
Solr: una potente piattaforma di ricerca
Pubblicato: 2022-11-18Solr è una potente piattaforma di ricerca che ti consente di interrogare grandi quantità di dati molto rapidamente. È basato sulla libreria di ricerca Apache Lucene e fornisce un'API simile a REST per una facile integrazione con la tua applicazione. Una delle caratteristiche principali di Solr è la sua scalabilità: può gestire con facilità miliardi di documenti e query. Solr è spesso descritto come un database NoSQL perché non utilizza il tradizionale modello di database relazionale. Tuttavia, è importante notare che Solr non è un database tradizionale e non dovrebbe essere utilizzato come tale. È progettato per l'indicizzazione e la ricerca, non per la memorizzazione dei dati. Se devi archiviare i dati, dovresti utilizzare un database NoSQL come MongoDB o Cassandra.
Con Elasticsearch come unico progetto open source in grado di competere con Solr, Solr è uno dei due motori di ricerca open source più popolari al mondo. NoSQL sta per Not Only SQL, il che significa che utilizza linguaggi di query separati dal tradizionale SQL e non solo database. Nonostante la sua eccellente funzione di ricerca full-text, Solr può essere estremamente utile in un database NoSQL. I dati sulla salute sono stati estratti direttamente da HBase tramite applicazioni Explorys e Worklist precedenti. Solr ha fornito a Worklist tre caratteristiche essenziali: era estremamente facile da usare e le funzionalità erano molto intuitive. Il processo di filtraggio e smistamento è molto efficiente. Poiché il filtraggio di Solr si basa sugli ID documento e sulla memorizzazione nella cache, può calcolare quasi istantaneamente il numero di documenti che soddisfano i criteri del filtro.
