
Perché utilizzare la mappatura oggetto-relazionale per archiviare dati relazionali in un database NoSQL?
Pubblicato: 2022-11-22I dati relazionali vengono archiviati in un database NoSQL utilizzando una tecnica chiamata "mappatura oggetto-relazionale" (ORM). Questa tecnica mappa gli oggetti in un database relazionale al database NoSQL. Gli oggetti vengono quindi archiviati nel database NoSQL come documenti. La tecnica ORM viene utilizzata per mappare le relazioni tra gli oggetti nel database relazionale ai documenti nel database NoSQL. Questa tecnica viene utilizzata per archiviare i dati in un database NoSQL.
I dati vengono archiviati in documenti anziché in tabelle nei database NoSQL. Sono progettati per soddisfare le esigenze delle odierne esigenze di gestione dei dati delle aziende, indipendentemente dal fatto che siano flessibili, scalabili o in grado di rispondere rapidamente. Database di documenti, archivi di valori-chiave, database a colonne larghe e database a grafo sono esempi di database NoSQL. Le aziende Global 2000 stanno adottando sempre più database NoSQL per potenziare le applicazioni mission-critical. Esistono cinque tendenze principali che richiedono di evitare la maggior parte dei database relazionali a causa delle loro sfide tecniche. A causa del loro modello di dati fisso, i database relazionali rappresentano un grosso problema per lo sviluppo agile perché mancano dell'agilità richiesta. Il modello dell'applicazione è il modello principale utilizzato per definire un modello di dati NoSQL.
Il modello NoSQL non tenta di definire il modello di dati. I database orientati ai documenti utilizzano JSON come formato principale per l'archiviazione dei dati. Il sovraccarico dei framework ORM viene eliminato e lo sviluppo delle applicazioni viene semplificato. Ora è possibile estendere SQL a JSON utilizzando il nuovo linguaggio N1QL (pronunciato "nickel") in Couchbase Server 4.0. Non solo supporta le istruzioni standard SELECT / FROM / WHERE, ma supporta anche l'aggregazione (GROUP BY), l'ordinamento (SORT BY), i join (LEFT OUTER / INNER) e così via. Esistono numerosi vantaggi operativi per i database distribuiti NoSQL, che sono costruiti con un'architettura scalabile e non contengono alcun singolo punto di errore. Sta diventando sempre più fondamentale disporre di un sito Web e di un'app mobile affidabili mentre i clienti interagiscono con noi online e di persona.
I database NoSQL possono essere creati, configurati e ridimensionati in modo rapido e semplice. Sono stati progettati per ospitare un'ampia gamma di dispositivi che leggono, scrivono e archiviano dati. Inoltre, possono essere implementati su qualsiasi scala, inclusa la gestione e il monitoraggio di cluster di varie dimensioni. Un database NoSQL distribuito è progettato per essere replicato su più data center, semplificando la creazione di un database NoSQL in pochi clic. La capacità di abilitare router hardware immediati garantisce che le applicazioni possano eseguire il proprio failover piuttosto che attendere che un database rilevi un problema ed esegua il proprio. I database NoSQL stanno diventando sempre più popolari nelle odierne applicazioni web, mobile e Internet of Things.
Il database relazionale è una raccolta di informazioni che organizza i dati in relazioni predefinite in cui i dati vengono archiviati in una o più tabelle (o relazioni) di colonne e righe, rendendo semplice vedere e comprendere come le strutture di dati si relazionano tra loro.
Le transazioni non sono supportate dai database NoSQL (sono supportate solo transazioni semplici). Le transazioni (note anche come join) possono essere eseguite utilizzando il database relazionale. I database NoSQL sono ideali per la gestione di dati in rapido movimento. I dati che arrivano in uno stato crittografato a bassa velocità vengono gestiti da un database relazionale.
L'obiettivo dei database NoSQL (noto anche come non solo SQL) è archiviare i dati in modo più naturale e non tabulare rispetto ai database tradizionali . In base al modello di dati utilizzato, i database NoSQL possono essere suddivisi in diversi tipi. Un documento può contenere un valore chiave, una colonna larga o un grafico.
