
NoSQL データベースを最適化する 5 つの方法
公開: 2023-01-12NoSQL データベースは、従来のリレーショナル データベースよりもスケーラブルで柔軟であると見なされているため、ますます人気が高まっています。 NoSQL データベースを最適化するには、次のようなさまざまな方法があります。 2. データのインデックス作成: これにより、クエリのパフォーマンスが向上します。 3. キャッシングの使用: キャッシングは、頻繁にアクセスされるデータをメモリに格納することで、パフォーマンスの向上に役立ちます。 4. データの分割: 複数のサーバーにデータを分散することで、パフォーマンスとスケーラビリティを向上させることができます。 5. パフォーマンスの監視: これは、ボトルネックを特定し、是正措置を講じるために重要です。
eBay アーキテクトの Jay Patel は最近、Cassandra データ ストアを使用したデータ モデリングに関する記事を公開しました。 彼は、Cassandra を使用してデータ モデルを設計した方法、列と列ファミリーを使用した方法、およびクエリの最適化を使用してクエリ結果を最適化した方法について説明しています。 彼らのアプローチからの私のお気に入りの洞察の 1 つは、それがあらゆる NoSQL データベースに適用できるということです。 データ モデルを最適化する前に、まずアクセス方法を理解する必要があります。 クエリに時間がかかっていることに気付き始めると、リレーショナル データベースでパフォーマンスの問題が発生していることに気付きます。 データが正規化されると、不要な結合や n+1 クエリが発生する可能性が低くなります。 NoSQL データ ストアで非正規化が可能である場合でも、それに関連するコストが発生します。
Nosqlのクエリ最適化とは?
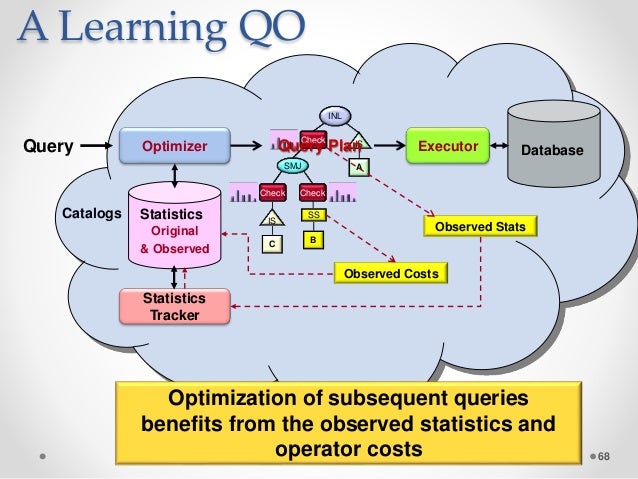
クエリ最適化の目標は、最も効率的なプランを見つけることです。 効率を測定するときは、レイテンシとスループットが使用されます。 コストベースの最適化のコストは、メモリ、CPU、およびディスク領域のコストと同じです。 NoSQL の世界では、ほとんどのデータベースが SQL に似たクエリ言語をサポートしています。
MongoDB データベースは、ドキュメント データベースとも呼ばれる NoSQL データベースです。 このデータベースは、他のリレーショナル データベースよりも開発が容易になるように設計されています。 Explain() を使用すると、クエリがどのように機能するかを確認できます。 Explain を使用して、クエリ プラン、クエリ ステージなどを含むドキュメントを作成できます。 この記事の結果として、インデックスが特定のコレクションのスキャン ステージをどのように変更できるかを理解することができます。 この記事の目的は、最適化の基礎について説明することです。 集計ステージの最適化の詳細については、後続の記事で説明します。 黒人はテクノロジーの分野で優れています。 このリソース コレクションでは、知っておくべきいくつかのことを強調しています。
Nosql が速い理由は?
