
NoSQL データベースでデータをモデル化する際に留意すべき 3 つの重要事項
公開: 2023-02-27NoSQL データベースでのデータのモデリングに関しては、留意すべき重要な点がいくつかあります。 まず、リレーショナル データベースと非リレーショナル データベースの違いを理解することが重要です。 MySQL などのリレーショナル データベースは、データをテーブルと行に格納します。 MongoDB などの非リレーショナル データベースは、データをドキュメントに格納します。 つまり、NoSQL データベースでデータをモデル化する場合、ドキュメント ベースのデータベースにとって意味のある方法でデータを構造化する方法を考える必要があります。 次に、データに対して実行する必要があるクエリの種類を覚えておくことが重要です。 リレーショナル データベースでは、通常、SQL を使用してデータをクエリします。 ただし、NoSQL データベースでは、別のクエリ言語を使用する必要があります。 たとえば、MongoDB では、 MongoDB クエリ言語(MQL) を使用します。 最後に、データのインデックスを作成する方法について考えることが重要です。 リレーショナル データベースでは、通常、テーブルと列にインデックスを作成してデータにインデックスを付けます。 ただし、NoSQL データベースでは、別の方法でデータのインデックスを作成する必要があります。 たとえば、MongoDB では、ドキュメントとフィールドにインデックスを作成できます。 これら 3 つのことを念頭に置くことで、効率的でスケーラブルな方法で NoSQL データベースのデータをモデル化できます。
複数のコンピューターに分散された SQL データベースは、リレーショナル モデルから脱却するように設計されています。 NoSQL データベースにはデータ モデルがないという一般的な誤解があります。 スキーマを作成する最初のステップは、データの編成方法を記述することです。 各タイプの NoSQL データベースには独自のデータ モデル セットがあるため、それらの違いは当然のことです。 その結果、スキーマの設計は、アプリケーションの存続期間を通じて反復されます。 どの NoSQL データベースを使用するかを決定する際の最も重要な考慮事項の 1 つは、データ モデルが最適なユース ケースです。 各ドキュメントには、さまざまなデータ型とデータ構造に加えて、複数のフィールドと値が格納されます。
さまざまなタイプのフィールド値を処理するために、さまざまな強力なクエリ言語が開発されており、クエリを使用してフィールド値を取得できます。 NoSQL データベースには、各行にキーと関連する列が含まれており、これらは列ファミリーと呼ばれます。 これは、NoSQL データベースの 4 つの主要なタイプのそれぞれにデータを格納する基礎となる構造です。 データの編成方法の詳細は非常に柔軟ですが、「スキーマのない」システムが必要になる場合もあります。 ドキュメント データベース、ワイドカラム データベース、およびグラフ データベースには、通常、特定のクエリ言語が組み込まれています。
Nosql データベース スキーマの例
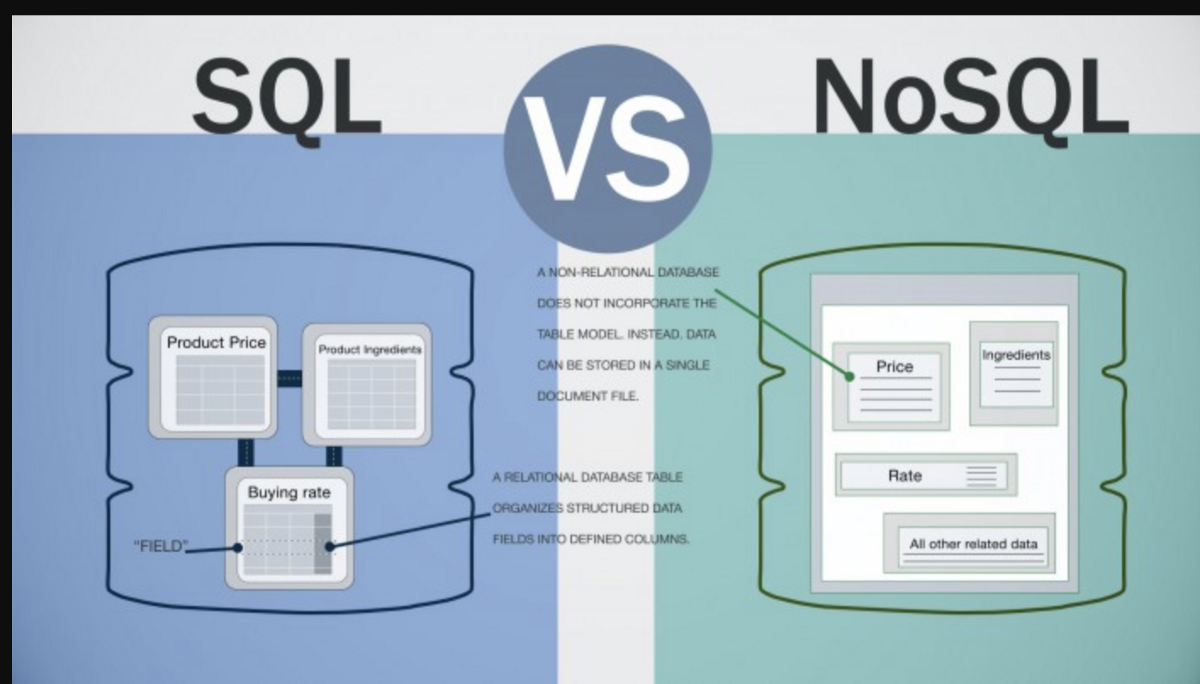
