
ペイウォールをバイパスする方法 (記事、ブログなど)
公開: 2022-02-09- ペイウォールとは何ですか?
- 検索エンジンはどのようにしてペイウォール コンテンツにアクセスしますか?
- ペイウォール コンテンツに対する Google のスタンス
- GDPR により EU でブロックされました
- ペイウォールを回避する方法
- 12フィートのはしご
- ペイウォールをバイパスする
- 記録
- プライバシーモード
- インコゴ
- ペイウォールをバイパスすることは倫理的ですか?
「最新の」Web で最も厄介なことの 1 つは、ペイウォールです。 ますます多くのパブリッシャーが、コンテンツをプレミアム サブスクリプションまたはメール サインアップ フォームの背後にロックすることを選択しています。 この記事では、ペイウォールが存在する理由と、ペイウォールを回避する方法について説明します。
プレミアム コンテンツへの支払いを避ける行為を容認しないことを明確にしたいと思います。 パブリッシャーはその仕事に対して報われるべきであり、私はそれを尊重します。 しかし、問題を引き起こしているのは、ニューヨーク タイムズなどの大手出版社だけではありません。
Medium の多くのブログは、ユーザーにメールアドレスの共有を強制する境界線上の怪しげな戦術を行っています。 そして、私はその方法を説明するために最善を尽くします。 もう 1 つの問題は、サイトが GDPR 規制のために EU 地域全体からのアクセスをブロックする場合です。 それについてはすぐに。
技術的な部分をスキップしたい場合は、ここをクリックしてツール セクションに直接ジャンプしてください。
ペイウォールとは何ですか?
最も基本的な用語では、ペイウォールは、対価を支払うことを意図した Web サイトのコンテンツを保護するために使用されます。 費用は、金銭(サブスクリプション)またはニュースレターの成長に役立つメールアドレスのいずれかです.
ペイウォールを使用する理由は非常に単純です。広告ブロッカーがパブリッシャーの収益源を妨げているからです。 そして、これは10年以上前から起こっています。
Google は 2017 年に、 「[…] 6 億を超えるデバイスが広告ブロッカーを使用している」と報告しました。 それ以来、この数は指数関数的に増加したと仮定するのは公正です。

あなたが大手パブリッシャーであり、広告収入に依存している場合、サブスクリプション モデルに移行することは理にかなっています。 ただし、このトピックに対する私の角度は、検索エンジンに関連しています。
具体的には、パブリッシャーが Google などの検索エンジンにコンテンツのクロールとインデックス登録を許可し、検索者には読み取らせない方法です。
検索エンジンはどのようにしてペイウォール コンテンツにアクセスしますか?
では、何が起こったのか、そもそもなぜこの記事を書いたのかを説明しましょう。 オープンソースの分析記事の調査を行う際、広告ブロッカーが分析レポートに与える影響を知りたいと思いました。
特に、広告ブロッカーが Google アナリティクスなどのツールのレポートに与える影響。
これに対する私の検索クエリは、 「広告ブロッカー 分析追跡」でした。
そして、これがGoogleの検索結果です。
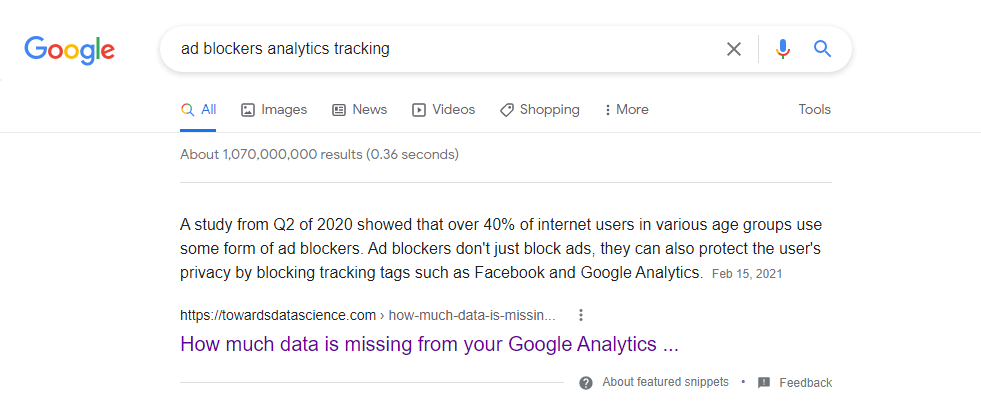
最初の結果はTowards Data Scienceからのもので、注目のスニペットです。 これらのスニペットは、特定の質問に対する迅速な回答を提供する Google の方法です。 そして、権限を暗示するために検索結果ページの上部に貼り付けられます。
それにもかかわらず、答えは非常に簡単ですが、もっと知りたいと思いました. というわけで、記事のリンクをクリックしてみました。 そして、これは私が迎えられたページです:

