
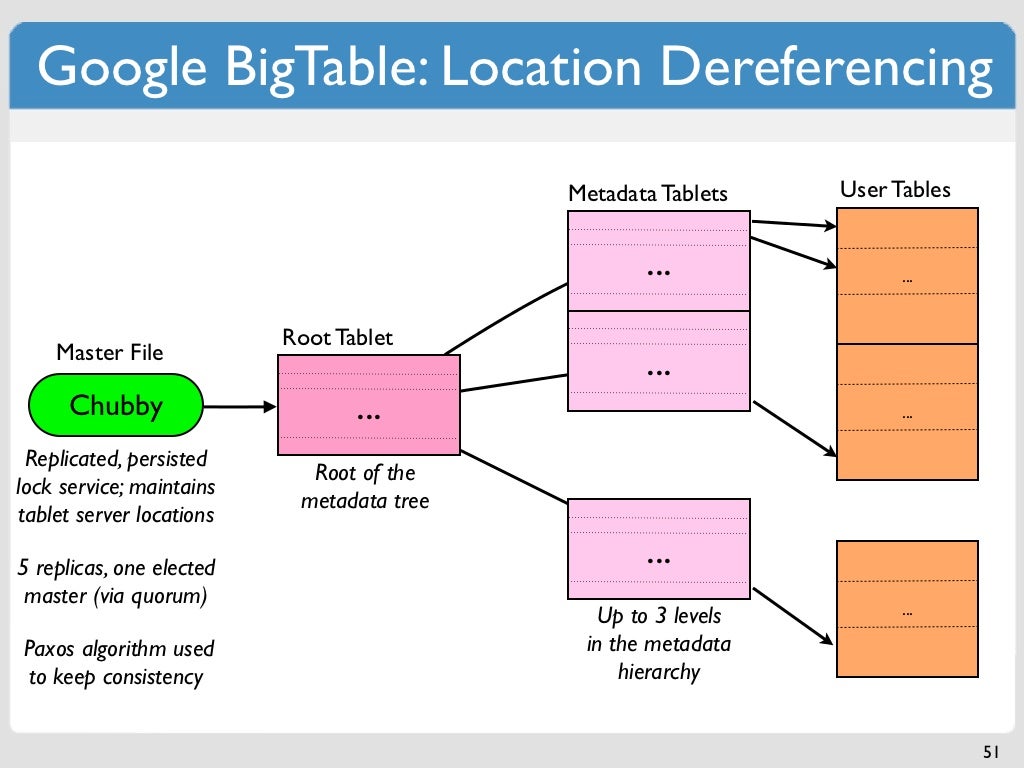
Google の Bigtable: 最も広く使用されている列指向のデータ ストア
公開: 2022-12-19Bigtable は、Google によって作成された列指向のデータ ストアです。 高度な柔軟性で大量のデータを処理するように設計されています。 Bigtable は Google で 10 年以上使用されており、Gmail、Google マップ、YouTube などの多くのサービスの基盤となっています。 Bigtable は最初の列指向のデータ ストアではありませんが、最も広く使用され、よく知られていることは確かです。
この記事では、Bigtable によって開発された 3 次元の NoSQL ストレージ モデルについて検討します。 正しく構造化されていることを確認するために、まず理論的にどのように実装されているかを見てから、Node.js クライアントを使用して実装します。 Bigtable のストレージ モデルは、同様のデータベースで見られる方法とは異なります。 行/列の組み合わせの複数のセルは、セルごとのタイムスタンプで並べ替えることができます。 セルを任意の順序で保存する代わりに、各セルには値とタイムスタンプがあり、セルが順序付けられた順序で保存されるようにします。 この例では、Node.js とプレーンな JavaScript を使用して Google Cloud Bigtable を構築します。 この記事では、コードを使用して新しい Bigtable インスタンスを作成する方法について説明します。
きれいな環境を作ることから始めて、そこで読み書きし、そして解体します。 Node.js Bigtable クライアントを使用してコードを実行すると、Node.js Bigtable クライアントによって Permission Denied エラーが発生し、Cloud Bigtable Admin API を有効にするためのリンクが生成される場合があります。 また、Bigtable 管理者ロールを処理するために、GCP プロジェクトで別のサービス アカウントを確立する必要があります。 Bigtable テーブルを作成するには、まずデータベースのインスタンスとテーブルのクラスターを構築する必要があります。 これを行うには、Node.js クライアントでテーブル ID と列ファミリーを定義するだけです。 データベースで Bigtable を使用すると、単純な行を作成できます。 データをクエリする唯一の方法は、行キーを使用して特定の行または行のグループをクエリすることです。
取り込み時間は、バージョンが保存される順序には影響しませんが、保存方法には影響します。 行キー全体を提供する必要はありません。 接頭辞だけで十分です。 Bigtable から複数の行をクエリする必要がある場合は、常にストリーミングを使用することをお勧めします。 ストリーミングを使用する場合、Bigtable は行を送信する前にデータをサーバーにバッファリングする必要がないため、パフォーマンスが向上します。 フィルターを使用してセルのバージョンを制限し、特定のファミリ名を持つ列または特定の修飾基準を持つ列のみを返すことができます。 これは、保持するバージョンが多数ある場合に特に便利ですが、特定の目的のために最新のバージョンのみが必要です。 フィルターは主に、照会されて送信されるデータの量を減らし、照会のパフォーマンスを向上させるために使用されます。
つまり、Cloud Bigtable は、分析と運用のワークロード用に設計されたNoSQL データベースです。 このデータベース システムは、カラムナ データベースを使用する HBase ではなく、Hadoop を使用するクロスプラットフォーム ハイブリッドです。 クラウド Bigtable を使用して、10 MB 未満の容量で高いスループットとスケーラビリティを備えたアプリケーションを強化できます。
Apache Cassandra、ScyllaDB、Apache HBase、Google BigTable、および Microsoft Azure CosmosDB は、ワイド カラム ストアの例です。
テーブルは、キー/値のストレージに関してリレーショナル データベースと同じではありません。 トランザクションは一度しか実行できず、結合はサポートされていません。
Google Bigtable は Nosql データベースですか?
