
Per recuperare un valore si utilizza il metodo Get() utilizzando le tabelle hash per archiviare i dati in un database NoSQL
Pubblicato: 2022-12-04Una tabella hash è una struttura di dati che memorizza coppie chiave-valore. È un modo semplice per archiviare i dati in un database NoSQL. La chiave viene utilizzata per cercare il valore nella tabella. Il valore può essere qualsiasi cosa, inclusa un'altra struttura di dati. Le tabelle hash vengono spesso utilizzate per archiviare i dati in un database NoSQL perché sono semplici ed efficienti. Possono essere utilizzati per archiviare dati di qualsiasi tipo, inclusi stringhe, numeri interi, float e oggetti. Le tabelle hash sono anche note come mappe hash o dizionari. Per utilizzare una tabella hash, devi prima creare una tabella. Le tabelle vengono create utilizzando il metodo createTable(). Il primo argomento è il nome della tabella e il secondo argomento è la funzione hash . La funzione hash viene utilizzata per mappare le chiavi ai valori. Una volta creata una tabella, puoi inserire i dati in essa utilizzando il metodo put(). Il primo argomento è la chiave e il secondo argomento è il valore. Per recuperare un valore, si utilizza il metodo get(). Il primo argomento è la chiave e il secondo argomento è il valore predefinito. Il valore predefinito viene restituito se la chiave non viene trovata nella tabella. Le tabelle hash sono un modo semplice ed efficiente per archiviare i dati in un database NoSQL. Per utilizzare una tabella hash, devi prima creare una tabella. Una volta creata una tabella, puoi inserire i dati in essa utilizzando il metodo put().
Cos'è l'hashing in Nosql?
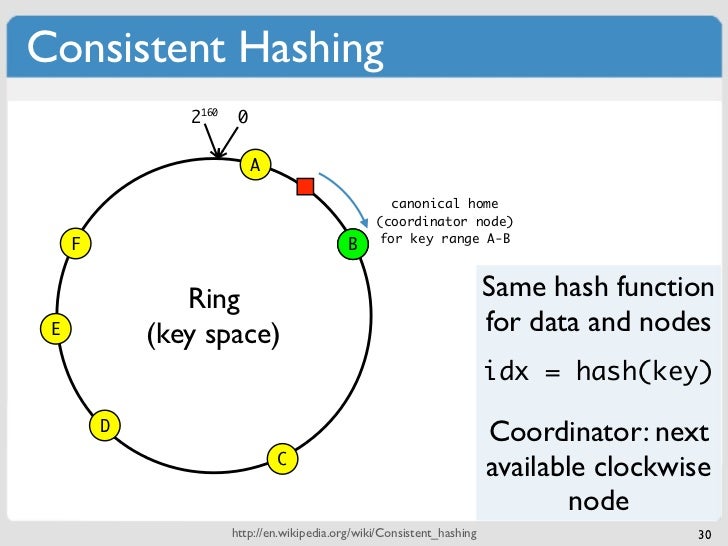
L'hashing è una tecnica utilizzata per indicizzare e recuperare elementi in un database o in una struttura di dati. Funziona trasformando la chiave dell'elemento in un hash, che viene quindi utilizzato per indicizzare l'elemento nel database o nella struttura dati.
I vantaggi dei database Nosql
I database NoSQL sono la tendenza più in voga in questo momento nella tecnologia. Grazie alle sue capacità di ridimensionamento orizzontale, è più adatto per dati di volume elevato rispetto a un database relazionale tradizionale. Se stai cercando un database di big data in grado di gestire il tuo set di dati in crescita, i database NoSQL dovrebbero essere in cima alla tua lista.
Nosql può avere tabelle?
