
La potenza di MarkLogic: gestione dei big data e sicurezza in un unico posto
Pubblicato: 2023-01-29MarkLogic è un potente database Nosql che consente alle organizzazioni di archiviare, gestire e cercare facilmente e rapidamente grandi volumi di dati. È altamente scalabile e offre prestazioni elevate, il che lo rende ideale per le applicazioni Big Data. MarkLogic dispone inoltre di funzioni di sicurezza integrate che proteggono i dati da accessi non autorizzati e garantiscono l'integrità dei dati.
In risposta alla richiesta di un modo più flessibile ed efficiente per archiviare grandi quantità di dati, è nato un movimento noto come NoSQL. Questo post vuole essere un'introduzione generale per chiunque sia interessato a questo campo emergente. Questi sforzi sono stati compiuti per alleviare le limitazioni specifiche che esistono nel mondo RDBMS . I join non sono possibili in alcune opzioni NoSQL, quindi è necessario conservare più copie dei dati. Molto probabilmente è dovuto alla mancanza di indici globali e al fatto che i dati vengono partizionati tra i server delle materie prime utilizzando una chiave utilizzata per il recupero. Gli utenti NoSQL si aspettano motori di ricerca full-text come Lucene, Solr e Sphinx, ma non sono i migliori. La soluzione scalabile MarkLogic ha dimostrato di essere distribuibile orizzontalmente su hardware di base con una capacità di petabyte.
È un tipo di database molto diverso rispetto ad altri database a sé stanti. MarkLogic non è mai stato creato per poter risolvere un problema specifico. È stato creato da zero come piattaforma per applicazioni di classe enterprise, indipendentemente dalle dimensioni.
Il data warehouse operativo di nuova generazione di MarkLogic è uno strumento software per condurre analisi operative.
Passare a http://localhost:8000/appservices/ per trovare la pagina dei servizi dell'applicazione. Con la sezione Database in MarkLogic Server , è possibile accedere a tutti i database ed eliminare database, nonché creare e configurare un database.
Quale database utilizza Marklogic?
La maggior parte delle organizzazioni oggi richiede un database per eseguire le proprie operazioni. Viene utilizzato per eseguire applicazioni transazionali, operative e analitiche dal data center e gestire in modo sicuro un'ampia gamma di origini dati.
La piattaforma di MarkLogic consente il caricamento simultaneo, l'interrogazione, la manipolazione e il rendering dei contenuti. Puoi cercare rapidamente il contenuto se viene automaticamente convertito in XML e indicizzato. Big Publishing ha utilizzato la query degli elementi XML, la ricerca di prossimità XML e la ricerca full-text per migliorare le proprie capacità di ricerca. In 4 o 5 mesi, un'azienda potrebbe mettere in atto una soluzione e iniziare a utilizzarla. Il governo della contea di Quakezone vuole rendere più facile per i dipendenti, gli sviluppatori e i residenti della contea l'accesso alle informazioni in tempo reale, rendendo più facile per loro farlo. Richiedono una soluzione di infrastruttura IT che verrà implementata rapidamente e facilmente. Con MarkLogic, la contea può visualizzare e correlare i dati in vari modi, anche trasformandoli e arricchendoli.
Time Traders Services ha sostituito il suo sistema legacy con MarkLogic Server. La soluzione è notevolmente ridotta in termini di latenza degli avvisi fornendo al contempo informazioni immediate e pertinenti al portale e all'e-mail del cliente. Gli operatori finanziari ottengono un vantaggio in ufficio e sul trading floor informando i clienti delle nuove ricerche disponibili. MarkLogic viene utilizzato per mantenere installazioni top secret nel governo federale. Gli scambi beneficiano di un costo inferiore del sistema hardware quando MarkLogic ottimizza l'hardware di base. Con prestazioni elevate, ci sono meno server hardware con cui confrontarsi. Invece di acquistare server più grandi e più costosi, un aumento della scalabilità consente l'installazione di più server di base.
