
Perché l'adesione ai database NoSQL è complicata
Pubblicato: 2022-11-19I database NoSQL sono sempre più diffusi come alternativa ai tradizionali database relazionali . Tuttavia, una delle caratteristiche principali dei database relazionali è la possibilità di eseguire join tra tabelle. Quindi, NoSQL supporta i join? La risposta è, dipende. Alcuni database NoSQL supportano i join, mentre altri no. E anche per coloro che supportano i join, il modo in cui vengono implementati può variare in modo significativo. Quindi, diamo un'occhiata più da vicino a come i join sono supportati nei database NoSQL. Inizieremo esaminando quelli che non supportano i join, prima di passare a quelli che lo fanno.
Gli operatori di join generali utilizzati nei database relazionali più tradizionali non sono supportati da Oracle NoSQL Database. Tuttavia, supporta l'utilizzo di un tipo univoco di join tra tabelle che sono membri della stessa gerarchia di tabelle. Poiché è possibile collegare solo righe con ubicazione condivisa, questi join possono essere eseguiti in modo efficiente.
Al momento, Oracle NoSQL Database non supporta gli operatori di join generali, utilizzati nei database relazionali tradizionali.
I join MongoDB ora possono essere eseguiti in MongoDB 3.2 grazie a una nuova operazione di ricerca che può essere utilizzata per eseguire operazioni di join sulle raccolte.
Il supporto MongoDB si unisce?
MongoDB non supporta il join, ma supporta il collegamento manuale dei riferimenti. È possibile utilizzare l'operatore $lookup per eseguire un join sinistro, un join destro o un join esterno completo su due raccolte.
MongoDB non supporta i left outer join, ma puoi farlo utilizzando la fase $lookup. Puoi specificare a quale raccolta vuoi unirti con quali campi e come vuoi che la raccolta venga confrontata selezionando la fase $lookup. È possibile utilizzare la fase $lookup per aggiungere le raccolte dei dipendenti e degli ordini della stessa raccolta selezionando i campi id_impiegato e id_ordine nel campo della raccolta dei dipendenti e specificando che si desidera che la raccolta dei dipendenti sia associata alla raccolta degli ordini. Verranno restituiti gli ID del dipendente e dell'ordine identici tra loro.
Unire le forze: come uno studente ha superato il voto
Un grado var indica un grado var. Dati per trovare il voto di uno studente; gradi.unirsi agli studenti; e dati per trovare il voto di uno studente Vengono restituiti i voti dell'utente 1 in tutti gli studenti.
Quale database Nosql non supporta relazioni e join?
MongoDB è il database non relazionale più popolare e non supporta i join.
Un database NoSQL è uno strumento eccellente per archiviare i dati in forme non strutturate come documenti o coppie chiave-valore. I dati in un database relazionale devono essere archiviati in modo strutturato e normalizzato. Un database ben definito può fornire un vantaggio in alcuni casi se utilizzato insieme a un database relazionale. Un database NoSQL è uno che non è conforme ai formati di dati strutturati e viene definito come tale. La capacità dei database NoSQL di ridimensionarsi orizzontalmente è dovuta alla loro base di tolleranza delle partizioni. Poiché il database non specifica alcuna struttura per le query di join , non sono nemmeno molto bravi a farlo. Hevo Data, una pipeline di dati senza codice, consente l'integrazione e la replica di database NoSQL e altri tipi di dati.
Non esiste una soluzione valida per tutti qui e la tua decisione deve essere basata sulle caratteristiche degli usi che stai considerando. I seguenti sono alcuni dei fattori chiave che influenzano la decisione tra database relazionale e NoSQL. Se hai bisogno dell'elaborazione dei dati su enormi database, dovresti utilizzare un database NoSQL il prima possibile. La scrittura nei database NoSQL tende ad essere il più prevedibile possibile. Puoi quindi aspettarti che la tua applicazione legga i vecchi dati fino a quando tutti i nodi non ricevono i dati. RDBMS supporta una varietà di funzioni di query e join, nonché join complessi . È preferibile utilizzare i database NoSQL quando i dati vengono archiviati nello stesso formato in cui verranno utilizzati per il consumo.
