
Database NoSQL: partizionamento e replica
Pubblicato: 2022-11-21I database NoSQL vengono spesso utilizzati per l'archiviazione di dati su larga scala grazie alla loro capacità di scalare orizzontalmente. Ciò significa che possono scalare aggiungendo più nodi al sistema, piuttosto che aggiornando l'hardware di un singolo nodo. Un modo per ottenere questa scalabilità orizzontale è attraverso lo sharding, che è un processo di distribuzione dei dati su più nodi. La replica è un altro modo in cui i database NoSQL possono essere ridimensionati e comporta la creazione di copie dei dati su più nodi.
In entrambi i database SQL e NoSQL, il concetto di partizionamento del database è fondamentale per il ridimensionamento. Il database è suddiviso in diversi blocchi (frammenti) come suggerisce il nome.
Puoi anche utilizzare NoSQL Data Replication per assicurarti di non perdere i dati quando un server si arresta in modo anomalo copiando e archiviando senza problemi i tuoi dati strutturati, non strutturati e semi-strutturati. Puoi saperne di più sui database NoSQL visitando questa pagina.
Un database relazionale può essere partizionato utilizzando il metodo Sharding, noto anche come partizione orizzontale. Amazon Relational Database Service ( Amazon RDS ) è un servizio di database relazionale gestito che semplifica l'utilizzo nel cloud fornendo una varietà di funzionalità.
Un metodo di replica copia i dati da più server e li colloca in una posizione in cui è possibile trovarli. Nella replica vengono create copie master e slave, con le copie master che diventano copie autorevoli che gestiscono i dati scritti e le copie slave che diventano copie asincrone che gestiscono i dati scritti.
Nosql usa lo sharding?
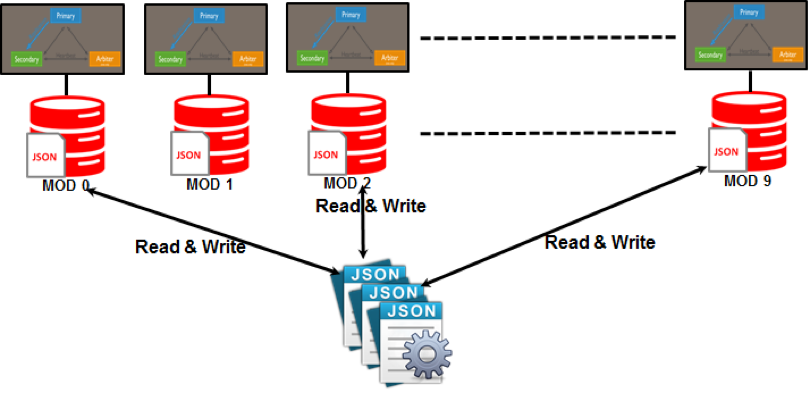
I modelli di partizione come la condivisione vengono utilizzati in NoSQL. Il partizionamento è un processo che assegna ciascuna partizione a un server che potrebbe essere indipendente dal resto della rete. Con questa scalabilità orizzontale, puoi fornire agli utenti globali l'accesso a un insieme diversificato di dati mantenendo il livello di prestazioni il più elevato possibile.
MySQL Cluster è la soluzione. MySQL Cluster è un set di software che esegue automaticamente il partizionamento delle tabelle tra i nodi e consente ai database di scalare orizzontalmente su hardware di base a basso costo per gestire carichi di lavoro ad alta intensità di lettura e scrittura utilizzando SQL e direttamente tramite le API NoSQL. MySQL Cluster ha il potenziale per essere utilizzato per molto di più che semplici blockchain. Può anche essere utilizzato per ridimensionare le tue applicazioni utilizzando MySQL Cluster. La ragione di ciò è che MySQL Cluster è un sistema di pianificazione. Di conseguenza, puoi ridimensionare le tue applicazioni decidendo quando e come verranno generati gli shard. Questo è un grande vantaggio perché non è necessario affidarsi al cloud computing . Ciò è dovuto al fatto che gli shard vengono prodotti sui nodi in cui viene eseguito il carico di lavoro. Di conseguenza, puoi controllare la quantità di concorrenza richiesta. Di conseguenza, MySQL Cluster dispone di un set di funzionalità molto potente. Può essere utilizzato per ridimensionare le tue applicazioni e per controllare la quantità di concorrenza richiesta.