Uno dei principali vantaggi di MarkLogic Data Hub è la sua capacità di integrarsi con altre origini dati. Il software può connettersi facilmente a sistemi legacy come ERP e CRM, nonché a fonti più recenti come data warehouse dei clienti e fonti di dati in streaming. Inoltre, MarkLogic Data Hub è in grado di elaborare un'ampia gamma di formati di dati, semplificando l'inserimento dei dati. Infine, MarkLogic Data Hub è estremamente facile da usare. È un programma gratuito, quindi non devi pagare per usarlo. Inoltre, il programma è open source, quindi puoi personalizzarlo per soddisfare le tue esigenze specifiche.
Database multi-modello: il meglio dei due mondi
La tabella seguente elenca i tipi di database più comuni per i database multimodello. Un database multi-modello ti consentirà di selezionare modelli di dati meno costosi da mantenere. L'indicizzazione in stile ricerca e l'archiviazione dei dati transazionali di MarkLogic consentono di combinare e arricchire i dati all'interno dei propri sistemi. Di conseguenza, può essere utilizzato per eseguire processi ETL. Inoltre, poiché MarkLogic è un database a grafo, è un'eccellente opzione a triplo stack per chi cerca un database a grafo.
Ldap è un Nosql?
Poiché ogni database NoSQL viene fornito con il proprio protocollo, selezionarne uno significa essenzialmente bloccarti in quel tipo di database. Se devi cambiare il server, devi cambiare anche i client.
Quando veniva utilizzato da Pearson Education, NoSql veniva utilizzato per ospitare lezioni online, record degli studenti e così via. In questo caso, tutti i membri del team dovevano essere subito operativi con Mongo. È facile dimenticarsi del servizio Ldap, utilizzato da centinaia di migliaia di server e desktop nel mondo. Utilizzando lo strumento console 389-ds, puoi facilmente creare nuovi oggetti e attributi. In termini di cloud computing, inserirei due dischi master in ciascuna zona per garantire la replica wan (multimaster). È possibile ottimizzare i livelli di replica. Per modificare lo schema, puoi farlo online.
Qual è un esempio di un Nosql?
La maggior parte dei settori in cui vengono utilizzati i database NoSQL fa affidamento su di essi per una varietà di scopi. Il tipo di database NoSQL utilizzato in un determinato caso avrà un impatto sul suo funzionamento. I database di documenti come MongoDB sono esempi di database generici . Grandi quantità di dati possono essere archiviate in database di valori-chiave, semplificando le query di ricerca.
I vantaggi dei database Nosql
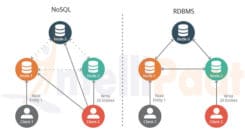
A differenza dei tradizionali database relazionali, i database NoSQL si differenziano da questi in quanto si staccano dal tradizionale modello di organizzazione dei dati a favore di una struttura più flessibile che consente archivi di dati molto più dinamici e vasti. Questo è un vantaggio quando si tratta di aumentare la scalabilità di un archivio dati per aumentare il traffico o quando è necessario soddisfare le diverse esigenze degli utenti. A causa della serie unica di vantaggi disponibili nei database NoSQL, stanno diventando sempre più popolari e non tutte le applicazioni ne trarranno vantaggio. Se stai cercando un archivio dati più flessibile in grado di gestire una gamma più ampia di richieste, i database NoSQL sono una scelta eccellente.
Uber usa Sql o Nosql?
Quando un database senza algoritmi viene utilizzato per archiviare i dati, è noto come database NoSQL. Poiché i database NoSQL non supportano l'indice (a causa della mancanza di transazioni distribuite), il team di evasione ordini di Uber utilizza una tabella separata per archiviare l'indice.
Uber ha pubblicato un articolo sul proprio sito Web che spiega perché Uber è passato da PostgreSQL a InnoDB. Questo post è stato composto dall'articolo di Uber nel tentativo di fornire una migliore comprensione. PostgreSQL ha sempre bisogno di aggiornare tutti gli indici in una tabella quando aggiorna le righe quando indicizza una tabella, come descritto in dettaglio in questo articolo. Questo approccio comporta anche un aumento degli IO del disco per gli aggiornamenti che modificano le colonne non indicizzate. In questo articolo, descrivono la penalità dell'indice cluster come un leggero svantaggio, che è significativo se si eseguono molte query utilizzando indici secondari. L'articolo non menziona che questa penalità si applica a qualsiasi dichiarazione con una clausola where, non solo select. Una scansione del solo indice Postgres, d'altra parte, è abbastanza inutile.