Una chiave è un record con un ID univoco che rappresenta una riga in un database relazionale. Le colonne della tabella contengono gli attributi dei dati e ogni record ha il proprio valore per ogni attributo, facilitando l'associazione dei punti dati.
Come vengono archiviati i dati relazionali in un database Nosql?
I dati relazionali vengono archiviati in un database nosql utilizzando una tecnica chiamata "mappatura oggetto-relazionale" (ORM). Questa tecnica consente al database nosql di archiviare i dati in un modo compatibile con il modo in cui i database relazionali memorizzano i dati. Ciò rende possibile archiviare i dati in un database nosql utilizzando gli stessi metodi utilizzati per archiviare i dati in un database relazionale.
È un tipo di database che non è limitato a SQL. I database NoSQL sono disponibili in quattro diversi tipi. Poiché ogni tipo di NoSQL utilizza un modello di dati diverso, le differenze tra loro possono essere significative. Le implementazioni NoSQL hanno la mancanza di un database come una delle loro caratteristiche principali. Ci vorrà del tempo, ma lo schema, il clustering dei dati, il supporto della replica e la coerenza funzioneranno tutti. Un database chiave-valore è ideale per gestire le richieste di sessione e la memorizzazione nella cache nelle applicazioni web. La migliore query di dati viene eseguita da un archivio basato su colonne.
I cinque aspetti principali di NoSQL sono API, modello di dati, requisiti dello schema, scalabilità e integrità dei dati. I database NoSQL consentono di archiviare i dati in modo completamente semantico o in forma libera. Come risultato di questo approccio, i programmatori hanno un maggiore livello di flessibilità, facilitando il completamento delle attività di sviluppo. Per salvaguardare l'integrità dei dati mentre vengono creati, letti, aggiornati ed eliminati dall'applicazione e dall'utente, i database NoSQL e SQL differiscono. Lo scopo di ACID è garantire che le transazioni vengano completate nello stato del database più coerente e che non vengano generati effetti. Le transazioni che vengono eseguite da sole vengono completate, producendo risultati corretti o vengono terminate senza effetto. Database NoSQL può essere utilizzato per descrivere alcuni database creati prima dello sviluppo del sistema di gestione relazionale (RDBMS). Il termine "cloud" si riferisce ai database creati nei primi anni 2000 per archiviare dati in grandi cluster per applicazioni cloud e web.
Per una serie di motivi, i database NoSQL stanno diventando sempre più popolari. Poiché questi carichi di lavoro sono progettati per applicazioni a bassa latenza, hanno uno scopo nelle applicazioni che devono reagire a dati in rapida evoluzione. I dati semi-strutturati vengono spesso convertiti in database di ricerca NoSQL per essere analizzati. Tipi di dati come questo possono essere difficili da modellare in un database SQL, ma i database di ricerca NoSQL ne facilitano l'analisi e la comprensione.
Database Nosql per diverse esigenze di archiviazione dei dati
Quando i dati vengono archiviati nei database NoSQL, vengono quindi interrogati utilizzando diversi linguaggi e costrutti di programmazione. Gli archivi di dati dei documenti, i database orientati alle colonne, gli archivi di valori-chiave e i database a grafo sono tutti possibili tipi di database. Gli archivi dati dei documenti sono popolari perché possono essere distribuiti nel cloud e sono progettati per un utilizzo su larga scala. I dati organizzati in tabelle sono più efficaci nei database orientati alle colonne. Un archivio di valori-chiave può archiviare dati sparsi in un database, mentre un database a grafo può archiviare dati simili a quelli di un grafico.
