
構造化データを NoSQL データベースに保存する方法
公開: 2022-11-17NoSQL データベースは非構造化データの保存によく使用されますが、構造化データの保存にも使用できます。 構造化データを NoSQL データベースに格納する方法はいくつかありますが、最も適切な方法は、特定のデータと目的の結果によって異なります。 構造化データを NoSQL データベースに格納する 1 つの方法は、ドキュメント指向のアプローチを使用することです。 これは、データがドキュメントに保存され、コレクションに編成されることを意味します。 構造化データを NoSQL データベースに格納するもう 1 つの方法は、キーと値のアプローチを使用することです。 これは、データがキー値ストアに格納され、各キーが値に対応することを意味します。 最後に、グラフ指向のアプローチを使用して、構造化データを NoSQL データベースに格納することもできます。 これは、ノードがデータを表し、エッジがデータ間の関係を表すグラフにデータが格納されることを意味します。
「非構造化データ」という用語には幅広い意味合いがあり、人によって意味が異なる可能性があります。 RDBMSは、すべてを定義することを期待しているため、事前に定義することを期待しています(特に、列名と型(このようなもの)でデータを管理することは困難です.ユーザーが最後にアクセスしたとき特定の国を訪問した頻度を知りたい場合. No. SQL データベースでは、セルの名前がテーブルの名前に対応するようにテーブルをモデル化することができます. BLOB は、 Oracle Database やその他のリレーショナル データベースを含む、任意の RDBMS に安全に格納されます。CLOB と BLOB の場合、キー値を指定できません。これらは半構造化されているため (JSON、XML、すべてのフィールドが不明)、区別されます。構造化されていない性質によって。
NoSQL データベースは、半構造化データの処理によく使用されます。 IIoT デバイスは、構造化データ、非構造化データ、および半構造化データをリアルタイムで生成します。 販売者が構造を定義すると、構造化データの管理と処理が簡単になります。
Hadoop は、企業の構造を支援し、さまざまなソースから生成された膨大な量のデータに隠されたパターンや傾向を理解するのに役立ちます。特に、大量のデータが存在する時代においてはそうです。 非構造化データに対する Hadoop の優れた機能を誇張することはできませんが、複雑な構造化データの問題を解決するためにも使用できます。
ビッグデータなど、膨大な量のさまざまな非構造化データを処理および分析するビジネスでは、NoSQL がより適切なオプションです。 NoSQL データベースには、格納できるデータに関するリレーショナル データベースと同じ制約はありません。
Mongodb は構造化データを保存できますか?

はい、MongoDB は構造化データを格納できます。 これは、BSON (Binary JSON) を使用してデータをバイナリ形式で保存することによって行われます。 BSON は JSON のスーパーセットであるため、すべての JSON ドキュメントをMongoDB データベースに格納できます。
たとえば、MongoDB は、さまざまな要因により、近年人気が高まっています。 データを構造化できず、柔軟な方法で保存する必要がある大規模なアプリケーションには、クラウド ストレージが適しています。 MongoDB は非構造化データベースに分類されるため、データ ストレージに対して異なるアプローチを採用しています。 JSON はさまざまな方法でフォーマットできるデータ型であるため、テキスト ファイルやその他の非構造化アセットはこの形式で保持されます。 MongoDB は、この目的のために構築されているため、大量のデータを処理するのに適しています。 MongoDB は物理的に処理できないため、大量のデータを簡単に処理できます。
Nosql はどのような種類のデータを保存しますか?
