
I diversi modi per archiviare i dati del grafico su disco
Pubblicato: 2022-11-22I database a grafo sono un tipo di database NoSQL che utilizza strutture a grafo per query semantiche con nodi, bordi e proprietà per rappresentare e archiviare i dati. I database a grafo sono diversi dagli altri database NoSQL in quanto memorizzano i propri dati in un formato grafico. Ciò significa che i dati sono rappresentati dai nodi (le entità) e dalle relazioni tra questi nodi (i bordi). Ciò consente molta più flessibilità e interrogazioni più semplici rispetto ai database tradizionali. Esistono diversi modi in cui i database a grafo possono archiviare i propri dati su disco. Il più comune è utilizzare un elenco di adiacenza. Qui è dove ogni nodo ha un elenco di tutti gli altri nodi a cui è connesso. Questo è il modo più semplice per memorizzare i dati del grafico, ma può essere inefficiente se il grafico è molto grande. Un altro modo per memorizzare i dati del grafico consiste nell'utilizzare una matrice di adiacenza. È qui che viene utilizzata una matrice per rappresentare i bordi tra i nodi. Questo è più efficiente per i grafici più grandi, ma può essere più difficile da interrogare. L'ultimo modo per memorizzare i dati del grafico consiste nell'utilizzare un grafico delle proprietà. Qui è dove ogni nodo ha un insieme di proprietà (attributi) e i bordi tra i nodi sono definiti da quelle proprietà. Questo è il modo più flessibile per archiviare i dati del grafico, ma può essere più difficile eseguire query. I database a grafo sono un potente strumento per l'analisi dei dati e possono essere utilizzati per una varietà di applicazioni. Sono particolarmente adatti per applicazioni che richiedono query complesse o che necessitano di archiviare i dati in modo flessibile.
Quali sono i metodi utilizzati da questi documenti per memorizzare il grafico nel file system? Non sono sicuro di cosa debba essere caricato in memoria e di quali ID richiedano specificamente. Se sono necessarie ulteriori ricerche, sottolineare le caratteristiche chiave da cercare potrebbe aiutare a portare questo a una comprensione più chiara.
Si tratta di una tecnologia per la gestione di grandi raccolte di dati strutturati, semi-strutturati o non strutturati utilizzando sia SQL che NoSQL ("non solo SQL"). Consente alle organizzazioni di ottenere una migliore comprensione dei loro big data e dell'analisi dei social media integrando e analizzando i dati provenienti da una varietà di fonti.
I sistemi di database a grafo in genere memorizzano i dati in una struttura simile agli elenchi collegati in termini di struttura dei dati. In essi sono memorizzati collegamenti diretti ai dati anziché solo catene di dati.
Utilizzando il tuo tipo di dati come identificatore primario, definisci un sistema di tipi per la tua API e utilizzalo per eseguire query utilizzando il linguaggio di query GraphQL . Poiché GraphQL è supportato da codice e dati esistenti, non richiede alcun database o motore di archiviazione speciale.
I dati del grafico vengono archiviati in file store, che contengono informazioni su una parte specifica del grafico, ad esempio nodi, relazioni, etichette e proprietà. Come affermato in precedenza, i dati sono divisi in questo modo per agevolare l'attraversamento di grafici altamente performanti.
Come vengono archiviati i dati in Graph Nosql?
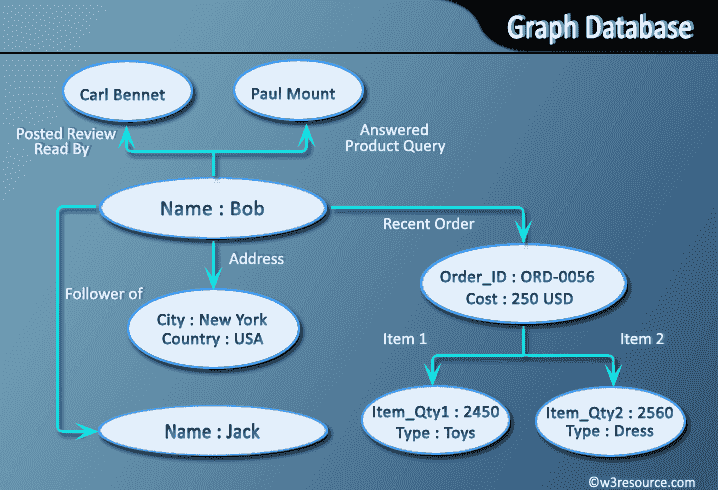
I database a grafo sono un tipo di database NoSQL che utilizza strutture a grafo per query semantiche con nodi, bordi e proprietà per rappresentare e archiviare i dati.
