
I pro ei contro dei database a colonne
Pubblicato: 2022-11-19I database NoSQL sono un'ottima scelta per molte applicazioni moderne, ma ci sono alcune cose fondamentali da considerare prima di effettuare il passaggio. Un fattore importante è se hai bisogno o meno di un database relazionale. Se lo fai, un database a colonne potrebbe non essere la scelta giusta. I database a colonne sono adatti per le applicazioni che devono analizzare rapidamente grandi quantità di dati. Sono anche una buona scelta per le applicazioni che non necessitano del modello relazionale completo e possono cavarsela con un modello di dati più semplice. Tuttavia, i database a colonne presentano alcuni inconvenienti. Possono essere più difficili da usare rispetto ai database relazionali e potrebbero non supportare tutte le funzionalità necessarie. Prima di decidere se un database a colonne è adatto alla tua applicazione, assicurati di comprendere i pro e i contro.
Un database a colonne organizza e archivia i dati per colonne anziché per righe. Utilizzano funzioni e operazioni di aggregazione per ottimizzare le colonne di dati. Le colonne del database sono scalabili e si comprimono bene rispetto ad altri tipi di database. In un database a colonne, ogni riga di dati è separata in più colonne da un numero di colonne. I database a colonne sono adatti per l'elaborazione di big data, la business intelligence (BI) e l'analisi. Le operazioni di riga hanno un tempo molto più lento rispetto alle operazioni di colonna. I record IoT possono contenere solo un numero limitato di elementi di dati poiché i nuovi record arrivano in un flusso coerente. I big data hanno il potenziale per trasformare il modo in cui funzionano i sistemi di database operativi.
I due tipi di database di database, righe e colonne, possono caricare dati ed eseguire query utilizzando linguaggi di query di database tradizionali come SQL. In molti casi, le dorsali dei database, come i database a righe ea colonne, possono fungere da motore per l'estrazione, la trasformazione, il caricamento e la creazione di strumenti di dati comuni.
Un database a colonne, un tipo di sistema di gestione del database (DBMS), è uno che archivia i dati in colonne anziché in righe. Per accelerare il ritorno di una query, le colonne in un database a colonne possono essere scritte e lette in modo efficiente da e sul disco rigido.
Oggi esamineremo come funzionano le colonne in un database a colonne e le confronteremo con un più tradizionale database orientato alle righe (ad esempio, MySQL). Esamineremo cos'è un database a colonne in questo articolo, nonché i suoi vantaggi e svantaggi.
Quali sono alcuni esempi di un database NoSQL? Microsoft SQL Server è un sistema di gestione di database relazionali creato da Microsoft.
MongoDB è un database a colonne?
MongoDB non è un database a colonne.
Sta diventando sempre più popolare perché fornisce prestazioni di query migliorate nelle query analitiche. I dati nei database a colonne vengono archiviati in modo più efficiente rispetto agli archivi dati basati su database perché i dati vengono archiviati in colonne. Le query analitiche eseguite su database a colonne hanno un vantaggio in termini di prestazioni maggiore. Rispetto all'archiviazione orientata alle righe, l'archiviazione a colonne è molto più efficiente in termini di spazio di archiviazione e prestazioni delle query. Poiché i dati vengono archiviati in modo colonnare, i dati possono essere letti e scritti più facilmente.
Quali sono i database Nosql?