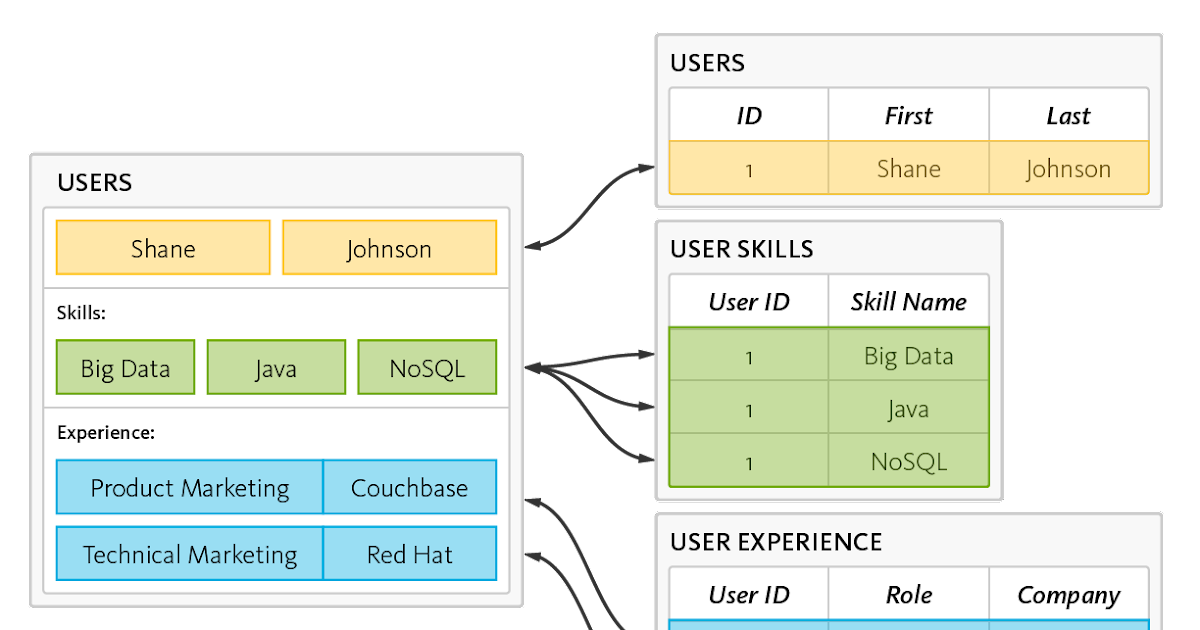
Non esiste un formato prestabilito per ciascun documento. Database con righe e colonne simili a RDBMS: i database NoSQL a colonne larghe memorizzano i dati in tabelle con righe e colonne simili a RDBMS, ma i nomi e i formati variano da riga a riga. Le colonne del database contenenti colonne correlate tra loro sono raggruppate in database a colonne grandi.
NoSQL ha fatto un forte ritorno nel 2011, diventando la prossima grande novità nell'architettura di sistema. Il database NoSQL è disponibile in una varietà di versioni: alcune di esse vengono persino archiviate in formato tabella. Non è possibile stabilire relazioni tra i dati e l'elemento comune tra tutti è che non lo fanno. Anche se si utilizza un database NoSQL, SQL non è necessario. Un database NoSQL e un database SQL possono coesistere. NoSQL differisce dagli approcci tradizionali all'atomicità, alla coerenza, all'isolamento e alla durabilità. Puoi inviare alcuni dati a una giurisdizione non attendibile e altri dati a una giurisdizione attendibile utilizzando lo sharding perché i dati sono crittografati in modo sicuro. Utilizzando lo sharding nei database NoSQL, che consente a più macchine di elaborare i dati contemporaneamente, i dati possono essere collocati nel posto giusto al momento giusto.
Sono ideali per archiviare dati che non cambiano molto o cambiano molto rapidamente nel tempo. È anche possibile copiare un backup da un altro server sulla rete perché i dati sono solo un singolo file. Nonostante i vantaggi dei database tradizionali, molte applicazioni richiedono ancora il tipo di vincoli, la coerenza e le garanzie fornite da un database tradizionale. La novità dei database NoSQL è stata a lungo superata dai tradizionali database relazionali. L'implementazione di un database NoSQL può essere difficile e richiede un alto livello di gestione e provider. Man mano che i database NoSQL guadagnano popolarità, la domanda di competenze NoSQL cresce poiché le grandi aziende richiedono dati ad alta velocità. Se puoi aiutare a supportare il database relazionale o il database non relazionale di un'altra azienda, potresti guadagnare un buon stipendio.
