
I fattori di differenziazione di Hadoop: scalabilità open source e tolleranza ai guasti
Pubblicato: 2022-11-18Hadoop è un framework software open source per l'archiviazione distribuita e l'elaborazione di set di big data tra cluster di computer. È progettato per scalare da un singolo server a migliaia di macchine, ognuna delle quali offre elaborazione e archiviazione locali. Anziché affidarsi all'hardware per fornire alta disponibilità, il framework è progettato per rilevare e gestire i guasti a livello di applicazione. Hadoop è un database nosql perché utilizza un'architettura completamente diversa rispetto a un database relazionale tradizionale. Hadoop è progettato per scalare orizzontalmente, il che significa che può scalare per accogliere più dati aggiungendo più server di base al cluster. Hadoop è inoltre progettato per essere tollerante ai guasti, il che significa che se un server nel cluster si interrompe, il sistema può continuare a funzionare senza quel server.
Hadoop non viene utilizzato per l'archiviazione dei dati, né richiede l'uso dell'archiviazione relazionale; piuttosto, viene utilizzato per archiviare grandi quantità di dati su server distribuiti. Un database Hadoop è un tipo di dati piuttosto che un sistema software che consente un enorme calcolo parallelo. È un tipo vincolante di database NoSQL (come HBase) che consente agli utenti di interrogare e cercare database in una varietà vincolata. RDBMS, nella sua forma attuale, non sarebbe in grado di competere con Hadoop perché è in grado di gestire dati sia relativi che transazionali. Hadoop ha la capacità di gestire qualsiasi tipo di dati, siano essi strutturati, semi-strutturati o non strutturati, e supporta un'ampia gamma di metodi. L' analisi dei big data offre alle aziende un vantaggio competitivo nel mondo reale fornendo informazioni più approfondite. Hadoop, come servizio, supporta l'uso dell'elaborazione analitica online (OLAP) nell'elaborazione dei dati. È importante ricordare che la velocità di elaborazione dei dati è determinata dal numero di richieste di dati. Puoi utilizzare Hadoop se non desideri transazioni ACID o supporto OLAP, ad esempio.
Hadoop e database in memoria sono due tecnologie completamente diverse che si sovrappongono. Non sono la stessa cosa, ma sono d'accordo su alcune cose.
Le applicazioni analitiche che utilizzano SQL-on-Hadoop combinano metodi di query in stile SQL consolidati con elementi del framework di dati Hadoop più recenti . SQL-on-Hadoop consente agli sviluppatori aziendali e agli analisti aziendali di collaborare su cluster Hadoop con query SQL familiari.
È un database NoSQL che fornisce un mezzo per archiviare e recuperare i dati. Non relazionale/non SQL è uno dei termini comunemente usati in questo spazio.
I dati sono gestiti in vari modi da Hadoop e SQL. SQL è un linguaggio di programmazione, mentre Hadoop è un framework di componenti nel software. Entrambi gli strumenti sono utili per i big data, ma presentano degli svantaggi. La piattaforma Hadoop può gestire un set di dati molto più ampio, ma scrive i dati solo una volta.
Qual è la differenza tra Hadoop e Nosql?
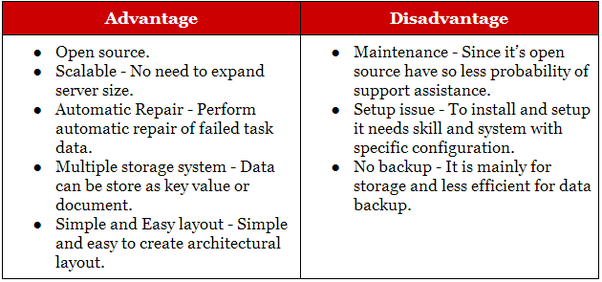
Hadoop è adatto per applicazioni di archiviazione analitica e storica, mentre NoSQL è ideale per carichi di lavoro operativi che completano le loro controparti relazionali. I database NoSQL sono nati come database archivio chiave-valore , ma in seguito si sono uniti a loro database document/json e graph.
Elaborazione in tempo reale, dati di grandi dimensioni e dati non strutturati sono solo alcuni degli scenari in cui è possibile utilizzare la tecnologia NoSQL. Di conseguenza, alcune di queste sfide, come la scalabilità e la disponibilità, possono essere affrontate. Il database NoSQL presenta una serie di vantaggi rispetto al tradizionale database relazionale. Possono elaborare set di dati in modo molto più rapido e scalabile rispetto al passato. I sistemi di amministrazione dei database utilizzano anche meno conoscenze e competenze rispetto ai database tradizionali , il che li rende più facili da usare. Un database NoSQL ha una serie di vantaggi rispetto a un database relazionale tradizionale. La cosa più importante da considerare è se sono necessari per l'elaborazione in tempo reale e grandi set di dati.
