
Perché la coerenza finale è essenziale per gli archivi dati
Pubblicato: 2022-11-17La coerenza finale è una proprietà degli archivi dati in cui i dati che sono stati scritti nell'archivio potrebbero non essere immediatamente disponibili per la lettura. Il negozio può eventualmente rendere i dati disponibili per la lettura, ma non è garantito che lo faccia. I sistemi di archiviazione dati che presentano una coerenza finale possono farlo per una serie di motivi, inclusa la necessità di migliorare le prestazioni o garantire la disponibilità a fronte di partizioni di rete.
È molto più difficile realizzare un'implementazione dell'archivio dati del documento piuttosto che realizzare un modello relazionale. Inoltre, i dati del negozio in transito sono molto più difficili da convertire rispetto ai dati RDBMS. Questa opportunità manca a sviluppatori e architetti che temono o non sono consapevoli delle conseguenze dei propri errori. Suddivideranno le transazioni atomiche in cui dovrebbero consistere in pezzi logici dimenticando che la replica e la latenza sono cose, oltre a trascinare sistemi di terze parti al loro interno. Ad un certo punto, tutto il sistema verrà esternalizzato e qualcun altro subentrerà quando il dipartimento verrà sciolto.
Di conseguenza, i database NoSQL supportano spesso una coerenza graduale piuttosto che una coerenza costante. Non è richiesta una forte coerenza dei dati perché non supportano le transazioni di database. È sempre possibile ottenere la coerenza finale assicurando che tutti gli aggiornamenti vengano consegnati a tutte le repliche contemporaneamente.
Il fatto che l'eventuale coerenza si riferisca al processo di replica tra i nodi primari e secondari e il fatto che l'applicazione potrebbe non essere sempre aggiornata con la lettura dei dati, rende le letture primarie la strada da percorrere.
Quando i database NoSQL utilizzano il modello di coerenza finale , non forniscono lo stesso livello di coerenza dei dati dei database SQL. Se i dati non sono coerenti, ciò li rende inadatti a transazioni come transazioni bancarie e bancomat, che richiedono un'integrità immediata.
Cosa significa coerenza finale in Nosql?
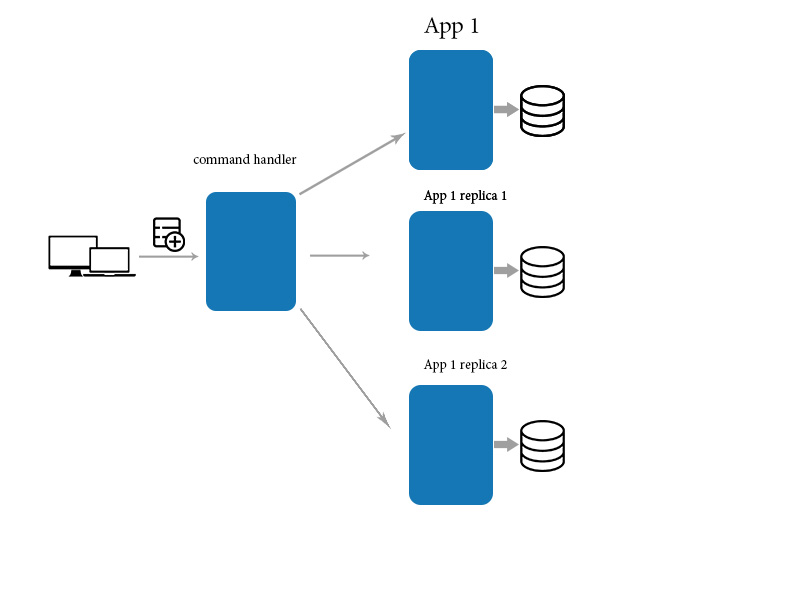
La coerenza finale è una garanzia che, se non vengono apportati nuovi aggiornamenti a un dato, alla fine tutti gli accessi a quei dati restituiranno l'ultimo valore aggiornato. Ciò è in contrasto con la consistenza forte , che richiede che ogni lettura riceva la scrittura più aggiornata.
Il concetto di comportamento alla fine coerente ha preso piede per la prima volta alla fine degli anni '70. Amazon ha rilasciato DynamoDB un decennio fa, che ha acceso la popolarità del termine. Il database NoSQL è stato sviluppato per potenziare i social media e i servizi di streaming. i dati non strutturati, come immagini, video e file audio, possono essere gestiti con facilità. Utilizzando il modello Volt Active Data, è possibile garantire che i dati vengano replicati su più database in tempo reale. Le piattaforme dati sono immediatamente coerenti e impediscono scritture e letture incoerenti. Di conseguenza, sono estremamente in grado di soddisfare i requisiti di latenza del 5G gestendo rapidamente questo processo.
