
Il database Oracle NoSQL
Pubblicato: 2022-12-17Il database Oracle NoSQL è un database di valori-chiave distribuito. È progettato per fornire una gestione dei dati scalabile e ad alte prestazioni pur mantenendo un'interfaccia semplice. Il database Oracle NoSQL è basato su Oracle Berkeley DB Java Edition, che fornisce un motore di database incorporabile ad alte prestazioni. Il database Oracle NoSQL è disponibile come immagine di macchina virtuale scaricabile o come servizio cloud.
In-Memory utilizza un'esclusiva architettura a doppio formato che consente la rappresentazione simultanea delle tabelle in memoria. Poiché il nuovo formato di colonna è un formato in memoria puro e non richiede l'archiviazione su disco, non vi sono costi di archiviazione aggiuntivi o problemi di sincronizzazione dell'archiviazione. La capacità dei database in memoria di gestire query all'incredibile velocità di miliardi di righe al secondo su un core della CPU è sbalorditiva. La maggior parte di questi indici analitici può essere eliminata con In-Memory utilizzando il formato di colonna In-Memory, che riduce la quantità di dati che devono essere recuperati fornendo allo stesso tempo prestazioni paragonabili all'avere un indice su ogni colonna. La rimozione degli indici analitici accelera le operazioni OLTP perché non è più necessario che gli indici vengano mantenuti da ogni transazione. Solo le tabelle e le partizioni con privilegi di memoria possono essere inserite nella memoria degli utenti.
Il sistema di gestione del database NoSQL in memoria, come MongoDB e Redis, memorizza tutti i dati nella memoria principale e li aggiorna su disco a tempo indeterminato. Per garantire la persistenza, ogni richiesta di modifica viene salvata in un registro binario. Poiché il registro è di sola aggiunta, raramente è un problema scriverlo in fretta.
Il database Oracle è in memoria?

Sì, Oracle Database è in memoria. La funzionalità di archiviazione delle colonne in memoria di Oracle consente di archiviare e accedere ai dati in memoria, fornendo un significativo incremento delle prestazioni per i carichi di lavoro analitici. In combinazione con la tecnologia Real Application Clusters (RAC) di Oracle, Oracle Database può fornire un livello ancora più elevato di scalabilità e disponibilità.
Database In-Memory è un set di funzionalità che migliora l'analisi in tempo reale e i carichi di lavoro misti fornendo significativi miglioramenti delle prestazioni. Il Column Store (archivio colonne IM) è stato aggiunto a Oracle Database 12c Release 1 (12.1.0.2) come componente di Oracle Database 12c Release 1 (12.1.0.2). Nei database relazionali tradizionali, i dati possono essere archiviati in formati riga o colonna. La selezione di colonne in un database a colonne corrisponde alla selezione di righe in un database di righe. Database In-Memory include un archivio colonne In-database, ottimizzazioni avanzate delle query e soluzioni di accesso. L'archivio di colonne IM conserva copie di tutte le colonne, tabelle, partizioni e così via in un formato colonnare compresso progettato per una scansione rapida. Utilizzando l'elaborazione parallela, i data warehouse e i database a uso misto possono gestire ordini di grandezza più velocemente.
Come risultato del popolamento, i dati basati su righe sul disco vengono trasformati in dati colonnari nell'archivio colonne IM. Ad esempio, se si desidera suddividere una tabella o una vista in partizioni partizionate, tutte o parte delle partizioni possono essere configurate per il popolamento. L'espressione in memoria (espressione IM) in DBMS_INMEMORY_ADMIN.IME_CAPTURE_EXPRESSIONS consente l'identificazione e la selezione di espressioni calde. Quando un'istanza di database viene riavviata, il metodo Database In-Memory FastStart (IM FastStart) consente di risparmiare tempo riducendo la quantità di dati che devono essere inseriti nell'archivio colonne IM. Il formato colonnare è ideale per la scansione dei dati grazie alla sua elevata produttività. Puoi utilizzare l'analisi dei dati in tempo reale per esplorare nuove possibilità e iterazioni. È possibile eseguire la scansione dei dati nel formato compresso senza prima decomprimerli nel database Oracle.
