
I diversi tipi di cluster di computer
Pubblicato: 2023-02-16In informatica, un cluster è un gruppo di sistemi informatici indipendenti che lavorano insieme in modo che, per molti aspetti, possano essere visti come un unico sistema. I cluster vengono generalmente distribuiti per migliorare le prestazioni e la disponibilità rispetto a quella di un singolo computer, pur essendo in genere molto più convenienti rispetto ai singoli computer di velocità o disponibilità comparabili. Esistono diversi tipi di cluster di computer, inclusi cluster di elaborazione ad alte prestazioni, cluster di computer utilizzati per scopi commerciali e cluster di archiviazione. In ogni tipo di cluster, i sistemi componenti lavorano insieme per eseguire un'attività o attività comuni. I cluster di calcolo ad alte prestazioni (HPC) vengono utilizzati per applicazioni scientifiche e ingegneristiche che richiedono una grande quantità di potenza di calcolo e/o archiviazione dei dati. Questi cluster sono in genere costituiti da un gruppo di computer di base, collegati da una rete locale veloce (LAN). I computer in un cluster HPC in genere eseguono lo stesso sistema operativo (OS) o uno simile e hanno componenti hardware uguali o simili. I cluster commerciali vengono utilizzati per eseguire applicazioni aziendali che richiedono un elevato grado di disponibilità e/o scalabilità. Questi cluster sono spesso costituiti da server che eseguono una varietà di sistemi operativi e hanno una varietà di componenti hardware. In molti casi, i server in un cluster commerciale sono anche connessi a una rete SAN (Storage Area Network) in modo che possano accedere agli archivi di dati comuni. I cluster di archiviazione vengono utilizzati per fornire un archivio di archiviazione centralizzato accessibile da un gruppo di computer. I cluster di archiviazione in genere sono costituiti da un gruppo di server di archiviazione connessi a una SAN. I server in un cluster di archiviazione di solito eseguono una varietà di sistemi operativi e hanno una varietà di componenti hardware.
Che cos'è un cluster mongodb frammentato e qual è lo scopo di connettersi a uno in MongoDB? Come mi connetto a uno o semplicemente mi connetto al localhost? La medaglia d'oro viene assegnata nel badge Noob 7461. Sono stati prodotti dieci distintivi d'argento e 23 distintivi di bronzo. Un cluster replicato è costituito da dieci server, uno per l'interfaccia mongos, tre per ogni set di repliche e uno per ogni set di repliche del server di configurazione. In un sistema di replica, un componente viene duplicato in modo che ci sia sempre un backup se qualcosa va storto. Tutti i frammenti devono essere repliche per poter essere prodotti.
Un cluster mongodb, ad esempio, viene comunemente utilizzato per descrivere un cluster frammentato in MongoDB. Un mongodb sharded svolge le seguenti funzioni: Ridimensionamento di letture e scritture da più nodi. Poiché ogni nodo non gestisce l'intero set di dati, puoi solo partizionare i dati in regioni nello shard.
Un cluster di database , come suggerisce il nome, è una raccolta di database che può essere eseguita da un'istanza di un server di database in esecuzione. Postgres, che significa database "predefinito" in PostgreSQL, verrà incluso come database predefinito in un cluster di database dopo che è stato creato.
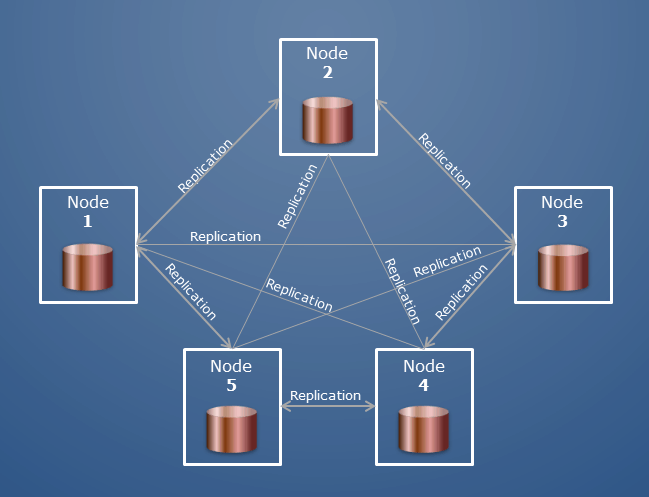
Un cluster MongoDB può anche essere definito "set di repliche" o "cluster frammentato". In un set di repliche, diversi server trasportano copie degli stessi dati. I nodi in un set di repliche sono in genere tre. Quando un'applicazione client esegue qualsiasi operazione su un nodo, tutte le letture e le scritture vengono inviate a quel nodo; se qualcosa va storto, due nodi secondari lo proteggono.