In generale, è necessario un hardware di fascia alta per i database relazionali per gestire enormi quantità di dati. Solo quando il tuo volume di dati è abbastanza grande per l'implementazione di un database distribuito, questo sarà valido. Hevo è una pipeline di dati non di codice che semplifica la replica e il caricamento dei dati da origini e database di destinazione comunemente utilizzati. L'utilizzo di Hevo per tali operazioni di copia consente a sviluppatori e analisti di concentrarsi sulla propria logica di business principale, producendo operazioni di copia alla velocità più bassa possibile. Hevo è un bravo ragazzo e mi piacerebbe provare. Puoi provare la suite Hevo gratuitamente per 14 giorni e imparare tutto quello che c'è da sapere al riguardo.
MongoDB è una scelta eccellente se desideri utilizzare un database NoSQL con una grande quantità di dati. Ci sono numerosi vantaggi nell'utilizzo di questo programma, che include la possibilità di utilizzare una varietà di linguaggi di programmazione, un gran numero di tipi di dati e un robusto sistema di amministrazione.
Se hai appena iniziato, MongoDB è una scelta eccellente perché è semplice da usare e non richiede molte conoscenze di programmazione. Inoltre, MongoDB è poco costoso e ampiamente disponibile, il che rende semplice trovare un server che lo ospiterà per te.
In generale, MongoDB è il chiaro vincitore quando si tratta di un database NoSQL in grado di gestire grandi quantità di dati.
Perché MongoDB non supporta Join?
MongoDB non supporta join perché è un database NoSQL. I database NoSQL sono progettati per essere scalabili e per funzionare con grandi quantità di dati. Sono inoltre progettati per essere flessibili, nel senso che possono essere facilmente modificati per soddisfare le esigenze di una particolare applicazione.
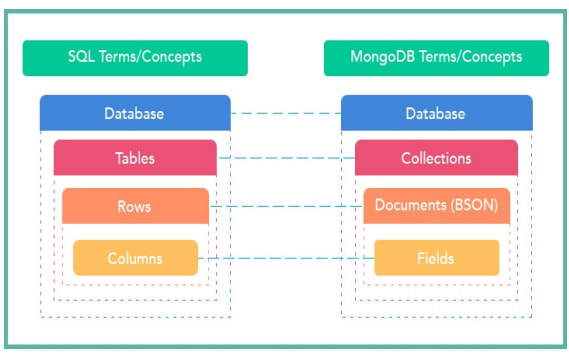
MongoDB è un database NoSQL open-source e può essere utilizzato per archiviare enormi quantità di dati. Tabelle e righe vengono utilizzate nei database tradizionali , mentre raccolte e documenti vengono utilizzati in MongoDB. Le coppie chiave-valore vengono utilizzate dai documenti MongoDB, che sono gli elementi costitutivi del database. In questo post vengono utilizzati i join MongoDB, i tipi chiave di comandi Join e Lookup discussi in questo blog. Una nuova operazione di ricerca in MongoDB 3.2 può eseguire operazioni di join sulle raccolte. Una sintassi concisa per sottoquery correlate può essere utilizzata in MongoDB 5.0 e successivi. Quando si utilizzano i join MongoDB, esistono alcune restrizioni o limitazioni.
Il seguente frammento crea Collezioni, ristoranti e ordini in base ai seguenti documenti: Ordina la collezione a cui sei interessato. Inserisci il nome del ristorante e l'indirizzo. Il nome di ciascun ordine deve essere abbinato a una corrispondenza di array $in tra di essi. Le bevande e le bevande sono elencate nel seguente ordine. L'output sarebbe elencato di seguito.
MongoDB: nessun join, ma $lookup fornisce una soluzione alternativa
Il database MongoDB non è relazionale, quindi non supporta i join. La funzionalità di join è una funzionalità comune nei database relazionali, ma MongoDB non è destinata a supportarla. Di conseguenza, il database sarà più efficiente e veloce perché l'unione non richiede l'uso di costose macchine. Questa funzione ci consentirà di includere documenti in una raccolta utilizzando la funzione $lookup (Aggregation) di MongoDB. Di conseguenza, quando i dati vengono uniti, la funzione crea un join sinistro con una raccolta, consentendo di filtrare i dati di entrambe le raccolte.
Quale non si applica a Nosql?
Nosql è un database non relazionale che non utilizza il tradizionale schema tabulare di un database relazionale. Viene spesso utilizzato per archiviare grandi quantità di dati che non sono adatti per un database relazionale.