私の最初の考え? これは地獄のように迷惑です。 私の考え直し? Google はこの記事をどのように見て、検索結果で宣伝しましたか?
もちろん無知でいたいわけではありません。 Medium では 1 か月に読める記事の数が制限されていることは知っています。 ただし、読んだ数を追跡することは現実的ではありません。 特に、Medium ブログにカスタム ドメイン名を使用できることを考慮してください。
この場合、Towards Data Science はそのコンテンツを Medium で公開しています。 また、Medium は、クリエイターがプラットフォームで公開することで収益を得る方法を提供します。 これは、個人的な信頼の問題というよりも、ビジネス上の関係です。 しかし、ここに私の不満があります。
このコンテンツが繁栄するためには、検索エンジンのトラフィックに大きく依存しています.
そのため、Google クローラーには、ページ全体のコンテンツを表示するだけでなく、検索結果にインデックスを作成するためのフリー パスが与えられます。 そして、上で見たように、これらの検索結果は信頼できるステータスに昇格できます。 正直なところ、これは意味がありません。
ペイウォール コンテンツに対する Google のスタンス

Google は、スキーマ マークアップを使用してペイウォール コンテンツを構造化する方法について、公式のガイドラインを作成しました。 ここで公式ドキュメントを見ることができます。
要約すれば:
- Google はコンテンツのクローキングを許可していません。
- ペイウォール コンテンツは、ペイウォールの背後に隠されている正確なセクションまでマークアップする必要があります。
Google がこれらの規則をどの程度積極的に実施しているかは不明です。

Towards Data Science でデューデリジェンスを行いました。その特定のページで使用しているコードは次のとおりです。
mainEntityOfPage: https://towardsdatascience.com/how-much-data-is-missing-from-your-google-analytics-dashboard-20506b26e6d isAccessibleForFree: False cssSelector: .meteredContentここでわかるように、 isAccessibleForFreeはFalseに設定され、CSS セレクターは.meteredContent に設定されています。 これは、Medium がペイウォール コンテンツの構造に関する Google のガイドラインに従っていることを示しています。
「.meteredContent」セレクターとは何ですか?
このセレクターは、Google などの検索エンジンに、ユーザーが読める無料記事の数に制限があることを伝えるために使用されます。 Mediumの場合、月3本まで無料です。
確かに、Medium 側の本当の不正行為を探している間、私は手ぶらで戻ってきました。 論理的には、Google がすべての記事を閲覧できるというのは理にかなっていないと思いますが、実際の読者は登録を余儀なくされる前に 3 つの記事しか読むことができません。 Google はこの種の行為を喜んで許可しているようで、私が言えることは他にあまりありません。
Google は、アクセシビリティよりもコンテンツの質に関心があると公言しています。 同社は当初、初回訪問者に少なくとも 3 つの無料記事を許可するよう出版社に指示するガイドラインを公開しました。 これは、Medium で見たものにも当てはまります。 しかし、近年、Google は構造化マークアップに移行しています。 詳細については、Google 自身の記事「検索アルゴリズムの仕組み」を参照してください。
GDPR により EU でブロックされました
場合によっては、アクセスを完全にブロックする Web サイトに出くわすことがあります。 これは、EU の読者のアクセスをブロックしている米国を拠点とするパブリッシャーに大きく関係しています。 これの単純な理由は、ヨーロッパのプライバシー規制である GDPR です。

上の画像は、手元の Web サイトが EU の訪問者を「気にかけている」ことを暗示していますが、実際にはそうではないことは明らかです。 パブリッシャーがこれを行う理由は、ユーザーに関するデータを収集する複雑な広告手法のためです。 また、特定の地域で追跡するデータを制限するのではなく、アクセスを完全にブロックすることを選択する人もいます.
ペイウォールを回避する方法
さて、ペイウォールの背後にあるすべてのドラマと理由を見てみましょう. 代わりに、ペイウォールをすばやく回避するために使用できるツールをいくつか見ていきましょう。
12フィートのはしご
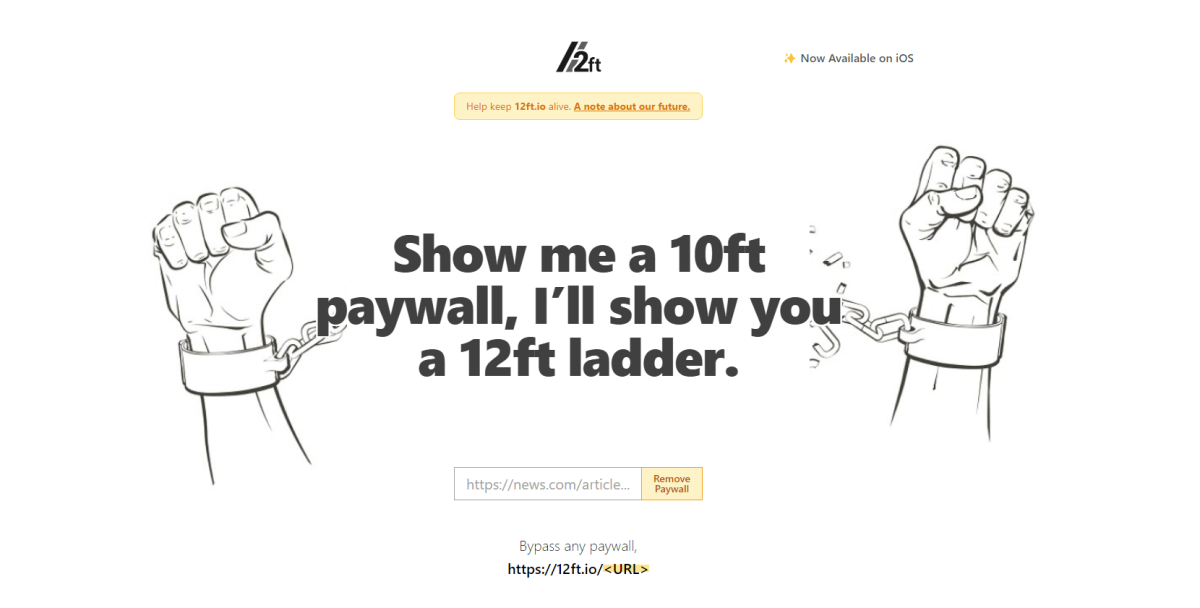
ペイウォールを突破する最も簡単な方法は、12ft Ladder Web サイトを使用することです。 ペイウォールにリンクする URL を入力するだけで、後は 12ft が行います。
https://12ft.io/[link to the paywalled website]それがどのように機能するかについては、非常に簡単です。 ニュース サイト、出版社、およびその他のコンテンツ プロバイダは、ペイウォールを使用していますが、Google クローラーがそれらのページを表示できるようにしています。 このコンテキストでは、12ft は単に Google キャッシュ機能を使用してページ全体を表示します。
私の知る限り、12ft は The New York Times のバイパスをサポートしていません。
ペイウォールをバイパスする