Un predicato della clausola WHERE viene utilizzato rispetto ai dati compressi nel database quando le colonne vengono compresse utilizzando algoritmi che consentono la compressione automatica delle colonne. I filtri Bloom anticipano i join convertendo i predicati su tabelle di piccole dimensioni in filtri su grandi dimensioni. Quando i dati vengono archiviati nell'archivio colonne IM, è più semplice organizzare ed eseguire query complesse. La creazione di strutture di accesso è un passaggio fondamentale per migliorare le prestazioni delle query analitiche. L'approccio più comune consiste nel creare indici analitici, viste materializzate e cubi OLAP. Una riga deve essere inserita in una tabella, il che richiede la modifica di tutti gli indici. I database Oracle sono archiviati nel formato di archiviazione su disco di Oracle, che è identico al formato a colonne.
È completamente supportato da RMAN, Oracle Data Guard e Oracle ASM. Non richiede l'uso di uno strumento di migrazione dei dati gestito dall'utente. Se utilizzi le funzioni analitiche Oracle o un codice PL/SQL personalizzato, avrai accesso a una gamma più ampia di query analitiche. Le uniche attività richieste sono il dimensionamento dell'archivio colonne IM e la specifica dei valori oggetto per il popolamento. Nella tabella seguente, troverai un elenco delle attività di configurazione più basilari di IM Column Store. È possibile scaricare In-Memory Advisor per PL/SQL e utilizzarlo per analizzare il carico di lavoro di elaborazione analitica del database. L'elaborazione analitica differisce da altre attività del database in base alla cardinalità del piano, all'utilizzo di query parallele e ad altri fattori.
In-Memory Advisor non è incluso nei pacchetti PL/SQL archiviati nel sistema. Devi prima ottenere il pacchetto da Oracle Support. Le stime dell'advisor indicano miglioramenti nelle prestazioni di elaborazione analitica in base ai seguenti fattori. I tempi di attesa per l'I/O utente, i trasferimenti cluster e gli eventi di blocco della cache del buffer possono essere eliminati. A seconda del tipo di compressione, i costi di compressione incorrono nell'euristica.
Cosa c'è in memoria nel database?
Un database in memoria, al contrario di un database basato su disco o SSD, è progettato per archiviare i dati in memoria principalmente a scopo di archiviazione dei dati. Gli archivi dati creati in memoria utilizzano un metodo a basso costo per eliminare la necessità di accedere ai dischi e ridurre i tempi di risposta.
Vantaggi dei database in memoria
I database in memoria sono diventati più popolari negli ultimi anni perché offrono molti vantaggi rispetto ai database tradizionali. Il primo vantaggio è che possono archiviare tutti i tipi di dati nello stesso sistema, rendendoli ideali per le applicazioni che devono archiviare grandi quantità di dati non strutturati. Oltre alla velocità e all'efficienza dei database in memoria, gli utenti possono accedere ai dati più rapidamente. Inoltre, i database in memoria possono essere utilizzati da piccole imprese e consumatori perché sono semplici da usare e gestibili.
Oracle ha un database Nosql?
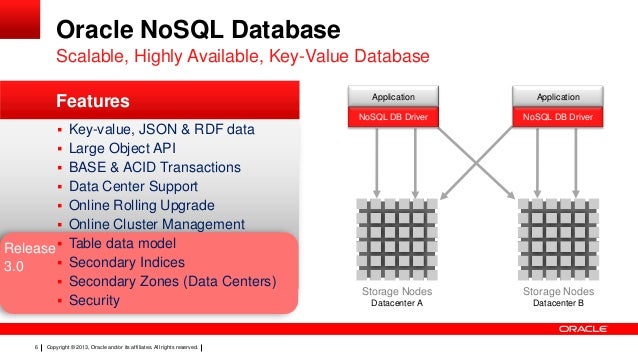
Sì, Oracle ha un database nosql chiamato Berkeley DB. Berkeley DB è un database open source ad alte prestazioni, scalabile.