Come vengono chiamate le tabelle in Nosql?
I database NoSQL (noti anche come SQL) possono archiviare i dati in un modo diverso rispetto ai database relazionali e, pertanto, non vengono generalmente utilizzati per archiviare i dati in una tabella. In generale, i database NoSQL sono costituiti da una serie di tipi di dati basati sui loro modelli di dati. I tipi di documento, i tipi di valore-chiave, i tipi di colonne larghe e i tipi di grafico sono i più comuni.
Collezioni MongoDB: A Prime
Ci sono alcune cose da tenere a mente sulle raccolte MongoDB. Gli oggetti di database sono raccolte archiviate in un database. Il comando mongo shell o il driver mongoDB per PHP sono entrambi disponibili per crearlo.
Le tabelle di database non possono essere utilizzate per creare raccolte. È impossibile inserire dati in una raccolta nel modo in cui possono essere inseriti in una tabella. Anziché inserire dati nella raccolta utilizzando i suoi metodi, li inserisci utilizzando i metodi della raccolta.
L'accesso a un documento in una raccolta è possibile utilizzando il suo nome come parametro per il metodo find del documento.
È inoltre possibile accedere a un documento da una raccolta in cui risiede. Il percorso include una barra seguita dal nome della raccolta e dal nome del documento.
Una raccolta differisce da una tabella in quanto i documenti in una raccolta potrebbero non essere sempre organizzati in ordine cronologico. MongoDB considera l'indice del documento come una misura dell'ordine in cui i documenti sono organizzati in una raccolta durante il calcolo dell'indice.
Un documento può essere inserito in una raccolta seguendo il codice nell'esempio seguente. Successivamente, il codice crea una nuova raccolta e vi inserisce un documento.
*br* Crea una nuova collezione da zero. La raccolta var viene utilizzata per rappresentare la raccolta. MongoDB() aggiunge una raccolta in myCollection come alternativa.
Ciò può essere ottenuto selezionandolo dal menu a discesa della raccolta. Inserito. Il nome dell'uomo è Giovanni. Ho 27 anni.
Puoi unirti alle tabelle Nosql?