Dovresti determinare qual è l'opzione migliore in base ai pro e ai contro di ciascuno. Questo tipo di database permette di gestire i dati in maniera non relazionale piuttosto che in forma tabellare. Un database NoSQL può essere classificato in quattro tipi. I database dei documenti vengono creati utilizzando un array associativo (mappa o dizionario) per rappresentare un insieme di coppie chiave-valore che sono state rappresentate dal modello di dati. Le applicazioni Web che li utilizzano per la gestione delle sessioni e la memorizzazione nella cache li trovano estremamente utili. Gli archivi di grafici organizzano i dati come nodi e spigoli in base alla loro funzione di nodi e spigoli. Modelli come questi sono utili in una varietà di settori, inclusi i sistemi di gestione delle relazioni con i clienti, le mappe stradali e i sistemi di prenotazione.
La popolarità dei database NoSQL deriva dalla loro capacità di integrare big data, basso costo, semplice scalabilità e funzionalità open source. Le funzionalità di sicurezza dei database NoSQL sono limitate a causa della loro funzionalità limitata. Le tue preferenze, i requisiti aziendali, il volume e la varietà di dati influenzeranno tutti il database più adatto a te.
Tuttavia, NoSQL non deve essere utilizzato in applicazioni che devono garantire proprietà ACID come le transazioni finanziarie. Quando ciò accade, dovresti prendere in considerazione la migrazione ai database SQL. Se hai bisogno di flessibilità nel runtime, NoSQL dovrebbe essere evitato.
Database Nosql: non una soluzione valida per tutti
Un database NoSQL non è una soluzione valida per tutti. Poiché non sono vincolati a un modello di dati rigido e centralizzato ospitato su un singolo server, possono connettere diversi tipi di modelli di database che possono essere distribuiti su un'ampia gamma di dimensioni di server. NoSQL non supporta le transazioni, ma ciò non significa che non possano essere implementate in una varietà di applicazioni. Il database NoSQL consente l'archiviazione e il recupero dei dati in qualsiasi formato diverso dall'archiviazione tabulare, consentendo l'accesso e l'archiviazione in una varietà di formati diversi dall'archiviazione tabulare. Le tabelle esterne non sono necessarie per recuperare o archiviare i dati.
Nosql Join Equivalente
Nosql join equivalent è un modo per combinare i dati da due o più origini dati nosql. Ciò è utile quando è necessario combinare dati da più origini per creare un'unica visualizzazione dei dati. Ad esempio, potrebbe essere necessario combinare i dati di un database dei clienti e di un database degli ordini per creare un report che mostri gli ordini dei clienti.

Entrambi i tipi di database richiedono operazioni di join per funzionare correttamente. In questo articolo confronteremo un database relazionale MySQL con un database NoSQL (MongoDB). Per eseguire operazioni di join utilizzando la parola chiave $lookup, possiamo utilizzare la pipeline aggregata. In alcuni casi, le query richiedono l'unione di entrambi i database. La pipeline aggregata di MongoDB è particolarmente utile perché può essere utilizzata per eseguire una varietà di funzioni come filtraggio, ordinamento, raggruppamento e così via in un'unica pipeline. In una normale istruzione select, scriviamo solo il nome delle colonne da selezionare. Quando uniamo le tabelle, specifichiamo le colonne che verranno utilizzate per le colonne della tabella, che SQL capirà.
Nella fase di join dell'operazione $lookup, scegliamo "$location" come id dei documenti da raggruppare in base alla posizione. Quindi, come vedremo nelle sezioni seguenti, specifichiamo la funzione $avg, così come il campo che deve essere aggregato. Per utilizzare il criterio di filtraggio, dobbiamo prima aggiungere la fase $match alla pipeline.
Postgres è il miglior database per i join
In conclusione, PostgreSQL funziona meglio ed è più stabile di qualsiasi altro database.
MongoDB si unisce
I join MongoDB ti consentono di combinare documenti di raccolte diverse in un'unica query. Ciò può essere utile quando è necessario recuperare i dati da più raccolte in un'unica operazione. Ad esempio, puoi utilizzare un Join per combinare i dati di una raccolta di utenti e una raccolta di post per creare un feed di tutti i post di tutti gli utenti.