Dove vengono archiviati i dati Nosql?
Invece di archiviare i dati in un database relazionale, i database NoSQL archiviano i dati nei documenti. Per dirla in altro modo, li dividiamo in SQL e una varietà di modelli di dati flessibili per classificarli. Un database NoSQL può essere un database di documenti puro, un database di archiviazione di valori-chiave, un database a colonne larghe o un database a grafo.
Uno degli usi più comuni dei database NoSQL è l'archiviazione rapida di grandi quantità di dati non correlati. NoSQL è un tipo di database che non condivide dati relazionali. Durante gli anni '70, i database relazionali hanno guadagnato popolarità come standard per l'archiviazione dei dati. Secondo Ben Finkel, un trainer CBT, NoSQL è interessato alla velocità e alla flessibilità piuttosto che alla coerenza e all'efficienza. Nonostante la loro velocità ed efficienza, i database creati utilizzando la tecnologia relazionale non sono così semplici come sembrano. Il database NoSQL non richiede la progettazione o la pianificazione delle strutture dati. Ciò consente agli sviluppatori di creare, prototipare e distribuire le applicazioni molto più rapidamente.
Funzionano in modo simile allo sviluppo software agile, anch'esso popolare. I database NoSQL possono memorizzare una varietà di tipi di dati, rendendoli semplici da configurare. I database NoSQL richiedono più potenza di calcolo per essere eseguiti rispetto ai database relazionali. Il Raspberry Pi ha la capacità di eseguire piccoli database NoSQL , ma i server web saranno molto più impegnativi. I grafici, a differenza delle coppie chiave:valore o dei documenti, sono astratti. Nodi e spigoli sono i due componenti dei grafici. I nodi possono contenere informazioni su un oggetto (persona, luogo, cosa, idea, ecc.). La relazione tra un nodo e i suoi bordi è spiegata dai bordi. Il modello di dati a colonne larghe è simile alle righe e alle colonne in un database relazionale.
Diversi fattori contribuiscono alla crescente popolarità dei database NoSQL. I database relazionali tradizionali sono inefficienti, richiedono molto tempo e sono soggetti al danneggiamento dei dati, mentre i database basati su microservizi hanno prestazioni migliori. Per una buona ragione, JSON è il formato preferito per i database NoSQL. In poche parole, i documenti JSON sono più compatti e leggibili rispetto ad altri tipi di documenti. JSON è un formato di rappresentazione dei dati creato in JavaScript.
JSON è più leggibile e compatto rispetto al formato di testo standard.
I database NoSQL sono più efficienti dei tradizionali database relazionali in termini di velocità e prestazioni.
Rendono più facile da usare.
Sono più resistenti alla corruzione dei dati rispetto ad altri animali.

I vari tipi di database Nosql
I database NoSQL, come MongoDB, sono popolari per la loro semplicità nell'archiviazione dei dati, che è molto più facile da comprendere rispetto ai tipi di modelli di dati utilizzati nei database SQL. Gli sviluppatori hanno spesso accesso diretto alla struttura di un database NoSQL.
Un database NoSQL è un database non tabulare che archivia i dati in modo diverso rispetto a un database relazionale (noto anche come SQL). I vari tipi di database NoSQL si basano sui loro modelli di dati. I principali tipi di documenti sono grafici, diagrammi e dichiarazioni di valore-chiave.
Come installo Nosql per archiviare i dati in forma strutturata?
I dati possono essere strutturati, semi-strutturati o non strutturati in un database NoSQL, consentendone l'accesso attraverso una serie di meccanismi. Il principale vantaggio del loro software è che è semi-strutturato (JSON, XML, ma non tutti i campi sono noti), il che porta a dati non strutturati.
In che modo i dati possono essere archiviati in un database non relazionale?
Poiché un database non relazionale non utilizza lo schema tabulare della maggior parte dei database tradizionali, non ci sono righe o colonne. I database non relazionali, invece, utilizzano un modello di archiviazione ottimizzato per il tipo di dati che devono essere archiviati.