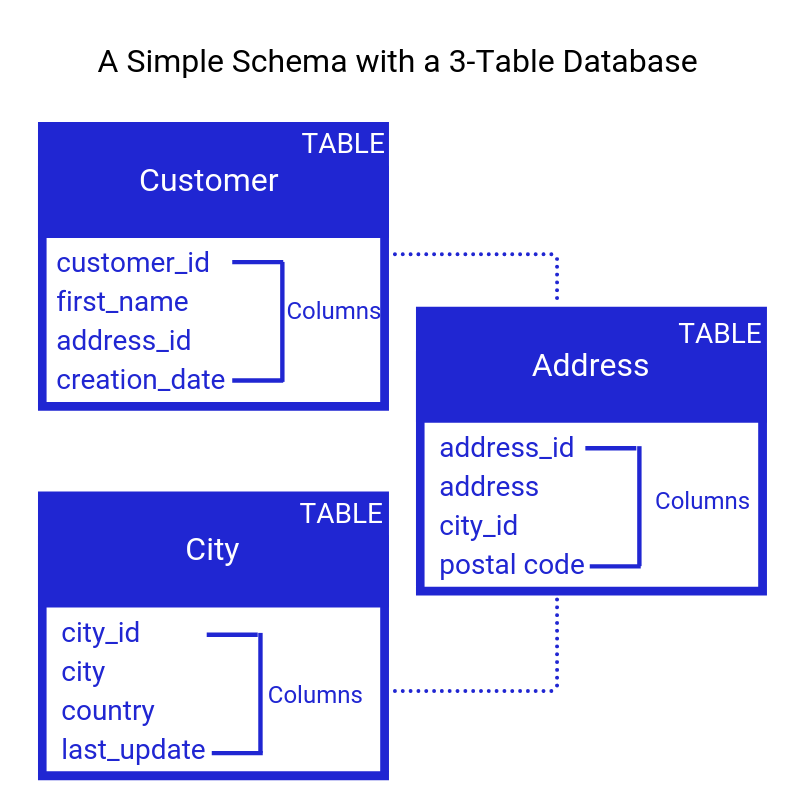
In che modo i database relazionali memorizzano i dati?
I database relazionali memorizzano i dati nelle tabelle. Le tabelle sono simili alle cartelle in un file system, in cui ogni tabella memorizza una raccolta di informazioni. Le tabelle sono composte da colonne e righe, in cui ogni colonna rappresenta un'informazione e ogni riga rappresenta un record.
Un database relazionale è costituito da informazioni organizzate secondo un insieme di relazioni definite. Sono utilizzati in azienda per organizzare i dati e identificare le relazioni tra i punti dati chiave. È semplice ordinare e trovare le informazioni, consentendo alle aziende di prendere decisioni più informate. Un database relazionale contiene informazioni sugli oggetti e le loro relazioni. Gli utenti definiscono il dominio di un possibile valore in una colonna di dati e i vincoli che possono essere applicati a tale valore nella creazione di un database. L'integrità dei dati è un vincolo importante, così come le chiavi esterne e le chiavi primarie. Un database relazionale viene fornito anche con l'indipendenza dei dati fisici.
Sono disponibili diversi database, inclusi quelli che non sono connessi a Internet e quelli che non sono disponibili nei database relazionali o nei database NoSQL. Un sistema di gestione di database relazionali (RDBMS) e un sistema di database orientato agli oggetti (OODBMS) sono due esempi di ORD. In generale, i dati vengono archiviati in un database. È quindi accessibile e manipolato utilizzando un linguaggio di query nativo del linguaggio di query. Un database non relazionale, noto anche come database NoSQL, è uno che non contiene alcun record. È molto più che decidere su un database non relazionale per un progetto aziendale. Considera il tipo di dati utilizzati o sviluppati quando determini quali dati includere. Quando si decide il software per un database, è fondamentale prendere in considerazione iniziative specifiche. C'è molto in gioco nelle iniziative IoT quando si tratta di NoSQL rispetto ai database relazionali.
Le relazioni uno a uno sono il tipo più comune di relazione. In una relazione uno a uno, la relazione di un segmento con un altro segmento è limitata.
