
Database NoSQL: elevata disponibilità e scalabilità attraverso la replica
Pubblicato: 2022-11-19Esistono molti tipi diversi di database NoSQL, ognuno con le proprie capacità e caratteristiche. Tuttavia, una caratteristica comune a molti database NoSQL è la capacità di replicare i dati su più server. La replica è il processo di copia dei dati da un server a un altro in modo che i dati siano disponibili su più server. La replica può fornire maggiore disponibilità e prestazioni consentendo la lettura dei dati da più server. I database NoSQL utilizzano in genere un modello di replica master-slave, in cui un server è designato come master e tutti gli altri server sono slave. Il server master conserva una copia dei dati e replica le modifiche sugli slave. Gli slave possono essere utilizzati per leggere i dati, ma tutte le scritture devono passare attraverso il master. Un vantaggio della replica è che può aiutare a migliorare le prestazioni distribuendo le letture su più server. La replica può anche migliorare la disponibilità fornendo più copie dei dati in caso di guasto di un server. I database NoSQL in genere offrono elevata disponibilità e scalabilità grazie alla loro capacità di replicare i dati su più server.
Allo stesso modo, NoSQL Data Replication è una funzionalità robusta che consente di copiare e archiviare senza problemi dati strutturati, non strutturati e semi-strutturati, nonché di prevenire la perdita di dati quando un server si arresta in modo anomalo. Ulteriori informazioni sui database NoSQL in questo sito.
Vengono eseguite sia la replica master-slave che quella slave-run e la replica master-slave designa un nodo come copia autorevole in grado di gestire sia le scritture che le letture. Un processo di replica peer-to-peer consente ai nodi di scriversi l'un l'altro e ogni nodo copia i dati sul successivo.
La replica di MongoDB si riferisce alla creazione di un set di repliche che condivide un set di dati comune con altre istanze di MongoDB . Il set di repliche contiene un numero di nodi che trasportano dati e il nodo che funge da arbitro è facoltativo. Ci sono sei nodi in un ambiente che porta dati, con un membro designato come nodo primario e gli altri membri classificati come nodi secondari.
In generale, un esperimento o una procedura che produce più di un certo numero di risultati è un successo; in questo caso, la replicazione del DNA viene copiata o replicata. L'atto di replicare qualcosa è indicato come replica.
Cos'è la replica dei dati Nosql?
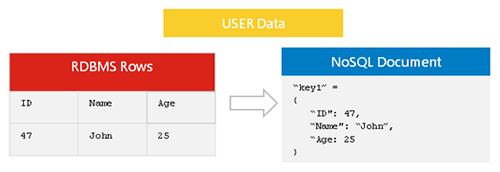
La replica dei dati Nosql è il processo di copia dei dati da un database nosql a un altro. Questo può essere fatto per una serie di motivi, come la creazione di un backup o la distribuzione dei dati su più server. La replica dei dati Nosql viene generalmente eseguita in modo asincrono, il che significa che la copia dei dati non deve essere una replica esatta dei dati originali.
Per molti anni, la replica dei dati è stata una componente essenziale dell'infrastruttura dati di qualsiasi organizzazione. Un sistema di replica dei dati proteggerà i tuoi dati garantendo alta disponibilità, backup e ripristino di emergenza. Inoltre, la replica contribuisce alla capacità dell'organizzazione di migliorare la coerenza e l'accuratezza dei dati. È un metodo per migliorare l'affidabilità dei dati attraverso il processo di replica. Replicando i dati, puoi assicurarti che siano sempre disponibili, sottoposti a backup e in caso di emergenza. Replicando i dati, può anche migliorarne la coerenza e l'accuratezza. Quando si progetta un'infrastruttura di dati, è fondamentale considerare la replica dei dati.
Che cos'è lo sharding e la replica in Nosql?
Qual è la differenza tra sharding e replica? Il nodo del server primario copia i dati dai nodi del server secondario come parte della replica dei dati. In questo modo, puoi aumentare la disponibilità dei dati e renderli un backup di emergenza in caso di guasto del server primario. Gestisce il ridimensionamento dei server su superfici orizzontali utilizzando una chiave di partizione.

I database Nosql hanno ridondanza dei dati?
Quando è presente un volume di dati significativo e la ridondanza dei dati può essere tollerata, il database NoSQL è più adatto a tipi specifici di applicazioni e casi d'uso selettivi.