Cos'è il database Oracle Nosql
Un database Oracle NoSQL è un archivio chiave-valore distribuito e scalabile progettato per fornire prestazioni elevate, scalabilità orizzontale e facile disponibilità. Il database Oracle NoSQL è un database conforme a NoSQL che fornisce l'archiviazione dei dati di coppia chiave-valore. Il database Oracle NoSQL viene eseguito su un cluster di server commodity e fornisce una semplice API Java per accedere al database.
L'SDK Oracle NoSQL per Spring Data include un modulo di implementazione di Spring Data. Questa funzione può essere utilizzata per connettersi a un cluster di database Oracle NoQL o al servizio cloud Oracle NoQL. Aggiungi la dipendenza Maven all'XML del tuo progetto per l'utilizzo con l'SDK. Per avere accesso a queste informazioni, è necessario utilizzare quanto segue. Nosql.spring è un client di Oracle. Utilizzo di un metodo NosqlDbConfig per configurare un database. Definire una classe di entità come segue.
Si consiglia di creare un repository per l'estensione Nosql . La classe dell'applicazione dovrebbe essere scritta. Aggiungendo file di dipendenza a org.springframework.boot:spring-boot, puoi iniziare con Spring Framework.
Esempio in memoria Oracle
Un esempio di Oracle in memoria sarebbe un'azienda che utilizza un database Oracle per archiviare ed elaborare i propri dati in memoria. Ciò consentirebbe un'elaborazione e un recupero dei dati più rapidi, oltre a ridurre la necessità di archiviazione su disco.
Senza modifiche alla base di codice, i tipi di query come le operazioni di raggruppamento (query analitiche) sono migliorati di 4-27 volte. Una query di analisi online che richiedeva 11 secondi per essere completata ha impiegato 399 millisecondi per essere completata utilizzando OIM. Tenere in memoria le partizioni interrogate più di frequente per tabelle partizionate di grandi dimensioni è una buona idea. Quando una tabella ha colonne molto larghe, si consiglia di escludere le colonne che vengono interrogate raramente. Poiché ogni colonna non è un componente in memoria di una query, Oracle imposta la cache del buffer su 0. Il rapporto di compressione viene aumentato in modo che sia necessaria una minore elaborazione per elaborarlo, risparmiando spazio. Più specifica è la query, maggiore è l'incremento di velocità fornito da OIM. Una query che ha restituito 75 righe da una tabella di 20 milioni di righe che esegue Oracle In-Memory ha impiegato 69 volte il tempo necessario utilizzando un DBMS standard . Di conseguenza, può fornire miglioramenti delle prestazioni fino a 67 volte più veloci (su query altamente selettive).
Perché l'area Pl/sql merita più memoria
Per PL/SQL e gli oggetti associati, le procedure PL/SQL e gli oggetti globali sono entrambi archiviati nell'area di memoria PL/SQL. Tutti questi oggetti hanno funzioni definite dall'utente, sono collegati a un pacchetto PL/SQL e dispongono di privilegi oggetto. È anche possibile l'esecuzione parallela del database Oracle utilizzando la memoria dell'area PL/SQL.
La raccomandazione generale di Oracle è di allocare il 95% della memoria totale all'SGA e il 5% all'area PL/SQL.
Oracle Nosql contro Cassandra
Ci sono alcune differenze chiave tra Oracle NoSQL e Cassandra. Per prima cosa, Cassandra è un progetto open source, mentre Oracle NoSQL è un sistema proprietario. Cassandra è anche un database orientato alle colonne, mentre Oracle NoSQL è un database orientato alle righe. Infine, Cassandra si concentra sull'elevata disponibilità e sulla scalabilità orizzontale, mentre Oracle NoSQL si concentra sulla facilità d'uso e sulla gestione dei dati gerarchici.