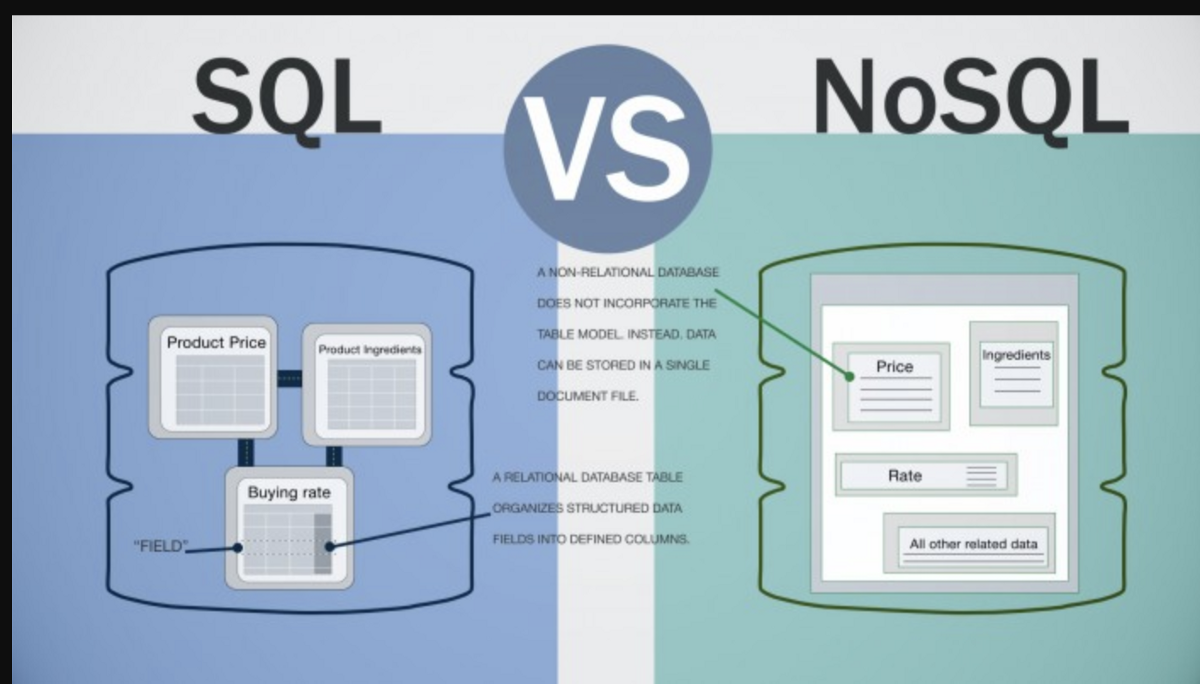
I database NoSQL sono database che non utilizzano il tradizionale modello di database relazionale. Invece, usano una varietà di modelli diversi, inclusi documenti, grafici, valori-chiave e colonne. I database NoSQL sono spesso più adatti per gestire grandi quantità di dati che non sono adatti al modello relazionale.
Un sistema NoSQL è un tipo di database che non è basato su SQL. Il modello di dati utilizzato dal team di modellazione dei dati differisce dal tradizionale modello di tabella riga e colonna utilizzato nei sistemi di gestione dei database relazionali. I database NoSQL, oltre ad essere abbastanza diversi l'uno dall'altro, sono anche abbastanza diversi l'uno dall'altro. I database di documenti sono in genere implementati con un'architettura scalabile per i tipi di documenti più comuni. Piattaforme di e-commerce, piattaforme di trading e sviluppo di app mobili sono tutti esempi di come queste piattaforme possono avvantaggiare un'azienda. L'obiettivo principale del confronto tra MongoDB e Postgres è fornire un confronto dettagliato dei principali database NoSQL. La capacità di un database a colonne di aggregare il valore di una singola colonna è ideale per analizzare rapidamente una colonna specifica.
Poiché il modo in cui i dati vengono scritti rende difficile la coerenza, devono fare affidamento su una varietà di fonti. I database a grafo sono ottimizzati per l'acquisizione e la ricerca di connessioni tra elementi di dati al fine di catturarli e cercarli. L'overhead associato all'unione di più tabelle in SQL viene eliminato con l'uso di questi metodi.
MongoDB in genere archivia i documenti in una raccolta nota come raccolta. È la raccolta di documenti che sono collegati tra loro da qualche aspetto. I dati nelle raccolte vengono in genere utilizzati da più applicazioni per archiviare i dati.
I dati di MongoDB sono archiviati in un albero B, il che significa che sono organizzati come bucket o livello. Un bucket è una raccolta di dati a cui un browser accede frequentemente. Il livello è più grande perché contiene più secchi. I dati in un albero B possono essere ordinati in ordine crescente per chiave.
Poiché MongoDB è così semplice da scalare, è una piattaforma fantastica per il ridimensionamento. Se il tuo cluster subisce un aumento del carico, potrebbe essere necessario aggiungere più server. Inoltre, MongoDB può essere raggruppato in cluster per fornire dati HA (alta disponibilità).
Perché i database Nosql stanno guadagnando popolarità
Nonostante il fatto che i database NoSQL stiano diventando sempre più popolari in molti casi, sono ancora un'alternativa ai database relazionali. I dati che non possono essere archiviati in un database relazionale, come grafici di grandi dimensioni o dati che cambiano regolarmente, sono particolarmente interessanti per loro.