Bypass Paywalls ブラウザー拡張機能は、GitHub でホストされているオープンソース プロジェクトです。 この特定の拡張機能を使用するには、自分でインストールする必要があります。 Google Chrome マーケットプレイスまたは Mozilla のいずれからもダウンロードできないためです。
拡張機能自体は、Chrome、Firefox、および Edge ブラウザーで使用できます。 最後になりましたが、プロジェクトには GitHub で 20,000 を超えるスターがあります。 そのため、実績があり、信頼性も高いです。 この拡張機能でバイパスできるサイトの完全なリストは、プロジェクト ページ自体にあります。
記録
Archive Today プロジェクトは、他の多くのペイウォール バイパス ツールと同様に機能します。 ページが検索エンジンによって閲覧されたかのようにページをアーカイブし、表示しようとしているページの読み取り可能なバージョンを返します。
この方法は、ユーザーがペイウォール コンテンツの背後にある記事を投稿する Hacker News などのサイトでよく使用されます。 私が知る限り、NY Times、Financial Times、The Wall Street Journal などの多くのサイトで問題なく動作します。
プライバシーモード
場合によっては、Web サイトが Cookie データを保存して、ユーザーが読んだ無料記事の数を監視します。 制限に達すると、ペイウォールになります。 そして、それを回避する簡単な方法の 1 つは、シークレット モードを使用することです。 プライベート モードとも呼ばれます。
[設定] に移動し、新しい [プライベート ウィンドウ]を選択すると、最新のブラウザでシークレット モードにアクセスできます。 これにより、Cookie の履歴がない「白紙の状態」が得られます。つまり、Cookie ペイウォールの背後に隠されたコンテンツにアクセスできます。
インコゴ

Incoggo の背後にいる人々は、広告ブロッカー市場への参入を計画しています。 しかし、当面は、ペイウォールをスキップする無料の Mac ベースのソフトウェアを提供しています。 繰り返しになりますが、このソフトウェアは OSX ユーザーのみが利用できますが、Windows バージョンは間もなく登場するはずです。
最新のブログ ニュースを見ると、プロジェクトは活発に開発されているようです。 これは、ソフトウェアが必要なときに機能することを意味するため、朗報です。 Incoggo がスキップできる出版物やサイトについては、公式 Web サイトを確認してください。
ペイウォールをバイパスすることは倫理的ですか?
私たちは皆、さまざまなレベルの道徳的羅針盤で活動していると思います。 双方に多くの議論が必要です。 また、記事の冒頭で述べたように、パブリッシャーはプレミアム コンテンツのサブスクリプション料金を請求できるようにすべきだと思います。
私の唯一の問題は、このプロセスが恐喝になるときです。 言い換えれば、なぜ Google のような検索エンジンに権限を与えてから、他のすべてのユーザーを締め出すのでしょうか?
コンテンツにペイウォールを追加したパブリッシャーにリンクしている本物の無料記事を読んでいることは珍しくありません。
記事を 1 つだけ読むために、年間 50 ドルを支払う価値はありますか? 同じことが、かつては無料だった記事にも当てはまりますが、有料の壁にもかかわらず、まだリンクされています.
いずれにせよ、このガイドが少なくともいくつかの有用なポイントを提供してくれることを願っています.