Apache Cassandra è un database NoSQL adatto a prestazioni elevate, scalabilità lineare, coerenza regolabile e carichi di lavoro a bassa latenza in diversi carichi di lavoro. Nella maggior parte dei casi, Apache Cassandra non sarà la scelta migliore per il tuo caso d'uso perché manca di una semantica coerente tra il tuo database relazionale e i database NoSQL con transazioni ACID. Se hai bisogno di una ridondanza dei dati ridotta e della conformità ACID, dovresti prendere in considerazione l'utilizzo di database SQL anziché Oracle. HBase non è comunemente utilizzato dagli sviluppatori web o mobili perché è progettato per funzionare con casi d'uso di data lake freddi o storici. Un'applicazione Cassandra è, invece, più facilmente disponibile e in grado di gestire ambienti altamente esigenti.
Qual è la differenza tra Cassandra e Oracle?
Oracle Database Management System (ODMS) è un sistema di gestione di database relazionali (RDBMS) disponibile in due formati: S.NO.ORACLE CASSANDRA1. È stato sviluppato da Oracle Corporation nel 1980 ed è stato creato da Apache Software Foundation nel 2008; 2. È stato scritto È possibile accedere al software open source eseguendo altre sette righe.
Oracle è un database Nosql?
Oracle NoSQL Database Cloud Service semplifica agli sviluppatori la creazione di applicazioni utilizzando modelli di database di documenti, colonne e valori-chiave offrendo tempi di risposta prevedibili in millisecondi, replica dei dati per l'alta disponibilità e applicazioni basate su documenti.
Cassandra e Nosql sono uguali?
Cassandra è un sistema di gestione del database dell'archivio a colonne gratuito e open source, distribuito, basato sul progetto Cassandra open source.
Netflix usa Cassandra?
Cassandra su Amazon Web Services funge da componente infrastrutturale chiave del servizio di streaming globale di Netflix.
Database Oracle Nosql Vs MongoDB
Ci sono molte differenze tra Oracle NoSQL Database e MongoDB. Innanzitutto, MongoDB è un database orientato ai documenti mentre Oracle NoSQL Database è un archivio di valori-chiave. Ciò significa che MongoDB archivia i dati in documenti simili a JSON, mentre Oracle NoSQL Database memorizza i dati in coppie chiave-valore. In secondo luogo, MongoDB supporta gli indici secondari, mentre Oracle NoSQL Database no. In terzo luogo, MongoDB ha un linguaggio di query più ricco rispetto al database Oracle NoSQL. In quarto luogo, MongoDB supporta l'auto-sharding, mentre Oracle NoSQL Database no. Infine, MongoDB è open source, mentre Oracle NoSQL Database no.
MongoDB è semplice da configurare e offre un'incredibile flessibilità in termini di flessibilità di progettazione. Se i tuoi formati di dati non sono coerenti, un database NoSQL come Oracle NoSQL Database è una buona scelta. Se hai bisogno di meno ridondanza dei dati e conformità ACID, l'utilizzo di un database SQL potrebbe essere l'opzione migliore per te. Poiché i database NoSQL, come MongoDB, non dispongono di interfacce grafiche, in genere non sono destinati a essere utilizzati insieme ai database tradizionali. Per migliorare l'usabilità, è necessario installare applicazioni di terze parti che consentono di visualizzare visivamente gli schemi e i documenti archiviati. Se non conosci un DBA o un amministratore di sistema su come utilizzare MongoDB, è una buona idea rivolgersi a un provider di hosting MongoDB di terze parti.
Differenze chiave tra MongoDB e Oracle
Ci sono molte differenze significative tra MongoDB e Oracle che dovrebbero essere prese in considerazione quando si decide quale software acquistare. La piattaforma MongoDB è ben nota per la sua capacità di gestire grandi quantità di dati, mentre Oracle è più comunemente utilizzato per creare applicazioni aziendali. Inoltre, MongoDB include funzionalità avanzate per la ricerca in qualsiasi campo o intervallo di query, mentre le capacità di Oracle sono meno limitate. Oracle si ridimensiona verticalmente perché si basa sullo sharding, mentre MongoDB si ridimensiona orizzontalmente perché si basa sullo sharding. Inoltre, MongoDB è costruito su un'architettura di sistema distribuita piuttosto che su un design monolitico a nodo singolo, che lo distingue da Oracle in termini di architettura.