NoSQL データベースは、リレーショナル データベースの従来のテーブル ベースのスキーマを使用しない非リレーショナル データベースです。 NoSQL データベースは、構造化されていないデータ、多数のリレーションシップを持つデータ、絶えず変化するデータなど、リレーショナル データベースにはあまり適していない大量のデータを保存するためによく使用されます。
NoSQL データベースには階層がないため、固定スキーマを使用してデータを管理する必要はありません。 生成および消費されるデータの量が多いため、ストレージ要件の高い分散データ ストアには NoSQL データベースが使用されます。 Twitter、Facebook、および Google は、NoSQL を使用してデータを保存し、リアルタイム Web アプリを構築する企業の 1 つです。 データをキーと値のデータベースに格納し、データベースから取得することでキーと値のペアとして使用できます。 連想配列およびコレクション データベース タイプは、このタイプの NoSQL データベースの一般的な用途です。 ドキュメント タイプは通常、コンテンツ管理システム (CMS)、ブログ プラットフォーム、リアルタイム分析、および e コマース アプリケーションの基盤として機能します。 グラフ データベース内のデータは、ソーシャル ネットワーク、物流、または空間マップの構築に使用できます。
CouchDB ビューは、システムを使用して MapReduce で定義できます。 それによると、分散データ ストアは 3 つのうち 2 つ以上を保証できません。 一貫性は、操作が完了した後でも、一般的にデータの一貫性にとって重要です。 サーバーが相互に通信できない場合は、パーティション トレランスを維持する必要があります。
Nosql データベース: ニューノーマル?
NoSQL データベース プラットフォームは、従来のリレーショナル データベース プラットフォームよりも柔軟で効率的です。 厳格なスキーマを必要としないため、これらのタイプのデータベースは多くの場合、より簡単に使用できます。 一方、これらはリレーショナル データベースのすべての機能を備えているわけではありません。
Nosql データ モデリング
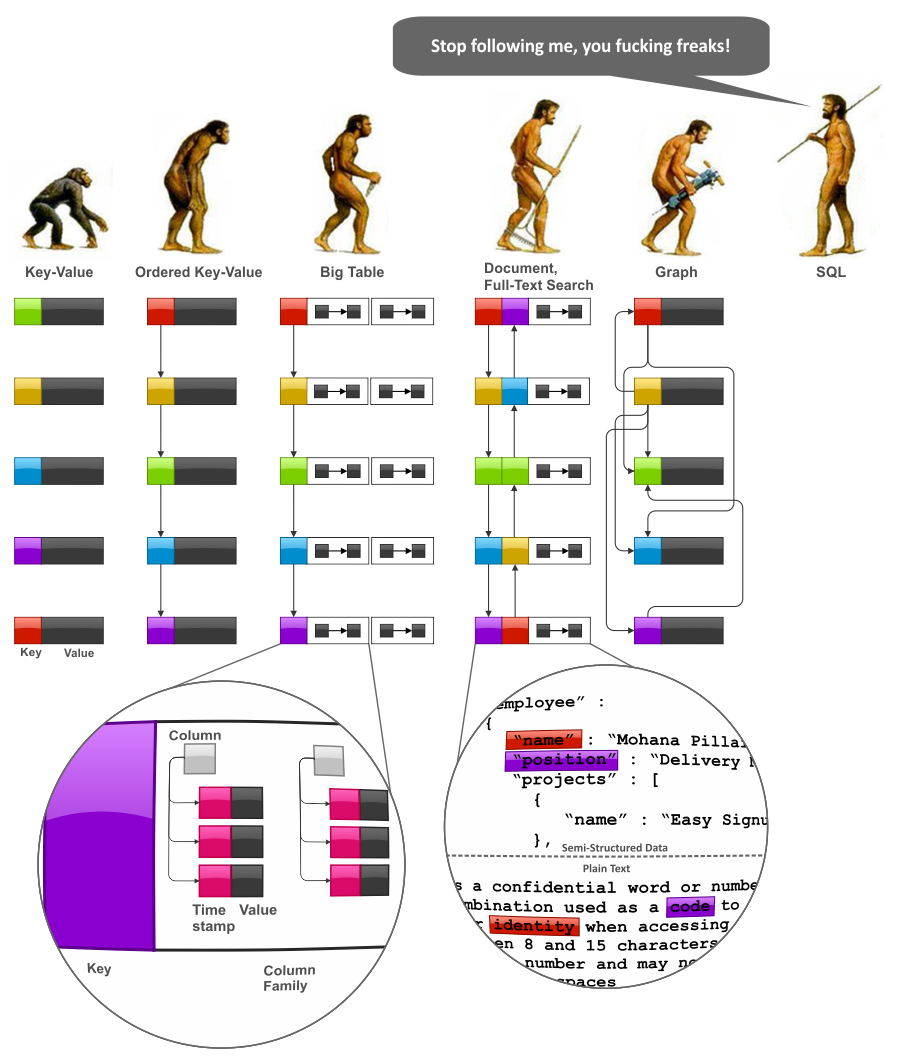
NoSQL データモデルとは? このモデルは、リレーショナル データベース管理システム (RDBMS) の使用に依存しません。 その結果、データがどのように相互に作用するか、つまりすべてがどのように接続されるかについて、モデルがあいまいになります。
8 Data Modeling Patterns in Redis は、Redis でのデータ モデリングを学習するための優れた本です。 法外に高価になる可能性がある従来のリレーショナル データベースの制限なしで最新のアプリケーションを作成するために使用できる 8 つのデータ モデルについて説明します。 NoSQL プラットフォームでは、2 つの個別のテーブルまたはコレクションを 1 つのテーブルに統合できます。 その結果、関係をよりよく理解し、関連するすべてのデータをより簡単に見つけることができます。 各テーブルは、NoSQL アプリケーションでは独自のビューです。つまり、そのパフォーマンスはアプリケーションに依存しません。 制限付きリスト (既知のサイズのリストなど) は無制限リストとして埋め込まれますが、無制限リストは無制限リストとして個別に埋め込まれます。 この場合、それは 1 であるため、次の変数が必要です: 製品、著者、発行日、評価、およびコメント。