Solr è un'eccellente soluzione di database NoSQL che viene spesso combinata con altri servizi di big data. Abbiamo fornito un feedback immediato ai nostri utenti mentre lavoravano all'aggiunta e alla configurazione dei filtri inviando il parameterrows=0 a Solr. È fondamentale considerare qualcosa di più del semplice mantenimento di uno schema Solr per creare un motore di ricerca che sia utile per la pertinenza.
Puoi usare Solr come database?
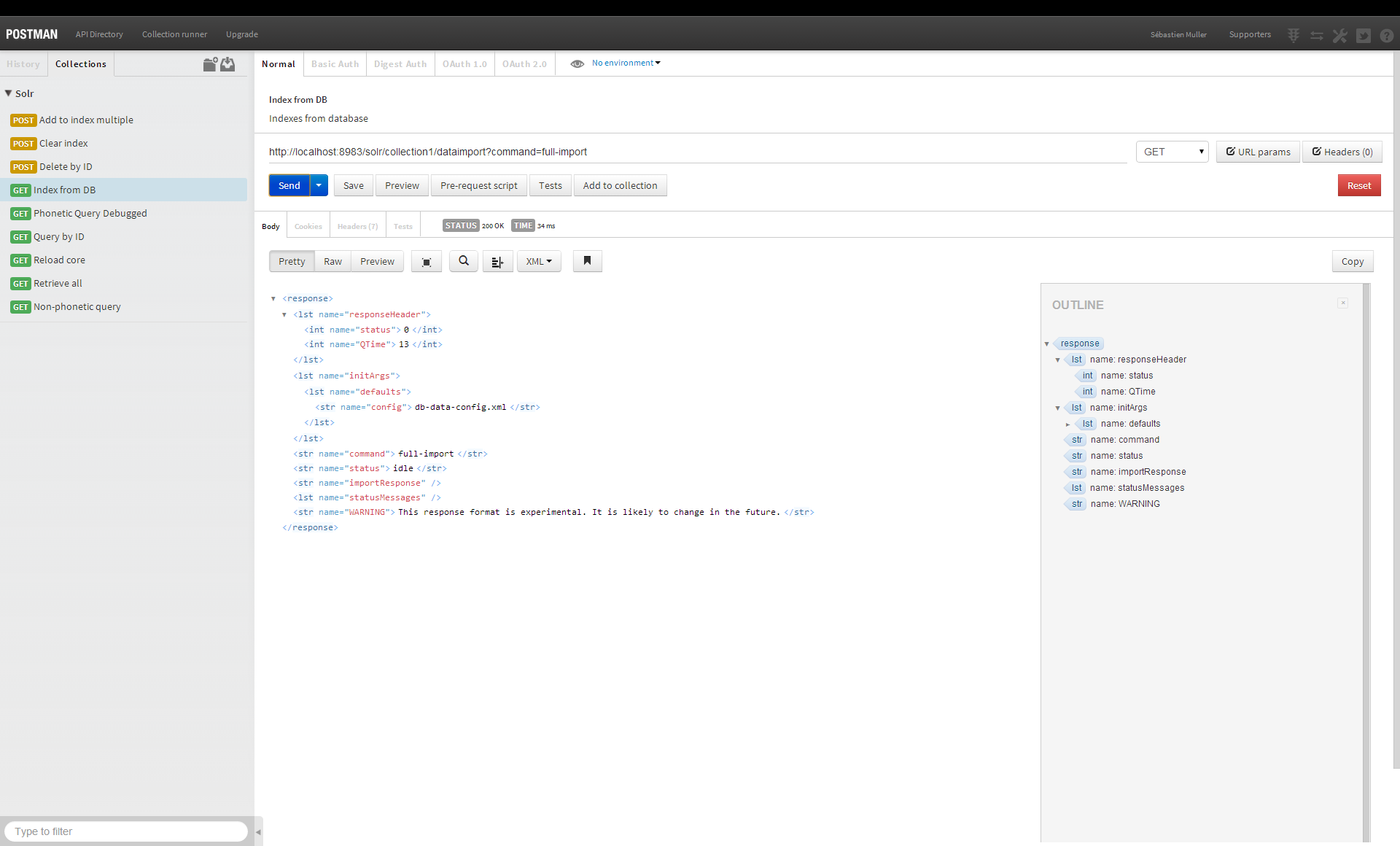
Sì, puoi usare Solr come database. È un potente motore di ricerca che può essere utilizzato per indicizzare e cercare dati. Può essere utilizzato per archiviare i dati in un formato strutturato e recuperarli rapidamente.
L'utilizzo di un indice di ricerca come database è sbagliato? Nel mio caso, ho avuto un'idea simile per memorizzare alcuni elementi di dati di base in Solr. Tuttavia, il processo di aggiornamento di Solr mi ha fatto cambiare idea e devo ammettere che mi sbagliavo. Se hai aggiornato 2 versioni principali ma non hai reindicizzato (ad esempio, eliminando i documenti originali e quindi i file di indice stessi), il core non viene più riconosciuto.
Algolia, Elastic Observability, Coveo e Yext sono solo alcune delle popolari alternative ad Apache Solr. Algolia è un motore di ricerca in linguaggio naturale che analizza ed elabora le query di ricerca in base a ciò che sappiamo su una persona o un argomento in linguaggio naturale. Elastic Observability è una piattaforma di dati che fornisce informazioni approfondite in tempo reale su dati e applicazioni. Coveo, una piattaforma di marketing sui motori di ricerca, ti consente di indirizzare e misurare i tuoi sforzi di marketing sui motori di ricerca. Utilizzando Yext, puoi indirizzare e misurare le tue campagne di marketing sui motori di ricerca.
Quali sono i database Nosql?