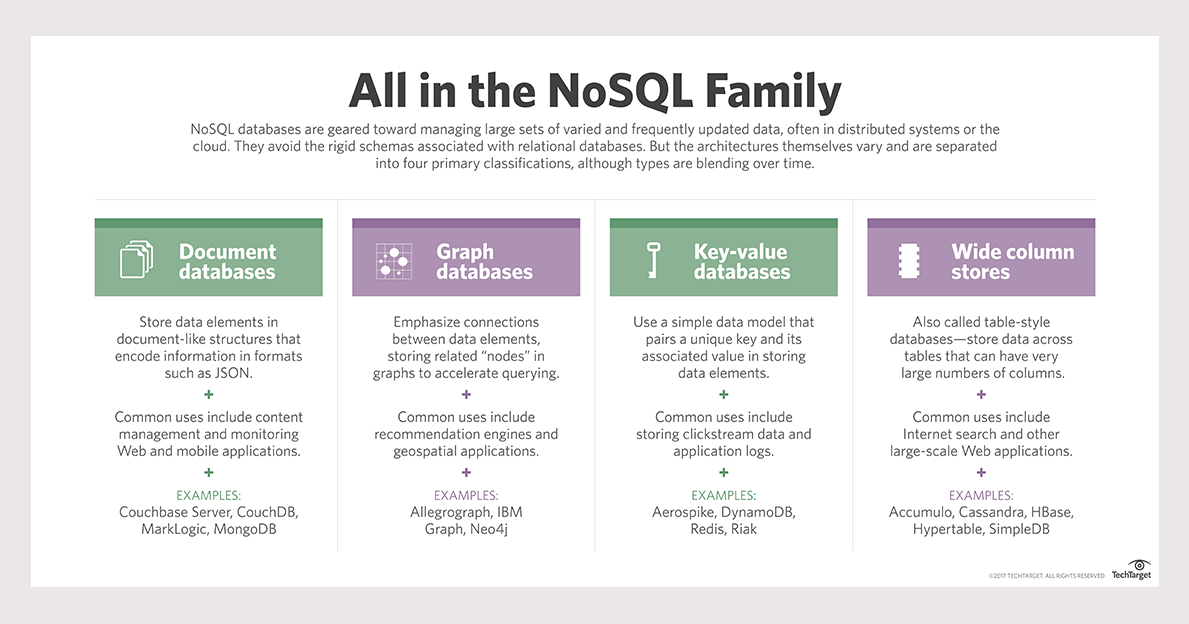
NoSQL データベースは、構造化されていないデータを格納するために使用されます。つまり、従来のテーブル形式にうまく適合しません。 これには、ソーシャル メディアの投稿、コメント、画像など、従来のデータベース構造に収まらないものが含まれます。 NoSQL データベースは柔軟性が高いため、大量のデータにすばやく簡単にアクセスする必要があるアプリケーションに適しています。
「非リレーショナル データベース」という用語は、固定構造を持たないデータベースを指します。 キー値ストア、列指向、ドキュメント ベース、グラフ、およびグラフ データベースは、最も一般的な種類のデータベースです。 NoSQL の世界では、キー値データベースは、使用する最も単純なタイプのデータベースの 1 つです。 データは、単純な一連の関数を使用して保存、収集、および削除されます。 キー値ストア データベースには、使用できるクエリ言語がありません。 データのタイプは、データを処理するアプリケーションの要件によって決まります。 キー値データベースの最も一般的な使用例は、ログインが必要なアプリケーションでセッションを記録することです。
より一般的な使用例に加えて、ショッピング カートを使用すると、e コマース Web サイトで各ユーザーのショッピング セッションに関するデータを保存できます。 ホリデー セールや特別なプロモーションが行われているときは、キー値ストアのスケーラビリティが役に立ちます。 さらに、システムには冗長性が組み込まれているため、カートのアイテムが失われることはありません。 Key-Value データベースは特定の目的を果たし、他のものに制限を課しながら、あるものに価値を追加する機能を含みます。
MongoDB プログラミング言語は人気があるだけでなく、非常に柔軟でもあります。 その結果、追加の負荷を処理するためにサーバーの数を拡張できます。 それに加えて、MongoDB のレプリケーション機能により、データが常に最新で複数の場所にあることが保証されます。 その結果、MongoDB は、データの信頼性と一貫性を維持したい大規模な組織にとって非常に魅力的なオプションです。

Nosql は非構造化データですか、それとも半構造化データですか?