I database Nosql sono la scelta migliore per le aziende con carichi di lavoro di Big Data
Se i tuoi carichi di lavoro di dati sono più focalizzati sull'analisi e l'elaborazione di grandi quantità di dati vari e non strutturati, come i Big Data, i database NoSQL sono una scelta migliore. A differenza dei database relazionali, i database NoSQL non si basano su un modello di schema fisso. L'RDBMS è più flessibile degli RDBMS tradizionali in termini di archiviazione, elaborazione e gestione dei dati, rendendolo un'opzione migliore per le aziende che richiedono la possibilità di accedere rapidamente a grandi quantità di dati e hanno la necessità di archiviarli a tempo indeterminato.
Big Data Sql o Nosql?

Se i tuoi carichi di lavoro di dati riguardano principalmente l'elaborazione e l'analisi rapide di grandi quantità di dati vari e non strutturati, come i Big Data, NoSQL è la soluzione migliore. Il modello di database NoSQL è unico in quanto non si basa sulla stessa struttura dello schema di un database relazionale.
Non è più una questione se i big data miglioreranno la produzione; è una questione di quando. Nei big data sono disponibili quantità vaste, diversificate e complesse di dati strutturati e non strutturati. Sensori, telecamere sul piano di produzione e dispositivi di consumo possono essere tutti utilizzati per raccogliere big data nella produzione. Poiché la maggior parte dei dati nella produzione non è strutturata, le architetture NoSQL non possono competere con approcci rigidi come SQL. Un database NoSQL non richiede schemi per archiviare i dati nella stessa tabella del database, consentendo agli utenti di archiviare i dati in varie strutture. La linea di separazione di un'azienda può essere determinata dalla quantità di dati che intende utilizzare. Le transazioni devono rispettare quattro principi operativi fondamentali per essere considerate una transazione di database relazionale.
Poiché i sistemi NoSQL e i sistemi cloud possono essere integrati, è una buona idea utilizzare framework di cloud computing per supportare i sistemi NoSQL. L'ottimizzazione del processo di produzione in tempo reale tramite NoSQL può essere ottenuta attraverso l'integrazione con Manufacturing Execution Systems (MES). Questo successo è stato reso possibile utilizzando l'analisi dei big data per produrre risposte più rapide alle mutevoli condizioni. MongoDB è un buon database NoSQL perché è semplice da configurare e può essere utilizzato per l'analisi. L'uso di architetture di database a risposta più rapida come NoSQL consente al management di eseguire simulazioni migliori, consentendo loro di prendere decisioni migliori sui prodotti nel mondo reale. I database B2B sono vulnerabili agli attacchi cross-site, nonché agli attacchi injection e agli attacchi di forza bruta. Un attacco injection si verifica quando un utente malintenzionato aggiunge dati ai comandi di query NoSQL o alle istruzioni di archiviazione.

Il settore manifatturiero è particolarmente preoccupato per la sicurezza dell'architettura NoSQL. Se un attacco denial of service o un attacco injection viene consegnato con successo, un produttore potrebbe essere in grado di modificare le specifiche. Per questo motivo, i concorrenti potrebbero essere in grado di ottenere un vantaggio in un mercato altamente competitivo.
I processi aziendali che si basano su dati in tempo reale stanno diventando sempre più comuni poiché le aziende cercano modi per migliorare la loro efficienza e reattività alle esigenze dei clienti. I database NoSQL basati su cloud, come Cloud Bigtable, forniscono un modo rapido ed efficiente per archiviare e accedere a set di dati di grandi dimensioni, rendendoli una soluzione eccellente per questo tipo di applicazioni.
Cloud Bigtable è un servizio di database NoSQL completamente gestito e offre un tempo di attività del 99,999%. È ideale per i carichi di lavoro analitici e operativi perché ha un'elevata velocità di alimentazione dei dati ed è semplice da aumentare e diminuire. Di conseguenza, è una scelta eccellente per l'elaborazione dei dati in tempo reale in applicazioni come giochi mobili e analisi al dettaglio.
Nosql è il miglior database per dati di grandi dimensioni?
MongoDB, ad esempio, è una scelta eccellente per archiviare grandi quantità di dati. Consentono un'ampia gamma di scenari di elaborazione agile e ad alte prestazioni. Inoltre, i dati non strutturati vengono archiviati in database NoSQL su più nodi di elaborazione e su più server. Di conseguenza, i database NoSQL sono stati la scelta predefinita di alcuni dei più grandi data warehouse del mondo. Quale database è il migliore per i dati di grandi dimensioni? Quando si tratta di questa domanda, non è possibile prevedere quale database sia il migliore per i dati di grandi dimensioni a causa delle diverse esigenze dell'organizzazione. Amazon Redshift, Azure Synapse Analytics, Microsoft SQL Server, Oracle Database, MySQL, IBM DB2 e molti altri database sono tra le opzioni più popolari per l'archiviazione di dati di grandi dimensioni.
