharding automatico e ripristino automatico in caso di errore (con replica).
BigQuery, piuttosto che un database NoSQL, non lo fa.
Che tipo di database Nosql è Bigtable?
Cloud Bigtable è un database NoSQL che può essere utilizzato per analizzare i dati ed eseguire operazioni. È un'alternativa a HBase, che è un sistema di database a colonne che utilizza HDFS. Le applicazioni con una larghezza di banda inferiore a 10 MB sono adatte a Cloud Bigtable, che può supportare un elevato livello di throughput e scalabilità.
I database Big Table, come sono noti, sono un sottoinsieme dei database NoSQL. Bigtable, un'applicazione di Google, è simile a Kleenex. I database Bigtable sono lo standard del settore per l'imitazione e l'ispirazione. Sebbene l'articolo si occupi principalmente di Bigtable, esamina anche altri database NoSQL. Bigtable è stato progettato principalmente per uso interno da parte di Google, senza accesso esterno. Bigtable è stato introdotto su Google nel 2004 e da allora è stato utilizzato da più di 60 applicazioni Google. Un'implementazione di Bigtable richiede un server master per tenere traccia dei tablet in un cluster di altri server.
L'Apache Software Foundation ha contribuito a una serie di eccellenti iniziative tecniche, in particolare nel campo dei database. Accumulo e HBase utilizzano gli stessi principi di progettazione di Google Bigtable, ma in un formato disponibile in commercio. Attualmente, Apache HBase esegue il sistema di messaggistica di Facebook ed è strettamente integrato con Hadoop, consentendogli di elaborare grandi set di dati. Il database Hypertable si basa su Bigtable, che è un semplice database tabulare. Hypertable funziona allo stesso modo di Hadoop e HFS. Baidu, uno dei più grandi motori di ricerca cinesi, è uno dei principali sponsor di Hypertable. I clienti includono siti di aste online come eBay, Groupon e Rediff.com, nonché rivenditori offline come Lowe's e TJ Maxx.
Hadoop è una piattaforma software open source che consente agli utenti di archiviare ed elaborare enormi quantità di dati in modo efficiente. Ciò abilita i database NoSQL, che possono ridurre la quantità di dati richiesti per l'archiviazione su singoli server. Un database NoSQL, invece, non richiede uno schema fisso perché è guidato dalla scalabilità. Per questo motivo, sono una scelta eccellente per archiviare enormi quantità di dati in modo distribuito.
In quale tipo di datastore Nosql rientra Bigtable?
Una delle poche funzionalità disponibili nel mercato generico. Al suo livello più elementare, Bigtable è un database NoSQL che si estende su un'ampia gamma di colonne.
Il database a colonne Bigtable è?
Gli archivi a colonne larghe come Bigtable e Apache Cassandra non sono colonne nel senso tradizionale del termine perché non utilizzano affatto strutture di dati colonnari ai due livelli.
Bigtable è un database non relazionale?
Non esiste una risposta definitiva a questa domanda in quanto dipende da come si definisce un "database non relazionale". Bigtable è un archivio dati orientato alle colonne, che alcune persone considerano un tipo di database NoSQL. Tuttavia, ha il supporto per le transazioni e l'indicizzazione, che sono tipicamente associate ai database relazionali. Quindi, dipende davvero da come definisci un database non relazionale.
L'istruzione CREATE EXTERNAL TABLE può essere utilizzata per creare una tabella in BigQuery specificando una tabella da cui estrarre i dati. L'opzione uri può essere utilizzata per specificare una tabella da cui estrarre i dati. Lo schema della tabella include il nome della tabella, il tipo di tabella, i nomi delle colonne e i tipi di dati, nonché lo schema della tabella dell'opzione bigtable_options.
Se utilizzi MySQL, lo strumento di importazione BigQuery può essere utilizzato per importare automaticamente i dati da una tabella MySQL in BigQuery. Un nome di tabella e una famiglia di colonne vengono inseriti nello strumento, che importa i dati in una tabella BigQuery.