MongoDB non è ufficialmente compatibile con l'adesione. Questo significa che non possiamo collegare insieme due raccolte? Ti sarei grato se potessi rispondermi su questo. Ci sono due metodi per risolvere i riferimenti in questo spazio. Puoi risolvere il problema manualmente scrivendo la tua funzione oppure puoi automatizzarla. In alternativa, MongoDB può utilizzare DBRefs, che gli consentirà di gestire le relazioni cliente per cliente. Il comportamento di riferimento di MongoDB è molto simile al caricamento lento, piuttosto che all'unione.
Puoi guardare e ascoltare i discorsi sulla progettazione dello schema sul sito web mongodb.org. Quando si tratta di utilizzare database nosql come MongoDB, è necessario implementare uno schema. Di conseguenza, avrai sempre meno un aspetto del database SQL nelle tue raccolte. Questo pacchetto ti consente di aggiungere componenti lato server (non sono sicuro di nessun altro framework che lo faccia). Non ci sono join in MongoDB, ma abbiamo bisogno di riferimenti a documenti in altre raccolte, ad esempio. Usare StackOverflow è semplice come seguire i passaggi in questa risposta StackOverflow.
La velocità di MongoDB ha alcune limitazioni
Nonostante la sua velocità, MongoDB presenta alcuni inconvenienti. Uno dei limiti è che non supporta il cross-linking. Di conseguenza, quando si tratta di cose come i dati aggregati, devi farle individualmente. Sebbene questo sia più lento di un database relazionale, è comunque estremamente veloce.
Database Nosql
I database Nosql sono un tipo di database che non utilizza il tradizionale modello relazionale utilizzato dalla maggior parte dei database. Utilizza invece un archivio di valori-chiave, un archivio di documenti o un archivio di grafici. Ciò rende i database nosql più scalabili e flessibili dei database relazionali.
Il vantaggio principale dei database NoSQL rispetto ai database tradizionali è che offrono una maggiore flessibilità. I database NoSQL memorizzano i dati in un'unica struttura di dati, come un documento, a differenza dei database relazionali, che in genere contengono più righe di dati. Poiché questa progettazione di database non richiede uno schema per gestire set di dati di grandi dimensioni e in genere non strutturati, è altamente scalabile. Poiché i database NoSQL non condividono dati, le tabelle non possono essere collegate. A causa delle sue diverse strutture di dati, NoSQL ha il potenziale per essere utilizzato in una varietà di aree, tra cui analisi dei dati, social network e app mobili. Nonostante il fatto che ogni tipo di database tragga vantaggio dal proprio insieme di caratteristiche, la maggior parte delle aziende utilizza NoSQL e database relazionali. I database di documenti memorizzano i dati come documenti, che li mantengono organizzati quando vengono utilizzati nelle applicazioni.
I database di documenti sono spesso utilizzati per i sistemi di gestione dei contenuti e i profili utente. Il vantaggio principale di un database a colonne larghe è che memorizza i dati in colonne, consentendo agli utenti di accedere a colonne specifiche solo quando ne hanno bisogno. Questi tipi di database includono Apache Cassandra e Apache HBase. I database a grafo vengono utilizzati per gestire e archiviare una rete di connessioni tra elementi in un grafo. Un database basato sulla memoria memorizza i dati anziché su un disco, consentendo un accesso più rapido. Poiché eliminano la necessità di un singolo archivio dati condiviso per un'intera applicazione, i microservizi sono un'opzione praticabile. I database PaaS e NoSQL sono disponibili presso IBM in una varietà di applicazioni. Aggiungi gratuitamente IBM Data Management Platform for MongoDB Enterprise Advanced a IBM Cloud Pak for Data. Questo servizio è compatibile con Apache CouchDB, PouchDB e gli ecosistemi di librerie, nonché con i popolari stack di sviluppo web e mobile.
I database NoSQL, nel loro insieme, sono stati ostacolati dalla loro mancanza di scalabilità e prestazioni. Ora ci sono startup innovative e aziende leader che stanno iniziando ad affrontare queste limitazioni.
I database scale-out sono il tipo di database NoSQL più utilizzato. L'architettura consente di archiviare più copie di dati su più tipi di nodo, nonostante venga utilizzato il calcolo masterless. Questa tecnologia consente un'enorme scalabilità, fondamentale per evitare i tempi di inattività.
Questa funzione consente l'archiviazione dei dati in più posizioni ed è fondamentale per l'alta disponibilità e il ripristino di emergenza. La replica dei dati è richiesta anche durante la creazione di un ambiente di data warehousing e multi-tenancy.
