
Pig: una piattaforma di alto livello per Apache Hadoop
Pubblicato: 2023-02-22Pig è una piattaforma di alto livello per la creazione di programmi che girano su Apache Hadoop. Il termine "Pig" si riferisce al livello dell'infrastruttura della piattaforma, che consiste in un compilatore e in un ambiente di esecuzione, nonché in un insieme di operatori di alto livello. Il livello dell'infrastruttura di Pig fornisce agli sviluppatori una serie di strumenti per creare, mantenere ed eseguire i loro programmi Pig. Pig è un progetto open source che fa parte dell'ecosistema Apache Hadoop . Il modello di programmazione di Pig si basa sul flusso di dati, il che semplifica la scrittura di programmi che elaborano grandi quantità di dati. I programmi pig sono composti da una serie di operatori che vengono eseguiti in un grafo aciclico diretto. Pig è un'ottima scelta per l'elaborazione di grandi quantità di dati perché è scalabile, efficiente e facile da usare.
Come soluzione NoSQL, hai bisogno di modalità specifiche e predefinite per analizzare e accedere ai dati. SQL (UNION, INTERSECT, ecc.) è un'espressione di query comune che non viene utilizzata molto spesso nel mondo dei big data. Poiché Hive è ottimizzato per l'elaborazione in batch e di Big Data, è meglio toccare ogni riga. Hive spende molto meno tempo e denaro nelle operazioni rispetto a Hadoop, che ha il vantaggio della scalabilità. Anche piccole query sui sistemi di sviluppo possono essere ORDINI di grandezza più lente rispetto a query simili su RDBMS. Hive non memorizza nella cache i risultati delle query. Il reinvio di una query ripetuta è una pratica comune in MapReduce.
Esistono due tipi di Hive: 1) Hive non è un database; piuttosto, è un motore di query che supporta parti SQL specifiche per interrogare i dati b) Hive è un database con supporto SQL c) Hive è un database specifico per SQL. Hive è un sistema di data warehouse basato su SQL per Hadoop che include Pig e Python, tra le altre cose; Hive viene utilizzato per archiviare i dati Hadoop .
Maiale è un Sql?
Non esiste una risposta giusta o sbagliata a questa domanda, poiché dipende dall'opinione personale. Alcune persone potrebbero credere che il maiale sia uno sql, mentre altri no. In definitiva, spetta all'individuo decidere se il maiale è o meno un sql.
Oggi, Apache Hive e Pig sono due termini che stanno rapidamente diventando sinonimo di big data. Con questi strumenti, gli sviluppatori di dati e gli analisti possono utilizzarli per ridurre la complessità di MapReduce pur mantenendo un elevato livello di integrità dei dati. Hive è un'infrastruttura di data warehouse nota anche come strumento ETL (estrazione, caricamento e trasformazione). Apache Hive, Pig e SQL sono tre strumenti popolari per l'analisi e la gestione dei dati. Devi essere consapevole di quale piattaforma sarà la migliore per le tue esigenze e quanto spesso dovresti usarla. Diamo un'occhiata ai tre diversi modi di usare Hive, Pig e SQL nel contesto di queste tre tecnologie. SQL è ancora il re del posatoio nella gestione e nell'analisi dei big data, nonostante il predominio di Apache Hive e Apache Pig. Poiché ognuno svolge una funzione specifica, i loro requisiti sono adattati all'azienda. Apache Pig si basa su script e richiede conoscenze speciali, mentre Apache Hive è l'unica soluzione di database nativa per lo sviluppatore.
Il maiale è un animale versatile con una grande flessibilità. Pig, ad esempio, può elaborare file di registro contenenti dati JSON o XML, consentendo di leggere i dati. È anche possibile memorizzare dati dai servizi web in Pig.
Tipi di dati mappa, tuple e tipi di dati bag possono essere usati in modo intercambiabile. Sono in grado di gestire dati da qualsiasi fonte.
Maiale è uno strumento Etl?