La coerenza può essere una caratteristica preziosa di un sistema distribuito. Garantisce che i valori vengano archiviati e accessibili da più nodi in modo coerente, indipendentemente dal fatto che tali nodi vengano aggiornati contemporaneamente. È fondamentale che i sistemi, come il Domain Name System, siano in grado di mantenere una visione coerente dei dati.
La coerenza che deriva dal completamento di un progetto a volte può essere difficile da raggiungere. Può essere difficile garantire che tutti i nodi ricevano gli stessi aggiornamenti a causa della varietà di metodi disponibili. Il valore della coerenza è innegabile e i sistemi che la utilizzano potrebbero essere più affidabili a lungo termine.
Cos'è l'eventuale coerenza in Cassandra?

Cassandra ottiene tutte queste funzionalità con un sistema di storage coerente in grado di soddisfare i requisiti di prestazioni, affidabilità, scalabilità e disponibilità in produzione. Infine, coerente significa che tutti gli aggiornamenti vengono infine condivisi con tutte le repliche.
La coerenza è qualcosa che Cassandra può ottenere con la sua coerenza sintonizzabile. Il risultato R=w <=N dovrebbe essere coerente se N è il numero di nodi. Per ottenere coerenza, Cassandra esegue il backup di ogni colonna e campo di ogni colonna. C'è un meccanismo dietro questo stato che gli permette di essere coerente. R + W è un solido se N è consistentemente solido. Il client deve selezionare il livello di coerenza appropriato (zero, any, one, quoram o nessuno). La coerenza non si verificherà immediatamente perché le scritture vengono memorizzate nel buffer sul nodo a cui le invii nonostante il fattore di replica di 1:1.
Cassandra utilizza l'hashing coerente, il che significa che quando un insieme di chiavi viene sottoposto ad hashing utilizzando lo stesso algoritmo e gli stessi parametri della funzione hash, la funzione hash produce sempre lo stesso risultato.
Questo è fondamentale perché ti consente di conservare una chiave in più bucket senza preoccuparti che entri in collisione con qualcosa.
Di conseguenza, si ritiene che l'hashing coerente sia più efficiente perché consente a Cassandra di archiviare più dati nella stessa quantità di spazio.
È necessario assicurarsi che i conteggi di scrittura e lettura siano coerenti se si desidera ottenere una forte coerenza. La coerenza di Cassandra si basa sul presupposto che tutte le letture del client siano sempre aggiornate recuperando automaticamente i dati scritti più recenti. L'hashing coerente viene utilizzato per garantire che la funzione hash produca sempre lo stesso risultato per due chiavi diverse se vengono sottoposte ad hashing insieme utilizzando lo stesso algoritmo e i parametri della funzione hash. È fondamentale mantenere una chiave in più bucket perché le collisioni non sono un problema. Cassandra ha un tasso di prestazioni più elevato perché può conservare più dati nella stessa quantità di spazio con hashing coerente.
Qual è il livello di coerenza predefinito in Cassandra?
Basta chiamare QUBEDBUILDER per utilizzare il driver Java. Impostare theConsistencyLevel per garantire che il livello di coerenza per ogni inserimento sia impostato in insertInto. Durante la scrittura e la lettura, a tutte le operazioni viene assegnato un livello di coerenza pari a uno.
Come garantire la coerenza dei dati con Cassandra
Il motivo principale di ciò è che le chiavi non vengono archiviate nei bucket fino a quando non vengono eseguite l'hashing. Cassandra memorizza anche la chiave e il puntatore al bucket nella stessa riga della tabella. Cassandra confronta la riga per la chiave e il puntatore per un valore sopra un valore chiave per determinare quale riga corrisponde a quale chiave. Se entrambi sono veri, Cassandra prenderà il valore dal secchio al puntatore. Il valore di una chiave viene sempre memorizzato nella stessa riga indipendentemente da quante volte viene richiesto, purché sia memorizzato nella stessa riga. Quando una lettura viene ripetuta più volte, i dati rimangono costanti. Se vuoi cambiare il livello di coerenza per la tua sessione corrente, usa semplicemente il comando CONSISTENCY dalla shell cassandra (CQLSH). Se vuoi vedere quanto sei lontano dal tuo livello di coerenza, puoi usare CONSISTENCY; dal guscio. [e-mail protetta] | Coerenza: coerenza Il livello di coerenza corrente è uno.