Esempio di database colonnare Nosql
Un database a colonne è un sistema di gestione del database (DBMS) che archivia i dati in colonne anziché in righe. I sistemi orientati alle colonne sono spesso più veloci per i carichi di lavoro di analisi rispetto ai tradizionali sistemi orientati alle righe.
Ad esempio, un database a colonne potrebbe archiviare i dati dei dipendenti con ogni colonna contenente dati come ID dipendente, nome, titolo professionale, stipendio e così via. Un database orientato alle righe memorizzerebbe gli stessi dati con ogni riga contenente l'ID, il nome, la qualifica professionale, lo stipendio e così via di un dipendente.
NoSQL è un importante progresso nel campo dei dati relazionali perché elimina la necessità di sistemi altamente specializzati o dispendiosi in termini di tempo. I database NoSQL per documenti, grafici, colonne e valori di riga sono i quattro tipi principali. Gli archivi di documenti contengono sia schemi di dati complessi che coppie di chiavi associative. Le colonne del database organizzano i dati in colonne e funzionano allo stesso modo dei database relazionali. Esiste una scalabilità della griglia da orizzontale a infinito disponibile nei database di colonne . La compressione è un metodo di archiviazione ben fatto e gli archivi di colonne forniscono molto spazio di archiviazione. La velocità con cui vengono eseguite le query di aggregazione è in genere superiore a quella di un database relazionale.
A causa della natura orizzontale della progettazione dei dati, le app OLTP non possono essere utilizzate insieme agli archivi a colonne. I negozi a colonna , come soluzione, hanno il potenziale per essere estremamente potenti, ma hanno anche il potenziale per essere estremamente limitati. Sebbene le colonne forniscano minori garanzie di coerenza e isolamento rispetto alle righe, ogni riga deve essere riscritta più volte. I database NoSQL sono più vulnerabili agli attacchi online a causa della mancanza di funzionalità di sicurezza native. Se la sicurezza informatica è una priorità per te, dovresti utilizzare un modello relazionale o definire il tuo schema.
Database Nosql
Un database NoSQL è un database non relazionale che non utilizza il tradizionale modello di database relazionale basato su tabelle. I database NoSQL sono spesso usati per big data e applicazioni web in tempo reale.
Database I database NoSQL non memorizzano i dati nei tradizionali database relazionali . I tipi di documento, i tipi di valore-chiave, i tipi di colonne larghe e i tipi di grafico sono i più comuni. Il costo dell'archiviazione dei dati è diminuito drasticamente negli ultimi anni, con il conseguente sviluppo di database NoSQL. Possono archiviare una grande quantità di dati non strutturati, consentendo agli sviluppatori di selezionare quali aspetti dei dati desiderano salvare. Database di documenti, database di valori-chiave, archivi a colonne larghe e database a grafo sono esempi di database NoSQL. Poiché non sono richiesti join, le query vengono eseguite più velocemente. È possibile utilizzare casi d'uso ad alta intensità di dati come analisi finanziarie e letture IoT da lettiere per gatti intelligenti, mentre possono essere utilizzate applicazioni meno serie come casi d'uso divertenti e divertenti come imballaggi alimentari intelligenti.
In questo tutorial, esamineremo quando e perché dovresti prendere in considerazione i database NoSQL. Inoltre, esamineremo alcuni dei malintesi più comuni sui database NoSQL. Secondo DB-Engines, MongoDB è il database NoSQL più popolare al mondo. In questo tutorial imparerai come interrogare un database MongoDB senza installare nulla sul tuo computer. I cluster di database sono un esempio di database MongoDB. Non appena avrai un cluster, Atlas inizierà a memorizzare i dati. Hai tre opzioni per creare un database in Atlas Data Explorer, MongoDB Shell o MongoDB Compass: manuale o automatizzato.
In questo caso, verrà importato il set di dati campione di Atlas. I database NoSQL offrono numerosi vantaggi oltre ai modelli di dati flessibili, al ridimensionamento orizzontale, alle query velocissime e alla facilità d'uso. Esplora dati può essere utilizzato per inserire nuovi documenti, modificare documenti esistenti ed eliminarli. L'utilizzo del framework di aggregazione è uno strumento estremamente potente per l'analisi dei dati. L'utilizzo di grafici per visualizzare i dati archiviati in Atlas e Atlas Data Lake è il modo più semplice per farlo.