Cluster e database sono uguali?
Esistono più cluster di host che costituiscono un cluster. Gli host di un cluster sharded sono classificati in una varietà di ruoli. Un database è una raccolta di raccolte; in Oracle, sarebbe equivalente a un database e aschema.
Un cluster di database è una raccolta di server o istanze che connettono un database a un altro. Il clustering del database viene utilizzato dai server per una serie di motivi, i principali dei quali sono la ridondanza dei dati, il bilanciamento del carico, l'elevata disponibilità, il monitoraggio e l'automazione. Di conseguenza, se un computer si guasta, tutti i nostri dati saranno disponibili per gli altri, offrendoci il vantaggio della ridondanza dei dati. Con il clustering, c'è l'opportunità di automatizzare molti dei processi del database creando anche regole per identificare potenziali problemi. Nell'architettura cluster, tutte le richieste vengono instradate a un certo numero di computer, ognuno dei quali è in grado di gestire la richiesta e produrla per l'utente. Un cluster di failover o disponibilità elevata replica i server e riconfigura l'hardware per garantire la disponibilità del servizio. Questi tipi di cluster sono vantaggiosi per gli utenti di computer che si affidano completamente ai propri sistemi. L'obiettivo dei cluster ad alte prestazioni è aumentare la capacità della rete migliorando al tempo stesso le prestazioni.
In un sistema distribuito Hadoop, i nodi fungono da centri di archiviazione ed elaborazione dei dati. La distinzione principale tra un cluster e un server è che il cluster utilizza più nodi che comunicano tra loro per eseguire una serie di operazioni. Un cluster contiene un numero di nodi che eseguiranno una serie di operazioni. Il sistema distribuito Hadoop può supportare fino a 10.000 database. Risultati di query simili possono essere ottenuti quando i dati di più tabelle nello stesso database vengono combinati in una query da più database nello stesso cluster.
I vantaggi di Cluste
Utilizzando un cluster, puoi gestire facilmente più database fornendo un'archiviazione uniforme di tabelle e colonne per tutti. Ciò migliora le prestazioni e l'integrità dei dati e quindi rende il sistema più efficiente.
Dov'è il nome del cluster in MongoDB?
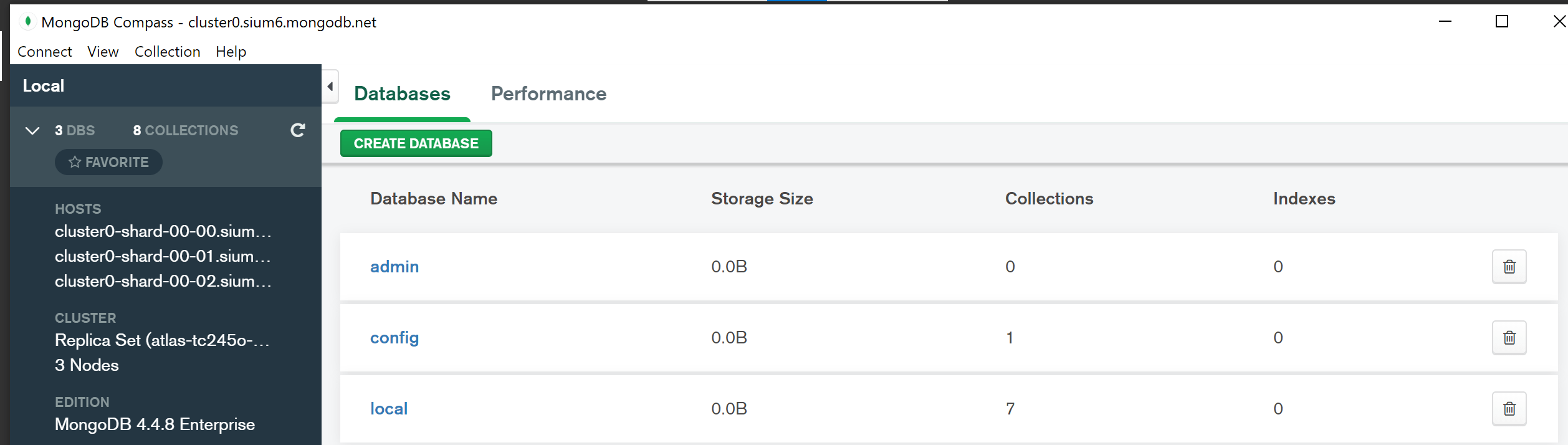
Non esiste una risposta fissa per questa domanda poiché il nome del cluster può essere trovato in posizioni diverse a seconda del tipo di cluster MongoDB utilizzato. Ad esempio, in un set di repliche il nome del cluster è in genere archiviato nella raccolta local.system.replset, mentre in un cluster frammentato si trova solitamente nella raccolta config.shards.