Il secondo tipo di relazione più comune è uno a molti. In un database, il numero di segmenti in una relazione uno a molti rappresenta il numero di segmenti correlati.
La relazione molti-a-molti è il terzo tipo di relazione più comune. La relazione tra un segmento e le sue controparti molti-a-molti in un database è nota come relazione molti-a-molti.
Come viene memorizzato un database relazionale?
Le tabelle sono costituite da righe e colonne in un database relazionale. In genere, i dati possono essere uniti utilizzando una chiave primaria o esterna e possono essere strutturati su più tabelle.
Archivi dati: vantaggi e svantaggi
Gli archivi dati sono classificati in una varietà di categorie in base ai loro vantaggi e svantaggi. Database a oggetti, database NoSQL e database relazionali sono alcuni dei tipi più comuni di database.
Perché il database relazionale è importante per l'archiviazione dei dati?
Un database relazionale è un tipo di database in cui è possibile utilizzare un ID univoco o "chiave" per accedere ai dati memorizzati in varie tabelle. Questa chiave è utile per sbloccare le voci di dati relative a una chiave in un'altra tabella, consentendo agli utenti di gestire l'inventario, spedire articoli e fare una varietà di altre cose.
Come un database relazionale può aiutare il tuo business
Il database relazionale può essere utilizzato in vari modi, ma il suo scopo principale è archiviare dati correlati tra loro. Di conseguenza, gli imprenditori che devono tenere traccia dei propri clienti, prodotti e ordini possono utilizzarlo.
Il database relazionale può essere utilizzato anche per archiviare i dati che le aziende archiviano quotidianamente nelle loro operazioni. Clienti, prodotti, ordini e altre informazioni vengono tutti raccolti in questo modo. Di conseguenza, un database relazionale può essere utilizzato da aziende di tutte le dimensioni.
Quale sistema di database memorizza i dati nelle tabelle relazionali in Nosql?

Esistono molti sistemi di database che memorizzano i dati in tabelle relazionali in nosql, ma i più popolari sono MySQL, Oracle e Microsoft SQL Server. Ciascuno di questi sistemi di database ha i propri punti di forza e di debolezza, quindi è importante scegliere quello giusto per le proprie esigenze.
I database SQL, d'altro canto, mancano della flessibilità e della scalabilità offerte dai sistemi NoSQL, come l'archiviazione tabelle di Azure. Consentono un sistema di archiviazione molto più scalabile, nonché la possibilità di aggiungere facilmente nuovi tipi di dati senza influire sulla struttura dei dati esistente. Poiché lo schema dei dati è più flessibile, gli sviluppatori possono creare app con maggiore flessibilità.
In che modo l'archiviazione del database Nosql differisce dall'archiviazione del database Sql relazionale?
I database MySQL sono database relazionali, mentre i database SQL non lo sono. I database SQL hanno schemi predefiniti e utilizzano un linguaggio di query strutturato. Gli schemi dinamici vengono utilizzati nei database NoSQL per i dati non strutturati. I database SQL sono scalabili verticalmente, mentre i database NoSQL sono scalabili orizzontalmente.

SQL è un linguaggio di query in uso dagli anni '70. Un database NoSQL, a differenza di un database SQL, non contiene strutture nidificate. I database NoSQL, per natura, possono essere ridimensionati verticalmente, consentendo di caricare più risorse su un server. È possibile lavorare con una varietà di strutture di dati in un database NoSQL. Poiché i database NoSQL non memorizzano i dati in righe o tabelle, non si basano esclusivamente su di essi. Poiché possono gestire schemi dinamici per dati non strutturati, è meno probabile che richiedano la pre-pianificazione e l'organizzazione dei dati. I database SQL e relazionali possono gestire un gran numero di punti dati, scalare in base alle esigenze e consentire una maggiore flessibilità nell'accesso ai dati.