最初のパターンには、無制限の側面を持つ多対多の関係があります。 リレーショナル データベースでは、さまざまな種類の製品をテーブルに分割して追跡する必要があります。 Redis Stack を使用して、コレクションの型フィールドを区別することができます。 バケット パターンを進めていくと、時系列データを保存および管理することでオーバーヘッドを削減できます。 リビジョン パターンをリアルタイム データと組み合わせて使用することで、多くのユース ケースを強化できます。 NoSQL を使用すると、これらのパターンをさまざまな方法で使用して、JOIN 操作の複雑さを軽減できます。 HR システム、CMS、製品カタログ、ソーシャル ネットワークなどの負荷の高い JOIN 操作では、ツリーとグラフのパターンを使用する必要があります。
強化のためにリレーショナル データベース管理システム (RDBMS) を使用する必要はありません。 データは、ディスク、メモリ内ドライブ、またはその両方に保存できます。 Redis と NoSQL を使用してアプリケーションを作成する方法は、Redis Launchpad の多数の例で示されています。
Nosql データベース: 非リレーショナル データを格納する最良の方法
一方、Somenosql データベースは、リレーショナル データベースで実行できます。 たとえば、MongoDB と Cassandra は、多数のデータベースで見られる B-Tree インデックスを使用します。 Neo4j で使用されるグラフ モデルは、リレーショナル データベースと互換性がありません。 NoSQL データベースは、従来のデータベースよりも柔軟で効率的であるため、人気が高まっています。 リレーショナル モデルに基づいていないデータ モデルが必要な場合、nosql データベースが優れた選択肢であることは驚くに値しません。
Nosql データベースの設計方法
NoSQL データベースを設計する最善の方法は、アプリケーションの特定のニーズによって異なるため、この質問に対する決定的な答えはありません。 ただし、データベースが最適に設計されていることを確認するために従うことができる一般的なヒントがいくつかあります。 まず、データベースに格納されるデータとデータ間の関係を理解することが重要です。 これは、データに最適なスキーマを決定するのに役立ちます。 次に、アプリケーションに適した NoSQL データベース テクノロジを選択することが重要です。 さまざまなテクノロジが利用可能であり、それぞれに独自の長所と短所があります。 最後に、パフォーマンスのためにデータベースを設計することが重要です。 これは、インデックス作成やシャーディングなどを考慮することを意味します。

正規化された RDBMS を使用すると、リレーショナル パラダイムの本来の長所を活用できます。 NoSQL データベースの主な利点は、半構造化された集計と動的エンティティをモデル化できることです。 エンティティと関係の代わりに、階層と集計の観点から NoSql をモデル化する方法を検討する必要があります。 RDBMS で定義されている非正規化は、DB を NoSQL データベースに効果的にシャットダウンします。 集計のサブセットのみが必要な場合は、コードに参加する必要があります。集計の集計が必要な場合は、それを解析する必要があります。 できるだけ早く関係を特定することが重要です。
Nosql 設計
