
Il formato dati HDF5: un'opzione interessante per l'archiviazione e la gestione di grandi raccolte di dati
Pubblicato: 2023-02-13HDF5 è un formato di dati progettato per l'archiviazione e la gestione di raccolte di dati grandi e complesse. È spesso utilizzato in applicazioni scientifiche e ingegneristiche e la sua popolarità è aumentata negli ultimi anni. HDF5 non è un database, ma può essere utilizzato per archiviare dati in un formato gerarchico simile a un file system. Ciò rende HDF5 un'opzione interessante per le applicazioni che devono archiviare e gestire grandi quantità di dati.
È possibile estrarre metadati e dati non elaborati da file HDF5 e netCDF4 e utilizzare lo streaming Hadoop per analizzare i dati Hadoop utilizzando il driver di file virtuale (VFD) del connettore HDF5 di Hadoop Distributed File System (HDFS).
Hdf5 è un database?
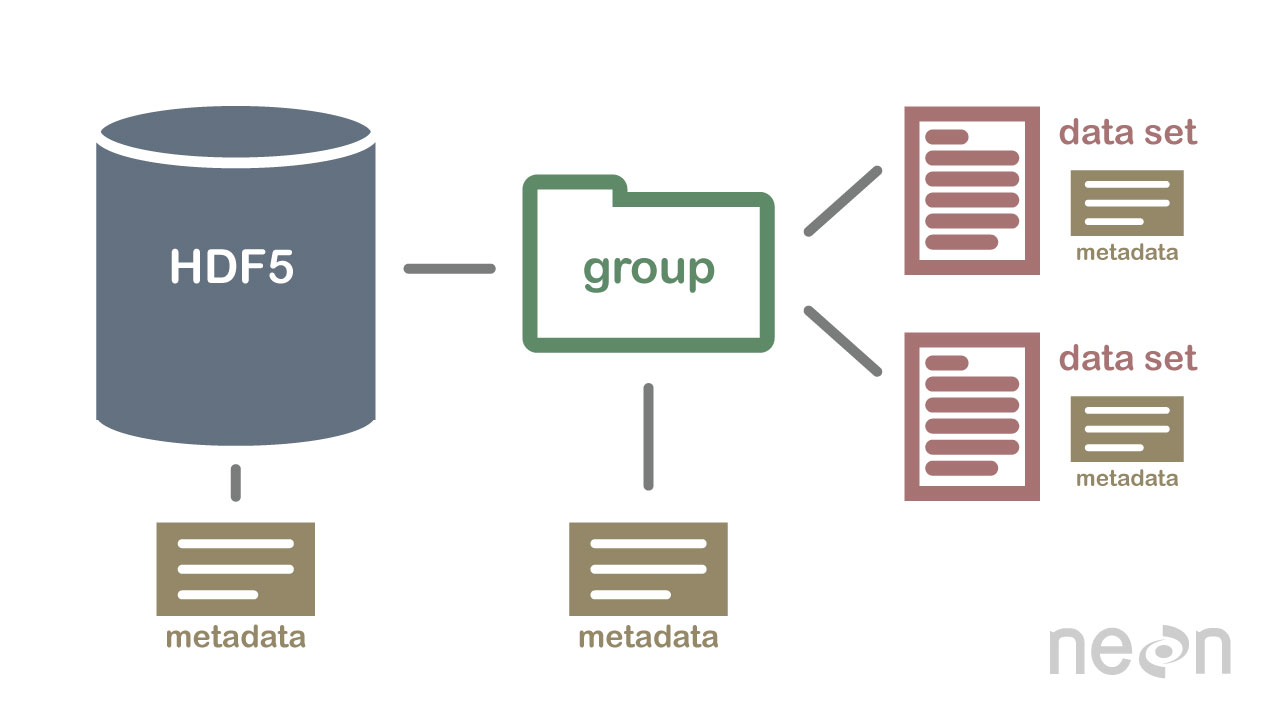
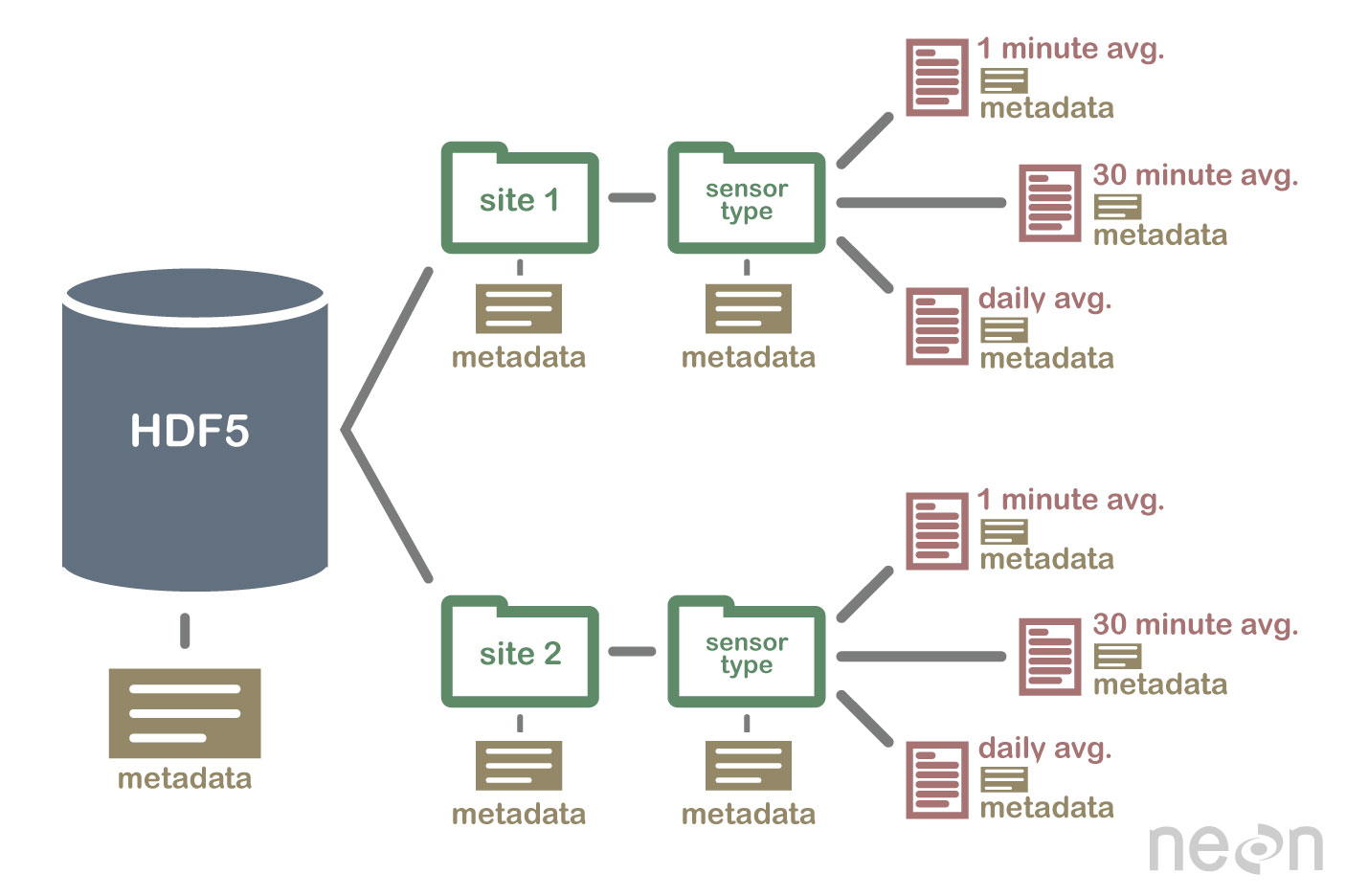
HDF5 non è un database, ma può essere utilizzato per archiviare i dati in una struttura gerarchica, simile a un file system. HDF5 può essere utilizzato per archiviare dati in una varietà di formati, inclusi testo, immagini e dati binari .
I dati in formato gerarchico (HDF5) sono estremamente utili nella ricerca scientifica. Il file system HDF5, poiché è simile a un file system in quanto è molto efficiente, è un formato eccellente. Quando si tratta di dati codificati in questo formato, può essere difficile accedervi. Questa guida ti illustrerà come Apache Drill può aiutarti ad accedere e interrogare facilmente i set di dati HDf5. Drill ha accesso ai singoli file HDF5 tramite l'opzione defaultPath. Ciò si ottiene eseguendo direttamente la funzione table() durante il tempo di interrogazione o tramite la configurazione. I risultati di questa query possono essere trovati nella tabella sottostante. Drill può quindi selezionare le colonne e filtrarle singolarmente, filtrate, aggregate o combinate con altri dati su cui può interrogare.