Poiché ogni informazione è memorizzata in un'unica posizione, una versione precedente dell'immagine non sembra fuori posto ora. Inoltre, NoSQL è una scelta eccellente quando si ha a che fare con grandi insiemi di dati (o in continua evoluzione). Poiché richiedono grandi quantità di dati, i database di grandi dimensioni sono fondamentali per le grandi aziende come Facebook, Google e altri. Cassandra e altri database NoSQL gestiscono enormi quantità di dati distribuiti su numerosi server. Se hai bisogno di accedere a un negozio di valore-chiave in un breve periodo di tempo senza solide garanzie di integrità, Redis potrebbe essere la soluzione migliore. Elastic Search è una scelta eccellente quando si tratta di una ricerca complessa o flessibile.
I database NoSQL hanno completamente cambiato il modo in cui pensiamo all'archiviazione e al recupero dei dati. Il vantaggio di questi database rispetto ai tradizionali database relazionali è la facilità d'uso e le prestazioni. I database NoSQL possono gestire grandi quantità di dati non strutturati, come documenti, multimedia e dati di sensori, in particolare. Molti dei più grandi rivenditori online del mondo, come Amazon ed eBay, archiviano grandi quantità di dati dei clienti in database NoSQL. Non c'è motivo per cui i database NoSQL non dovrebbero essere lo standard de facto per l'archiviazione e il recupero dei dati man mano che guadagnano popolarità. Questi database presentano molti vantaggi rispetto ai tradizionali database relazionali e possono essere utilizzati in una varietà di applicazioni.
Quale tipo di dati viene spesso memorizzato nei database Nosql?
Esistono molti tipi diversi di dati che possono essere archiviati in un database NoSQL, ma il tipo più comune sono i dati non strutturati. Questo tipo di dati non è vincolato da uno schema particolare, il che lo rende più flessibile e più facile da scalare rispetto ad altri tipi di database.
I quattro tipi più comuni di database NoSQL sono archivi di valori-chiave, archivi di documenti, database orientati alle colonne e database a grafo. Il problema che può essere risolto solo da uno di questi tipi è lo stesso che può essere risolto solo da un database relazionale. OrientDB, ad esempio, è un database NoSQL che combina modelli e tipi. Con l'aggiunta di tabelle di collegamento e tipi di entità, un database relazionale può essere costituito da molte entità. I dati di una persona o di un'entità vengono visualizzati nella loro interezza in una riga. Poiché sono coinvolte solo poche colonne, il database memorizza ogni colonna separatamente, con conseguente scansione più rapida. A differenza degli indici, le colonne nei database associano i dati alle righe.
L'archivio chiave-valore è il meno complesso dei database NoSQL in termini di complessità. I documenti possono essere archiviati nello stesso modo di prima e possono essere facilmente interrogati e calcolati in base a questo. La normalizzazione non è importante per documentare i negozi fintanto che i dati sono strutturati in modo sensato. L'obiettivo dei database grafici è semplificare la gestione delle relazioni tra entità. I database a grafo hanno due componenti principali: dati e struttura. Questo è l'ente responsabile. Una linea collega due entità; rappresenta la relazione dell'entità e le sue proprietà. I database a grafo, come Neo4j, affermano di essere conformi ad ACID, mentre gli archivi di valori-chiave e gli archivi di documenti aderiscono allo standard.
I database NoSQL differiscono dai tradizionali database relazionali in termini di funzionalità Zero Downtime. Nel caso dei database relazionali, possono verificarsi tempi di inattività del sistema per aggiornamenti e riparazioni, che possono essere costosi per le aziende. Grazie a NoSQL, è semplice per le aziende mantenere aggiornati i propri dati senza dover subire tempi di inattività.
Inoltre, i database NoSQL forniscono una struttura dati più flessibile, consentendo alle aziende di soddisfare i propri requisiti specifici in materia di dati. Di conseguenza, quando sviluppano i propri dati in database relazionali, le aziende devono aderire a regole e strutture predeterminate, che possono essere difficili o restrittive da modificare.