Google Bigtable は、大量のデータを保存および管理するために設計された NoSQL データベースです。 Bigtable は列指向のデータベースです。つまり、データは行ではなく列に編成されます。 これにより、Web ログやソーシャル メディア データなど、常に変化するデータの保存に適しています。 Bigtable はスケーラビリティも高いため、大量のデータを簡単に処理できます。
この NoSQL データベースは、幅広いデータ タイプを格納でき、非常に安定しています。 また、シャーディングとレプリケーションの両方を処理し、データベースの可用性と信頼性を高めます。 Google アナリティクス、ウェブ インデックス作成、MapReduce、Google マップ、Google ブックス、検索履歴、Google Earth、Blogger.com、Google Code Hosting、Google など、多くの Google アプリケーションがこれを使用しています。データ アイテムの数、Datastore は最適な選択です。
データは Bigtable にどのような順序で保存されますか?
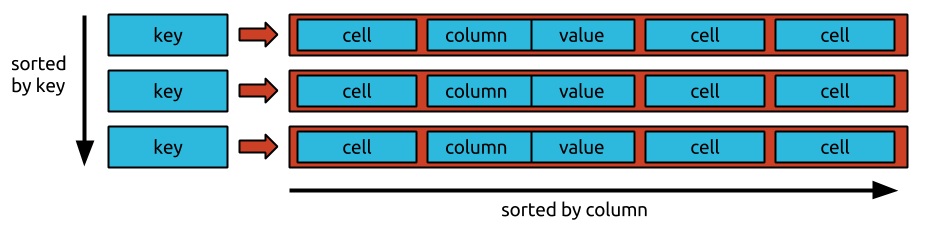
データが bigtable に格納される特定の順序はありません。 データはランダムな順序で保存されるため、特定のデータにアクセスすることは困難です。
Google の Bigtable: データを保存するためだけではありません
igtable 内でデータを特定の順序で配置することはできません。 Bigtable は行指向のデータベースであるため、行内のすべてのデータは列で編成され、その後に列が続きます。 データは新しい順に保存されるため、最新の値を要求するのは簡単で迅速ですが、最も古い値を要求するのは難しく、時間がかかります。
データは、Bigtable が Colossus を使用した結果、Google のデータ センター内に格納されている、Google の内部の長期にわたるファイル システムである Colossus に保存されます。 Bigtable は無料で使用でき、HDFS クラスタやその他のファイル システムを使用する必要はありません。
外部データ ソースへのクエリは、combine コマンドを使用して永続的なテーブルを作成せずに実行できます。クエリを含むテーブル定義ファイル。 インライン スキーマ定義とクエリがあります。 クエリを含む JSON スキーマ定義ファイル。
Bigtable とデータストア
Bigtable と Datastore にはいくつかの重要な違いがあります。 まず、Bigtable は列指向のデータ ストアですが、Datastore は行指向です。 これは、Bigtable ではデータが列に編成されるのに対し、Datastore では行に編成されることを意味します。 次に、Bigtable にはトランザクションの概念がありませんが、Datastore にはあります。 つまり、Bigtable では変更を以前の状態にロールバックできませんが、Datastore ではロールバックできます。 最後に、Bigtable は高スループットと低レイテンシ向けに設計されており、Datastore は高可用性とスケーラビリティ向けに設計されています。
Google クラウド データベースの構築に使用できるクラウド データ ストアはどれですか? Bigtable は複雑なバックエンド ワークロードを含む大規模なワークロードをサポートするため、大規模な組織や企業向けです。 より制限的なクエリ言語 GQL を使用する SQL とは対照的に、データストアは、エンティティ グループと呼ばれるデータのサブセットに対して ACID トランザクションを実行します (ただし、クエリ言語 GQL ははるかに制限がありません)。 Google Cloud Datastore と Google Cloud Bigtable は、多数の異なる機能を持つ 2 つの異なるサービスです。 さらに、下の画像の情報は、適切なサービス プロバイダーを選択するのに役立ちます。 上記の回答と、Coursea Google Cloud Platform Big Data and Machine Learning Fundamentals テキストブックで説明されている内容は、この記事のガイドとして役立ちます。
Bigtable とデータストアの違いは何ですか?