MongoDB Atlas è un'offerta NoSQL Database-as-a-Service MongoDB-as-a-Service disponibile nei cloud pubblici di Microsoft Azure, Google Cloud Platform e Amazon Web Services. Puoi creare un cluster MongoDB funzionante in pochi minuti utilizzando il tuo browser Web preferito facendo clic su un collegamento per configurarlo. Non è necessario installare software sulla workstation per connettersi al Web tramite esso e puoi utilizzare l'interfaccia Web per farlo. Quando i set di repliche MongoDB vengono utilizzati insieme a più server MongoDB, la ridondanza dei dati e l'elevata disponibilità sono garantite. Il cluster MongoDB ha una capacità di operazioni di lettura aggiuntiva, che gli consente di indirizzare i client a server aggiuntivi. In una replica, uno o più membri del set di repliche vengono replicati in modo asincrono dall'oplog del nodo primario ai secondari, consentendo al set di repliche di funzionare nonostante eventuali guasti dei suoi membri. In MongoDB, puoi eseguire ulteriori operazioni di lettura e scrittura oltre ai comandi di input e output standard.
Nella maggior parte dei casi, il nodo primario è l'origine di tutte le operazioni di lettura, ma è possibile configurare il routing ai secondari. Il rischio di dati potenzialmente obsoleti è maggiore quando il nodo più vicino è un nodo secondario. Affinché la scrittura si propaghi correttamente nel cluster, dovrai includere le opzioni per la scrittura dei dati in un set di repliche MongoDB. Come parte di questo processo, è necessario aggiungere a insert una proprietà relativa al problema di scrittura. Quando viene ricevuta una richiesta di scrittura, al cluster viene richiesto di riconoscere che ha avuto successo nella stragrande maggioranza dei nodi che trasportano dati. La configurazione di un cluster frammentato consente di configurarlo anche come set di repliche. Un set di repliche contiene processi mongod sia primari che secondari. Se il master fallisce, si raccomanda che il numero totale di questi processi sia dispari per garantire che la maggior parte venga eseguita.
I cluster MongoDB , come suggerisce il nome, sono cluster di nodi che lavorano insieme per archiviare e gestire i dati. Quando crei un cluster MongoDB, specifichi quanti nodi includere e per cosa devono essere configurati. Puoi connettere la tua applicazione al tuo cluster MongoDB con Node una volta creato. MongoDB Compass può essere pensato come un driver per la libreria MongoDB JS o un driver PyMongo per MongoDB. Il vantaggio principale di connettere la tua applicazione a un cluster è che può leggere e scrivere dati su di esso. Con MongoDB Compass, puoi esplorare, modificare e visualizzare i tuoi dati in vari modi. Un esempio di come puoi visualizzare i tuoi dati può essere trovato in una griglia, che ti consente di osservare come i dati cambiano nel tempo e chi sta distribuendo i dati nel tuo cluster.
Dov'è il cluster in MongoDB Atlas?
Non esiste una risposta definitiva a questa domanda poiché la posizione di un cluster in MongoDB Atlas può variare a seconda di una serie di fattori, tra cui la regione geografica in cui si trova e le esigenze specifiche dell'applicazione che sta alimentando. Tuttavia, in generale, è possibile trovare un cluster in MongoDB Atlas nella sezione "Cluster" della console MongoDB Atlas.
Un cluster può essere un set di repliche o un set partizionato. Il numero totale di nodi di ciascun progetto è vincolato da un vincolo specifico basato sulla loro gamma di funzioni tra le regioni. Ogni progetto Atlas può distribuire fino a 25 database. Si prega di contattare gli amministratori del database per qualsiasi domanda sul limite di distribuzione del database. TLS versione 1.2 è la versione TLS predefinita per i cluster creati dopo il 1° luglio 2020.

Cos'è un cluster in MongoDB
In MongoDB, un cluster è un gruppo di server di database che conservano copie degli stessi dati. Ogni server in un cluster viene definito nodo. Un cluster può avere uno o più nodi.
A cosa serve il clustering del database? Il processo di connessione di più server o istanze a un singolo database viene definito connessione SQL. In MongoDB, un cluster è un set di repliche o un cluster frammentato, a seconda del tipo di MongoDB. Esaminerò in modo più approfondito ciascuno degli aspetti distinti di questi cluster nei paragrafi seguenti. A causa del bilanciamento del carico e del numero di macchine di MongoDB, ha un alto livello di disponibilità. Un cluster può essere utilizzato per automatizzare molti processi di database consentendo anche la creazione di regole per segnalare potenziali problemi. Un database MongoDB può essere suddiviso in due tipi: set di repliche e cluster di partizionamento orizzontale.