L'ascesa dei database NoSQL è dovuta alla loro capacità di fornire una soluzione più efficiente e flessibile rispetto ai database tradizionali. Queste soluzioni sono ideali per le aziende che devono mantenere i propri dati aggiornati senza tempi di inattività e forniscono una struttura dati più flessibile adattata alle esigenze di ciascuna organizzazione.
Quale tipo di dati è meglio per Nosql?
Un database NoSQL è in genere più adatto all'archiviazione e alla modellazione di dati strutturati, semi-strutturati e non strutturati all'interno di un singolo database.
Quale dei seguenti è un tipo Nosql?
I quattro tipi di database NoSQL sono archivi di valori chiave (KV), archivi di documenti, archivi di dati di famiglie di colonne e database di grafici.
Tipi di database Nosql
Un database NoSQL è un database non relazionale che non utilizza il tradizionale schema tabulare di righe e colonne. I database NoSQL vengono spesso utilizzati per applicazioni Big Data che richiedono un elevato grado di scalabilità e flessibilità. Esistono quattro tipi principali di database NoSQL: archivi di valori-chiave, archivi di documenti, archivi di colonne e database a grafo.
L'uso di database NoSQL per soddisfare le esigenze di sistemi alternativi è indicato come il loro equivalente ai database SQL. Un sistema di gestione di database relazionali utilizza un modello di tabella riga e colonna, mentre un database XML utilizza un modello di dati con una struttura diversa. I database NoSQL sono, come ci si potrebbe aspettare, distinti l'uno dall'altro. I database di documenti con grandi architetture scale-out sono più comunemente usati nelle organizzazioni. L'utilizzo di questa tecnologia in una varietà di settori, dalle piattaforme di e-commerce alle piattaforme di trading allo sviluppo di app, è vantaggioso. In questo articolo, esaminerò come MongoDB si confronta con PostgreSQL, nonché qual è il principale database NoSQL. Un database a colonne può ora aggregare i valori di varie colonne.
Poiché scrivono i dati in questo modo, può essere difficile per loro avere una forte coerenza. I database a grafo sono ottimizzati per la ricerca di elementi di dati con connessioni. Più tabelle in SQL possono essere UNITE tramite questi metodi, eliminando la necessità di sovraccarico SQL.
Oltre ad essere più flessibili e scalabili rispetto ai database SQL tradizionali, i database NoSQL stanno diventando sempre più popolari. MongoDB è il database NoSQL più popolare ed è un database open source incentrato sull'elaborazione dei documenti. Ciò consentirà una maggiore flessibilità nella modellazione dei dati e nella query. MongoDB, d'altra parte, supporta un'ampia gamma di linguaggi di programmazione, rendendolo semplice da imparare. Il database NoSQL sta diventando sempre più popolare grazie alla maggiore flessibilità e scalabilità rispetto ai database SQL. Se stai cercando maggiore flessibilità e scalabilità rispetto a un database SQL, i database NoSQL potrebbero essere la soluzione migliore per te.
Database Nosql
Un database NoSQL è un database non relazionale che non utilizza il tradizionale schema tabulare di un database relazionale. I database NoSQL sono spesso usati per big data e applicazioni web in tempo reale.
Con particolare attenzione alla scalabilità, alle query veloci e alla semplificazione della programmazione, i database NoSQL sono stati sviluppati alla fine degli anni 2000. Poiché i database NoSQL sono flessibili, scalabili orizzontalmente e semplici da utilizzare, possono essere personalizzati per soddisfare le esigenze degli sviluppatori. I database SQL (Structured Query Language) con schemi rigidi, complessi e tabulari sono ideali per l'accesso tramite database relazionali. In MongoDB 4.0 sono ora supportate più transazioni ACID, nonché un'estensione di quelle in 4.2 per estendersi su cluster frammentati. I modelli di dati sono studiati in numero uno. L'obiettivo principale dei database NoSQL è ottimizzare i dati per le query piuttosto che ridurre la duplicazione dei dati. Come parte del n.