Nosql データベースは、高速でスケーラブルになるように設計されています。 これを実現するために、水平スケーリング、シャーディング、非正規化などのさまざまな手法が使用されます。
noSQL システムの大部分は、単なる永続的なキーまたは値のストレージです (Project Voldemort など)。 クエリが特定のキー値を検索する必要があるタイプの場合、RDBMS と同じくらい迅速に検索できるシステム。 ドキュメント データベース (CouchDB など) も一般的な nosql システムです。 これらのデータベースでは、データ構造を構築するために非正規化が多用されています。 実際、アプリケーションのパフォーマンスは、1 つの要件を満たすために必要な部品の数によって測定できると私は信じています。 NoSQL を使用すると、djondb のような NoSQL データベースのパフォーマンスは、単純な挿入が 1 つだけ必要な場合に 10 倍速くなる可能性があります。 NoSQL によって消費されるデータが少なくなるため、開発者はより効率的に作業できるようになります。
NoSQL DATABASES (境界なし) の主な目標は、高レベルのスケーラビリティを維持することです。 実行しているクエリの種類、テーブルで使用している列、および使用しているサーバーの実装を考慮する必要があります。 より多くのノードを 1000000rpm 安定 2 ミリ秒でクレートし、より少ないコードを使用すると、より高い安定速度とパフォーマンスを備えたより高速なノードが得られます。
Nosql が Sql より速い理由は何ですか?
この方法では、さまざまなデータ エンティティの収集、統合、および分割が必要になります。 その結果、NoSQL データベースは、SQL データベースよりも高速に読み取りおよび書き込み操作を実行します。
Nosql データベースが主流になっている理由
さまざまな要因に加えて、NoSQL データベースの人気が高まっています。 それらは使いやすく、大量のデータを処理でき、アプリケーションの特定の要件を満たすように調整できます。 柔軟性とカスタマイズ性に加えて、他のデータベース タイプでは見られない多くの利点があります。
Nosql パフォーマンス チューニング

Nosql パフォーマンス チューニングとは、nosql データベースが可能な限り効率的に実行されていることを確認することです。 nosql データベースを調整する際に注目すべき重要な領域がいくつかあります。 1. データベースが適切にインデックス化されていることを確認します。 2. クエリが最適化されていることを確認します。 3. データが適切に正規化されていることを確認します。 4. データベースが適切に構成されていることを確認します。 これらの重要な領域に集中することで、nosql データベースが最高のパフォーマンスで実行されていることを確認できます。
Mango の負荷が高い場合、MangoNoSql スクリプトはバックグラウンドでバックグラウンド書き込みを実行します。 Batch Write Behind 機能を使用すると、舞台裏で書き込むことができます。 各タスクは他のタスクと並行して実行され、プールからのポイント値が注目されます。 システムで NoSQL データ損失イベントに気付いた場合は、パフォーマンス設定を変更することをお勧めします。 [今すぐバックアップ] ボタンを押すと、システムを今すぐバックアップするためのジョブのキューが作成されます。 NoSQL モジュールの一部としてメモリ リストに書き込む準備ができているすべてのポイント値は、mango に保存されます。 その後、リストから「タスクごとのバッチ ライト ビハインド インサート」までを選択し、スレッドを開始してインサートを挿入します。
Nosql の長所と短所
NoSQL データベースを開発するときは、柔軟性と速度を維持することが重要です。 SQL よりも制約が少ないため、オーバーヘッドが少なくなります。 浅い NoSQL ストレージは柔軟で、さまざまなオブジェクト (ドキュメントまたはキーと値のペア) に分散できます。 NoSQL データベースは、開発、機能、およびパフォーマンスの点で難易度が低いと広く見なされています。 簡単に習得でき、従来のデータベース モデルに準拠しないデータを格納することを好むユーザーに使用されます。
Mongodb パフォーマンスの最適化
MongoDB は、強力なオープンソースのドキュメント指向データベース システムです。 インデックスベースの検索機能を備えているため、データをすばやく簡単に取得できます。 ただし、他のデータベース システムと同様に、MongoDB のパフォーマンスを最適化して、スムーズかつ効率的に実行できるようにすることができます。 MongoDB のパフォーマンスを最適化するために実行できる基本的なことがいくつかあります。 まず、正しいインデックスが配置されていることを確認することが重要です。 これにより、データを迅速かつ簡単に取得できるようになります。 次に、データベースを適切に編成しておくことが重要です。 これにより、データ サイズが小さくなり、クエリが容易になります。 最後に、データベースを定期的に監視して、円滑に実行されていることを確認することが重要です。 これらの簡単なヒントに従うことで、MongoDB をスムーズかつ効率的に実行し続けることができます。

Guy Harrison が、MongoDB 5.0 で新しいウィンドウ集約と集約パイプラインを使用する方法について、このブログ投稿で説明しています。 データ レイクは、ビッグ データと Hadoop への関心が爆発的に高まった結果として作成されました。 エンタープライズ データ ウェアハウス (EDW) に代わる最新のより効率的なデータ レイクが開発されました。 今週のブログでは、 MongoDB の Bツリー インデックスと、連結インデックスを作成してマルチキー ルックアップを最適化する方法に焦点を当てます。 さらに、インデックスを検討または使用する際には、いくつかのトレードオフを考慮します。
Mongodb でのパフォーマンスの向上とは?