Una clausola congiunta combina le righe di due o più tabelle utilizzando una colonna correlata tra di loro. Quando un utente sta tentando di estrarre dati da tabelle collegate gerarchicamente, i join vengono in genere utilizzati nei database Oracle NoSQL.
I pro ei contro di Nosql
NoSQL, d'altra parte, offre una serie di vantaggi, tra cui scalabilità, rapido accesso ai dati, sviluppo semplice e bassi costi di manutenzione.
Come viene utilizzata la tabella hash nel database?
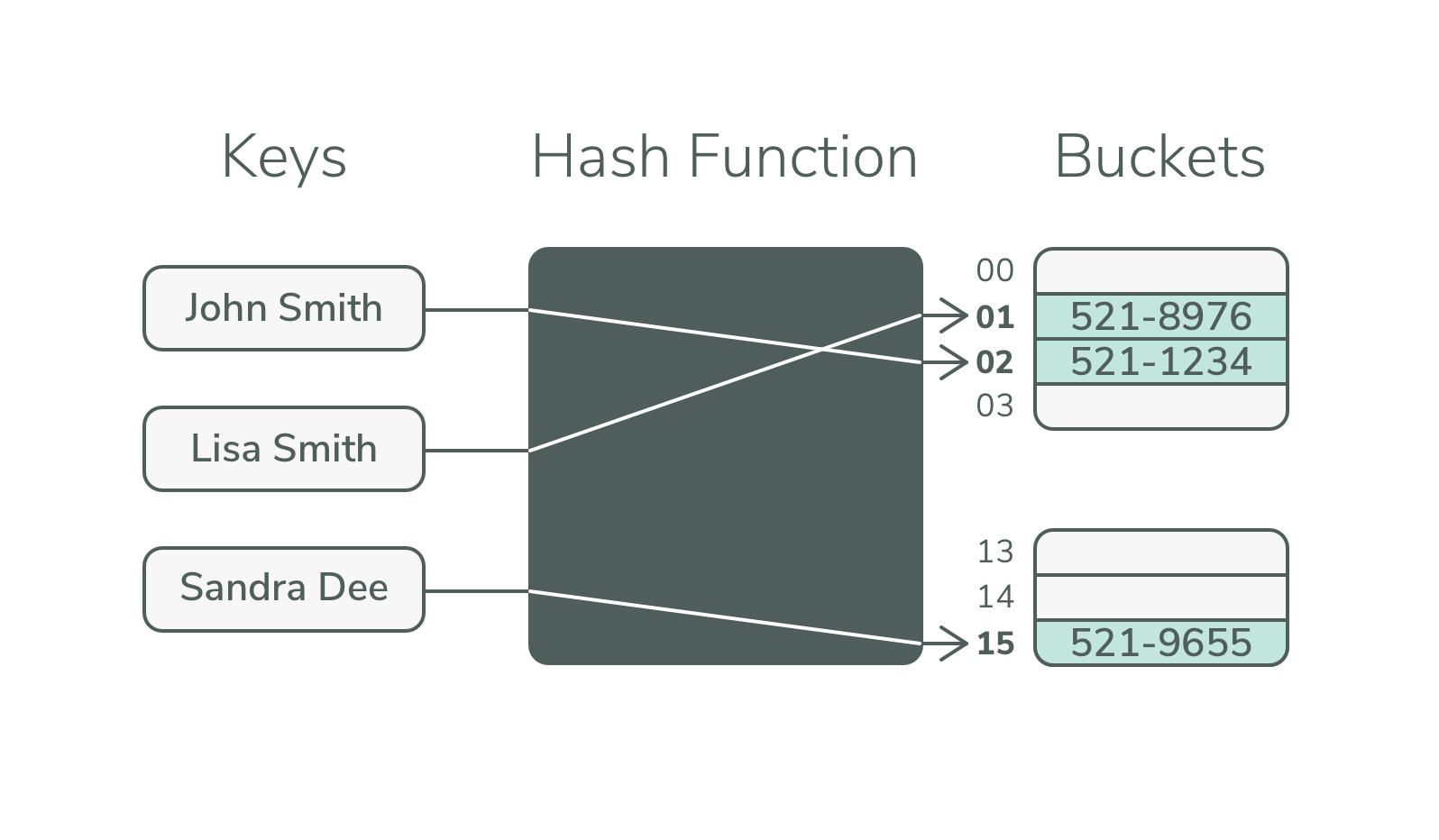
Una tabella hash memorizza i dati in una struttura dati che è una combinazione di chiavi e coppie di valori. Calcola un indice utilizzando una funzione hash per posizionare un elemento in un array in cui può essere inserito o cercato. Se si utilizza la funzione di hashing corretta , i risultati possono essere eccellenti.
La tecnica dell'hashing può essere utilizzata per identificare un oggetto specifico esaminando un gruppo di oggetti simili. Utilizzando le funzioni di hashing, le chiavi grandi possono essere convertite in chiavi piccole. Successivamente, i valori vengono archiviati in una struttura di dati nota come tabella hash. Un metodo per l'hashing viene sviluppato in due fasi: inizializzazione e convalida. La chiave hash viene utilizzata per recuperare rapidamente l'elemento dalla tabella hash. Una tabella hash è una struttura dati che memorizza coppie chiave/valore. L'indice viene calcolato utilizzando una funzione hash utilizzata per calcolare un indice per ogni coppia di chiavi o valori.
L'indice di una stringa specifica sarà uguale alla somma dei valori ASCII moltiplicati per il rispettivo ordine nella stringa dopo di che diventa modulo (2069). Una delle tecniche di risoluzione delle collisioni più comuni è l'hashing. In genere, viene implementato collegando le liste. Un elenco collegato è incluso in ogni elemento di una tabella hash come parte del suo concatenamento. le ricerche costano denaro perché comportano la scansione delle voci nell'elenco collegato per la chiave richiesta. Con la funzione hash, verrà restituito un numero intero compreso tra 0 e 19. Quando si utilizzano indirizzi aperti anziché elenchi collegati, tutti i record di ingresso vengono archiviati nell'array stesso.