La specifica HDF5 definisce un formato di file per memorizzare gli array di dati. Un array di dati può essere costituito da qualsiasi tipo di dati, inclusi dati stringa, float, complessi e interi. Un array può contenere dati di qualsiasi dimensione e può avere qualsiasi forma. In HDF5, è necessario prima creare un file di intestazione per creare un set di dati. Il file di intestazione include informazioni sul set di dati e metadati. Il file di intestazione include due informazioni importanti: il nome del set di dati e il numero di versione del set di dati. Un array di dati viene utilizzato per archiviare i dati di un set di dati. I blocchi sono costituiti da dati in un array di dati. Nell'array di dati, ogni blocco di dati contiene un insieme contiguo di dati. Il numero di blocchi di un set di dati è determinato dal numero di byte in esso contenuti. È possibile accedere ai dati tramite una serie di metodi in conformità con la specifica HDF5. i metodi di indicizzazione sono più comunemente utilizzati per ottenere dati in un set di dati. Utilizzando questi metodi, è possibile accedere ai dati immettendo il nome di un blocco nell'array di dati a cui si desidera accedere. Il metodo della struttura può essere utilizzato per accedere ai dati in un set di dati. Quando si utilizzano questi metodi, è possibile accedere ai dati utilizzando la struttura di un array di dati. Nell'esempio seguente è possibile accedere ai dati in un array di dati utilizzando i valori offset e length del metodo structure. Un altro modo per ottenere dati da un set di dati è attraverso l'uso di metodi di funzione. È possibile ottenere i dati utilizzando uno dei metodi selezionando la funzione nel file di intestazione per i dati. Il metodo per accedere a un array di dati può essere utilizzato definendo il valore nel file di intestazione come elemento dell'array di dati dell'array. Infine, puoi accedere ai dati in un set di dati utilizzando il metodo di accesso. Utilizzando questi metodi, è possibile accedere ai dati utilizzando i privilegi di accesso impostati nel file di intestazione. In altre parole, utilizzando il privilegio di lettura è possibile accedere ai dati in un array di dati tramite il metodo di accesso. I dati possono essere creati e utilizzati in vari modi utilizzando la specifica HDF5. Il metodo create è il metodo più comune per la creazione di un set di dati. Utilizzando il metodo create, è possibile creare un set di dati immettendo il nome del set di dati e il numero di versione del set di dati. Oltre alla specifica HDF5, l'uso dei set di dati può essere realizzato in vari modi. Il metodo più comunemente usato.

Hdf5 è un database relazionale?
HDF5 non è un database relazionale.
Graphql è Nosql o Sql?
L'obiettivo principale di GraphQL è utilizzare un sistema di tipi per restituire i dati in modo più rapido ed efficiente. SQL (linguaggio di query strutturato) è un linguaggio più vecchio e più diffuso per l'archiviazione di dati in sistemi di database tabulari o relazionali . Se vuoi che la tua API sia costruita su un database NoSQL, sarebbe una buona idea lavorare con GraphQL.
Il Type Mismatch è un database GraphQL e NoSQL creato da Herman Camarena e Roger Cochrane. L'uso di GraphQL può portare all'introduzione di un sistema di tipi piuttosto che di un sistema NoSQL, eliminando la flessibilità creata dai sistemi NoSQL. Una raccolta GraphQL contiene un'ampia varietà di documenti che sono coerenti nella struttura e contengono alcune eccezioni. Poiché GraphQL ha un set integrato di tipi di dati che corrispondono ai tipi di backend, gli sviluppatori possono scegliere quali tipi di dati creare. GraphQL dovrebbe affrontare il problema delle discrepanze di tipo per realizzare appieno il suo potenziale. In termini di caratteristiche, fornisce una soluzione di mancata corrispondenza di livello inferiore grazie ai suoi numerosi vantaggi. Il lavoro è sempre più automatizzato con strumenti come JSON2SDL di StepZen.
È uno strumento potente che può essere utilizzato per creare applicazioni più resilienti ed efficienti, ma SQL non è un sostituto. In termini di manutenzione, questo può avere un impatto negativo perché rende alcune attività più difficili.
Graphql: un linguaggio di query per qualsiasi database
Il linguaggio di query GraphQL consente a client e server di comunicare tra loro. Un'istanza GraphQL può recuperare e rendere persistenti le modifiche da un'origine dati o da uno stato persistente. Un resolver è un insieme di funzioni arbitrarie utilizzate per accedere e manipolare i dati. L'API è disponibile in una varietà di database e GraphQL può essere utilizzato con qualsiasi database. Il database MongoDB è un popolare database di origine dati indipendente da vari tipi di dati.
Nosql usa gli alberi B?
I database NOSQL non utilizzano alberi B perché non sono basati sul modello relazionale. I database NOSQL sono spesso basati su coppie chiave-valore, archivi di documenti o database a grafo.
I B-tree sono la struttura di indicizzazione predefinita in MongoDB. Nell'archiviazione dei dati , un albero B è un metodo più efficiente. I dati possono essere organizzati utilizzando numeri interi e stringhe se vengono utilizzati insieme. Di conseguenza, i database con un elevato volume di dati dovrebbero considerare di utilizzarla. Poiché gli alberi B possono occupare molto spazio, sono un modello efficiente. Ciò è vantaggioso per i database che devono conservare una grande quantità di dati. I B-tree sono anche una buona scelta per i database che devono organizzare i dati in un modo specifico.
Quale database utilizza B-tree?
È in circolazione da molto tempo e può essere utilizzato in una vasta gamma di database. I database NoSQL possono essere costruiti su motori B-tree, oltre ai motori B-tree. MongoDB, ad esempio, indicizza i dati in alberi B. L'algoritmo è lo stesso per il DBMS come per un database relazionale, sebbene esistano alcune eccezioni. Stringhe e numeri interi possono essere usati per organizzare i dati nel B-tree.
Quale database utilizza B-tree? Mysql, nell'articolo che segue, utilizza sia Btree che B+tree. SQL Server archivia gli indici basati su dati persistenti basati su chiave sotto forma di BTree. Di conseguenza, ogni nodo in tale albero appare come una singola pagina.