アプリケーション指向のアプローチとは対照的に、NoSQL データ モデルは、データ内の関係ではなく、アプリケーションがデータをクエリする方法に焦点を当てています。 厳格なリレーショナル スキーマではなく、NoSQLデータベースの設計原則では、データの柔軟性が重視されます。
その結果、NoSQL データベースには、アプリケーション アーキテクチャの対応する変更が伴う必要があります。 サーバーの複雑さは、NoSQL アプローチの一部として、SQL ベースのデータベースから移行されます。 この記事では、データ管理のさまざまな側面を見ていき、NoSQL データベースではなくデータ管理層を使用するアーキテクチャを推奨します。 通常、オブジェクト指向の NoSQL データベースには、データ エンティティのネストされた構造があります。 親ドキュメントの子/サブ構造が常にドキュメント内からアクセスできる場合、ネストされたデータ構造はうまく機能します。 ネストされた構造を使用することで、場合によっては双方向の関係を回避できます。 一部の重要なアプリケーションでは、依然として関係が必要です。
従来の RDBMS との関係を管理する方法はよく理解されています。 NoSQL データベースを使用してどのように関係をモデル化できますか? 2 つの戦略のいずれかを試すことができます。 データの重複を最小限に抑える 1 つの方法は、正規化戦略を採用することです。 1 つのオプションは、データを非正規化することです。これにより、クエリのパフォーマンスが向上する可能性があります。 データ管理に対する NoSQL アプローチは、Edgar Codd の歴史的なデータ管理の柱を弱体化させようとすると、誤解される危険があります。 その結果、データベース アクセスは、再利用可能な API としてではなく、実装の内部コンポーネントとして見なされる必要があります。
NoSQL ストレージとデータベース全体でデータの一貫性を維持することが重要です。 Key-Value ドキュメント データベースは、Berkeley の DB API と同様のインデックス API を使用してインデックス化されました。 レポートによると、W3C は、NoSQL データベースはクエリベースのアクセスではなく、インデックスへのプログラムによるアクセスを行うべきであると結論付けました。 その結果、データの有効性と整合性の制約を引き続き実施する必要があります。 検証をストレージ層から移動することで、データ管理層に集中化できます。 一般に、一貫性ベースのレプリケーション システムは、より厳密なトランザクション セマンティクスに基づいて、個々のデータベース ストレージ システムの上に実装できます。 カスタム レプリケーションと一貫性の強制は、より高い整合性を必要とするアプリケーションや、緩和された一貫性のより大きなスケーラビリティを必要とするアプリケーションに非常に役立ちます。
Multi-Version Concurency Control (MVCC) スタイルの競合解決を使用した CouchDB での競合の解決は、単純な場合があります。 Persevere 2.0 では、データ モデルを定義して、製品を製造元にリンクできます。 私たちの努力の結果、MVC アーキテクチャ モデルは効果的に実装されました。 このタイプのユーザー インターフェイス レイヤーを mVC として再大文字化することは、ユーザー インターフェイス ロジックにおけるデータ モデリングの関心から離れて重点を置いていることを示しています。
Nosqlと例とは何ですか?