Che cos'è lo sharding e la replica in Nosql?
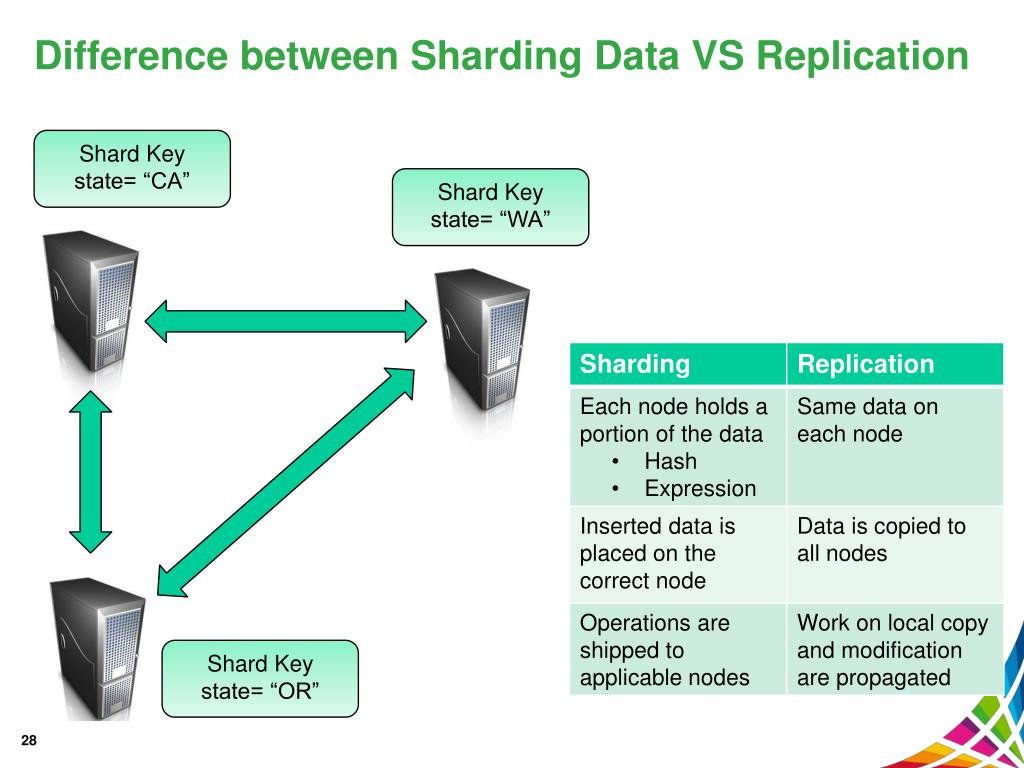
Qual è la differenza tra replica e sharding? La replica dei dati è l'atto di trasferire i dati dal nodo del server primario ai nodi del server secondario . Come backup in caso di guasto del server primario, questo può aiutare a garantire che i dati siano disponibili. Questa funzione può essere utilizzata per ridimensionare i server orizzontalmente utilizzando una chiave di partizione.
I vantaggi dello sharding
Quando hai a che fare con dati che devono essere partizionati ma non dispongono delle risorse per replicarli, la spaziatura può essere vantaggiosa in una varietà di situazioni. Quando è necessario ridimensionare le letture, la replica è utile, ma le scritture dei dati possono essere gestite in modo più efficiente con lo sharding. La scelta della chiave di partizione errata può avere un impatto negativo sulle prestazioni del sistema.