Il database grafico (noto anche come NoSQL o SQL) è un tipo di database in grado di memorizzare grandi raccolte di dati strutturati, semi-strutturati e non strutturati. Aiuta le aziende a ottenere l'accesso, l'integrazione e l'analisi dei dati da una varietà di fonti, consentendo loro di analizzare i propri social media e l'analisi dei big data. Non ha bisogno di essere ridefinito prima di aggiungere nuovi dati a un database NoSQL che non ha bisogno di essere ridefinito. Gli standard W3C utilizzati per rappresentare i dati sul Web sono utilizzati nei database a grafo. L'utilizzo di pratiche standard semplifica l'integrazione, lo scambio e la mappatura dei dati tra set di dati. Con l'inferenza, le organizzazioni possono aumentare la potenza del loro database grafico aggiungendo nuove conoscenze e consentendo loro di vedere tutti i loro dati in un modo molto più pertinente. Le organizzazioni possono anche trarre vantaggio dalla tecnologia semantica e da NoSQL nell'area dell'analisi dei social media.
I database a grafo esistono da un po' di tempo, ma stanno diventando sempre più popolari. La loro memorizzazione dei dati è unica e potrebbero essere utili per alcuni utenti. È utile per la risoluzione dei problemi in cui i database tradizionali hanno fallito, come i documenti e l'assegnazione di priorità alle relazioni tra entità.
In termini di database a grafo, MongoDB è una buona scelta. Poiché dispone di un cluster MongoDB Atlas gratuito, semplificare al massimo l'installazione e l'utilizzo di un database a grafo.
Database a grafo: il futuro dell'archiviazione dei dati
I dati vengono memorizzati in forma di grafico da nodi (ad esempio persone, post, commenti), relazioni (ad esempio Mi piace, condivisioni) e proprietà (ad esempio timestamp). Questi tipi di strutture consentono una visualizzazione più semplice dei dati e semplificano le associazioni tra entità. I database a grafo possono anche essere utilizzati per archiviare enormi quantità di dati fortemente interconnessi. Le relazioni tra i dati sono prioritarie al fine di facilitare una facile visualizzazione.
I database a grafo, come database autonomo, sono attualmente disponibili solo nei formati NoSQL. La rappresentazione grafica, d'altra parte, è disponibile in MongoDB tramite la sua funzione $graphLookup. Significa anche che puoi guardare i dati da qualsiasi posizione senza dover ricominciare da capo.
Come viene memorizzato il grafico Db?
I database a grafo memorizzano i dati in un grafico, che è una raccolta di nodi e spigoli. I nodi rappresentano entità come persone, luoghi o cose e i bordi rappresentano le relazioni tra di loro. Ad esempio, in un social network, i nodi potrebbero rappresentare le persone e gli spigoli potrebbero rappresentare le relazioni tra loro (ad esempio, amici, famiglia, colleghi di lavoro, ecc.).
I database grafici nativi stanno guadagnando terreno come valida alternativa a NoSQL e ai database relazionali sul mercato. I database grafici nativi dovrebbero avere una vasta gamma di funzioni, secondo la teoria del design, ma Neo4j sembra essere il più popolare al momento. Tutti i bordi contengono l'origine e la destinazione di una riga del bordo (relazione). Avere un indice ti consente di aumentare la dimensione dei tuoi dati riducendo al contempo la quantità di tempo che dedichi alla scrittura. Per risolvere questi problemi, utilizziamo un modello di archiviazione grafico nativo che è O(log(n). In ogni record viene visualizzato l'ID di relazione di un nodo (first_rid). Edge A, ad esempio, è legato a entrambi i nodi 1.
In questo caso, sarà necessario aggiungere un nuovo nodo 4 e un nuovo nodo 2. Il first_rid del nodo 4, D, è memorizzato nell'archivio delle relazioni con un nuovo record [Figura 4 (d)]. Il codice del server ha due parametri: un src e un dst. Il modello di archiviazione del grafico nella Figura 4 (a) è stato aggiornato. Un BLOB continuo di dati viene archiviato in Native-Graph Physical Storage tramite mmap. Di conseguenza, puoi leggere/scrivere il record direttamente dalla costante ID * record_size nel BLOB continuo. Mmap è uno strumento utile perché impedisce la visualizzazione di copie doppie sia sul sistema operativo che sull'applicazione.