Che cos'è la coerenza degli aggiornamenti in Nosql

La coerenza degli aggiornamenti in NoSQL è il processo di aggiornamento dei dati su più nodi in un database NoSQL . Questo processo garantisce che tutti i nodi nel database abbiano gli stessi dati e che i dati siano coerenti in tutti i nodi.
Che cos'è la coerenza degli aggiornamenti in Nosql?
La coerenza delle copie degli stessi dati all'interno dello stesso sistema di database replicato [1], in contrasto con il modo in cui i dati cambiano, è semplicemente una questione di scelta. Ciò si verifica quando le letture su un determinato oggetto dati non sono coerenti con l'aggiornamento precedente.

Che cos'è la coerenza degli aggiornamenti nel database?
Il concetto di coerenza nei sistemi di database implica il requisito che ogni data transazione di database consenta solo la modifica dei dati interessati nel modo consentito. I dati che sono stati scritti nel database devono rispettare tutte le regole definite, come vincoli, cascate, trigger e qualsiasi combinazione di questi.
Consistenza finale MongoDB

Eventual Consistency è un termine tecnico che significa che i dati che stai leggendo non sono sempre coerenti; tuttavia, migliorerà con il passare del tempo. L'unico modo per farlo è leggere dai secondari utilizzando uno qualsiasi dei readPreferences che possono leggere da fonti secondarie.
Come primo passo, esaminerò alcuni esempi di codice MongoDB effettivi che violano la garanzia di coerenza causale . La maggior parte dei metodi di lettura e scrittura verrà utilizzata nel primo tentativo di risolvere questo problema. Di conseguenza, esamineremo gli orologi logici e le sessioni correlate in Mongo. Useremo il driver Mongo C# per questa applicazione, ma mi piacerebbe lasciarlo stare. La maggioranza dei membri del set di repliche deve firmare una lettura maggioritaria se i dati di una query sono stati riconosciuti. Quando usiamo una lettura maggioritaria seguita da una scrittura maggioritaria, può sembrare che possiamo risolvere il nostro problema "Leggi la tua scrittura". Un server secondario mantiene un'istantanea in memoria della scrittura maggioritaria più recente.
Impostazioni Readconcern di MongoDB
Un client deve determinare la quantità di dati che dovrebbe essere consentito di leggere affinché readConcern sia soddisfatto prima che possa iniziare a soddisfare readConcern. In MongoDB, è preferibile che readConcern sia impostato su maxRead.
Coerenza finale contro coerenza forte
Fornisce dati aggiornati a una latenza inferiore rispetto ad altre tecnologie, ma richiede anche un alto grado di persistenza. Poiché il database potrebbe non disporre di dati aggiornati in tutti i nodi, l'eventuale coerenza potrebbe fornire una bassa latenza ma potrebbe non sempre rispondere alle richieste di lettura con dati obsoleti.
La coerenza in generale si riferisce alla capacità di un database di elaborare transazioni preservando al tempo stesso l'integrità dei dati. I sistemi di database conformi alle normative ACID sono in genere lenti, difficili da scalare e proibitivi da mantenere e utilizzare. Alcuni sistemi RDBMS attenuano le garanzie ACID. Le garanzie di base di un database NoSQL sono note come algoritmi NoSQL. Di conseguenza, la base può essere utilizzata per aumentare la disponibilità consentendo anche l'allentamento di standard rigidi. Di conseguenza, i database NoSQL richiedono una quantità significativa di coerenza per essere più stabili. Quando la coerenza finale di DynamoDB è determinata da una topologia ad anello, diventa Cassandra.
Per gestire risultati coerenti, in Redis viene utilizzata una topologia master-slave. ScyllaDB è una società di database di big data in tempo reale con sede nei Paesi Bassi. Inoltre, può essere utilizzato per specificare un livello di coerenza per ogni operazione (lettura o scrittura). Poiché i dati potrebbero essere stati modificati su un nodo coordinatore ma non sono ancora stati registrati e archiviati su tutte le repliche richieste, i cluster ScyllaDB forniscono risultati coerenti.
Uno degli aspetti più importanti della coerenza del sistema informatico è la sua coerenza. I dati possono essere gestiti in questo modo indipendentemente da come vengono archiviati perché garantisce la coerenza. Di conseguenza, le istituzioni finanziarie, ad esempio, adottano frequentemente sistemi che saranno coerenti nel tempo. La maggior parte delle transazioni sarà completata il più rapidamente possibile come risultato di questo processo. L'elaborazione di una transazione può richiedere fino a 24 ore, sebbene ciò non sia garantito. Questo fenomeno è causato da un modello generale di sistemi coerenti che alla fine esisteranno.