Quando utilizzi Google Cloud Console, devi inserire manualmente il nome della tabella e i parametri di qualificazione della famiglia di colonne. Sulla piattaforma Google Cloud è possibile importare dati da una varietà di fonti, tra cui MySQL, PostgreSQL, MongoDB e Redis.
Caratteristiche principali di Bigtable
Quali sono alcune caratteristiche di Bigtable?
La velocità di lettura e scrittura di Bigtable, la sua enorme scalabilità e la capacità di gestire grandi quantità di dati sono solo alcune delle sue numerose funzionalità. Inoltre, poiché Bigtable è un database NoSQL, le query SQL non sono supportate. Ciò elimina la necessità di eseguire operazioni SQL in database separati.
Bigtable è un database?
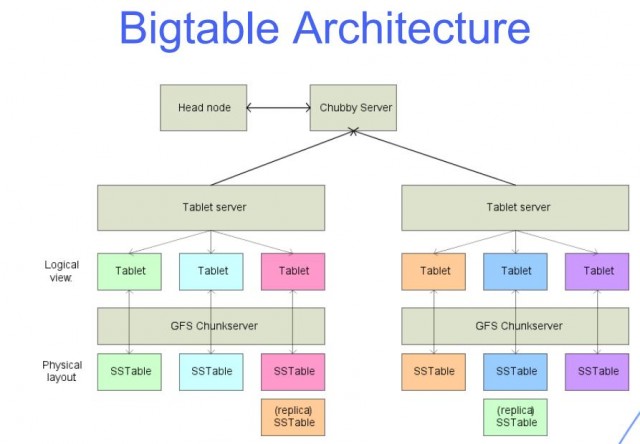
Bigtable non è un database relazionale. È un sistema di archiviazione distribuito per la gestione di dati strutturati progettato per scalare fino a dimensioni molto grandi: petabyte di dati su migliaia di server di prodotti. Google utilizza Bigtable per alimentare molti dei suoi servizi su larga scala, come Google Analytics e Google Maps.
Cloud BigTable offre un set unico di funzionalità che gli consentono di scalare fino a oltre 100.000 colonne e miliardi di righe. Supporta l'archiviazione di circa petabyte e terabyte di dati. Rispetto a BigTable, ha una latenza molto bassa, ma ha anche il potenziale per archiviare una grande quantità di dati. BigTable può archiviare dati strutturati in colonne, consentendogli di gestire i servizi Web e i dati di ricerca Internet dell'azienda. Gli algoritmi di compressione vengono utilizzati anche per aumentare la capacità del sistema. BigTable dispone di server back-end di grande impatto che offrono vantaggi migliori rispetto all'installazione HBase autogestita inclusa in BigTable. Le righe su BigTable condividono lo stesso bordo, pertanto vengono anche chiamate blocchi.
Questi dispositivi, denominati "tablet", ti aiutano a gestire il carico di lavoro delle query. Il file system basato su cloud di Google Colossus viene utilizzato per archiviare tutti i tablet. Tutte le operazioni di scrittura in BigTable sono archiviate nel registro condiviso di Colossus, così come i file SSTable. Le sette funzionalità chiave di BigTable sono fondamentali per il successo di un'azienda. BigTable ha il potenziale per personalizzare, velocizzare e automatizzare la tua vita in vari modi. righe e colonne sono le due dimensioni dei dati in BigTable. Ogni riga contiene un identificatore univoco o un indice a cui è possibile accedere utilizzando la chiave di riga singola.
Ognuna delle colonne di una famiglia ha una colonna qualificante. L'uso di unità qualificanti di colonna, come le chiavi di riga, aiuta nell'identificazione delle colonne. Quando si tratta di database, BigTable è noto come uno scarso. Ognuna delle versioni timestamp di BigTable è rappresentata da una cella, che è una delle dimensioni all'interno della struttura della mappa 3D. Questo potente database, che può essere personalizzato e sensibile alla velocità, può essere utilizzato per potenziare siti Web e app mobili. Se ripensi al passato, puoi capire quali interazioni hanno prodotto i migliori risultati. Ti aiuterà a implementare più analisi dei dati e porterà a un migliore servizio clienti.