Un database di valori-chiave è il tipo più semplice di NoSQL, con più tabelle contenenti chiavi e valori. La chiave è richiesta solo per l'accesso ai dati, semplificandone la lettura e la scrittura. Tuttavia, questo tipo di database non è adatto a set di dati di grandi dimensioni perché ogni chiave nel database deve essere univoca.
I dati vengono archiviati in tabelle contenenti colonne, che memorizzano le chiavi e i valori dei database basati su colonne. Grazie alla sua versatilità, un database basato su colonne può archiviare i dati per un periodo di tempo più lungo rispetto a un database senza colonne.
I database di documenti, al contrario dei database di colonne, memorizzano i dati in tabelle con colonne che memorizzano chiavi e valori. I database basati su documenti, invece, memorizzano i dati in file, simili alle e-mail. Poiché i documenti sono semplici da leggere e comprendere, i dati possono essere cercati e visualizzati in modo semplice.
Un database basato su grafici è simile a un database basato su documenti in quanto i dati vengono archiviati in tabelle contenenti colonne con chiavi e valori. Al contrario, i grafici, che sono simili alle reti in termini di archiviazione dei dati, sono archiviati in database basati su grafici. I nodi di dati possono essere collegati e i modelli possono essere identificati con facilità.
Tipi di database Nosql per ogni esigenza
I database di documenti come MongoDB sono adatti per le applicazioni che devono archiviare le informazioni in un formato flessibile e modulare. In MongoDB, JSON, testo e BSON sono tutti supportati. Questo lo rende una scelta eccellente per applicazioni come blog e wiki, che memorizzano grandi quantità di dati non strutturati.
Cassandra e altri database basati su colonne sono opzioni eccellenti per le applicazioni che devono archiviare grandi quantità di dati in un formato a colonne. I formati di dati come Avro e il formato binario di Cassandra possono essere utilizzati in aggiunta all'archiviazione basata su testo all'interno di HBase. Poiché ha la capacità di archiviare dati che non possono rientrare in un database relazionale, è adatto per applicazioni che richiedono una grande quantità di dati.
DynamoDB e altri database chiave-valore sono particolarmente adatti alle applicazioni che in genere archiviano quantità di dati medio-piccole. DynamoDB, ad esempio, supporta i formati di dati JSON e binari. Ciò lo rende una scelta eccellente per le applicazioni che archiviano dati troppo piccoli per una tabella relazionale e a cui si accede frequentemente ma che non richiedono un formato specifico, nonché per le applicazioni che devono archiviare dati a cui si accede frequentemente ma che non richiedono uno specifico formato.
È adatto per applicazioni che richiedono l'integrazione di elementi di dati archiviati in database a grafo, come Neo4j. Ad esempio, i formati di dati come JSON, Atom e Graph possono essere utilizzati nei database a grafo. È ideale per le applicazioni che devono archiviare dati troppo complessi per essere archiviati in un database relazionale o che archiviano dati a cui si accede frequentemente ma che non richiedono l'archiviazione in un formato specifico.

Database colonnare open source
Un database a colonne è un tipo di database che archivia i dati in colonne anziché in righe. Questo tipo di database viene spesso utilizzato per applicazioni di data warehousing e analisi perché può fornire prestazioni e scalabilità migliori rispetto a un database tradizionale basato su righe.
Sono disponibili numerosi database colonnari open source, come Apache Cassandra, Apache HBase e Apache Drill. Ognuno di questi database ha i suoi punti di forza e di debolezza, quindi è importante scegliere quello giusto per le tue esigenze specifiche.
Questi database sono ideali per un flusso di lavoro di analisi efficiente perché sono veloci e scalabili allo stesso tempo. Invece di archiviare i dati in righe, le colonne vengono utilizzate nel database a colonne. L'utilizzo dell'archiviazione basata su colonne migliora le prestazioni delle query del database riducendo in modo significativo il numero di tentativi di I/O. È stato utilizzato per alimentare Amazon Redshift e Snowflake, nonché altri Relational Warehouse. Per migliorare il throughput dei database a colonne, vengono utilizzati cluster hardware a basso costo per ridimensionarli. Nei database tradizionali le righe sono suddivise in varie sezioni di dati. Gli elementi più rilevanti in un database a colonne sono accessibili in pochi secondi.