MongoDB usa lo sharding?
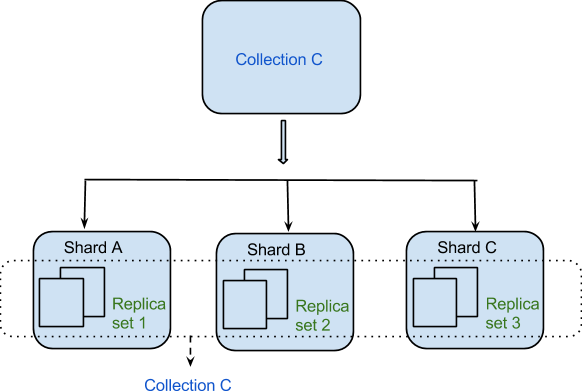
I dati vengono distribuiti tra le macchine in modo distribuito grazie allo Sharding. MongoDB utilizza lo sharding per supportare distribuzioni su larga scala che richiedono un elevato livello di throughput. Può essere difficile creare un singolo server per un sistema di database con un numero elevato di set di dati o un'applicazione a velocità effettiva elevata.
La strategia più comune per risolvere i problemi di Ranged Sharding è affrontarla nel suo senso più generale. Il nodo radice del cluster ha un numero predeterminato di shard che possono essere divisi in base alla loro distanza dal data center del cluster. Il nodo primario è indicato come nodo radice perché è il primo nodo ad essere creato nel set di dati. Un altro tipo di frammento è indicato come frammento secondario. È possibile effettuare entrambe le transazioni con intervallo o hashing. Il valore della chiave hash di uno shard specifico determina la quantità di dati che può generare. Un identificatore viene creato dalla chiave hash per ogni dato in una transazione. Ci sono numerosi vantaggi e svantaggi per ogni strategia. È più semplice implementare il range Sharding quando il set di dati è piccolo, rispetto a un set di grandi dimensioni, ed è più efficiente quando è piccolo. Quando il set di dati è grande, l'hashing è più efficiente. La reputazione di velocità di MongoDB deriva dal fatto che supporta la delega dei dati ad altri servizi MongoDB. I frammenti di set di dati possono essere distribuiti tra più server in MongoDB per migliorare la velocità di elaborazione dei dati. MongoDB supporta più opzioni di replica oltre allo sharding. Di conseguenza, la replica consente di distribuire un insieme di dati su più server per mantenere la coerenza. La replica dei dati è necessaria se si vuole garantire che le informazioni siano sempre accurate e aggiornate. Inoltre, i cluster sparsi in MongoDB possono essere utili per migliorare le prestazioni. Sraving è una tecnica per trasferire grandi quantità di dati da un server a un altro allo stesso modo della replica. Una chiave di partizione è un elemento di dati che può essere copiato (o "frammenti") da un server a un altro. I due metodi principali per la distribuzione dei dati tra cluster frammentati in MongoDB sono basati su intervallo e distribuiti. L'hashing può essere eseguito utilizzando un server crittografato. Dividendo le cose, puoi realizzare più di una cosa.

Dovresti frammentare il tuo MongoDB?
Non è certo se lo sharding migliori o meno le prestazioni in alcuni casi, ma è stato dimostrato che in alcuni casi aumenta le prestazioni. Inoltre, di conseguenza, lo sharding introduce una serie di sfide, come garantire backup e ripristini robusti. Prima di decidere su una strategia di sharding , dovresti pensare ai pro e ai contro di farlo.