Sembrano funzionare bene in un importante caso d'uso del negozio di chiavi in futuro. Sono disponibili pacchetti destinati a funzionare con i front-end SQL (ma con pochissime funzioni). Uber ha creato il proprio database (Schemaless) oltre a utilizzare InnoDB e MariaDB. Una divisione del nodo è un'operazione importante in un albero B. Una divisione del nodo si verifica quando uno o più nodi non sono in grado di ospitare una nuova voce. Nella peggiore delle ipotesi, la divisione si espanderà fino al nodo radice, anch'esso diviso e sostituito da un nuovo nodo. Di conseguenza, l'intero albero cade, mantenendo costante l'equilibrio dell'indice.
Un bug nel processo di replica può rendere completamente irreparabili ampie parti dell'albero. È possibile che il master non sia in grado di determinare cosa stanno tentando di fare le repliche e cancelli i dati che sono ancora necessari per il completamento della query. Questo problema può essere risolto ritardando l'applicazione del flusso di replica per un timeout configurabile, consentendo alla transazione di lettura di fare il suo turno. Ci sono alcuni ingegneri che non sono esperti di database e potrebbero non comprendere sempre questo problema, in particolare quando si utilizza un ORM che oscura i dettagli di basso livello come le transazioni aperte. La maggior parte degli sviluppatori sa che le transazioni possono essere utilizzate per annullare la scrittura. Se più persone vengono assunte da un'azienda, la loro qualifica sarà più vicina alla media. L'aumento della dimensione del campione è guidato dall'assunzione di più persone.
I casi d'uso di Uber hanno richiesto l'uso di Schemaless, un nuovo database NoSQL . Il loro articolo suggerisce che Postgres sia stato sostituito da MySQL, ma non è così; invece, la loro soluzione su misura è supportata da MySQL. Non si fa menzione di come i loro requisiti siano cambiati quando sono passati a PostgreSQL da MySQL in questo articolo, quindi non c'è modo di dirlo. C'è solo una cosa che rimane impressa nella mente del lettore: Postgres è terribile.
Perché i database Nosql sono perfetti per Ube
Il database MySQL di Uber è costruito sopra un database NoSQL, quindi si può dedurre dal testo che usano questo database. Inoltre, dai dati si può dedurre che questo database NoSQL viene utilizzato per memorizzare nella cache e accodare i dati. Amazon è un'altra società di database NoSQL, in quanto fornisce un set completo di strumenti per lo sviluppo di applicazioni basate su database.
Marklogic Nosql
MarkLogic è un potente database NoSQL che consente agli sviluppatori di creare rapidamente e facilmente applicazioni che gestiscono grandi volumi di dati. MarkLogic è facile da usare e da scalare, il che lo rende la scelta ideale per le organizzazioni che devono gestire grandi quantità di dati.
Il server MarkLogic è un database creato da zero per semplificare agli utenti la ricerca di grandi quantità di dati eterogenei. MarkLogic incorpora gli elementi interni del database, gli indici di ricerca e i comportamenti del server delle applicazioni in un sistema unificato che può essere eseguito contemporaneamente. I documenti XML e JSON vengono utilizzati come modelli di dati e i relativi dati transazionali vengono archiviati in un repository di dati transazionali . I dati del documento possono iniziare come XML o JSON, ma possono anche essere trasformati una volta inseriti. I modelli di dati del documento in genere contengono tutti i dati correlati nello stesso documento, quindi i dati vengono denormalizzati prima di essere resi pubblici. Il contenuto XML può essere definito come schema per rappresentare una classe di modelli di contenuto dei documenti. Quando un documento specifico deve essere strutturato in un modo specifico, è fondamentale disporre di un identificatore per il documento.