NoSQL データベース (SQL とも呼ばれます) は、リレーショナル データベースとは異なる方法でデータを格納するデータベースの一種です。 NoSQL という用語は、さまざまなデータベースの設計を可能にするデータ モデルを指します。 ドキュメント タイプ、キー値タイプ、ワイドカラム タイプ、およびグラフが最も一般的です。
Nosql のアーキテクチャとは
NoSQL データベース アプローチにより、SQL ベースのデータベースを実行するサーバーは、大量のデータを処理する必要がなくなります。 検証、アクセス制御、データ マッピング、相関アクティビティ、競合解決、整合性制約の維持、およびトリガーされたプロシージャはすべて、データベース レイヤーから削除されます。
Nosql クラウド データベースの利点
従来のリレーショナル データベースよりもnosql クラウド データベースを使用することには、いくつかの利点があります。 スケーリングに関しては、より柔軟です。 それらは、他のタイプのソフトウェアよりも読み取りおよび書き込み操作に関して優れたパフォーマンスを発揮します。 3 つ目の利点は、データ変更の処理が優れていることです。
Nosql データベースの設計に使用されるツールはどれですか?
Hackolade、DbSchema、およびCassandra Data Modeler は、 NoSQL データベース スキーマ設計ツールの一部です。 Hackolade のビジュアル スキーマ デザインは、あらゆるタイプの NoSQL データベースに最適です。 DbSchema は、既存の NoSQL データベースからスキーマを抽出し、XML に変換します。
SqlまたはNosql?
NoSQL データ モデルは、使いやすく、製品間で一貫性がないため、人気が高まっています。 SQL データベースを使用すると、クエリを処理し、テーブル間でデータを結合することにより、構造化データに対して複雑なクエリを簡単に実行できます。 NoSQL データベース間での一貫性の欠如、およびより頻繁にデータをクエリする必要性により、クエリ時間が増加する可能性があります。 分析目的でデータをすばやくクエリする必要がある場合は、SQL データベースが最も可能性の高いソリューションです。 ただし、より柔軟で構造化されていない形式でデータを保存する必要がある場合は、NoSQL データ モデルの方が適している場合があります。
Nosql ドキュメント
より高速で柔軟なデータ管理ソリューションの必要性が高まるにつれて、 Nosql ドキュメント データベースの人気が高まっています。 これらのデータベースは、高いパフォーマンス、スケーラビリティ、および柔軟性を提供するように設計されているため、幅広いアプリケーションに最適です。
ドキュメント指向データベースは、列や行ではなく JSON をデータ ストレージとして使用する最新のアプローチです。 半構造化データを扱う場合、RDBMS では把握がより困難な問題を処理できます。 ドキュメント ストアは、アジャイルな開発者にとって自然で柔軟なソリューションです。 表現力豊かなクエリ言語と多面的なインデックス作成により、さまざまなクエリ オプションが提供されます。 ACID トランザクションを実行することで、リレーショナル データベースの保証を引き続き利用できます。 distributedsystems.com にアクセスすると、分散システムがデータのスケーラビリティと回復力を向上させる方法について詳しく知ることができます。 個々のドキュメントは独立した単位であるため、データの局所性を損なうことなく、サーバー間で簡単に配布できます。
ドキュメント データベースで直感的で実用的なモデリングを使用すると、リレーショナル データベースで使用されるモデルよりも高速にモデルを読み取ることができます。 データ品質が低下することが予想され、厳密なテーブルによるデータの劣化のリスクがあります。 リレーショナル データベースにはネイティブのスケールアウトがないため、既存のデータベースを分割 (シャード) する場合は、コストのかかるスケールアップ システムの料金を支払う必要があります。 ドキュメント指向データベースは、さまざまな種類のドキュメントを格納でき、通常はフィールドに入力する必要はありません。 それぞれの分野が異なるという事実にもかかわらず、共通の構造構成があります。 各ドキュメントには、情報の追加、変更、削除、またはクエリに使用できる一意の ID が含まれています。 カプセル化されたデータ (または情報) のカプセル化は、通常、標準形式またはデコードで行われます。
ドキュメント指向のデータベースは、従来のデータベースよりもはるかに柔軟な構造を持っています。 データは、クエリ時にデータベース内の列からではなく、ドキュメントから直接保存されます。 追加する必要がある唯一のデータ フィールドは、ドキュメント ストア内のデータセットに関連するものです。
ファイルの保存にドキュメントがリレーショナル テーブルより優れている理由
ドキュメントは、リレーショナル データベースよりも大きなファイル ストレージの効率が高いため、ファイルの格納によく使用されます。 文書文書には、検索と操作が便利であるという利点もあります。