No. Database SQL, la compressione può anche ridurre i footprint di archiviazione. I database a grafo sono eccellenti per l'analisi delle relazioni, ma potrebbero non essere in grado di fornire tutte le informazioni necessarie su base giornaliera. L'utilizzo di MongoDB nel tuo caso d'uso può essere determinato esaminando il white paper Dove utilizzare MongoDB. MongoDB Atlas è un ottimo database NoSQL con cui iniziare. Puoi imparare MongoDB da zero con MongoDB University , che offre formazione online completamente gratuita.
Le organizzazioni che richiedono grandi quantità di gestione dei dati possono trarre grandi vantaggi da NoSQL. Non è solo veloce e scalabile, ma è anche molto utile. È ideale per applicazioni di dati di grandi dimensioni perché è molto semplice da utilizzare.
Database relazionali
I database relazionali sono database che memorizzano i dati nelle tabelle. Le tabelle sono simili alle cartelle in un file system, in cui ogni tabella memorizza una raccolta di informazioni. Le tabelle sono collegate tra loro tramite relazioni, che sono definite dai dati che contengono. Le relazioni possono essere uno a uno, uno a molti o molti a molti.
Cos'è un database relazionale? La tabella è composta da righe e colonne in un database relazionale. Di solito è organizzato in tabelle con chiavi primarie ed esterne che possono essere unite insieme. Un database relazionale è un tipo di database che memorizza comandi e transazioni in un'unica posizione. Il linguaggio di query strutturato (SQL), un'invenzione IBM, è un linguaggio di programmazione comunemente utilizzato nei database. A causa di un problema di marchio, SQL è stato rinominato SEQUEL e SEQUEL è stato rimosso. Consente agli utenti di accedere ai dati nei database utilizzando solo poche righe di codice.
Uno dei prodotti di maggior successo di IBM è il database DB2. Poiché la seconda famiglia di software di gestione dei database di IBM è nota come famiglia DB2, la famiglia di database relazionali DB2 è stata introdotta nel 1983. I database non relazionali non richiedono uno schema di database così rigido come i database relazionali. Il vantaggio principale di un database relazionale è la sua capacità di generare informazioni significative unendo le tabelle. Se una transazione bancaria o finanziaria contiene un errore e un reinvio, l'informazione potrebbe essere migliore della precedente. Sebbene i database relazionali siano stati tradizionalmente visti come una soluzione di archiviazione più rigida e poco flessibile, i progressi tecnologici hanno reso questa prospettiva obsoleta. Con i database relazionali basati su cloud, la perdita di dati durante un ripristino viene misurata in secondi o minuti. La maggior parte dei database relazionali dispone di semplici opzioni di esportazione e importazione, che semplificano i backup e i ripristini. La replica di lettura ti consente di archiviare una copia di sola lettura dei tuoi dati in un data center cloud.
I database orientati ai documenti come MongoDB, Couchbase e Apache HBase sono ideali per lo sviluppo rapido di applicazioni grazie alla loro flessibilità e facilità d'uso. Questi database possono essere rapidamente popolati con dati provenienti da varie fonti, il che li rende ideali per lo sviluppo di applicazioni in grado di rispondere rapidamente alle mutevoli condizioni dei dati.
I database orientati ai documenti hanno l'ulteriore vantaggio di essere facili da scalare verso l'alto o verso il basso. Il database di MongoDB può essere facilmente ampliato se un'applicazione specifica richiede più spazio di archiviazione. Se un'applicazione più piccola richiede l'arresto, Couchbase e Apache HBase possono essere facilmente ridimensionati.
I database orientati ai documenti sono una scelta eccellente per lo sviluppo rapido di applicazioni grazie alla loro facilità d'uso, scalabilità e velocità d'uso.
I vantaggi dei database relazionali
i database relazionali stanno diventando sempre più popolari perché offrono una serie di vantaggi rispetto ai database non relazionali. Ha anche la possibilità di aumentare e diminuire le dimensioni, nonché la possibilità di collegare tra loro le tabelle e cercare tra le tabelle il più rapidamente possibile.