Anche se il database è di grandi dimensioni, ciò aumenta la velocità delle query. Anche il costo dell'elaborazione e dell'archiviazione della maggiore quantità di dati è in aumento. Parquet e ORC sono due dei formati più utilizzati per le colonne nei database. Parquet viene utilizzato per presentare colonne piatte di dati in modo più efficace. ORC è un formato di file appositamente progettato per i carichi di lavoro Hadoop ed è stato ottimizzato per letture di streaming di grandi dimensioni. Hevo Data, una pipeline di dati senza codice, ti consente di integrare i dati provenienti da vari database con oltre 100 altre fonti e di caricarli nel tuo strumento di BI preferito. Apache Druid è un database di analisi in tempo reale basato su software open source in grado di eseguire query OLAP su set di dati di grandi dimensioni a una velocità molto più elevata.
Il motore di archiviazione dati distribuito open source Apache Kudu viene utilizzato per eseguire processi analitici rapidi su enormi quantità di informazioni. Il modello di archiviazione di MonetDB si basa sulla frammentazione verticale e la sua architettura di esecuzione delle query si basa su computer moderni. Il motore di reporting analitico di ClickHouse consente la generazione di report in tempo reale. BigQuery è il risultato del motore di query distribuito di Google, noto come Dremel. L'architettura serverless di Dremel è in grado di elaborare terabyte di dati in pochi secondi utilizzando il calcolo distribuito. Compressione, proiezione just-in-time e partizionamento orizzontale e verticale sono alcuni dei vantaggi dell'archiviazione basata su colonne. I dati possono essere archiviati in righe in un database a colonne, che è un database orientato alle righe.
Scalano utilizzando cluster con tecnologia a basso costo per aumentare il throughput. I database a colonne possono essere utilizzati per una varietà di scopi nell'elaborazione di big data, nella business intelligence (BI) e nell'analisi. I dispositivi Internet of Things (IoT) memorizzano una grande quantità di dati nei loro data center.
I tre database di archiviazione dei dati orientati alle colonne più popolari
Apache Cassandra è un noto sistema di archiviazione dei dati in una varietà di database orientati alle colonne. Cassandra è un progetto open source lato server in grado di gestire enormi quantità di dati su molti server di prodotti. DynamoDB, invece, utilizza un modello di database NoSQL e può archiviare qualsiasi tipo di dati. MariaDB mantiene il modello relazionale e SQL, consentendo anche una generazione di query analitiche più rapida e semplice, rendendolo una scelta popolare per molti database a colonne.
Miglior database a colonne
Non esiste una risposta definitiva a questa domanda poiché dipende dalle preferenze e dalle esigenze individuali. Tuttavia, alcuni dei database colonnari più popolari includono Amazon Redshift, Google BigQuery e Microsoft SQL Server. Questi database sono tutti altamente scalabili e offrono prestazioni eccellenti per i carichi di lavoro di data warehousing e analisi.
I dati in un database a colonne sono archiviati in colonne anziché in righe. Rispetto ai tradizionali database a righe , i database a colonne offrono una serie di vantaggi, tra cui velocità ed efficienza. Sadas Engine è il sistema di gestione di database a colonne più potente e flessibile disponibile sia on-premise che nel cloud. ClickHouse è un sistema di gestione di database open source facile da usare. Amazon Redshift, il data warehouse su cloud più veloce al mondo, continua a crescere in velocità. ClickHouse utilizza tutto l'hardware disponibile al massimo delle sue potenzialità per elaborare ogni richiesta il più rapidamente possibile. Il motore di ricerca e analisi di Rockset alimenta i display del dashboard in tempo reale e le app in tempo reale.
Vertica è il database analitico avanzato più veloce e scalabile del mercato. Il linguaggio ANSI SQL è ideale per l'analisi di petabyte perché è in grado di gestire i dati a velocità fulminee eliminando al contempo il sovraccarico operativo. Analisi su richiesta su larga scala con un costo di proprietà triennale inferiore del 26%-34% rispetto alle alternative di data warehouse su cloud. Puoi crittografare i tuoi dati su richiesta ea casa con chiavi di crittografia gestite dall'azienda oppure puoi impostarli sulla crittografia a piacimento. Greenplum Database è una piattaforma di dati massicciamente parallela open source che fornisce funzionalità di analisi, machine learning e intelligenza artificiale. Lo strumento fornisce analisi dei dati in tempo reale su volumi di dati nell'ordine dei petabyte alla velocità della luce. Con il suo design di base, Druid combina idee provenienti da data warehouse, database di serie temporali e sistemi di ricerca per creare un database di analisi ad alte prestazioni in tempo reale.