Non esiste una risposta definitiva a questa domanda in quanto dipende da come si definisce uno strumento ETL. In generale, uno strumento ETL è un'applicazione software che consente di estrarre dati da una o più fonti, trasformarli in un formato compatibile con il sistema di destinazione e caricarli in quel sistema. Alcune persone direbbero che il maiale è uno strumento ETL perché può svolgere tutte queste funzioni. Altri potrebbero obiettare che pig non è uno strumento ETL perché non è specificamente progettato per la trasformazione dei dati. In definitiva, la risposta a questa domanda dipende dalla tua definizione di uno strumento ETL.

Come puoi usare il maiale per l'elaborazione ETL?
Un'applicazione Pig può essere descritta come un modello di transazione ETL, che descrive come un processo estrae i dati da un oggetto e li trasforma in un datastore basato su un set di regole. Gli utenti definiscono le funzioni definite dall'utente (UDF) del maiale per importare dati da file, flussi e altre fonti.
Che cos'è lo strumento maiale?
Una piattaforma o uno strumento noto come Pig elabora set di dati di grandi dimensioni. Questa libreria contiene un alto livello di astrazione per l'elaborazione dei dati nel processo MapReduce. Pig Latin è un linguaggio di scripting di alto livello che viene utilizzato nel processo di codifica per sviluppare i codici di analisi dei dati.
Qual è la differenza tra maiale e Sql?
SQL Pig Latin e Apache Pig sono linguaggi procedurali. SQL è un linguaggio di scripting di natura dichiarativa. Spetta interamente ad Apache Pig se lo schema viene utilizzato o meno. I dati possono essere archiviati senza la necessità di uno schema (i tipi di valore sono archiviati in $, $ e così via).
Il maiale fa parte di Hadoop?
Un'applicazione Pig Hadoop è un linguaggio di programmazione di alto livello che può essere utilizzato per analizzare enormi set di dati. Il progetto Pig Hadoop di Yahoo! è stato uno dei primi progetti Hadoop . In generale, esegue una notevole quantità di lavoro di amministrazione dei dati durante l'esecuzione di Hadoop.
Nel campo dell'analisi dei dati di grandi dimensioni, Pig Hadoop è un linguaggio di programmazione di alto livello. Per analizzare i dati utilizzando Apache Pig, dobbiamo prima scrivere script utilizzando Pig Latin. script che verranno trasformati in attività MapReduce . Ciò si ottiene utilizzando Pig Engine, un'estensione di Apache Pig. Seguendo i passaggi seguenti, puoi installare Apache Pig su Linux/CentOS/Windows (tramite VM o Cloudera). Il primo passo è scaricare e installare Apache Pig. Il secondo passaggio consiste nel modificare le variabili di ambiente di Apache Pig utilizzando il file bashrc.
Nel passaggio 3, determina la versione Pig . Questo file può essere salvato in un'altra directory dopo essere stato spostato. Il quinto passaggio consiste nell'avviare Grunt Shell (lo script utilizzato per eseguire Pig Latin) facendo clic sul comando Pig.
Perché Pig Latin è il miglior linguaggio di scripting di alto livello per l'analisi dei dati
Il codice di analisi dei dati Pig Latin è scritto in un linguaggio di scripting di alto livello. È un linguaggio simile a SQL che ha lo scopo di elaborare i flussi di dati in parallelo.