データストアとデータベースの違いは何ですか? bigtable とデータストアはどちらも、それぞれ大量のデータ処理と分析用に設計されており、データストアは高価値のトランザクション データ用に設計されています。 Datastore は、従来の SQL 標準に準拠していないため、NoSQL データベースとも呼ばれ、より柔軟でスケーラブルな方法でデータを保持できます。 Google Bigtable とはどのようなデータストアですか? Bigtable ストレージ モデルは、データを非常にスケーラブルなテーブルに格納し、キー マップと値マップで並べ替えます。 テーブルは、それぞれが 1 つのエンティティを表す行と、それぞれ独自の値を持つ列で構成されます。 データストアは非推奨ですか? Cloud Datastore API v1beta3 がリリースされたため、利用できなくなりました。 それにもかかわらず、Cloud Datastore 製品は完全に機能し、サポートされています。
Bigtable データベース
Bigtable は、構造化データを管理するための分散ストレージ システムであり、非常に大きなサイズ (数千のコモディティ サーバー全体でペタバイトのデータ) にスケーリングするように設計されています。 Bigtable は列指向のデータベースです。つまり、データは行単位ではなく列単位で保存されます。
テーブルは、数十億行に達する可能性のある行と列を含む疎で密集した構造です。 Bigtable は、低レイテンシで大量のデータを格納するための優れた選択肢です。 低レイテンシで高い読み取りおよび書き込みスループットをサポートするため、MapReduce 操作に適したデータ ソースです。 Bigtable テーブルを使用する場合、クエリを容易にするために、テーブルはタブレットと呼ばれる連続した行のブロックに分割されます。 Google が使用する Colossus と呼ばれるファイル システムでは、タブレットは SSTable 形式で保存されます。 Bigtable ノードは、Bigtable インスタンスの一部である各タブレットのサブセットです。 クラスターにノードを追加すると、処理できる同時要求の数を増やすことができます。

行には、列ファミリー、列タイムスタンプ、およびキーの組み合わせである一連のキーまたは値エントリが含まれます。 Bigtable はすべてのデータを同じように扱います。つまり、未加工のバイト文字列として扱います。 Bigtable はミューテーションをシーケンシャルに保存し、定期的に圧縮するため、一度に保存できるミューテーションの数によって、より多くのストレージ スペースが必要になります。 Bigtable は、自動化された高度なアルゴリズムを使用してデータを圧縮します。 削除は実際には新しいタイプの突然変異であるため、短期間でより多くのストレージ容量が必要になります。 Google 独自のストレージ方式により、標準の HDFS 3 方向レプリケーションを超えるデータ耐久性を実現できます。 Bigtable テーブルへのアクセスを管理するだけでなく、Google Cloud プロジェクトの Identity and Access Management (IAM) セクションでユーザーにロールを割り当てることで、他の Google Cloud サービスへのアクセスを管理できます。 Google Cloud のデフォルトの暗号化ポリシーに従って、クラウド内のすべてのデータは、暗号化されたデータに使用するのと同じ強化された鍵管理システムを使用して保存時に暗号化されます。 バックアップを使用すると、テーブルのスキーマとデータのコピーを保存し、後でそのデータのコピーを新しいテーブルに復元できます。
Bigtable 対 Cassandra
Cassandra と Bigtable は、異なる方法を使用して、読み取り操作と書き込み操作を実行する処理ノードを決定します。 Cassandra ではパーティション キーをキーと呼びますが、Bigtable では行キーをキーと呼びます。 Cassandra の負荷分散ポリシーは、プロセスの一部としてクライアントが確認する必要があります。