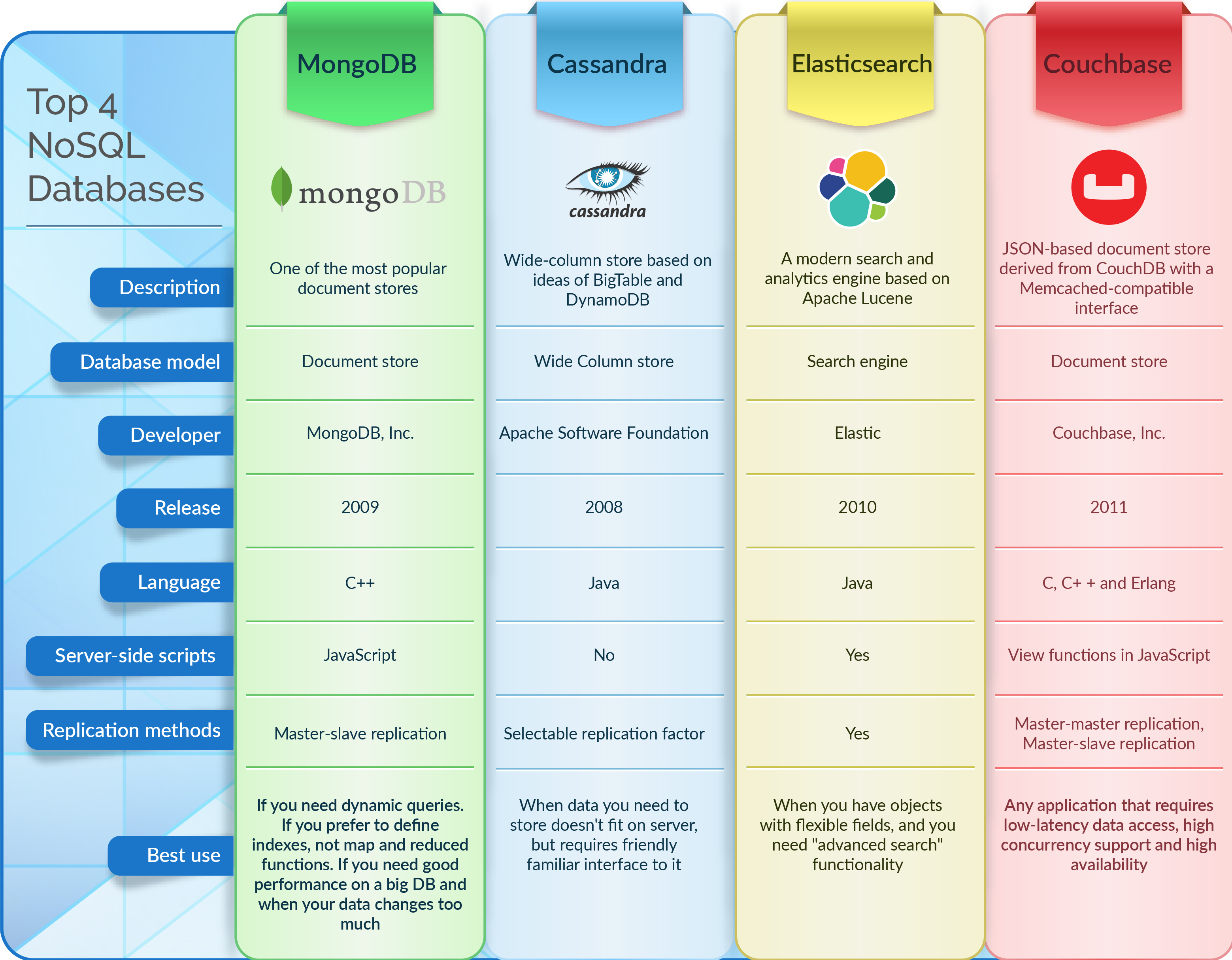
I database Nosql sono database che non utilizzano il tradizionale modello di database relazionale. Invece, usano una varietà di modelli, inclusi database di valori-chiave, documenti, colonne e grafici.
I database NoSQL basati su documenti memorizzano i dati allo stesso modo dei database relazionali. Il software di gestione dei dati è progettato per essere adattabile, scalabile e in grado di rispondere tempestivamente alle esigenze delle aziende moderne. Database di documenti , archivi di valori-chiave, database a colonne larghe e database a grafo sono solo alcuni dei tipi di database NoSQL. La maggior parte delle 2000 aziende più grandi del mondo sta rapidamente adottando i database NoSQL per potenziare le applicazioni mission-critical. In questo contesto, cinque tendenze stanno fornendo sfide tecniche che sono troppo difficili da affrontare per la maggior parte dei database relazionali. A causa del modello di dati fisso, i database relazionali rappresentano un grave ostacolo allo sviluppo agile. Il modello di applicazione definisce il modello di dati di NoSQL.