Google Cloud Bigtable, un database NoSQL open source, è integrato con Google Cloud. Il fatto che sia compatibile con così tanti ecosistemi di big data e Hadoop esistenti significa che può essere utilizzato per dati non strutturati o dati che richiedono una bassa latenza.
Bigtable: una scelta eccellente per le applicazioni a uso intensivo di dati
Bigtable, un servizio di database NoSQL, viene utilizzato per grandi carichi di lavoro analitici e operativi. Di conseguenza, è una scelta eccellente per applicazioni ad alta intensità di dati e in tempo reale. Inoltre, poiché è orientato alle colonne, è ideale per archiviare i dati in tre dimensioni.
Bigtable contro MongoDB
Ci sono alcune differenze chiave tra Bigtable e MongoDB. Innanzitutto, Bigtable è un database orientato alle colonne, mentre MongoDB è un database orientato ai documenti. Ciò significa che in Bigtable i dati vengono archiviati in colonne, mentre in MongoDB i dati vengono archiviati in documenti. In secondo luogo, Bigtable non supporta gli indici secondari, mentre MongoDB sì. Ciò significa che se vuoi interrogare i dati in Bigtable, devi conoscere la colonna specifica che vuoi interrogare. In MongoDB, puoi interrogare qualsiasi campo in un documento. Infine, Bigtable è progettato per scalare orizzontalmente, mentre MongoDB è progettato per scalare verticalmente. Ciò significa che in Bigtable puoi aggiungere più macchine al tuo cluster per aumentare la capacità, mentre in MongoDB puoi aggiungere più RAM e CPU al tuo server per aumentare la capacità.
Cloud Bigtable di Google: non solo per i Big Data
Bigtable è ancora un componente dell'infrastruttura di Google, essendo stato creato nel 2007. Sebbene Cloud Bigtable sia ideale per l'archiviazione di grandi quantità di dati con bassa latenza, non è l'ideale per i dati che non richiedono un accesso frequente. Cloud Bigtable, ad esempio, non sarebbe adatto per un data lake.
Database BigTable
Un database bigtable è un database che utilizza una struttura di dati bigtable . Un bigtable è un sistema di archiviazione distribuito per dati strutturati progettato per scalare a dimensioni molto grandi.
Una tabella di grandi dimensioni è una tabella con molte righe e colonne ed è in genere scarsamente popolata. Bigtable è ideale per set di dati di grandi dimensioni grazie alla sua bassa latenza e all'elevata densità. Questa origine dati è ideale per le operazioni MapReduce perché supporta un'elevata velocità effettiva di lettura/scrittura a bassa latenza ed è ideale per set di dati di grandi dimensioni. I dati di una tabella Bigtable vengono suddivisi in blocchi di righe contigue, ciascuna delle quali viene definita tablet, al fine di ridurre il carico di query. Il formato SSTable viene utilizzato per archiviare i tablet Google in Colossus, il file system dell'azienda. Ogni tablet è collegato a un nodo specifico nell'istanza Bigtable, noto anche come nodo. L'aggiunta di nodi a un cluster può aumentare la capacità del cluster di gestire più richieste simultanee.
Ogni riga contiene una combinazione della famiglia di colonne, l'identificatore di colonna e il timestamp, essenzialmente un array di chiavi/voci di valore. La stragrande maggioranza delle volte, Bigtable converte tutti i dati in stringhe di byte grezze. Poiché Bigtable archivia le mutazioni in sequenza e le compatta solo una volta ogni pochi mesi, le mutazioni occupano più spazio di archiviazione quando vengono modificate in una riga. Bigtable comprime i dati utilizzando un algoritmo intelligente e impiega la tecnologia di compressione. Poiché le delezioni sono un tipo specializzato di mutazione, richiedono spazio di archiviazione aggiuntivo a breve termine. I metodi di archiviazione proprietari di Google gli consentono di resistere alla prova del tempo per i dati oltre l'intervallo della replica HDFS a tre vie standard. Gli utenti possono accedere alle tue tabelle Bigtable utilizzando i ruoli loro assegnati dal tuo progetto Google Cloud e da Identity and Access Management (IAM). La maggior parte dei dati di Google Cloud viene crittografata a riposo utilizzando gli stessi sistemi di gestione delle chiavi rafforzati che utilizziamo sui nostri dati crittografati. È possibile utilizzare un backup per salvare una copia dello schema e dei dati della tabella, nonché per ripristinare successivamente il backup in una nuova tabella.