MongoDB のクエリ パターンがわかっている場合は、MongoDB のパフォーマンスを次のように改善できます。頻繁なサブクエリの結果を格納して読み取り負荷を軽減します。 MongoDB クエリ パターンを検出します。 定期的に照会するすべてのフィールドにインデックスがあることを確認してください。 遅いクエリに気付いた場合は、ログを使用して特定できます。
Mongodb には大量の RAM が必要ですか?
MongoDB を単一のアセットで実行するには、1 GB の RAM が必要です。 システムがメモリからディスクへのスワップを開始する必要がある場合、パフォーマンスに深刻な影響を与えるため、回避する必要があります。
Mongodb にはクエリ オプティマイザーがありますか?
MongoDB でインデックスを使用できる場合、クエリ オプティマイザーは、最も効率的なクエリ プランを判断し、それをキャッシュします。 クエリ実行プランによって実行される「作業単位」 (作業) の数は、クエリ プランナーが候補プランを調べるときに、最も効率的なクエリ プランを決定するために使用されます。
Mongodb クエリ最適化ツール
Mongodb は、ユーザーがクエリのパフォーマンスを向上できるクエリ最適化ツールを提供します。 このツールは、クエリ実行プランを視覚化し、結果に基づいてクエリを最適化する方法を提供します。 このツールを使用すると、ユーザーは JSON、BSON、CSV などのさまざまな形式でクエリ実行プランを表示することもできます。
MongoDB は、検査システムの一部としてクエリ実行統計を提供します。 この情報は、開発者がクエリを最適化するために使用できます。 たとえば、Explain Plan タブを使用すると、ユーザーは計画の統計をグラフィカルに表示できます。 queryPlanner、executionStats、および allExecutionPlans に加えて、冗長モードを使用して説明できます。 一意、部分的、スパース (インデックス フィールドのないドキュメントをインデックス化しない)、非表示 (クエリ プランナーの結果を表示しない)、およびマルチキー インデックスはすべて MongoDB でサポートされています。 インデックスのプレフィックス キーやさまざまな並べ替え順序を使用する代わりに、複合インデックスを使用してインデックスを作成します。 MongoDB は、2 つのインデックスまたはプレフィックスを接続するときに、2 つの個別のインデックスまたはプレフィックスを使用して、クエリのパフォーマンスを最適化します。
Mongod のパイプラインには、インデックスが作成されていないフィールドに一致するステージが含まれています。 既に存在し、インデックスが作成されているフィールドを使用するようにマッチング ステージを書き直すことは、簡単な解決策です。 オプティマイザは、各候補計画を実行するときに実行する必要がある作業単位を探します。 読み取り負荷の高いアプリケーションを実行する場合は、レプリカ セットのサイズを増やしてシャーディングを実行する必要があります。 レプリケーションの状態と期間を監視する必要があります。 True: multi を使用する場合、一致するすべてのドキュメントを可能な限り効率的に更新します。 特定の順序でロック メトリックを調べます。
ロック時間が長い場合は、クエリ構造またはシステム アーキテクチャが適切に機能していないことを示している可能性があります。 バッチ処理により、リソース効率が向上します。 たとえば、Kafka のイベントは、チャンクではなくバッチで消費できます。 インデックスにコレクションへのキーが含まれていない場合、シャード コレクションのクエリにインデックスを作成することはできません。 $planCacheStats を使用すると、集計段階でキャッシュ情報をよりよく理解できます。 これは、プラン キャッシュのサイズ制限が 0.5 GB のみであることも意味します。これは、以前のバージョンと同じサイズ制限です。
Nosql データ ストア