I dati devono essere modellati in un modello NoSQL indipendentemente da come sono strutturati. Il formato JSON è l'impostazione predefinita per l'archiviazione dei dati in un database orientato ai documenti. I framework ORM possono essere ridimensionati in questo modo, riducendo i costi generali dello sviluppo dell'applicazione. N1QL (pronunciato nickel) è un linguaggio di query da SQL a JSON che è stato rilasciato come parte di Couchbase Server 4.0. Lo strumento supporta anche l'aggregazione (GROUP BY), l'ordinamento (SORT BY), i join (LEFT OUTER / INNER) e una varietà di altre funzionalità. Un database distribuito NoSQL con un'architettura scalabile, nessun singolo punto di errore e vantaggi operativi convincenti è una delle caratteristiche più interessanti. Poiché sempre più interazioni con i clienti avvengono online tramite Web e app mobili, la disponibilità è un problema.
I database NoSQL sono semplici da imparare e utilizzare. Sono destinati a memorizzare informazioni, scrivere e leggere libri. Sono inoltre in grado di gestire e monitorare cluster di varie dimensioni a qualsiasi dimensione. La replica integrata inclusa in un database NoSQL distribuito è fornita dal database stesso e non è richiesto alcun software aggiuntivo. Inoltre, i router hardware garantiscono un accesso immediato e coerente ai dati critici. Mentre gli amministratori del database stanno esaminando un problema, le applicazioni non devono attendere che il database rilevi un problema prima di eseguire il proprio ripristino. La tecnologia NoSQL sta guadagnando popolarità come piattaforma per le odierne applicazioni Web, mobili e IoT.
Ci sono numerose ragioni per cui i database NoSQL stanno diventando sempre più popolari. Possono essere ridimensionati per soddisfare le esigenze di grandi organizzazioni e sono adattabili. Ad esempio, considera Ryanair e Marriott come clienti di MongoDB. Queste organizzazioni, oltre a utilizzare MongoDB per alimentare le proprie app mobili e i sistemi di prenotazione, lo utilizzano anche per alimentare i propri siti web. Anche il sistema di gestione dei contenuti Presto dell'azienda è realizzato con NoSQL. Il sistema aiuta nella gestione efficiente dei contenuti proprietari dell'azienda.
Il futuro del lavoro Il futuro del lavoro è remoto
Quale non è un database Nosql?
Qual è la differenza tra database NoSQL e non NoSQL? Microsoft SQL Server, il sistema di gestione del database relazionale dell'azienda, è il prodotto principale.
Durante la fine degli anni 2000, i database NoSQL si sono concentrati sul ridimensionamento, sui risultati rapidi delle query e sulla semplificazione della programmazione. I database NoSQL sono semplici da creare perché hanno un modello di dati flessibile, un modello di dati scalabile e un'interfaccia utente semplice da usare. I database relazionali SQL (Structured Query Language) sono in genere costruiti con schemi rigidi, complessi e tabulari, oltre a un ridimensionamento verticale proibitivo. La versione 4.0 di MongoDB includeva il supporto per le transazioni ACID multi-documento e la versione 4.2 aggiungeva il supporto per i cluster frammentati. Non ci sono modelli di dati nell'elenco. Nella maggior parte dei database NoSQL, le query sono ottimizzate anziché la duplicazione dei dati. Inoltre, alcuni n.
I database NoSQL supportano la compressione per ridurre i footprint di archiviazione. I database a grafo, ad esempio, possono essere utili per analizzare le relazioni, ma potrebbero non essere i più convenienti per il recupero dei dati giornalieri. L'utilizzo di MongoDB o di un altro database nel tuo caso d'uso verrà illustrato nel white paper Dove utilizzare MongoDB. L'utilizzo di MongoDB Atlas come punto di partenza è uno dei modi più semplici per apprendere i database NoSQL. La MongoDB University offre una formazione online completamente gratuita per aiutarti nell'apprendimento di MongoDB.