Bigtable è un sistema di archiviazione distribuito ben progettato in grado di archiviare fino a petabyte di dati. Poiché è semplice da usare, è una scelta eccellente per l'archiviazione di dati su larga scala .
Il potere del cloud Bigtable
Il database Cloud Bigtable ha la capacità di contenere decine di migliaia di righe e colonne ed è accessibile da qualsiasi parte del mondo. Di conseguenza, è adatto per l'archiviazione di dati su larga scala. Cloud Bigtable è ora disponibile su Google Cloud a partire dal 6 maggio 2015. Ciò ha comportato l'elaborazione di oltre 10 EXAbyte di dati e l'elaborazione di oltre 5 miliardi di richieste al secondo da allora. Di conseguenza, Cloud Bigtable è ancora in uso ed è uno strumento prezioso per l'archiviazione dei dati.

Bigtable contro Cassandra
Ogni nodo viene scelto per le operazioni di lettura e scrittura utilizzando il proprio metodo. In Cassandra viene identificata una chiave di partizione, mentre in Bigtable viene utilizzata una chiave di riga. La politica di bilanciamento del carico di Cassandra viene prima ispezionata dal client.
Vengono distribuiti sistemi di database come Bigtable e Cassandra. Creano archivi chiave-valore multidimensionali in grado di elaborare decine di migliaia di query al secondo (QPS). L'obiettivo di questo documento è spiegare le differenze e le somiglianze tra i due sistemi di database. Bigtable contiene molte delle funzionalità principali descritte in Bigtable. Il documento descrive un sistema di archiviazione distribuito per dati strutturati. Quando Bigtable identifica l'assegnazione dell'intervallo come richiesto per un set di dati, gli intervalli di dati per un nodo di elaborazione sono semplici da modificare perché il livello di archiviazione è separato dal livello di elaborazione. Inoltre, Bigtable consente la replica asincrona tra cluster distribuiti geograficamente in topologie fino a quattro.
La tolleranza ai guasti è fornita da Cassandra, che è correlata al livello di coerenza. Utilizzando una strategia di topologia di replica dei dati configurabile, è possibile definire la replica geografica. Nella maggior parte delle topologie con più data center, QUORUM (o LOCAL_QUORUM) è l'impostazione predefinita. La maggior parte delle risposte di un nodo di replica al nodo coordinatore è necessaria affinché questa impostazione di livello sia considerata corretta. Le repliche dei dati in Cassandra possono essere migliorate in termini di tolleranza agli errori utilizzando configurazioni di data center e rack. La topologia determina quali nodi sono necessari per garantire la coerenza durante le operazioni di lettura e scrittura. L'istanza Bigtable può avere uno o più cluster oppure può avere una raccolta di un massimo di quattro cluster replicati.
Bigtable e Cassandra funzionano entrambi come archivi NoSQL a colonne larghe. La chiave di riga determina l'ordine in cui l'ordinamento globale dei dati di una tabella viene visualizzato in Bigtable. In Bigtable, i nodi vengono utilizzati per bilanciare la responsabilità degli intervalli di chiavi, comunemente indicati come tablet. Il servizio Bigtable non applica i tipi di dati di colonna inviati dal client. La famiglia di colonne Bigtable seleziona quali colonne in una tabella devono essere archiviate e recuperate da una all'altra. Ogni tabella deve avere almeno una famiglia di colonne, ma spesso le tabelle ne hanno di più (il numero massimo di colonne che una tabella può avere è 100). Una chiave di riga si trova in una cella e un nome di colonna si trova nell'altra.