È possibile trovare le informazioni in_use, first_rid, il primo ID proprietà e il primo ID etichetta nel record del nodo di Neo4j. nodi. l'ID proprietà e l'ID etichetta sono due puntatori alle proprietà e alle etichette del nodo. Allo stesso modo, un altro metodo viene utilizzato per massimizzare l'utilità di un record di relazione per l'intero periodo di tempo.
Poiché elimina la necessità di apprendere un nuovo linguaggio di query per ogni API, GraphQL è uno strumento potente. L'utilizzo dello stesso linguaggio di query con ogni API è la soluzione migliore. In questo modo, sarai in grado di sviluppare e mantenere le tue applicazioni più facilmente. Lo schema GraphQL definisce la struttura dei dati in un database di rete. I nodi di dati in questo schema sono rappresentati dalle relazioni tra loro. Per questo motivo, è possibile accedere alla struttura dei dati in un normale database relazionale solo per inferenza. Le API che utilizzano GraphQL non sono database, ma piuttosto linguaggi di query. Può essere integrato con una varietà di tipi di database, così come nessun database, quindi può essere utilizzato ovunque siano presenti database. A causa della facilità con cui viene utilizzato GraphQL, elimina la necessità per un'API di apprendere una nuova lingua per ogni query. Poiché consente un controllo più granulare dei dati, l'uso di GraphQL è un'ottima scelta per i database di rete. Questo è particolarmente importante perché aumenta il numero di opzioni e la flessibilità con cui i dati possono essere personalizzati.
In che modo Neo4j memorizza i dati del disco?
Neo4j memorizza i dati del disco in un formato proprietario ottimizzato per letture e scritture veloci. I dati vengono memorizzati in una serie di file, ognuno dei quali contiene una certa quantità di dati. Quando un nuovo dato viene aggiunto al database, viene memorizzato in un nuovo file. Quando un dato viene eliminato dal database, il file viene eliminato.
I file relativi ai dati verranno inseriti nella directory dei dati Neo4j se sono inseriti nel tipo di file data/databases/graph.db (v3.x+). Un campo è contenuto in una chiave o in un valore. Se una stringa o un array non rientra nei blocchi 8B, avrà un puntatore a un record nell'archivio di stringhe/array (128B). I dati del disco sono organizzati in tutti i relativi record di dimensioni fisse in un elenco collegato. Le proprietà vengono archiviate come elenchi collegati di record, ciascuno contenente una chiave e un valore e puntando alla proprietà successiva. Puoi immaginare questo come esempio: un calcolo dello spazio su disco. Lo stato iniziale di questo scenario.
Il conteggio dei nodi è 4M. Ogni nodo ha tre (12) proprietà distinte. Una relazione si forma sotto forma di due o più altre relazioni. Ogni relazione ha due proprietà (M). Ciò corrisponde alle seguenti dimensioni del disco. Il nodo 4.000.x15B ha una capacità di memoria di 600.000 MB.
Dove memorizza i dati il grafico?
Il grafico memorizza i dati in un database.
Viene utilizzato in un modo che i database relazionali non possono eseguire per rappresentare e archiviare i dati. Nel grafico delle proprietà, i dati sono collegati all'analisi e alle query, mentre nel grafico RDF è l'integrazione dei dati. Esistono due tipi di grafici: quelli costituiti da punti (vertici) e quelli che implicano connessioni tra tali punti. Grafici e database grafici, oltre a rappresentare le relazioni tra i dati, vengono utilizzati per creare modelli grafici. Questi sistemi sono in grado di eseguire query e applicare algoritmi grafici per identificare modelli, percorsi, comunità, influencer, errori a punto singolo e altre relazioni. Le capacità dei grafici nell'analisi includono la loro capacità di fornire approfondimenti, collegare fonti di dati disparate e generare approfondimenti. I database a grafo hanno una pletora di funzionalità che li rendono estremamente versatili e potenti.
I grafici possono essere utilizzati in vari modi perché enfatizzano la relazione tra i dati. L'analisi dei grafici può essere utilizzata per indagare su social network, reti di comunicazione, siti Web, traffico e utilizzo, nonché transazioni e conti finanziari. I database a grafo possono essere utilizzati per analizzare un'ampia gamma di social network, ma in genere vengono utilizzati per analizzare i grafici. È possibile utilizzare grafici creati da transazioni tra entità o entità che condividono informazioni. L'analisi dei grafici può essere utilizzata per identificare modelli naturali piuttosto che modelli di bot. I database a grafo sono diventati uno strumento efficace per rilevare le frodi nel settore finanziario. Il metodo più comune per rilevare le frodi, l'identificazione del modello, è spesso la prima linea di difesa.