分散データベースは、複数の人によって共有されるデータベースです。 この会社は、システムに多次元キー値ストアを組み込み、1 秒あたり数万のクエリ (QPS) を処理できるようにしています。 このドキュメントの目的は、2 つのデータベース システムを比較対照することです。 Bigtable の主な機能は次のとおりです。 構造化データ用の分散ストレージ システム ペーパーが作成されました。 データセットに範囲の再調整が必要であると Bigtable が判断した場合、ストレージ レイヤーは処理レイヤーから分離されているため、処理ノードはデータ範囲を簡単に変更できます。 Bigtable を使用して、トポロジ内の最大 4 つのクラスタからなる地理的に分散したクラスタ全体で非同期レプリケーションをサポートすることもできます。 Cassandra のフォールト トレランスは、調整可能な一貫性のレベルに関連しています。
データ レプリケーション トポロジ戦略を構成することにより、地理的レプリケーションを定義できます。 一般に、QUORUM (データセンターによっては LOCAL_QUORUM) 設定が使用されます。 成功したと見なされるには、操作の一貫性レベルの設定が、コーディネーター ノードに応答するレプリカ ノードの過半数に一致する必要があります。 Cassandra のレプリカは、データ センターとラックの構成を使用することで、従来のレプリカよりも多くのストレスに耐えることができます。 読み取り操作と書き込み操作を実行する場合、トポロジーによって、一貫性を保証するために必要なノードが決定されます。 Bigtable インスタンスには、単一のクラスタ、または最大 4 つの大きなレプリカのグループを含めることができます。 Bigtable と Cassandra は、幅の広い列ストアであるNoSQL データ ストアです。
Bigtable の行キーは、テーブル内のグローバル データを順番に並べ替えるために使用されます。 Bigtable のノードは、Bigtable のノード機能の一部として、タブレットとも呼ばれるキー範囲に対するノードの責任を自動的に調整します。 クライアントのBigtable サービスは、送信する列のデータ型を強制しません。 Bigtable では、テーブルの各列にファミリー ネームが割り当てられます。 多くの場合、テーブルにはより多くの列ファミリーがありますが (テーブルごとの列の最大数は 100 です)、各テーブルには少なくとも 1 つの列ファミリーが必要です。 行キーの共通部分は、2 つのセル (列修飾子と結合された列ファミリー) で構成されます。 Cassandra と Bigtable には、読み取り操作と書き込み操作の処理ノードを選択する方法があります。
Cassandra ではパーティション キーが識別されますが、Bigtable では行キーが使用されます。 マルチクラスタ ポリシーなど、データ センターを認識する負荷分散ポリシーは、フェイルオーバーの可能性を提供します。 どちらのデータベースも同様の方法で書き込みを終了し、速度が最適化されています。 データは、不変の SSTable ファイルを介して 2 つのデータベースに格納されます。 Cassandra では、コーディネーターは、いくつかのレプリカが応答する前に、書き込みが完了したことをクライアントに通知する必要があります。 各行キーは 1 つのノードにのみ割り当てられるため、Bigtable への書き込みの成功は、1 つのノードからの応答によってのみ確認できます。 どちらのデータベースのセルも、マージされた SSTable に含まれない場合があります。
CQL クエリの WHERE 句のため、Cassandra で複数の行を返すことはできません。 Bigtable で参照する必要があるのは、キー範囲を担当するノードだけです。 処理ノードでは、読み取ることができるデータの量を制限することができます。 圧縮フェーズでは、SSTable が定期的にマージされ、Bigtable と Cassandra に格納されているデータが格納されます。 各セルのタイムスタンプ バージョンの数を管理する規則はありませんが、他の行サイズの制限がある場合があります。 Colossus のレプリケーション システムによって、データの耐久性が保証されます。 Bigtable は、Cassandra と同様に、多くの一般的なプログラミング言語用のコマンドライン インターフェースとクライアント ライブラリを備えています。