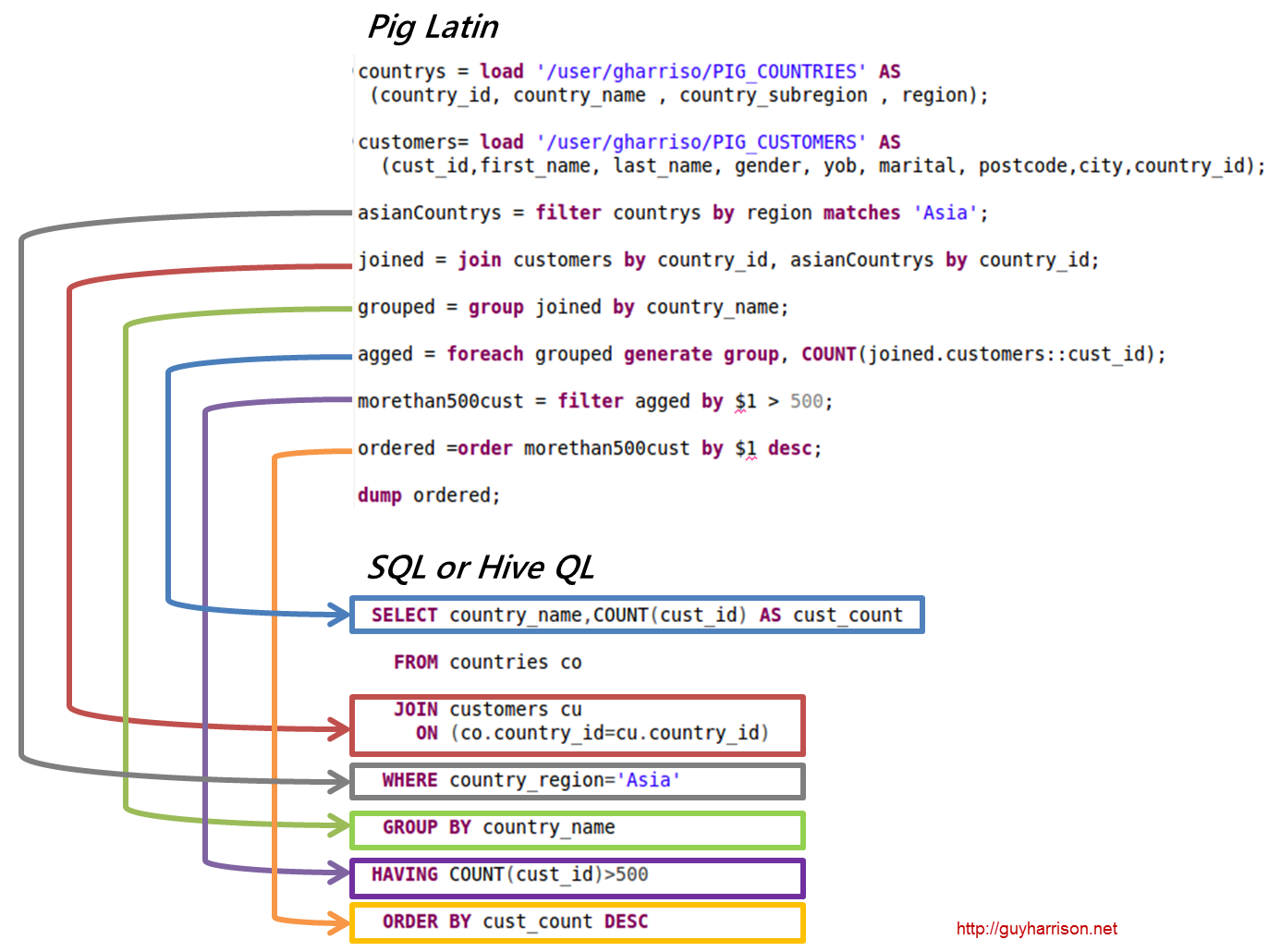
Esempio di maiale Apache
Pig è una piattaforma di alto livello per la creazione di programmi che girano su Apache Hadoop. La lingua per questa piattaforma si chiama Pig Latin. Pig può eseguire i suoi lavori Hadoop in MapReduce, Tez o Spark. Pig Latin astrae la programmazione dall'idioma Java MapReduce in una notazione che semplifica la programmazione MapReduce. Ad esempio, la seguente istruzione Pig Latin è equivalente al codice Java MapReduce precedente: A = LOAD 'mydata' USING PigStorage(',') AS (id:int, name:chararray, age:int, gpa:float); SCARICO A;