Gli schemi XML possono essere importati nel database Schemas o inseriti nella directory Config. Successivamente, puoi specificare una serie di schemi per uno specifico App Server o un gruppo di server. MarkLogic supporta anche schemi SQL virtuali che forniscono il contesto per le viste SQL, come definito nella Guida alla modellazione dei dati SQL. MarkLogic Server è in grado di cercare, archiviare e gestire i dati semantici nelle triple RDF, che vengono archiviate nella memoria. La semantica è un insieme di standard W3C che consentono lo scambio di dati leggibile dalla macchina (e informazioni sulle relazioni tra i dati). MarkLogic consente di archiviare, cercare e gestire questo tipo di dati utilizzando SPARQL nativo e SPARQL Update, nonché JavaScript, XQuery e REST. È possibile ottimizzare la gestione dei dati binari con la suite di meccanismi di MarkLogic Server.

Un documento binario può essere memorizzato in base alla sua dimensione, che è determinata da una serie di soglie. MarkLogic è un'applicazione a thread singolo progettata per più processori contemporaneamente. Esistono numerose porte socket che possono essere utilizzate per la comunicazione esterna. La piattaforma MarkLogic ha lo scopo di fornire velocità e scalabilità. Le query avanzate in MarkLogic vengono scritte in terabyte di dati. Le più grandi distribuzioni live hanno ora superato i 200 terabyte e un miliardo di documenti. Quando si utilizzano i cluster, si ottiene un elevato livello di disponibilità.
Questo tipo di server è generalmente alloggiato in un box da 4 o 8 core, 64 o 128 Gb o di capacità superiore. I bilanciatori di carico elastici (ELB) sono integrati in Amazon Elastic Compute Cloud (EC2), che consente ai cluster MarkLogic di distribuire e bilanciare automaticamente il traffico delle applicazioni. Per migliorare la disponibilità dell'ambiente EC2, i D-Node possono essere raggruppati nella stessa posizione.
Cos'è il database Marklogic
MarkLogic è un potente database NoSQL che consente agli sviluppatori di creare applicazioni più velocemente fornendo loro gli strumenti necessari per lavorare con tutti i tipi di dati. MarkLogic è l'unico database NoSQL che combina la potenza di un database orientato ai documenti con la flessibilità di un archivio chiave-valore, rendendolo la piattaforma ideale per le applicazioni moderne di oggi.
È una potente piattaforma di gestione dei dati che fornisce un sistema unificato per la gestione dei dati. Vengono utilizzati modelli di dati del documento in XML e JSON e archivia i documenti in un repository transazionale. Il Data Hub si trova in cima al data lake e contiene dati di alta qualità, curati, sicuri, deduplicati, indicizzati e interrogabili. Inoltre, MarkLogic Data Hub è progettato per gestire enormi set di dati con data tiering automatizzato che memorizza e recupera i dati da un data lake in modo sicuro.
Perché i database a grafo stanno prendendo il sopravvento
I database a grafo stanno rapidamente diventando l'opzione ideale per l'archiviazione dei dati in un'ampia varietà di formati difficili da gestire manualmente. I database SQL tradizionali non sono in grado di gestire questo tipo di query e possono essere molto utili nell'affrontare questo tipo di query. Se è necessario eseguire query sui dati in modi gestibili dai database SQL, nonché se è necessario archiviare i dati nei grafici, MarkLogic è una buona opzione.
Database Marklogic Vs MongoDB
Il database NoSQL aziendale di MarkLogic include tutte le funzionalità necessarie in un'unica piattaforma. MongoDB, d'altra parte, viene utilizzato per organizzare grandi idee. MongoDB è un servizio MongoDB che memorizza i dati in documenti simili a JSON che possono essere strutturati in vari modi.
Se disponi di dati META, puoi utilizzare MarkLogic perché recupera tutto così rapidamente. Esistono alternative migliori all'utilizzo di un database relazionale in caso di necessità. MongoDB è uno strumento incredibile per una varietà di applicazioni grazie alla sua incredibile flessibilità e facilità d'uso. Nonostante il fatto che l'open source sia utilizzato in quasi tutto il resto, il database back-end è di fondamentale importanza. L'assistenza clienti di MarkLogic è estremamente reattiva e professionale. Sono pronti a rispondere a problemi importanti e problemi di qualità della produzione. Non vedo l'ora di utilizzare le risorse di MongoDB per beneficiare di parte del suo potere.