Cassandra e Bigtable utilizzano metodi diversi per scegliere il nodo di elaborazione per le operazioni di lettura e scrittura. In Cassandra si distingue la chiave di partizione, mentre in Bigtable viene utilizzata la chiave di riga. Creando una policy multi-cluster, una policy di bilanciamento del carico che sia a conoscenza dei data center offre i vantaggi del failover. Entrambi i database sono stati ottimizzati per la scrittura veloce e utilizzano un processo simile per farlo. Entrambi i database memorizzano i dati in file SSTable, che sono file immutabili. In Cassandra, diverse repliche devono essere contattate prima che il coordinatore informi il cliente che la scrittura è stata completata. Poiché ogni chiave di riga in Bigtable è assegnata a un solo nodo, è necessaria una risposta da quel nodo per confermare che la scrittura è andata a buon fine.
Come risultato della fusione SSTable, entrambi i database possono escludere le celle. Quando si restituiscono dati a Cassandra, la clausola WHERE in una query CQL limita il numero di righe. Quando si utilizza Bigtable, è necessario consultare solo il nodo responsabile dell'intervallo di chiavi. I risultati di lettura di un nodo possono essere limitati in vari modi. Durante una fase di compattazione, Bigtable e Cassandra memorizzano i dati in SSTables, che vengono regolarmente uniti. Il Bigtable non limita il numero di versioni di timestamp per ogni cella, ma altre dimensioni di riga possono. La replica fornita da Colossus garantisce un'elevata durabilità dei dati.
L'interfaccia della riga di comando di Bigtable, così come le sue librerie client per una varietà di linguaggi di programmazione comuni, completano le capacità di Cassandra. Ogni nodo di Bigtable deve servire una serie di SSTable contenenti dati archiviati su tali tabelle. Non è più necessario calcolare le repliche di archiviazione in Bigtable come si farebbe in Cassandra per determinare le dimensioni del cluster. Le istanze Bigtable in genere memorizzano i dati su unità a stato solido (SSD) o dischi rigidi (HDD). A differenza di Cassandra, che si basa sulla teoria secondo cui non vi è alcuna perdita di densità di archiviazione per ottenere la tolleranza agli errori, il carico di lavoro non perde densità. È semplice aumentare o ridurre un'istanza di Bigtable in base alle esigenze per soddisfare i requisiti del carico di lavoro mantenendo al minimo lo sforzo e i tempi di inattività. Un'istanza può avere solo quattro cluster, ma possono essere raggruppati in qualsiasi regione cloud supportata sul pianeta.
Per creare una metrica per il pernodo QPS, Google consiglia di utilizzare le prestazioni di Bigtable con dati e query rappresentativi. Bigtable include componenti gestiti per le comuni funzioni di amministrazione di Cassandra. Una tabella che fa parte del cluster viene creata come copia ripristinabile della tabella in un backup di bigtable. Il prezzo di un backup è inferiore a quello di Cloud Storage o non consuma le risorse del nodo. Un'altra opzione consiste nell'utilizzare un'esportazione di dati gestiti in Cloud Storage per eseguire il backup di Bigtable. Bigtable gestisce con facilità le comuni attività di manutenzione interna di Cassandra come l'applicazione di patch al sistema operativo, il ripristino dei nodi, la riparazione dei nodi, il monitoraggio della compattazione dello storage e la rotazione dei certificati SSL. I dashboard sono predefiniti per monitorare la velocità effettiva e le metriche di utilizzo a livello di istanza, cluster e tabella nella pagina della console di Bigtable Google Cloud. È possibile utilizzare il dashboard di monitoraggio per eseguire l'ottimizzazione avanzata delle prestazioni.
SQL viene utilizzato in Bigtable, così come l'accesso tramite chiave di riga ai dati in un database NoSQL. I nodi sono distribuiti attraverso la rete e il gossip viene utilizzato per mantenere la coerenza della rete. Con questo sistema, la capacità di archiviazione dei dati viene aumentata e la disponibilità viene mantenuta senza un singolo punto di errore.
Bigtable, invece, è più scalabile e offre un livello di disponibilità maggiore rispetto a Cassandra. Bigtable è anche più user-friendly rispetto ad altri linguaggi di programmazione, rendendolo una scelta eccellente per set di dati con meno risorse.
Google utilizza ancora Bigtable?