Un indirizzo aperto è un nome che si riferisce al fatto che la posizione o l'indirizzo di un elemento non è determinato dal valore hash dell'elemento. Le sonde lineari vengono utilizzate per risolvere le collisioni Hash nell'indirizzamento aperto. L'indice CodeMonk e Hashing ha lo stesso indice (ovvero 2, quindi l'hashing dovrebbe essere a 3 in questo caso) e l'intervallo tra le successive sonde deve essere uno. Si supponga che l' indice con hash per una voce sia index e che vi sia uno slot occupato in index. Se non hai trovato uno slot vuoto prima, devi iniziare attraversando una sequenza specifica.
L'utilizzo di una tabella hash nella struttura dei dati è un metodo economico per archiviare dati di dimensioni fisse. Sono particolarmente adatti per operazioni che comportano la ricerca di un elemento con una chiave specifica, l'indicizzazione di strutture dati e così via. Una tabella hash non è adatta a tutte le operazioni. Le tabelle hash, d'altra parte, non supportano tutti gli elementi le cui chiavi si trovano all'interno di un intervallo specifico. Al contrario, l'hashing dinamico, invece, aggiunge e rimuove i bucket di dati secondo necessità, senza richiedere alcuna modifica. Ciò fornisce una migliore comprensione di alcune operazioni, come trovare l'elemento con le chiavi più grandi o più piccole. In media, la carnagione O(log n) è quasi incolore. Le tabelle hash sono efficienti in generale, ma non per tutti i tipi di dati. In alcuni casi, l'hashing dinamico può fornire una soluzione migliore rispetto all'hashing statico , ad esempio trovare un elemento con la chiave più alta o più piccola.
Come viene utilizzato l'hashing nei database?
Il metodo hash indicizza e recupera gli elementi dai database perché è più veloce cercare un elemento specifico con una chiave con hash più breve anziché utilizzare il valore originale. Se stai cercando la posizione di un record di dati su un disco senza utilizzare strutture di indice, l'hashing è un ottimo modo per farlo.
Sql usa Hashtable?
Se SQL Server lo richiede, genera le proprie tabelle hash. È impossibile creare una struttura come un indice o un programma relativo all'indice. Ad esempio, l'hash join di SQL Server viene eseguito utilizzando le tabelle hash.
Mysql usa tabelle hash?
Sia gli indici hash che i database possono essere utilizzati in MySQL, ma gli indici hash sono più lenti per l'utilizzo del database. Poiché le chiavi lunghe (in particolare le stringhe di caratteri) in genere non sono abbastanza grandi da supportare un indice, gli indici hash sono in genere utili solo se utilizzati con chiavi lunghe (in particolare stringhe di caratteri).
Cos'è la tabella hash in Sql?
I dati possono essere memorizzati in modo associativo in una tabella hash . In una tabella hash, il valore di indice di ogni valore di dati è il proprio, che viene memorizzato in un formato di matrice. Possiamo accedere ai dati molto più rapidamente se capiamo cosa c'è nell'indice dei dati desiderati.
Possiamo usare Nosql per la transazione?
Le transazioni multi-chiave non sono supportate dai database NoSQL. Più elementi di dati vengono raggruppati atomicamente ed elaborati in un'unica operazione, consentendo di eseguire più transazioni multi-chiave. Un database NoSQL è tipicamente strutturato in modo tale che ogni operazione chiave sia seguita da una semplice operazione put and get.