Il modello di acquisto previsto di un utente è influenzato da fattori quali la posizione, la frequenza e il tipo di negozio. La capacità dell'analisi grafica di comprendere i modelli tra i nodi non è seconda a nessuno. A causa della maggiore potenza e dimensione dei dati, i database a grafo si sono evoluti. L'apprendimento automatico viene in genere utilizzato per rilevare le frodi, ma l'analisi dei grafici può integrare questo sforzo per renderlo più accurato ed efficiente. Il database convergente di Oracle è progettato per gestire ambienti multimodello, multicarico di lavoro e multitenant.
I grafici offrono una miriade di vantaggi oltre alla loro convenienza. Ci sono diversi vantaggi nell'usare un grafico. Un altro vantaggio del calcolo grafico è che un grafico può essere calcolato sulla base di una varietà di fattori. I grafici possono essere memorizzati in vari modi. Uno dei modi più semplici per farlo è mantenere un vettore per ogni spigolo. La situazione può diventare molto inefficiente se ciò non viene fatto correttamente. Per memorizzare un grafico, è anche una buona idea tenere una coppia per ogni spigolo. Questo è più efficace, ma tenere traccia di quali spigoli sono correlati può essere difficile. È anche possibile memorizzare un grafico assegnando una struttura a ciascun bordo.

I pro ei contro dei database a grafo
Le relazioni possono essere rappresentate implicitamente nei database a grafo, il che presenta un vantaggio significativo durante l'archiviazione dei dati. Ti permette di trovare i dati che cerchi in maniera diretta. Anche i database a grafo possono diventare più difficili da manipolare se sono anch'essi vulnerabili a questo tipo di vulnerabilità.
I database a grafo sono la scelta migliore per archiviare dati correlati a qualcosa. Questa categoria può essere applicata a dati provenienti da tutte le fonti, compresi i social network e la ricerca scientifica.
Archiviazione del database grafico
L'archiviazione di database a grafo è un tipo di archiviazione di database che utilizza una struttura di dati a grafo per archiviare i dati. Questo tipo di archiviazione è adatto per l'archiviazione di dati che hanno molte relazioni tra elementi di dati. Ad esempio, un social network potrebbe utilizzare un sistema di archiviazione di database a grafo per archiviare informazioni sugli utenti e le loro relazioni con altri utenti.
Le differenze tra un database a grafo e un database relazionale risiedono principalmente nei loro metodi di memorizzazione delle relazioni tra entità. Poiché non esiste una struttura predefinita per i dati nei database a grafo, ogni record deve essere esaminato separatamente durante una query. Una colonna in questo sistema differisce da una tabella in quanto può essere molto flessibile quando si tratta di struttura e tipi di dati. Se si intende recuperare i dati frequentemente, il database grafico è l'opzione migliore ed è stato ottimizzato per il recupero dei dati. Se i tuoi dati sono di natura transazionale, è altamente improbabile che tu preferisca utilizzare un database grafico. I dati possono essere archiviati in modo più efficace e talvolta possono essere necessarie analisi meno complesse. Un database grafico, d'altra parte, può essere flessibile e più astratto di un database schema.
Se il tuo modello di dati è incoerente e richiede modifiche frequenti, potresti prendere in considerazione l'utilizzo di un database a grafo. Con i database a grafo, puoi attraversare le relazioni quando hai un punto specifico da cui iniziare o almeno un insieme di punti da seguire. Un database a grafo può essere un potente strumento nel campo della gestione dei dati interconnessi. Se non si desidera utilizzare database a grafo, utilizzare invece identificatori semplici (chiave) per restituire un singolo nodo. I database a grafo non sono l'opzione migliore se è necessario archiviare set di dati estremamente grandi, come BLOB e CLOB. Tuttavia, se fosse necessario connettere questi attributi ad altre entità nel database, un database a grafo potrebbe essere più vantaggioso di un database.
I grafici sono più adatti delle tabelle per rappresentare le relazioni tra i dati nei database relazionali perché le tabelle vengono utilizzate per archiviare i dati. Il grafico rappresenta sia i dati che le relazioni, con i vertici che rappresentano gli oggetti e i bordi che rappresentano le relazioni tra di essi. I database a grafo, a differenza dei database relazionali, sono strutturati nel loro insieme, con le relazioni al centro.