Un'altra caratteristica importante dei database NoSQL è la loro capacità di creare strutture di dati flessibili. Inoltre, è facile aggiungere nuovi tipi di dati e manipolare i dati con facilità utilizzandoli. È fondamentale per il data warehousing e il rapido sviluppo di nuove applicazioni.
I vantaggi dei database Nosql
I dati archiviati nei database NoSQL possono essere archiviati in vari modi, il che li rende un tipo di database più popolare. Possono essere utilizzati per archiviare dati non strutturati e qualsiasi tipo di dati. Quando si tratta di elaborazione dati su larga scala, sono anche più efficienti dei database tradizionali.
Nei database NoSQL, non c'è limite ai tipi di dati che possono essere archiviati. Inoltre, i dati possono essere memorizzati in file o in database grafici.
Database Oracle Nosql
Un database Oracle NoSQL è un servizio di database NoSQL distribuito e scalabile che offre prestazioni elevate, disponibilità elevata e sharding automatico. Oracle NoSQL Database è basato su Oracle Berkeley DB Java Edition e fornisce una semplice API Java per accedere al database.
Spring Data può essere implementato utilizzando Oracle NoSQL SDK per Spring Data. Puoi usarlo per connetterti a un cluster Oracle NoQL Database o a Oracle NoQL Cloud Service. L'SDK sarà accessibile se utilizzi una dipendenza maven dal phar.xml del tuo progetto. Queste sono alcune delle migliori opzioni per comodità. www.oracle.com/nosql Recuperare il seguente metodo: NosqlDbConfig. Una classe di entità può essere definita come segue. Si consiglia di creare un repository per l'estensione Nosql . Scrivendo la classe dell'applicazione, puoi iniziare. Richiede l'installazione di dipendenze su org.springframework.boot:spring-boot.
I molti vantaggi di MongoDB
MongoDB è l'unico database in grado di cercare file di testo completo e documenti con strutture incorporate.
Cattura … Aggregazione MongoDB
La funzione di aggregazione di MongoDB ti consente di raggruppare i documenti insieme per eseguire analisi sui tuoi dati. Questa è una potente funzionalità che può essere utilizzata per rispondere a una serie di domande sui dati. Ad esempio, puoi utilizzare l'aggregazione per determinare il prezzo medio di un prodotto per tutti i tuoi clienti o per raggruppare i clienti in base alla località.
Il framework di aggregazione di MongoDB è in grado di elaborare qualsiasi tipo di dati. Un nome per un operatore di espressione può essere trovato in un array di argomenti o in un singolo argomento. Una delle applicazioni più comuni degli accumulatori è il calcolo di totali, massimi, minimi e altri valori in espressioni speciali. Alcuni accumulatori possono essere utilizzati in altre fasi ma non come accumulatori perché non mantengono lo stato. L'operatore $let è composto da due parti: vars ed espressioni, che consentono di assegnare variabili e utilizzarle nei calcoli. Le variabili definite internamente ma modificate in vars non cambiano i valori perché sono visibili solo i valori originali. Se salvi la pipeline, può essere ricaricata in un secondo momento all'interno di Compass.
MongoDB Compass include diversi strumenti per l'aggregazione, come Aggregation Pipeline Builder. La pipeline di aggregazione suddivide il problema in blocchi più piccoli. Le pipeline possono anche essere utilizzate per commentare le fasi del debug o della prototipazione. Le fasi di blocco devono essere attentamente progettate per migliorare le prestazioni della pipeline. La shell MongoDB 2.2 include un framework di aggregazione, completamente implementato con l'helper aggregate(). MongoDB 1.14 include MongoDB Aggregation Pipeline Builder. Le fasi sono state migliorate con l'aggiunta di $graphLookup, $bucket, $facet, $addFields e $replaceRoot. L'importazione/esportazione è ora una funzionalità disponibile in Compass 1.15 (agosto 2018). A novembre 2018 è stato rilasciato MongoDB 4.2 e MongoDB 4.4 è stato rilasciato a gennaio 2019.
MongoDB: un'ottima scelta per l'aggregazione
Un database MongoDB è una scelta eccellente per l'aggregazione dei dati perché può elaborare un'ampia gamma di tipi di dati. Con Export Aggregation Results, puoi facilmente importare i risultati dei dati in una varietà di formati. MongoDB può essere lento quando si lavora con raccolte di grandi dimensioni, ma può essere veloce quando si lavora con $lookup senza indice.