Ci sono, tuttavia, alcuni inconvenienti nei database NoSQL. I database NoSQL, oltre ad essere privi di ACID, non hanno le stesse proprietà dei database relazionali. Le transazioni nella tua applicazione possono causare problemi se il tuo sistema si basa su di esse. Inoltre, i database NoSQL in genere non forniscono lo stesso livello di flessibilità in fase di esecuzione dei database SQL. Dovresti evitare di utilizzare database NoSQL se la tua applicazione deve modificare dinamicamente i suoi modelli di dati.
Quale dei seguenti non è un database?
Poiché tutte le query, i report e le tabelle sono correlati ai database, le relazioni non sono oggetti di database; sono legati alla matematica.
MongoDB è un database Nosql?
Il programma di gestione del database MongoDB NoSQL è open source e gratuito. Il linguaggio NoSQL è un'alternativa ai tradizionali database relazionali. I database NoSQL sono eccellenti per la distribuzione di dati su larga scala. Le informazioni orientate ai documenti possono essere gestite, archiviate o recuperate utilizzando MongoDB, che è uno strumento di gestione dei documenti.
In che modo Solr memorizza i dati
Apache Solr indicizza i dati nel filesystem locale, come suggerisce il nome. Come risultato dell'HDFS (Hadoop Distributed File System), gli utenti possono godere di una serie di vantaggi, tra cui l'archiviazione su larga scala e distribuita con funzionalità ridondanti e di failover. Apache Solr include il supporto per HDFS.
A differenza di molti altri motori di ricerca, Solr può produrre risultati immediati perché cerca un indice piuttosto che cercare direttamente il testo. Analizzando l'indice sul retro di un libro, l'indice può essere utilizzato per recuperare le pagine relative a una parola chiave. Questo indice è memorizzato nella directory dei dati come indice in una directory nota come directory dei dati. Il motore di ricerca Solr è alimentato da Lucene, un motore di ricerca full-text open source. Il rapporto tra Solr e Lucene è simile a quello di un'auto e del suo motore. Esamineremo in dettaglio le differenze tra Lucene e Solr in questo articolo.

Come utilizzare i campi memorizzati in sol
Il formato del campo di un documento viene utilizzato in Solr. Un documento può contenere una qualche forma di campo, che è semplicemente una raccolta di dati. Quando cerchi un documento utilizzando Solr, i risultati includeranno le corrispondenze per tutti i campi nel documento che indicizza.
Un campo memorizzato è un campo che non deve essere cercato ma deve comunque essere visualizzato durante la ricerca di qualcosa. In Solr, questi sono noti come campi memorizzati. Solr indicizza tutti i campi archiviati come risultato del suo algoritmo di indicizzazione, quindi quando cerchi un documento, Solr restituisce risultati che includono tutti i campi archiviati.
Ci sono numerosi vantaggi nell'archiviazione dei campi. Se desideri visualizzare il titolo di un documento nell'elenco dei risultati, potrebbe essere necessario salvare il titolo come file. Se vuoi essere in grado di trovare tutti i documenti che hai mai cercato utilizzando lo stesso ID, puoi tenere traccia dell'ID di un documento attraverso più ricerche.
I risultati della ricerca possono essere visualizzati anche memorizzando i campi. Il titolo di un documento può apparire nell'elenco dei risultati se è etichettato. Potresti anche voler visualizzare l'ID del documento in modo da poterlo trovare facilmente cercando il documento in più siti.
Le capacità di Solr includono la possibilità di indicizzare i dati e archiviarli. Per indicizzare un documento, Solr deve prima creare un database di tutti i campi in esso contenuti, quindi verranno salvate le informazioni sulla posizione di ciascun campo. È possibile cercare e visualizzare i risultati di questo tipo di informazioni.
Oltre alle sue potenti capacità di ricerca, Solr consente di utilizzare potenti applicazioni di recupero dei documenti. Quando fornisci dati agli utenti in base alla loro query, si basa sulla loro query.