Google Analytics, indicizzazione web, MapReduce e molte altre applicazioni Google, come Google Maps, Google Libri, La mia cronologia delle ricerche, Google Earth, Blogger.com, Google Code hosting, lo utilizzano per generare e modificare i dati archiviati in Bigtable, Google Maps , Google Libri, La mia ricerca
Google utilizza Cassandra?
La topologia DataStax Astra Cassandra as a Service è stata distribuita su Google Cloud utilizzando il sistema operativo TensorFlow, nonché utilizzando il sistema operativo Apache Cassandra in tre zone Google Cloud.
Bigtable è uguale a Hbase?
Un timestamp Bigtable viene archiviato in microsecondi, mentre un timestamp HBase viene archiviato in millisecondi. Questa distinzione può essere utile quando si utilizza la libreria client HBase per Bigtable e si osservano timestamp invertiti.
A cosa serve Bigtable?
Il database Bigtable NoSQL è un database a colonne larghe ideale per l'utilizzo in un database NoSQL. Il sistema è ottimizzato per fornire bassa latenza, un numero elevato di letture e scritture e prestazioni elevate su larga scala. L'uso di table case è in genere limitato a una scala o velocità effettiva specifica che richiede un'elevata latenza, come Internet of Things (IoT), AdTech, FinTech e così via.
Bigtable contro Bigquery
Ci sono alcune differenze chiave tra bigtable e bigquery. Bigtable è progettato per essere un database scalabile e orientato alle colonne, mentre bigquery è progettato per essere un database scalabile e relazionale. Bigtable non supporta SQL, mentre bigquery sì. Bigtable non è così ampiamente utilizzato come bigquery, ma presenta alcuni vantaggi rispetto a bigquery, come la possibilità di scalare a un numero maggiore di colonne e righe.
Google ha compiuto progressi significativi nell'archiviazione cloud di enormi dati nel corso degli anni. Bigtable è un servizio di database NoSQL completamente gestito su scala petabyte basato su Object Oriented Database Administration (OOPA). BigQuery è realizzato utilizzando Bigtable e Google Cloud Platform, nonché il sistema di database Dremel di Google. Ci sono tre differenze principali tra BigQuery e Bigtable. Una soluzione Big Data as a Service (BaaS) è quella fornita da Google Cloud BigQuery. BigQuery è utilizzato da prodotti Google come Analytics, Finance, Ricerca personalizzata, Earth, orkut e Writely. Quando viene utilizzata l'elaborazione dei dati velocissima di BigQuery, è possibile elaborare 35 miliardi di righe in pochi secondi.
Un database NoSQL è l'acronimo di un servizio di database; in altre parole, non è un database relazionale. Le colonne chiave possono avere dimensioni multiple e le barre dei tasti possono essere fatte scorrere orizzontalmente. I singoli elementi di dati con una maggiore capacità di archiviazione di 10 megabyte possono compromettere le prestazioni. Se hai bisogno di una soluzione di archiviazione completa per oggetti non strutturati (ad esempio file video), è probabile che l'archiviazione cloud sia un'opzione migliore. È una scelta eccellente per le query che richiedono una scansione della tabella o per esaminare un database di grandi dimensioni in un'unica ripresa. È impossibile che un oggetto caricato cambi nel corso della sua durata in BigQuery e i suoi dati sono sempre immutabili. Le tabelle all'interno di un bigtable memorizzano dati scalabili che sono stati ordinati in mappe di chiavi/valori ordinate per chiave, riga e timestamp.
Con Integrate.io, puoi automatizzare un ETL e un processo di integrazione dei dati per collegare le tue origini dati e i data warehouse nel cloud. La piattaforma di integrazione include più di 100 integrazioni predefinite, tra cui BigQuery, e un'interfaccia drag-and-drop che semplifica più che mai la gestione dei processi di integrazione. Contatta il nostro team di esperti di dati per discutere la tua situazione o per iniziare un progetto pilota di 14 giorni della piattaforma Integrate.