Coerenza dei dati: come scegliere il tipo giusto per le tue esigenze
Quando si tratta di dati, ci sono due tipi: forti e deboli.
Poiché tutti i dati in un nodo sono coerenti, indipendentemente da dove risiedono, sono sempre gli stessi. Questo metodo è il metodo più affidabile per la coerenza dei dati, ma può essere difficile da implementare.
La mancanza di coerenza indica che non vi è alcuna garanzia che tutti i nodi dispongano degli stessi dati contemporaneamente. Questa coerenza è più soggetta alla corruzione, ma a volte può anche essere più efficiente.
Consistenza finale Cassandra
La coerenza finale è un modello di coerenza utilizzato nei sistemi distribuiti. In un sistema eventualmente coerente, le operazioni potrebbero richiedere del tempo per propagarsi e diventare visibili in tutti i nodi. Un'operazione di scrittura è considerata riuscita quando è durevole nel nodo in cui è stata emessa. Un'operazione di lettura è considerata riuscita quando restituisce l'operazione di scrittura più recente. La coerenza finale viene spesso utilizzata nei sistemi distribuiti su più data center. In questi sistemi, non è pratico mantenere una forte coerenza a causa della maggiore latenza e del potenziale di errori. L'eventuale coerenza consente al sistema di continuare a funzionare anche in caso di guasti. Cassandra è un database distribuito che utilizza la coerenza finale. Cassandra è progettata per gestire grandi quantità di dati con elevata disponibilità. Cassandra è utilizzata da alcune delle più grandi aziende del mondo, tra cui Facebook, Netflix e Instagram.
È un database NoSQL open source con un'architettura altamente disponibile e scalabile. La replica dei dati tra i cluster è necessaria per ottenere un'elevata disponibilità in Cassandra. Sono disponibili due strategie di replica: SimpleStrategy e NetworkTopology. La coerenza del modo in cui ogni riga di dati è rappresentata dalle repliche riflette quanto sono recenti e sincronizzate. Il livello di coerenza indica quanti nodi di replica devono rispondere ai dati coerenti più recenti prima che il coordinatore possa inviare correttamente i dati al client. A seconda del livello di coerenza specificato dal client, possiamo impostare il livello di coerenza per ogni query di scrittura o il livello di coerenza per ogni query globale. Quando scrivi, tieni presente il livello di coerenza (CL).
In 5.1, solo un nodo di replica restituisce dati, mentre in 5.2, il 51% dei nodi di replica in tutti i data center restituisce dati. Abbiamo iniziato definendo un livello di coerenza desiderato (CL) per le scritture e le letture di Cassandra. Di conseguenza, indipendentemente dal tempo che intercorre tra la scrittura più recente e la successiva, stai leggendo i dati scritti più recenti nel cluster. Per garantire la coerenza, possiamo specificare un livello di coerenza della query di scrittura o globale. Ecco alcuni esempi di CL in lettura che puoi vedere nel diagramma qui sotto.
Che cos'è la coerenza finale nei microservizi
Infatti, la coerenza finale è un metodo per mantenere la coerenza e la disponibilità dei dati mediante la comunicazione asincrona, oltre a garantire che gli errori in un processo specifico vengano risolti senza dover tornare allo stato precedente del processo.
Nella maggior parte dei casi, abbiamo riscontrato problemi con l'incoerenza dei dati in un sistema software. Si basa su un approccio decentrato e si ispira alla natura. Con il cloud computing, l'elastic computing e l'archiviazione sempre più popolari e la tecnologia dei container e l'orchestrazione sempre più popolari, una quantità significativa di nuove applicazioni viene creata utilizzando lo stile architettonico dei microservizi. Quando le transazioni atomiche si estendono su più servizi, vengono viste come una catena di semplici transazioni locali atomiche a ciascun livello di servizio. Quando una transazione fallisce in questa catena a causa di una circostanza specifica, essenzialmente attiva un'operazione di annullamento. Anche una chiamata o una transazione di compensazione può fallire. La coerenza e l'integrazione dei dati sono due degli approcci più comuni alla gestione dei dati, che sono Kafka e CDC.
CDC è adatto per grandi architetture distribuite perché non è eccessivamente orientato alle prestazioni. L'inflessibilità del CDC quando si tratta di modifiche agli schemi è uno degli svantaggi più significativi. Ciò limita notevolmente l'evoluzione dello schema del DB di servizio.