I dati vengono archiviati su più macchine in uno Shard. Il metodo di MongoDB per fornire la scalabilità dei dati si basa su questo. Questo riduce la quantità di tempo necessaria per gestire grandi quantità di dati. A causa della quantità di dati forniti dalle repliche, anche le applicazioni distribuite possono trarne vantaggio.
Possono verificarsi problemi di prestazioni e conflitti di dati se più progetti Atlas vengono distribuiti nello stesso cluster. Atlas consiglia di utilizzare un solo cluster gratuito per progetto Atlas. Un buon strumento di clustering dei dati è richiesto in un'ampia gamma di applicazioni di analisi dei dati e di data mining. Per evitare potenziali problemi di prestazioni e conflitti di dati nei progetti Atlas, Atlas consiglia di utilizzare un solo cluster gratuito per progetto.
Architettura del cluster MongoDB
Un cluster MongoDB è un gruppo di server MongoDB che lavorano insieme per conservare i tuoi dati. Ogni server in un cluster è chiamato nodo. Un cluster può avere qualsiasi numero di nodi. Un cluster è costituito da un set di repliche, ovvero un gruppo di nodi ognuno dei quali dispone di una copia dei dati. Un set di repliche ha almeno tre nodi, quindi se un nodo diventa inattivo, i tuoi dati sono ancora disponibili.
L'architettura dei set di repliche è un fattore importante per la capacità e la capacità di MongoDB. I cluster MongoDB sono in genere distribuiti in tre repliche di nodi. Il ripristino del database dopo un disastro deve essere costantemente stabile, soprattutto in seguito. Uno dei modi migliori per distribuire un cluster frammentato consiste nell'utilizzare una strategia di replica. I dati contenuti nelle Shard Key devono essere distribuiti allo stesso modo. È necessario ridimensionare il database orizzontalmente e ridurre il numero di operazioni che possono essere eseguite su una singola istanza. Con pochi shard, le operazioni di lettura e scrittura possono diventare lente a causa del fatto che il numero di shard limita il numero di operazioni.
Ogni pezzo di dati in uno Shard è costituito da un sottoinsieme di quel pezzo basato su un insieme specifico di criteri. È normale che il numero minimo di shard richiesto per ottenere un significato di sharding sia due. Le query di raccolta a dispersione devono essere utilizzate solo se possono essere utilizzate contemporaneamente tra loro su tutti gli shard. Quando si seleziona un cluster, è fondamentale avere almeno sette membri votanti affinché il processo elettorale sia il più semplice possibile. Se hai solo sette o meno membri votanti ma un numero uguale di membri, è necessario utilizzare l'arbitro. Gli arbitri non archiviano copie dei dati, con conseguente riduzione delle risorse necessarie per elaborare i dati. L'utilizzo del nome host DNS logico anziché dell'indirizzo IP è preferibile durante la configurazione dei membri del set di repliche o dei membri del cluster partizionati. Poiché alcune connessioni di set di repliche di gruppo di driver sono basate su nomi di set di repliche, questi nomi devono essere utilizzati separatamente per i set. La distribuzione geografica dei nodi del set di repliche è ideale per affrontare la ridondanza ridondante e garantire la tolleranza agli errori se uno dei data center è assente.
Nome del cluster MongoDB
Un cluster MongoDB è un gruppo di server MongoDB che lavorano insieme per fornire alta disponibilità e scalabilità. Un cluster ha in genere un server primario che funge da server master e uno o più server secondari che fungono da slave. Il server primario contiene i dati e i server secondari copiano i dati dal server primario.
I programmi di database orientati ai documenti vengono creati per l'archiviazione di volumi elevati con l'aiuto di MongoDB, un programma multipiattaforma. MongoDB, un programma di database NoSQL, è classificato come tale perché utilizza documenti in stile JSON con schemi opzionali. Puoi migliorare le prestazioni installando il tuo database nello stesso data center delle altre tue risorse DigitalOcean. La regione ha uno o più data center e ognuno ha la propria rete VPC. È possibile selezionare il tipo di macchina, il numero e la dimensione dei nodi del database. In altre parole, puoi aggiungere fino a due nodi in standby al tuo cluster. Aggiungi il nome di un progetto, rendilo completo e usa tutti i tag che vuoi usare su di esso quando lo crei. Il completamento di un cluster può richiedere fino a cinque minuti.