Esercitazione sul database Solr
Un database solr è un tipo di database che utilizza il software solr per indicizzare e cercare i dati. È uno strumento potente che può essere utilizzato per indicizzare e cercare grandi quantità di dati molto rapidamente.
Poiché questo tutorial è stato verificato con Solr 8, potrebbe funzionare anche con versioni precedenti. Il campo id è già predefinito in ogni Lucene e Solr, quindi bisogna capire quali tipi di campi può indicizzare nel modo corretto. I campi dinamici possono essere creati al volo senza la necessità di predefinizioni, consentendoti di modificarli in qualsiasi momento. La libreria Lucene utilizzata da Solr per la ricerca full-text impiega istantanee point-in-time che devono essere aggiornate regolarmente per garantire che i nuovi dettagli vengano presentati alle query. Solr, al contrario del formato dati agnostico JSON o XML, è indipendente dal formato dati.
Come utilizzare il motore di ricerca Solr in Java
Il client Java è necessario per connettersi al server Solr, quindi utilizzare il file org.apache.solr.client.solrjimpl. La classe che utilizza il protocollo HttpSolrServer è denominata HttpSolrServer. Questa classe utilizza Java Socket per comunicare con il server Solr. Quando crei un'applicazione server Solr, devi prima caricare le classi appropriate. In Java, ad esempio, è possibile accedere alla funzionalità di ricerca Solr utilizzando il file org.apache.solr.client.solrj.impl. La classe org.apache.solr.client.solrj.request è il componente della classe SolrServer. Questa classe crea una classe RequestHandler. Questo potente motore di ricerca ti consente di trovare facilmente le informazioni di cui hai bisogno. Per accedere al server Solr, utilizzare il client Java.
Solr contro Lucene
Quando si tratta dei progetti Apache Solr e Lucene, sono costituiti dagli stessi componenti. Apache Solr, d'altra parte, è un server autonomo, anche se con molte funzionalità avanzate. Apache Lucene, d'altra parte, è una soluzione basata su libreria Java che indicizza (memorizza) e ricerca i dati.
A causa della sua cache, Solr ha un vantaggio nel campo dei dati statici, che può facilitare il recupero dei risultati. I dati delle serie temporali vengono spesso elaborati da Elasticsearch, che utilizza i suoi filtri e le funzionalità di raggruppamento, oltre ai dati delle serie temporali.
Solr Vs Elasticsearch
Non esiste una risposta definitiva a questa domanda poiché dipende dalle esigenze e dalle preferenze individuali. Tuttavia, alcune differenze chiave tra Solr ed Elasticsearch includono:
-Solr si basa su un modello di database relazionale tradizionale, mentre Elasticsearch utilizza un approccio orientato ai documenti.
-Solr è in genere più veloce per l'indicizzazione e la ricerca di set di dati di grandi dimensioni, mentre Elasticsearch è generalmente più scalabile.
-Solr supporta funzionalità di query più avanzate come join e oggetti nidificati, mentre Elasticsearch ha una sintassi di query più semplice.
Esiste un'ampia comunità di contributori a entrambe le tecnologie ed è disponibile l'assistenza di esperti. Elasticsearch era precedentemente noto come Apache 2.0 ed era open source. A partire dal 2021 con il rilascio della versione 7.11, Elasticsearch sarà utilizzabile gratuitamente con la Server Side Public License. È destinato a ricerche di testo a livello aziendale che richiedono il recupero di informazioni e/o analisi. Le ricerche full-text sono possibili anche in Elasticsearch e possono essere letti documenti complessi come PDF e Word. Elasticsearch richiede più memoria heap rispetto a Solr (1 GB contro 512 MB), ma queste impostazioni predefinite possono essere modificate. La piattaforma Elasticsearch consente una maggiore automazione combinando il ribilanciamento del cluster con la pulizia dei dati, che di solito è manuale.