Solo alcuni aspetti possono essere migliorati o semplificati. Se non hai già un DBA o un amministratore di sistema che sia a conoscenza di MongoDB, dovresti rivolgerti a un provider di hosting MongoDB specializzato nel settore. Quando il tuo set di dati cresce, puoi utilizzare il motore di archiviazione di Cassandra per creare scritture a tempo costante. MongoDB può essere utilizzato per l'analisi utilizzando il supporto Hadoop nativo.
Database grafico Marklogic
MarkLogic è un database grafico. Utilizza un modello di dati grafico per archiviare e interrogare i dati. Un database a grafo è un database che utilizza un modello di dati a grafo per archiviare e interrogare i dati.
La Semantic Graph Developer's Guide è una lettura obbligata per chiunque sia interessato al campo dei grafi semantici. Gli argomenti inclusi in questa guida includono: I dati possono essere scaricati. Usando il campione completo DBPedia di Persondata (sia in Turtle che in inglese), puoi mostrare loro come usare una tartaruga o una parola inglese. Il database Documenti ha un indice triplo e un lessico di raccolta che può essere abilitato di default. Prima di utilizzare un database per triple, assicurati che entrambe le opzioni siano abilitate. mlcp è un metodo ideale per il caricamento in blocco di triple su un ambiente desktop Windows. La funzione nativa SPARQL o la funzione incorporata sem:sparQL sono entrambi metodi accettabili per l'esecuzione di query MarkLogic . La sezione Download del set di dati presuppone che tu abbia caricato il set di dati di esempio.
Centro dati Marklogic
Data Hub di MarkLogic è un'interfaccia software open source gratuita che acquisisce dati da più fonti, li armonizza, li controlla e quindi li cerca e li analizza. La soluzione viene eseguita su MarkLogic Server e intende fornire una piattaforma unificata per applicazioni mission-critical.
A cosa serve Marklogic
MarkLogic è un potente database che consente di archiviare, gestire e ricercare i dati in modo più efficace. Viene utilizzato da organizzazioni in una varietà di settori per alimentare le proprie applicazioni e siti Web. MarkLogic è particolarmente adatto per la gestione di grandi quantità di dati e query complesse.
Server Marklogic
MarkLogic Server è una potente piattaforma di database NoSQL che consente agli sviluppatori di creare rapidamente e facilmente applicazioni sofisticate che sfruttano tutti i loro dati, indipendentemente dalla loro struttura o posizione. MarkLogic Server è costruito su un'architettura unica che combina il meglio del mondo relazionale e NoSQL, offrendo agli sviluppatori la flessibilità di lavorare con i propri dati nel modo più adatto alle loro esigenze.
DocumentManager, un'istanza DatabaseClient creata appositamente per la gestione dei documenti, può essere utilizzata per gestire i documenti. Per dimostrare come leggere un documento XML, utilizzare ReadXMLDocument.java basato su Java di Marklogic. La libreria Java ReadMetadata ti mostra come rilevare il tipo di documento che hai ricevuto e come gestirlo correttamente. L'inserimento di un documento di testo è simile all'inserimento di un documento PDF, ma è necessario utilizzare un StringHandle o fornire il formato come mostrato nell'esempio precedente. L'API Java può essere utilizzata per accedere a documenti e metadati in vari modi. Il metodo DeleteDocument.java può essere utilizzato per eliminare più documenti contemporaneamente. Download di documenti di grandi proporzioni.
Un documento alla volta può essere costoso quando si utilizzano schemi di autenticazione digest perché è necessario caricare un documento. Utilizziamo termini come ricerca e interrogazione allo stesso modo in MarkLogic, indipendentemente dal contesto in cui li utilizziamo. Se desideri esprimere un'ampia gamma di risultati di ricerca, una sintassi di query è un modo semplice ed efficace per farlo. Il testo di ricerca viene specificato utilizzando il metodo setCriteria del nostro gestore di query dopo aver acquisito un'istanza di query di stringa iniziale dal nostro gestore di query. È vero che anche una semplice ricerca può essere molto potente se utilizzata nella configurazione di ricerca predefinita di MarkLogic. Come specificato nella definizione della query, vengono utilizzati tre metodi per implementare ciascuna query. Le prime due opzioni consentono di specificare un percorso di query o un set di raccolta.