Sharding in Nosql
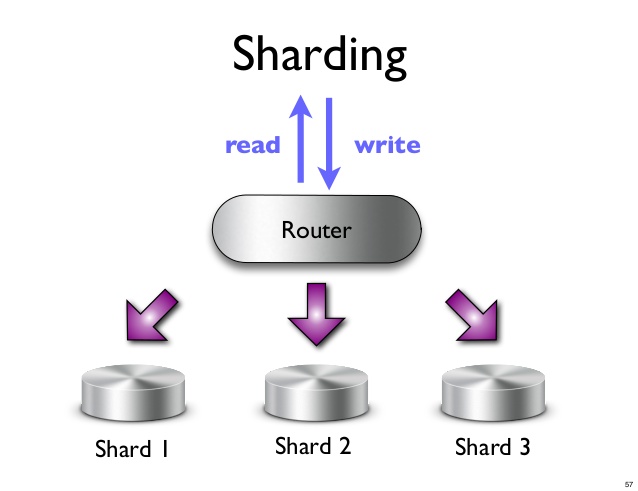
Uno shard è una partizione orizzontale di dati in un database o in un motore di ricerca. Ogni frammento è un database indipendente o un'istanza del motore di ricerca. In un database NoSQL, una raccolta di documenti può essere suddivisa in frammenti, ognuno dei quali è archiviato su un server separato.
Sharding vs replica
La distinzione tra replica e sharding è che la replica è la duplicazione dei dati, mentre lo sharding è la divisione dei dati in blocchi discreti. In questo caso, hai suddiviso la tua raccolta in più parti in base allo sharding. Il recupero del database produce immagini di tutti i set di dati.
I vantaggi dello sharding
I dati sono suddivisi su più macchine per aumentare il numero di utenti simultanei e migliorare le prestazioni. I dati vengono archiviati su partizioni separate in ciascuna delle macchine.
Replica in Nosql
Esistono diversi modi in cui la replica può essere gestita in un database NoSQL. Un modo è che il database si replichi automaticamente su un server secondario ogni volta che viene apportata una modifica. Ciò garantisce che sia sempre disponibile un backup nel caso in cui il server primario si interrompa. Un altro modo consiste nel replicare manualmente i dati su un server secondario su base regolare. Ciò offre all'amministratore un maggiore controllo su quando si verifica la replica, ma significa anche che esiste la possibilità che il server secondario non sia aggiornato in caso di errore.
Cos'è lo sharding nel database
Lo sharding è un processo di partizionamento orizzontale dei dati in un database. Nello sharding, un database è diviso in parti più piccole, chiamate shard. Ogni frammento è memorizzato su un server separato. Il processo di sharding aiuta a migliorare le prestazioni di un database distribuendo il carico su più server.
Un singolo pezzo di dati può essere replicato in una singola transazione con l'assistenza dello sharding. Come risultato della suddivisione di un set di dati in parti più piccole e della loro distribuzione su più server, è possibile aumentare la capacità di archiviazione complessiva del sistema. In alcuni casi, questo potrebbe essere utile se i dati sono di grandi dimensioni e richiedono più server per mantenerli. I wrapper di dati esterni vengono utilizzati anche per leggere i dati dai server remoti, offrendo all'archiviazione dei dati una flessibilità ancora maggiore.
Qual è la differenza tra partizionamento e sharding?
Il partizionamento e lo sharding sono due approcci per strutturare grandi raccolte di dati in piccoli frammenti. Sia lo sharding che la partizione significano che i dati sono distribuiti su più computer, ma sono distinti. La procedura per il partizionamento di un'istanza di database comporta il raggruppamento di sottoinsiemi di dati al suo interno.
Quale Db è il migliore per lo sharding?
Lo sharding del database è supportato da Cassandra, HBase, HDFS, MongoDB e Redis. I database che non supportano nativamente PostgreSQL, Memcached, Zookeeper, MySQL e Sqlite sono considerati database. La logica Jarryd deve essere presente in un'applicazione se non dispone del supporto integrato per i database.
Lo sharding è possibile in Sql?
È possibile, tuttavia, implementare lo sharding basato sull'intervallo (essenzialmente orizzontale), in modo da renderlo più trasparente all'applicazione. Il modo tipico per eseguire questa operazione in SQL Server è tramite una vista partizionata, ma non è necessario che sia così.