Lo sharding è un metodo di distribuzione dei dati su più server supportato da Solr ed Elastic. Sia Solr che ElasticSearch sono popolari database di motori di ricerca con comunità ampie e coinvolte e capacità simili. Elasticsearch è più user-friendly di Solr, più facile da scalare e ha migliori capacità di analisi e query. La libreria Apache Tika, che può essere utilizzata da entrambi i database, consente loro di eseguire ricerche full-text e leggere documenti ricchi.
Uso di Apache Solr
Poiché può indicizzare e cercare documenti e allegati e-mail, nonché indicizzare e cercare più siti Web, è uno strumento popolare per i siti Web e per la ricerca aziendale.
È una piattaforma di ricerca open source utilizzata per creare app di ricerca. Si basa sul popolare motore di ricerca full-text Lucene . Solr è una piattaforma cloud-native, altamente flessibile, pronta per le operazioni aziendali. Le query parallele sono state abilitate nella versione più recente di Solr, Solr 6.0, rilasciata nel 2016. La piattaforma Solr ci consente di ridimensionare, distribuire e gestire gli indici per applicazioni su larga scala (Big Data). Mentre lavori con Solr, non è necessario essere un programmatore con competenze Java. Invece di Lucene, fornisce un servizio molto semplice e facile da usare per la creazione di una casella di ricerca che include il completamento automatico.
I numerosi vantaggi di Apache Sol
Il motore di ricerca Apache Solr è un motore di ricerca popolare tra le piccole e grandi organizzazioni. Questo software è molto versatile e può essere utilizzato in una varietà di situazioni, tra cui l'analisi e il recupero dei dati. Solr è un servizio che offre funzionalità di ricerca aziendale, rendendolo la scelta ideale per la gestione di grandi quantità di dati.
Utile soluzione per database Nosql
Oggi sono disponibili molte utili soluzioni di database NoSQL . I database NoSQL sono spesso più scalabili e performanti rispetto ai tradizionali database relazionali. Di solito sono anche più flessibili, consentendo una modellazione dei dati e un'evoluzione dello schema più semplici. Alcuni database NoSQL popolari includono MongoDB, Cassandra e HBase.
I database NoSQL non saranno più utilizzati dagli sviluppatori in futuro. Il futuro è qui dove questi database saranno uno strumento comune per il potenziamento delle applicazioni più diffuse. Potresti non sapere che alcune applicazioni popolari vengono eseguite su database NoSQL e perché NoSQL è l'ideale per queste applicazioni. Nel 1996, Forbes è stata la prima pubblicazione economica a lanciare un sito web. Forbes ha migrato il suo servizio su MongoDB Atlas per soddisfare le esigenze dei suoi 140 milioni di utenti online. A causa dell'impatto della pandemia di COVID-19, la pubblicazione si è spostata su un'infrastruttura cloud ed è stata in grado di affrontare tempi difficili. BangDB è stato scelto da Accenture come database NoSQL per la sua applicazione di lead scoring.
Facebook Messenger viene eseguito sul database Cassandra NoSQL senza un singolo punto di errore, consentendogli di scalare le sue operazioni su più piattaforme. Bigtable è un componente di Google Mail che assiste Google Bigtable, un'azienda online che alimenta una varietà di transazioni di Google Mail. Il database di Espresso garantisce che tutte le applicazioni di LinkedIn funzionino normalmente. Scarica BangDB gratuitamente per vedere se è lo strumento giusto per te.
I vantaggi dei database Nosql
Molti database NoSQL possono essere utilizzati per archiviare e modellare dati strutturati, semi-strutturati e non strutturati in un unico database, rendendoli ideali per l'archiviazione e la modellazione di strutture e semantica dei dati. Possono funzionare meglio ed essere più stabili rispetto ai tradizionali database relazionali e possono essere più facili da implementare per gli sviluppatori. Con la crescente popolarità dei database NoSQL, è probabile che continuino a crescere in popolarità.
Mongodb »
MongoDB è un potente sistema di database orientato ai documenti. Ha una funzione di ricerca basata su indice che rende il recupero dei dati facile e veloce. MongoDB offre anche una funzione di scalabilità, che gli consente di gestire dati su larga scala.