I database a grafo possono gestire grandi quantità di dati interconnessi in un tempo significativo grazie al loro elevato livello di connettività. Le rappresentazioni chiare e gestibili delle relazioni dei grafici li rendono facili da capire. Inoltre, la flessibilità e l'agilità dei grafici li rendono ideali per un'ampia gamma di dati.
Uno svantaggio di un database a grafo è che non dispone di un linguaggio di query uniforme. Di conseguenza, può essere difficile per gli utenti comprendere e utilizzare il database. Inoltre, la rappresentazione delle relazioni può essere difficile da comprendere.
I database a grafo utilizzano una serie di vantaggi e svantaggi, ma i loro punti di forza sono chiaramente maggiori dei loro punti deboli. Di conseguenza, è una buona scelta per i sistemi che devono presentare dati altamente interconnessi in modo chiaro e gestibile.
La differenza tra database a grafo e Big Data
C'è un malinteso comune che i database a grafo e i big data siano la stessa cosa. In un database a grafo, non ci sono limiti al modo in cui i dati possono essere archiviati in blocchi. Poiché i nodi e le relazioni vengono utilizzati per archiviare i dati, può gestire insiemi di dati più piccoli in modo più efficiente. Sebbene i database a grafo siano ancora in uso oggi, sono più efficienti dei tradizionali database relazionali in termini di gestione di grandi set di dati.
Memorizzazione del grafico nel database relazionale
Esistono molti modi per archiviare un grafico in un database relazionale. Un modo consiste nell'archiviare i bordi del grafico come record in una tabella, con ogni record contenente gli ID dei due vertici che il bordo connette. Un altro modo è memorizzare i bordi del grafico come record in una tabella, con ogni record contenente l'ID del vertice in cui inizia il bordo, l'ID del vertice in cui termina il bordo e il peso del bordo.
È una struttura dati composta da nodi e spigoli. È comune trovare spigoli che indicano una relazione tra due nodi. Le relazioni tra i nodi sono gli argomenti di queste relazioni nel database. Le tabelle possono visualizzare questa struttura in vari modi. A causa della sua crescita, il numero di celle contenenti valori NULL aumenterà. Le tabelle sparse sono semplici da implementare ma non così efficienti come molte entità in un singolo sistema. Le operazioni possono essere bloccate o ritardate in alcuni casi e le migrazioni possono essere dolorose.
La tabella satellite prende il nome dalla tabella sparsa che abbiamo visto prima. La tabella satellite contiene una varietà di tabelle con tabelle separate per ogni tipo di entità. Poiché i dati sono distribuiti su più tabelle, la lettura e la scrittura non sono così congestionate come nella progettazione di tabelle sparse. L'impatto delle migrazioni è cresciuto, ma la sua distribuzione è diminuita. NoSQL ti consente di mangiare la torta e di archiviare informazioni. Non c'è niente come RDS e non c'è niente come il linguaggio di query senza schema che ti consente di trattare i tuoi dati come tali. Nel tuo DB, i dati normali sono normalizzati.
Nella maggior parte dei casi, le migrazioni ai dati avverranno a livello di database. Un database NoSQL è generalmente più scalabile di un database relazionale, ma questo vantaggio si realizza solo quando è coinvolto un numero elevato di set di dati. La selezione di una buona chiave di partizione dovrebbe essere effettuata in anticipo. DynamoDB è destinato agli aggiornamenti in batch con un limite di throughput, mentre MongoDB consente la riduzione delle mappe del database.
Il vantaggio di archiviare le relazioni a livello di record individuale
Le relazioni possono essere memorizzate a livello individuale, aumentandone l'efficienza. Quando i database accedono a un record in modo più tempestivo, non hanno bisogno di cercarlo nelle tabelle.
I database grafici memorizzano i dati
I database a grafo memorizzano i dati come un grafico, con i dati rappresentati come nodi e spigoli. Ciò consente un'interrogazione più flessibile ed efficiente dei dati, nonché un'analisi dei dati più potente.
I database a grafo sono pensati per essere utilizzati da utenti che dispongono di dati altamente interconnessi. I veri grafici, i triple store e i database convenzionali sono i tre tipi di database a grafo. Un database grafico di Neo4j può aiutare le organizzazioni a gestire meglio i propri dati. Consente inoltre alle organizzazioni di evolvere in modo rapido e semplice i modelli di intelligenza artificiale e machine learning. È ideale per situazioni in cui gli elementi devono essere collegati contemporaneamente, è possibile accedervi in pochi secondi e può eseguire query su milioni di relazioni contemporaneamente. Poiché i nodi fisicamente collegati nel database sono collegati tra loro, l'accesso alle relazioni è semplice quanto i dati stessi. Non è possibile trovare un'unica soluzione per ogni tipo di database a grafo.