非リレーショナル データベースは、構造化データと非構造化データを (構造化クエリ言語だけでなく) NoSQL で格納するために使用されます。 スケーラビリティが高く、検索が容易なため、NoSQL は非構造化データに最適です。
データは、スプレッドシート、テキスト、ビデオ、さらにはオーディオ ファイルなど、さまざまな形式で保存できます。 これは、ストレージに格納されるデータの一種であり、格納される前に事前定義された構造を持つことが期待されます。 非構造化データ セットは、事前定義されたデータ モデルがないため、リレーショナル データベースに格納できないデータ セットです。 非構造化データは、構造化されていないが、データの構造またはデータの階層を見つけるために使用できる何らかの形式のメタデータを含む非構造化データを指す用語です。 機械学習と人工知能のエンジニアと科学者は、機械学習や AI などの手法を使用してこの種のデータを分析し、意味 (または高レベルの構造) を抽出します。 これには、電子メールやその他のドキュメントが同様の形式で含まれていますが、形式に関係なく、ユーザーが特定のレベルで特定の情報にアクセスできるようにするメタデータが含まれています。 この記事では、さまざまな種類のデータの実際の例をいくつか取り上げ、それらが現代の組織でどのように使用されているかについても調べました。
通常、構造化データはデータベースに格納されます (後でデータ ウェアハウジングに使用されます)。 非構造化データは、非リレーショナル データベースまたはデータ レイクに格納されます。これは、データを分類するために従わなければならない定義済みのスキーマがないためです。 半構造化された階層ベースのデータの場合、MongoDB は適切なオプションです。
データベース NoSQL システムは、そのスケーラビリティと柔軟性により人気が高まっています。 このデータ保存方法は、半構造化データと非構造化データに加えて、非構造化データと半構造化データに最適です。 よりアジャイルな方法でデータを操作する方が簡単であるため、反復開発に最適です。
非構造化データ ストレージ
非構造化データ ストレージ システムは、格納するデータに構造を課さないファイル システムです。 データは単純にフラット ファイルとして保存され、ファイル システムによる構造はありません。 このタイプのストレージ システムは通常、特定の方法で編成する必要のないテキストまたはバイナリ データ (イメージなど) の格納に使用されます。
このカテゴリには、非構造化データの約 80% が含まれます。 非構造化データの量、種類、速度により、保存が困難になります。 従来、大量の非構造化データを処理するために構築されてきたストレージ システムは、将来的には処理できなくなる可能性があります。 その結果、データ ストレージ インフラストラクチャは、多数のトランザクションを処理できるだけでなく、スケーリングできる必要があります。 ビッグ データ プロジェクトを開発する場合、企業は事前に非構造化データの保存を計画することが重要です。 俊敏性、費用対効果、拡張性に優れ、幅広いユース ケースに合わせて調整されたストレージ インフラストラクチャを選択することが重要です。 Nosql (Norelational) データベースは、この情報を保存する優れた方法です。
MongoDB Atlas や、MongoDB as a Service (DaaS) などの他のクラウド データベースは優れたオプションです。 MongoDB データベースは、ドキュメントに基づいて BSON (json に似た) 形式でデータを格納します。 ドキュメントの属性は、そのデータのタイプによって異なります。 データがバックアップされ、複製できるため、ドキュメント ストアは非常にスケーラブルで、設計に利用できます。 MongoDB Atlas のサービスとしてのデータベース プラットフォームは、AWS、Azure、Google Cloud などの主要なクラウド プラットフォームを使用してデータベースを格納します。 データ ウェアハウスにアクセスする前に、非構造化データに対して抽出、変換、読み込みのステップ (ETL) を実行する必要があります。 データ ウェアハウスは、さまざまなソースからのデータを処理および保存して、分析の準備が整っていることを確認します。 データ レイクは、生データと処理済みデータを組み合わせたネイティブ形式ですべてのデータを保存します。
そのシンプルさ、軽量さ、および処理の容易さから、JSON は非構造化データの保存に最適です。 HDFS、Cassandra、MongoDB などのさまざまな形式に簡単に変換でき、これらはすべてこのアプリケーションでサポートされています。 データを結合する必要がないため、私たちのソリューションは簡単に実装できました。 json_archive 関数を使用すると、JSON オブジェクトごとに個別のファイルを作成できます。 リレーショナル データベースは、さまざまな方法で非構造化データを格納できます。 まず、リレーショナル データベースは、大量の非構造化データを格納およびクエリするための最も効率的な方法です。 それらは大量のデータの非常に効率的な圧縮を可能にし、多くの場合、クエリ言語、セマンティクス、および特定のデータ型に対応するその他のメカニズムが含まれています。 第 2 に、リレーショナル データベースの構造により、データ クエリが容易になります。 すべてのレコードは単一の JSON オブジェクトとしてリレーショナル データベースに保存され、そのデータはすべて 1 つとして保存されます。 特定のレコードを探している場合でも、レコードの完全なセットを探している場合でも、必要な情報を見つけることができます。 リレーショナル データベースの 3 つ目の利点は、大量のデータを処理できることです。 数千万のレコードを保存できることに加えて、複雑なクエリを処理できます。
非構造化データ: 何を、どこに、どのように保存するか
非構造化データは任意の形式で保存できますが、通常はテキストまたは非テキスト形式で保存されます。 一般に、非構造化データは事前定義された構造に収まらないため、より大きなストレージ容量が必要になります。 クラウド ストレージは、セキュリティと、どこからでもデータにアクセスできる機能を提供するため、非構造化データの優れたオプションとなります。 ファイル ストレージの使用は、大量のデータを保存して整理するのに適した方法です。 このソフトウェアは、パスベースのストレージに基づいています。つまり、フォルダーとディレクトリを使用してデータを保存します。 ファイル ストレージ システム内のどこにデータが存在するかを知ることが重要です。