Il potere di Mongodb Atlas Cluste
MongoDB Atlas Cluster è una soluzione NoSQL database-as-a-service nel cloud pubblico che viene eseguita in MongoDB. È una piattaforma dati robusta e scalabile che consente di creare e distribuire rapidamente applicazioni. Utilizzando MongoDB Atlas Cluster, puoi connetterti in modo sicuro a MongoDB da qualsiasi luogo nel mondo.
Come creare cluster in MongoDB
Utilizzare i seguenti passaggi per creare un cluster in MongoDB:
1. Scegli una topologia di distribuzione.
2. Selezionare il tipo di set di repliche che si desidera distribuire.
3. Scegliere il numero di set di repliche che si desidera distribuire.
4. Configurare i set di repliche.
5. Connettersi al router mongos.
6. Configurare la chiave di partizione.
7. Aggiunge gli shard al cluster.
8. Verificare che il cluster sia operativo.
MongoDB Atlas è un livello gratuito di MongoDB, che è il servizio di database cloud completamente gestito di MongoDB. Il servizio è progettato per i carichi di lavoro aziendali e per i cluster globali . Non è necessario creare un account con Amazon Web Services (AWS), Google Cloud Platform o Microsoft Azure. Ti verrà richiesto di creare un account amministratore per accedere al servizio. Per accedere al servizio, un cluster deve essere collegato a un indirizzo IP. Le impostazioni di sicurezza predefinite di MongoDB Atlas impediscono tutte le connessioni esterne. La tua password non deve contenere caratteri speciali e solo caratteri alfanumerici per facilitare la connessione a Studio 3T. Quando si crea una stringa di connessione per MongoDB, è necessario codificare i caratteri speciali. Nel passaggio 1, scegli Java dall'elenco a discesa DRIVER e quindi dall'elenco a discesa VERSIONE. Se selezioni il driver e la versione, il servizio aggiornerà automaticamente la stringa di connessione nel passaggio 2.
MongoDB Clustering: un'ottima opzione per un throughput a domanda elevata
Utilizzando il clustering MongoDB , puoi soddisfare i requisiti di velocità effettiva, disponibilità e velocità effettiva elevate per ambienti di grandi dimensioni. I cluster MongoDB possono essere configurati per supportare un'ampia gamma di tipi di set di repliche MongoDB, da semplici configurazioni a nodo singolo a configurazioni multinodo altamente disponibili.
Esercitazione sul cluster MongoDB
Un cluster MongoDB è un gruppo di server MongoDB che lavorano insieme per conservare i tuoi dati. Un cluster MongoDB può essere piccolo come un singolo server o grande come centinaia di server. Quando crei un cluster MongoDB, specifichi il numero di server (nodi) che desideri nel cluster. Ogni nodo in un cluster MongoDB memorizza un sottoinsieme dei tuoi dati. I cluster MongoDB sono progettati per essere scalabili e per fornire alta disponibilità. Puoi aggiungere nodi a un cluster in qualsiasi momento per aumentarne la capacità o per sostituire un nodo guasto. Quando rimuovi un nodo da un cluster, gli altri nodi ridistribuiscono i dati dal nodo rimosso in modo che i dati siano ancora distribuiti uniformemente nel cluster.
La guida facile di Hevo al clustering di MongoDB è il primo passo. Quando un database è troppo piccolo o troppo lento per eseguire un sistema, le operazioni di un'organizzazione continuano. MongoDB ha numerose funzionalità avanzate progettate per il cloud, come lo sharding e la replica. MongoDB consente di archiviare più copie degli stessi dati, rendendoli estremamente accessibili. Se un server si guasta, i dati dell'altro possono essere recuperati immediatamente. Puoi automatizzare, semplificare e arricchire il processo di replica dei dati utilizzando Hevo Data. La replica dei dati è semplice e indolore da usare quando hai accesso alla nostra prova gratuita di 14 giorni.
Per configurare i cluster MongoDB, devi prima installare tutti e tre i componenti necessari. Con la piattaforma automatizzata e senza codice di Hevo, puoi tenere traccia di tutto ciò che devi fare per un'esperienza di replica dei dati fluida. Per garantire la massima disponibilità, devono essere presenti più server di configurazione o router. Quando il router determina in quale shard sono ospitati i dati, invia le richieste al cluster appropriato. Nel processo di creazione dei cluster MongoDB, saranno necessari i seguenti passaggi per aggiungervi gli shard. In una configurazione in cluster, la porta 27018 viene utilizzata come predefinita per i server shard. Significa che è un server shard piuttosto che un server di configurazione.