Nosql può essere frammentato?
Il partizionamento in base a un modello di microservizi viene utilizzato negli ambienti NoSQL. Lo schema prevede la divisione di ciascuna partizione in più server, che possono trovarsi o meno nella stessa posizione in tutto il mondo. Questa scalabilità orizzontale funziona bene per le persone di tutto il mondo che desiderano accedere a diverse parti del set di dati e ottenere prestazioni elevate.
Cos'è la replica in un database?
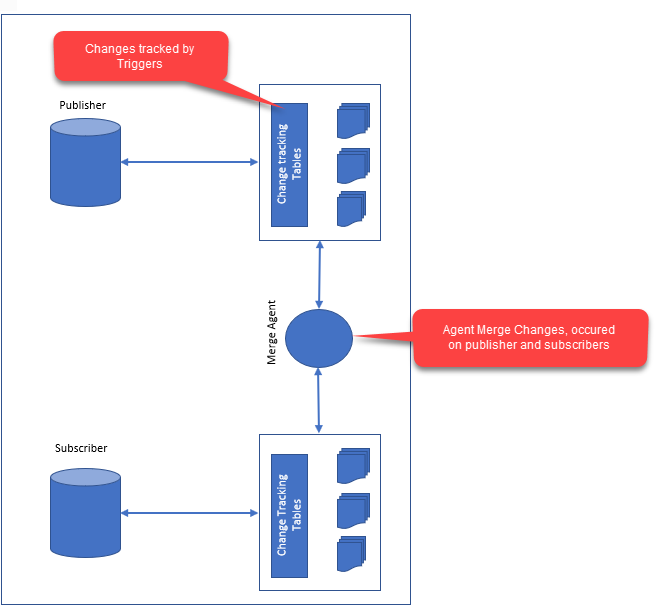
La replica in un database è il processo di copia dei dati da un database di origine a un database di destinazione. I due database possono trovarsi sullo stesso server o su server diversi. La replica può essere utilizzata per creare un backup dei dati, per distribuire i dati a più server o per consentire a più utenti di accedere ai dati.
L'integrità dei dati e le prestazioni sono entrambi aspetti critici della replica dei dati oggi . La riscrittura dei dati può essere semplice come inviarli a un abbonato o complicata come condurre più esperimenti contemporaneamente. La forma più comune di replica è la replica snapshot. Quando c'è una grande quantità di dati o se l'abbonato è remoto, invia loro l'intero set di dati. È una forma di replica più avanzata rispetto alla replica transazionale. In alcuni casi, invia modifiche ai dati solo all'abbonato o ai dati, il che può essere vantaggioso in file piccoli o locali. Questa è una tecnica di replica più complessa. Gli elementi possono essere modificati sia dall'editore che dall'abbonato, il che può essere utile in situazioni in cui i dati sono grandi o l'editore e l'abbonato sono remoti. La replica di dati eterogenei è così possibile per accedere a una varietà di prodotti di database. Ciò è particolarmente utile per i dati di grandi dimensioni e con più tipi di computer, ad esempio editori e abbonati.
Cosa si intende per replica in MongoDB?
Una replica MongoDB è un metodo per replicare il set di dati di più server MongoDB. È possibile ottenere ciò utilizzando un set di repliche. Un set di repliche è una raccolta di istanze MongoDB che servono lo stesso set di dati MongoDB e sono associate allo stesso processo.
Quando si crea un set di repliche, il nodo primario viene scelto automaticamente. Quando diventa disponibile, il nodo secondario sarà il nodo primario, con la designazione del set di repliche più elevata. Il set di replica MongoDB specifica i ruoli dei nodi primario e secondario e, se entrambi i nodi sono disponibili, MongoDB configura automaticamente il nodo primario. È una raccolta di istanze MongoDB identiche in termini di set di dati e processo. Gli amministratori di database possono offrire la ridondanza dei dati replicando i dati. I dati sono ampiamente disponibili. Un set di repliche è una raccolta di nodi MongoDB organizzati in gruppi per la replica. Un set di replica deve avere almeno tre nodi MongoDB: uno dei tre nodi è considerato il nodo primario responsabile della ricezione di tutte le operazioni di scrittura. Quando viene creato il primo set di repliche, il nodo primario viene scelto automaticamente.