Google BigQuery è il migliore in termini di funzionalità, nonostante MySQL sia ancora ampiamente utilizzato. Ciò è particolarmente vero per le funzionalità comunemente utilizzate nelle applicazioni aziendali, come l'importazione e l'esportazione dei dati, l'analisi dei dati e la federazione dei dati. MySQL, d'altra parte, ha solo 28 funzionalità, il che significa che potrebbe non essere in grado di soddisfare le esigenze di molte aziende. Google BigQuery è basato su cloud e consente di accedervi da qualsiasi luogo con una connessione Internet. MySQL, d'altra parte, funziona su un'architettura client-server e non è disponibile nel cloud.
Qual è la differenza tra BigQuery e Bigtable?
Bigtable è un database NoSQL a colonne larghe ottimizzato per letture e scritture pesanti. A differenza di BigQuery, che è un data warehouse aziendale per grandi quantità di dati relazionali, Oracle Data Warehouse funge da servizio di deduplicazione.
BigQuery è costruito su Bigtable?
Presto seguirono rispettivamente Bigtable, un servizio di query basato su cloud sviluppato in collaborazione con Google e Microsoft, e il sistema Dremel di Google per query ad hoc.
Quando dovrei usare Bigtable?
Bigtable è ideale per le applicazioni che richiedono throughput e scalabilità elevati durante la gestione dei dati chiave/valore, con non più di 10 MB di dati per valore. I punti di forza di Bigtable sono le operazioni MapReduce in batch, l'elaborazione/analisi dei flussi e l'apprendimento automatico.
Servizio di database Nosql scalabile
Un servizio di database nosql scalabile è un tipo di database in grado di gestire dati su larga scala. È un servizio basato sul Web che può essere utilizzato per archiviare e gestire grandi quantità di dati. Questo tipo di database è progettato per essere scalabile in modo da poter gestire dati su larga scala.
Questo tutorial presuppone che tu abbia un ambiente Node.js funzionante. Ho creato una cartella chiamata nodejs-dynamodb-sample in cui decomprimere i file DynamoDB. La pagina GitHub per il progetto è https://www.gofundme.com/adamfowleruk/nodesurvey.html. L'app di esempio utilizza DynamoDB per cercare e recuperare i dati dei film. Per archiviare i dati su S3, utilizzeremo il servizio IAM (Identity and Access Management) di Amazon e per accedere a DynamoDB su AWS, utilizzeremo il servizio DynamoDB di Amazon. Per utilizzare il servizio iADM di Amazon, devi prima registrarti e creare un utente. È possibile aggiungere il titolo e l'anno di un film alla sezione POST/film della ricerca.
Crea un elenco di film di un determinato anno inserendo il campo inserito dalla chiave. Ora puoi creare la tua applicazione seguendo questo esempio di base. Se intendi utilizzare nuovamente le tue tabelle, dovresti eliminarle una volta terminato di utilizzarle, il che comporterà costi di hosting e servizio AWS. Su AWS, vai alla console DynamoDB e inserisci la quantità di storage che hai utilizzato. Puoi visualizzare gli elementi in una tabella facendo clic su "Film", guardare le metriche che vedi nella tua applicazione e vedere i costi mensili stimati facendo clic sulla scheda Capacità. Nella mia pagina GitHub, includo un esempio del codice in questo esercizio: https://github.com/adamfowleruk/nodejs-dynamodb-sample.
Database Bigtable di Google Cloud
Google Cloud Bigtable è un servizio di database NoSQL veloce, completamente gestito e nell'ordine dei petabyte, ideale per grandi carichi di lavoro analitici e operativi.
Il datastore di Google è più adatto per le applicazioni che richiedono risposte rapide alle richieste degli utenti.
Nel database Bigtable di Google non esiste un database relazionale. Le query SQL, i join e le transazioni su più righe non sono supportati. Di conseguenza, se stai cercando un supporto per database standard, non puoi aspettartelo. Bigtable, d'altra parte, non fornisce una grande quantità di dati o analisi. La natura ottimizzata di Bigtable è dovuta in parte alle sue capacità di analisi e gestione dei dati ad alte prestazioni. Datastore, d'altra parte, è progettato per consentire alle applicazioni di fornire dati transazionali di alto valore. Di conseguenza, Datastore è più adatto alle applicazioni che richiedono risposte rapide alle richieste degli utenti.