Hadoop è un database
Hadoop è un file system distribuito e un framework per l'esecuzione di applicazioni su grandi cluster di hardware di base. Hadoop non è un database.
Hadoop, un framework open source, consente l'archiviazione e l'elaborazione efficienti di enormi set di dati. Le tabelle Hive e Imperative possono essere create utilizzando file di testo in HDFS. Supporta i tre principali formati di file: file di sequenza, file di dati Avro e file Parquet. Una serie di byte è rappresentata dalla serializzazione dei dati come unità di memoria. Avro, un efficiente framework di serializzazione dei dati, è ampiamente supportato da Hadoop e dal suo ecosistema.
L'utilizzo di file di testo come formato di archiviazione per le tabelle Hive e Implicit semplifica la gestione e la manipolazione dei dati. Di conseguenza, è una buona scelta per l'elaborazione in batch o l'archiviazione dei dati in una varietà di formati. Inoltre, la serializzazione dei dati tramite Avro consente l'archiviazione e il recupero dei dati in modo efficiente e conveniente. Di conseguenza, è una buona opzione per archiviare i dati in una varietà di formati o eseguire l'elaborazione parallela.
Hadoop contro Nosql
Hadoop gestisce i big data per un cluster di hardware di base. Se la funzionalità non soddisfa le tue esigenze o non è funzionale, può essere modificata. Questo è indicato come NoSQL ed è un tipo di sistema di gestione del database che memorizza dati strutturati, semi-strutturati e non strutturati.
MongoDB, come database NoSQL (Not Only SQL), è stato creato nel 2007 come risultato dello sviluppo di C++. Un Hadoop è una raccolta di programmi software open source scritti principalmente in Java per l'elaborazione di dati di grandi dimensioni. Questa piattaforma include anche la ricerca full-text, strumenti di analisi avanzati e un linguaggio di query di facile utilizzo. Sebbene Hadoop sia meglio conosciuto per la sua capacità di archiviare ed elaborare grandi quantità di dati, lo fa anche in piccoli batch. MongoDB fornisce una varietà di strumenti di elaborazione dei dati in tempo reale. I connettori di MongoDB per strumenti esterni, come Kafka e Spark, semplificano l'acquisizione e l'elaborazione dei dati. Quando si tratta di gestione dei dati, Hadoop e MongoDB offrono una vasta gamma di vantaggi rispetto ai database tradizionali. Hadoop è uno strumento eccellente per gestire strutture di dati di grandi dimensioni grazie al suo file system distribuito. MongoDB è l'unico database che può essere utilizzato in sostituzione dei database tradizionali.
Spark è un database Nosql
Nella documentazione si afferma che un NoSQL DataFrame è un Spark DataFrame basato sul formato Spark per l'archiviazione dei dati. A differenza delle origini dati precedenti, questa supporta lo sfoltimento e il filtraggio dei dati (pushdown del predicato), consentendo alle query Spark di eseguire query su meno dati e caricare solo i dati richiesti in base alle esigenze.
È fondamentale mantenere la consapevolezza tattica quando si usano i database Apache Spark e NoSQL ( Apache Cassandra e MongoDB) insieme in un'applicazione. Questo blog si concentra su come utilizzare Apache Spark in un'applicazione NoSQL. CassandraLand e MongoLand al TCP/IP sPark sono due delle giostre più popolari ed è un ottimo posto da visitare se ti piacciono i parchi a tema. Durante la ricerca dei dati del Dipartimento dell'Energia, la nostra applicazione Spark ha iniziato a girare le ruote. Ecco una breve lezione su quanto sia importante la sequenza di tasti Cassandra quando si tratta di interrogare. C'è anche l'ottovolante Partitioner a CassandraLand. I clienti che amano le montagne russe possono condividere le loro informazioni con gli operatori di corsa in modo che possano tenere traccia di chi le ha cavalcate su base giornaliera.
La prima lezione in MongoDB Lezione 1 è gestire correttamente le connessioni MongoDB. Quando è necessario aggiornare le informazioni sul nuovo stato di appartenenza al parco del Dipartimento dell'Energia, gli indici Mongo sono estremamente utili. Come cliente MongoDB o Spark, dovresti mantenere una connessione e indici adeguati in caso di aggiornamenti di sistema.