各ノードには Bigtable の SSTable が割り当てられ、格納されているデータはそのノードによって処理されます。 Cassandra クラスタのサイジングを行う場合、Bigtable の場合のようにストレージ レプリカを考慮する必要はありません。 ソリッド ステート ドライブ(SSD)またはハードディスク ドライブ(HDD)は、 Bigtable インスタンスで最も一般的に使用されるストレージ タイプです。 Cassandra で実証されているように、フォールト トレランスを実現するためにストレージ密度が低下することはありません。 ワークロードの要件を満たすように Bigtable インスタンスをスケーリングして、労力とダウンタイムを最小限に抑えることができます。 クラスターは 4 つしかありませんが、各クラスターは世界中のサポートされている任意のクラウド リージョンに作成できます。 Google では、代表的なデータとクエリを使用して Bigtable のパフォーマンスをテストし、ノードごとの QPS メトリクスを生成することをお勧めします。
Cassandra は、Bigtable マネージド コンポーネントを使用して多数の管理機能を実行します。 largetable のバックアップでは、テーブルの復元可能なコピーが作成され、クラスター内にオブジェクトとして格納されます。 バックアップは、ノード リソースの消費が少なく、クラウド ストレージよりも安価です。 Bigtable をバックアップするもう 1 つの方法は、Cloud Storage へのマネージド データ エクスポートを使用することです。 OS のパッチ適用、ノードの復旧、ノードの修復、ストレージ圧縮の監視、SSL 証明書のローテーションなどの内部メンテナンス タスクはすべて、Bigtable サービスによってシームレスに処理されます。 Bigtable の Google Cloud コンソール ページで、インスタンス、クラスタ、テーブル レベルでスループットと使用率の指標をモニタリングするためのダッシュボードを利用できます。 監視ダッシュボードを使用して、高度なパフォーマンス チューニングを実行できます。
Bigtable の論文では、大規模なスケールアウトをサポートするデータ ストレージ システムについて説明しています。 データ内の各テーブルは、いくつかのパーティションに分割されます。 行キーまたは行キーの範囲を使用して、テーブルをクエリできます。 Bigtable の論文では、テーブルの作業をノードのクラスタ全体に分散する方法についても説明しています。 オープン ソース データベースである Apache Cassandra は、Bigtable ペーパーのいくつかの概念に基づいています。 データセンターは、データを提供するサーバー間でストレージが共有される分散ノード アーキテクチャを使用します。 Bigtable のデータ ストレージ システムへのアクセスは、cbt コマンドライン インターフェースとクライアント ライブラリを使用して提供されます。 Bigtable には、Python に加えて多数のプログラミング言語が含まれているため、アプリケーションとの統合が簡単になります。
Google の Datastax Astra Cassandra As A Service: デプロイとスケーリングが簡単
Google の DataStax Astra Cassandra as a Service は、Cassandra について学習するための優れた選択肢です。 Kubernetes Operator のユーザー インターフェイスにより、Cassandra デプロイメントの構成、管理、スケーリングが簡単になります。
Bigtable ドキュメント
Bigtable のドキュメントは、この強力なツールについて学習するための優れたリソースです。 Bigtable の機能の概要と、その使用方法に関する詳細情報を提供します。 ドキュメントはよく整理されており、簡単に理解できるため、この強力なツールについて知りたい人にとって貴重なリソースとなっています。
Google Cloud Platform は、Google のBigtable データベースをホストしています。 Google のバックエンドと組み合わせて使用すると、OpenTSDB 2.1 以降を簡単に使用できます。 Bigtable インスタンスを作成し、Bigtable HBase シェルを使用して TSDB テーブルをセットアップし、TSD を開始するだけです。 Bigtable のクライアントは現在ベータ版であり、さまざまな変更が行われています。
Bigtable の効率的なデータ レイアウト
Bigtable は、MapReduce 操作にも適しています。 その効率的なデータ レイアウトにより、MapReduce は短時間で大量のデータを処理できます。