データをテーブルに保存する代わりに、NoSQL データベースはデータをドキュメントに保存します。 その結果、それらを「SQL だけではない」とラベル付けし、さまざまな方法を使用して柔軟なデータ モデルとして分類できます。 NoSQL データベースは、純粋なドキュメント データベース、キー値ストア、幅の広い列のデータベース、およびグラフ データベースの 4 つのタイプに分類されます。
Redis データ ストアは、IBM が開発したオープン ソースのインメモリ キーと値のペア ストアです。 キャッシュ、キューイング、およびキューイングに加えて、セッション データを保存して高速アクセスするために使用でき、従来のデータベースよりも安価です。 NoSQL データベースは、リレーショナル データベースの代わりとしてではなく、拡張として頻繁に使用されます。 基礎となる永続タイプには、リレーショナル データベースに格納されているものとは異なる一連の特性があります。 Python コードを使用して構築された PyMongo を使用すると、共通のインターフェイスを使用して 1 つ以上の MongoDB インスタンスと対話できます。 PyMongoEngine を中心に構築された Python ORM は、MongoDB 用に特別に設計されています。 グラフ データベースの目的は、NoSQL データ ストアの包括的な概要を提供し、それらを他のタイプのデータ ストアと比較することです。 以下は、NoSQL とその用途の簡単な説明、および一貫性、可用性、およびパーティション耐性 (CAP) の定理の説明です。 セッション データは、永続的なストレージを備えた従来のデータベースに格納するよりも高速にメモリに格納できます。
NoSQL データベースには、簡単なスケーリング、高可用性、およびデータ アクセスの低レイテンシーという特徴があります。 データベース アプリケーションは、従来のデータベースよりも多くのデータ タイプを処理するように設計されています。 単純化されたモデルを使用してデータストレージを簡素化し、より高速で効率的な処理を可能にします。 さらに、それらは大規模なデータ分析に適しています。 NoSQL データベースには、従来のデータベースよりも多くの利点があります。 それらを使用する利点は、スケーリングが可能で、高レベルの可用性を提供し、データ アクセスの低レベルの待機時間を提供できることです。
Nosql データベースが主流になっている理由
NoSQL データベースを使用することには、従来のリレーショナル データベースよりも多くの利点があり、ますます普及しています。 オブジェクト指向プログラミング手法のより効率的な使用を可能にする ObjectStore 設計が、この主な理由の 1 つです。 NoSQL データベースは、スケーラビリティに加えて、他にもさまざまな利点を提供します。 データは大容量で短時間で扱えるので扱いやすい。 信頼性が高くスケーラブルなドキュメント データベースを探している企業にとって、MongoDB は優れた選択肢です。 さらに、無料で使用でき、あらゆる規模の企業に人気があります。
Mongodb テキスト インデックス
MongoDB のテキスト インデックスは、トークン化、ステミング、言語固有のストップワードなど、言語固有のテキスト処理をサポートしています。 これらは、言語ベースのテキストを含む任意のフィールドで使用できます。
MongoDB でのテキスト インデックスの作成は、 createIndex() メソッドを使用するのと同じくらい簡単です。 テキスト インデックスの主な機能は、テキスト内の文字列または要素の配列内の任意の要素を識別することです。 複合索引には、テキスト索引キーに加えて、昇順索引キーと降順索引キーの両方が含まれます。 この場合、タイトル フィールドにテキスト インデックスを作成して、studentspost コレクション内を検索してみましょう。 MongoDB は、ドキュメント内の各インデックス フィールドの結果を、その重みに一致の総数を掛けて合計します。 インデックス フィールドのデフォルトの重みは 1 であるため、createIndex() メソッドを使用して変更できます。 ワイルドカード指定子 ($**) を使用して、複数のテキスト インデックスを作成できます。