L'obiettivo dei database a grafo è elaborare grandi reti dinamiche di relazioni con modelli di dati complessi. Questi sistemi, oltre a chatbot, sistemi conversazionali, algoritmi di raccomandazione, applicazioni di ottimizzazione, routing e mappe, sono necessari per la gestione e l'intelligence dei dati. Quando un'applicazione è configurata per funzionare su un database grafico, il suo valore sale alle stelle.
Molte persone usano i database a grafo per una serie di motivi. Un primo vantaggio di questi sistemi è che possono memorizzare dati complessi e semplici da interrogare. Inoltre, sono estremamente versatili nell'archiviazione dei dati che sono stati collegati. Sono anche adattabili agli ambienti mutevoli. I fattori elencati di seguito dovrebbero essere tutti considerati quando si seleziona un database.
La popolarità dei database a grafo è il risultato di una varietà di fattori.
Un database grafico consente agli utenti di accedere facilmente a grandi quantità di dati complessi. Questo è importante perché i dati complessi sono spesso difficili da leggere. I database a grafo sono adatti anche per l'archiviazione di dati connessi. Le connettività tra i nodi sono spesso fondamentali per il successo di un nodo. I database a grafo possono anche essere molto efficienti in termini di scala. A questo proposito, è possibile memorizzare una grande quantità di dati senza compromettere le prestazioni.
In generale, i dati archiviati nei database a grafo sono una buona scelta per archiviare informazioni complesse. È semplice da usare e fornisce una rappresentazione chiara e di facile lettura dei dati. Costituiscono data center eccellenti perché possono essere connessi e archiviare dati. Infine, hanno la capacità di scalare.
Il database Graph può archiviare documenti?
Invece di tabelle o documenti, i nodi e le relazioni vengono archiviati in database a grafo. I dati possono essere archiviati nello stesso modo in cui abbozzeresti le tue idee su una lavagna.
I vantaggi dei database a grafo
I database a grafo stanno diventando sempre più popolari perché offrono numerosi vantaggi rispetto ai database tradizionali. I database a grafo sono più efficienti quando nel database sono presenti chiavi esterne e set di dati di grandi dimensioni. Inoltre, sono più facili da interrogare in modo grafico e sono adatti per applicazioni di analisi dei dati in tempo reale.
Casi d'uso del database grafico Database grafici
Esistono molti casi d'uso per i database a grafo, inclusi social network, rilevamento delle frodi e motori di raccomandazione. Le applicazioni di social networking possono utilizzare database a grafo per modellare e interrogare le relazioni tra persone, luoghi e cose. Le applicazioni di rilevamento delle frodi possono utilizzare database a grafo per modellare ed eseguire query sulle relazioni tra transazioni finanziarie. I motori di raccomandazione possono utilizzare database a grafo per modellare ed eseguire query sulle relazioni tra prodotti, servizi e persone.
Se utilizzi un database grafico, non devi preoccuparti di perdere dati perché è sicuro da archiviare. Le relazioni vengono archiviate in database basati sul modello di righe e colonne piuttosto che su righe e colonne. Il mercato finanziario moderno è preoccupato per le frodi di un'ampia varietà. L'uso della tecnologia dei grafici migliora le prestazioni dei sistemi di rilevamento delle frodi basati su ML. I dati della tua azienda possono essere rappresentati in modo più completo da un database grafico. Gli algoritmi possono essere utilizzati per generare informazioni utili da grafici e reti. I grafici consentono di trovare schemi in modo più rapido ed efficiente.
Utilizzando la tecnologia dei grafici, algoritmi avanzati e intelligenza artificiale, è possibile migliorare la capacità di progettare trattamenti. I database grafici, utilizzati da molte delle piattaforme di social media più popolari, vengono utilizzati per analizzare le interazioni degli utenti. L'obiettivo di questo metodo è essere in grado di identificare quali account sono gestiti dai bot. Ti stai chiedendo se un database a grafo è una buona soluzione per il tuo business?
Database grafici e risorse digitali
I database a grafo consentono di collegare le relazioni e archiviare i dati. Questi professionisti sono esperti nell'arte della gestione di risorse digitali come film e programmi televisivi.