Le soluzioni NoSQL hanno una semantica transazionale inferiore rispetto ai database relazionali, ma possono ospitare operazioni atomiche a un certo livello. Se hai familiarità con Node.js o Ruby/Rack, Heroku.com può essere utilizzato per creare rapidamente un piccolo mock-up. Vorrei scusarmi per non averlo ancora implementato. Le proprietà dei sistemi di gestione del database sono necessarie per gestire le transazioni. La maggior parte degli strumenti NoSQL migliora i criteri di coerenza delle operazioni al fine di garantire tolleranza ai guasti e disponibilità di scalabilità. Prendi in considerazione l'utilizzo di database in memoria, orientati alle colonne e distribuiti come VoltDB. Puoi utilizzare "Transazioni ottimistiche" per raggiungere questo obiettivo, ma ti consiglio di assicurarti di comprendere le garanzie di atomicità dell'implementazione del database (ad esempio, che tipo di operazioni di scrittura e lettura sono atomiche).
C'è qualche discussione sulle transazioni HBase in rete? In generale, NoSQL utilizza archivi di dati chiave/valore: puoi utilizzarlo nel tuo RDBMS preferito e mantenere le cose buone, come transazioni, proprietà ACID e supporto DBA, realizzando al contempo i vantaggi delle prestazioni e della flessibilità di NoSQL. Se la funzione confronta e imposta è abilitata, le transazioni ottimistiche possono essere implementate sopra le soluzioni NoSQL.
Quale database è il migliore per le transazioni?
È probabile che i database SQL siano l'opzione più efficace nei casi in cui la stragrande maggioranza dei dati è strutturata. Se utilizzati in sistemi orientati alle transazioni come strumenti di gestione delle relazioni con i clienti, software di contabilità o piattaforme di e-commerce, i database SQL sono un'ottima scelta.
Quando non dovrebbe essere usato Nosql?
Se hai bisogno di flessibilità di runtime flessibile per la tua applicazione, dovresti anche evitare NoSQL. Se è richiesta coerenza e non ci saranno cambiamenti su larga scala in termini di volume di dati, i database SQL sono un'opzione migliore.
Quali sono i limiti di Nosql?
Quali sono i pro ei contro della tecnologia di database NoSQL ? Uno dei principali svantaggi dei database NoSQL è che non supportano le transazioni ACID (atomiche, coerenti, di isolamento e durabilità) su più documenti. Se uno schema è progettato correttamente, è ragionevole aspettarsi che l'atomicità a record singolo sia possibile per un'ampia gamma di applicazioni.
Quale non si applica a Nosql?
Quali sono i diversi tipi di database NoSQL e come vengono utilizzati? La piattaforma Microsoft SQL Server gestisce e semplifica una varietà di applicazioni di database.
Esempio di database Nosql
Un database NoSQL è un database non relazionale che non richiede uno schema fisso. I database NoSQL vengono spesso utilizzati per gestire grandi quantità di dati non strutturati. Un esempio di database NoSQL è MongoDB. MongoDB è un programma di database orientato ai documenti multipiattaforma gratuito e open source. Classificato come programma di database NoSQL , MongoDB utilizza documenti simili a JSON con schemi.
Un database NoSQL, noto anche come archivio Big Data, presenta una serie di vantaggi rispetto a un database relazionale tradizionale, come la scalabilità, le prestazioni e la capacità di gestire un gran numero di oggetti.
La crescita dei database NoSQL è stata guidata da diversi fattori, tra cui la scalabilità, le prestazioni e la capacità di gestire un gran numero di oggetti.
Come creare una tabella hash in Sql Server
Una tabella hash è una struttura di dati utilizzata per archiviare coppie chiave-valore. In SQL Server, una tabella hash viene implementata come una tabella con due colonne, una per le chiavi e una per i valori. Le chiavi vengono utilizzate per indicizzare la tabella e i valori sono i dati archiviati nella tabella.
Database Nosql Couchbase
Un database NoSQL è un database non relazionale che non utilizza il tradizionale modello di database relazionale basato su tabelle. Utilizza invece un modello di dati privo di schemi, che gli consente di essere più flessibile e scalabile. Couchbase è un tipo di database NoSQL che utilizza un modello di dati orientato ai documenti. È progettato per applicazioni interattive online che devono gestire grandi quantità di dati.