Apache 2 è il codice sorgente di questo progetto. La piattaforma MariaDB, un database open source aziendale, è la base di questa soluzione. Questa piattaforma può supportare un'ampia gamma di carichi di lavoro transazionali, analitici e ibridi. MariaDB può essere implementato su hardware di base o in un cloud pubblico, a seconda del tipo di hardware utilizzato. Studenti, insegnanti, ricercatori, imprenditori, piccole imprese e multinazionali di tutto il mondo possono entrare a far parte della comunità MonetDB. Forniamo database-as-a-service per CrateDB, che è completamente gestito. L'archiviazione tabella semplifica la scalabilità dei dati eliminando la necessità di partizionamento manuale.
Tre volte i dati archiviati di un'area vengono replicati usando l'archiviazione con ridondanza geografica. È semplice portare le applicazioni legacy o crearne di nuove con il semplice modello di dati di Kudu. Parquet consente di specificare gli schemi di compressione per colonna ed è a prova di futuro in modo che possano essere aggiunti nuovi schemi di compressione quando necessario. Hypertable, come suggerisce il nome, è progettato per risolvere il problema della scalabilità alle proprie condizioni. È progettato per supportare carichi di lavoro OLAP basati su DBMS colonnare InfiniDB . Le prestazioni di QikkDB nei big data e nelle complesse operazioni poligonali non hanno eguali. Il database qikkDB è costruito con le seguenti caratteristiche: È un database colonnare di serie temporali storiche multipiattaforma ad alte prestazioni con un motore di calcolo in memoria.
Q, un processore di streaming e un linguaggio di programmazione, ha lo scopo di permetterti di esprimerti in tempo reale. Sorted Index, Bitmap Index e Inverted Index sono le tre tecnologie di indicizzazione che possono essere collegate. Apache Versione 2.0 è stato concesso in licenza per questo progetto.
I database orientati alle colonne sono il futuro
Un gran numero di database è stato progettato attorno alle colonne negli ultimi anni. Poiché questi database memorizzano i dati in righe e colonne, sono semplici da utilizzare e gestire. Sono disponibili diversi database orientati alle colonne, tra cui MariaDB, CrateDB, ClickHouse, Greenplum Database, Apache Hbase, Apache Kudu, Apache Parquet, Hypertable e MonetDB. I dati di documenti, grafici e colonne possono essere generati all'interno di DynamoDB utilizzando un modello di database NoSQL. MongoDB, la società dietro il database dell'archivio documenti, ha annunciato il rilascio dell'indicizzazione columnstore, che consente agli sviluppatori di creare query analitiche nelle loro applicazioni.
Esempio di database colonnare
Un database a colonne è un tipo di database che archivia i dati in colonne anziché in righe. Questo tipo di database viene spesso utilizzato per applicazioni di data warehousing e analisi perché può fornire prestazioni e scalabilità migliori rispetto a un database tradizionale basato su righe. Un esempio di database a colonne è Apache HBase.
Le operazioni del database differiscono da quelle di altri database in quanto le colonne in genere distribuiscono le informazioni nelle righe. La capacità di analizzare set di dati di grandi dimensioni è particolarmente interessante per i database a colonne. Gli archivi di documenti che utilizzano database NoSQL sono cresciuti in popolarità negli ultimi anni. Anche i database a grafo stanno diventando sempre più popolari man mano che sempre più persone li utilizzano perché possono mappare dati altamente collegati in rete in modo molto preciso. Per molto tempo sono stati utilizzati sistemi di gestione di database colonnari. Nonostante ci siano ancora poche implementazioni disponibili, sono stati sviluppati diversi sistemi. L'accesso alle applicazioni transazionali è in genere diverso dall'accesso ad altre applicazioni. Questa attività verrebbe eseguita molto più lentamente in un database a colonne rispetto a un database convenzionale .
Perché i database orientati alle colonne stanno diventando sempre più popolari
I database orientati alle colonne come Cassandra, MariaDB e CrateDB stanno guadagnando popolarità come soluzioni di archiviazione dati per applicazioni che gestiscono grandi quantità di dati. Poiché i dati possono essere archiviati in un database con più righe della stessa tabella (famiglia di colonne), è più semplice archiviare i dati e migliorare le prestazioni.
Sono disponibili diversi database orientati alle colonne, come MariaDB, CrateDB, ClickHouse, Greenplum Database, Apache Hbase, Apache Kudu e Apache Parquet. Tutti questi database sono open source e sono stati utilizzati con successo in una varietà di applicazioni.