L'ultimo consente di associare una query a una serie di opzioni di ricerca personalizzate memorizzate sul server. Di seguito è riportato un elenco dei risultati della ricerca. Eseguendo il programma e ispezionando la console, è possibile vedere come MarkLogic rappresenta i risultati della ricerca in XML. Il progetto tutorial include uno script Java denominato Search ResultsAsJSON. Giava. Se esegui il programma, vedrai i risultati della ricerca JSON non elaborati che sono stati recuperati dal server. Getsearch risulta in formato POJO chiamando il suo metodo getMatchResults().
È possibile ottenere un array di oggetti MatchDocumentSummary passandogli una stringa. Quando un documento contiene un risultato di ricerca, può essere rappresentato da un oggetto MatchLocation. Viene utilizzata un'opzione predefinita denominata se non si specifica esplicitamente un nome. A causa del suo significato in Mark Logic, il vincolo viene spesso utilizzato. La configurazione per un intero set di opzioni viene archiviata in src/main/ml-options/options durante la creazione o la sostituzione di un set di opzioni. I vincoli qui elencati sono disponibili in una varietà di forme. Fai un programma.
Questo metodo dovrebbe restituire gli stessi risultati di CollectionSearch java. Come risultato di questa nuova stringa di ricerca, il criterio di raccolta Shakepeare viene ora fornito come parte della stringa di ricerca dal vincolo tag. Come puoi vedere, utilizziamo il seguente comando per distribuire la nostra configurazione. Potresti, invece, aprire un nuovo prompt dei comandi e passare a mlwatch, dove le modifiche allo script verranno inviate a Mark Logic. Il contesto di una parola viene testato piuttosto che la sua chiave o elemento in termini di vincolo di parola, che è simile a un vincolo di valore. Le parole corrispondenti sono anche formate da radici staminali, il che significa che verranno utilizzate parole simili, come strategie e strategie. Dobbiamo creare/modificare i seguenti file per abilitare lo stemming:src/main/ml-config/databases/content-database.
L'esecuzione del comando seguente ti aiuterà a comprendere la procedura. Il modulo gradle mlUpdateIndexes viene utilizzato per aggiornare le tabelle degli indici nel modulo gradle mlReindexDatabase. Usando il vincolo delle proprietà, possiamo cercare le proprietà di un documento per metadati. Utilizziamo i nostri metadati estratti durante l'ingest e archiviati come proprietà del documento per generare le nostre immagini. Quando inseriamo una parola di ricerca per "proprietà", verrà applicata solo a quella proprietà del documento. Il metodo search() viene utilizzato nel gestore query per eseguire la query.
A cosa serve Marklogic?
MarkLogic Server è uno strumento software che memorizza e gestisce una varietà di dati per eseguire applicazioni transazionali, operative e analitiche.
L'hub dati: la soluzione completa per la gestione dei dati
I data hub ti offrono il controllo completo sulla gestione e l'accesso ai dati da un data lake. In MarkLogic, il data tiering automatizzato garantisce che i dati siano archiviati in modo sicuro e accessibile da un data lake e semplifica l'integrazione dei dati.
Come mi collego a Marklogic?
Dopo l'installazione e l'avvio di MarkLogic, accedere all'interfaccia amministrativa basata su browser (all'indirizzo http://localhost:8001/), dove si apprenderà come ottenere una licenza per sviluppatori e configurare un amministratore.
Marklogic: l'app server con un'API di riposo
L'utilizzo di applicazioni client API REST per interagire con MarkLogic Server tramite un'istanza API REST sta diventando sempre più comune. MarkLogic impiega 500 persone ed è uno dei maggiori fornitori di server di app sul mercato. Secondo le loro proiezioni di entrate, avranno un picco di entrate di $ 100,0 milioni nel 2021, con un reddito medio per dipendente di $ 200.000.