
InfluxDB: 時系列データベース
公開: 2022-11-18InfluxDB は、Go で記述され、InfluxData によって開発された時系列データベースです。 高い書き込みパフォーマンスと高速なクエリに重点を置いて、スケーラブルになるように設計されています。 また、オープン ソースであり、コミュニティ バージョンとエンタープライズ バージョンがあります。 InfluxDB は、オープン ソースのデータ視覚化ツールである Grafana と組み合わせて使用されることがよくあります。 InfluxDB は、高い書き込みパフォーマンスと高速なクエリにより、時系列データの一般的な選択肢です。 また、オープンソースであるため、多くの開発者にとって魅力的です。
比較を行うために、実際の PeerSpot ユーザー レビューを使用して InfluxDB とOracle NoSQLを比較しました。 この記事では、NoSQL データベースの機能、価格、サービスとサポート、導入の容易さ、ROI を比較して、どちらがビジネスに適しているかを判断します。 2012 年以来、私たちの調査は 648,701 人の専門家によって使用されています。 クラウドベースのオファリングである InfluxDB には、time-seriesDB、高速な一括クエリ、およびウィンドウ操作という最高の機能があります。 InfluxDB のバルク API には、カーディナリティの高いデータと互換性のない問題がいくつかあります。 無料のレコメンデーション エンジンを使用して、お客様のニーズに最適な NoSQL データベースを判断してください。 InluxDB は、開発者や企業が時系列データを管理できるようにする無料のオープンソース ソフトウェア プログラムです。
InfluxDB を使用すると、モノのインターネット (IoT)、アプリケーション、システム、コンテナ、およびインフラストラクチャを監視および分析できます。 レビュアーは、最も重要な機能として、データの集約と Grafana との統合を挙げました。 Oracle NoSQL Databaseは、非常に大規模で可用性の高いデータベース システムとなることを目的としています。 完全な作成、読み取り、更新、および削除 (CRUD) 操作、およびさまざまな耐久性と一貫性の保証が利用可能です。 4 件のレビューで、InfluxDB は NoSQL データベース市場で 5 位にランクされ、1 件で 7 位にランクされた Oracle No SQL に続いています。 最も推奨されるデータベースとして、非常にシンプルなインターフェースを持ち、軽量で強力です。
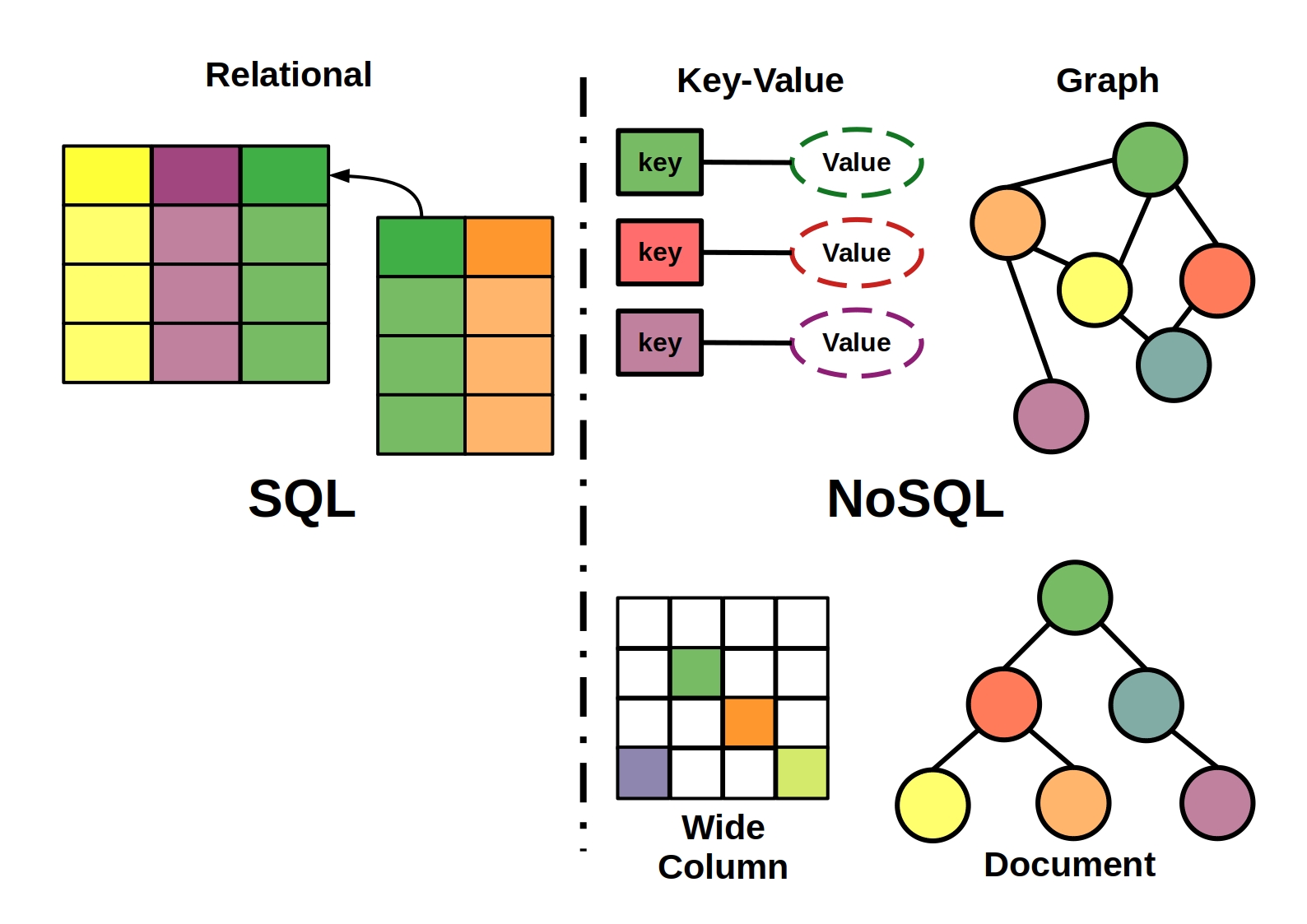
InfluxDB はリレーショナル データベースではありません。主キーや外部キー、測定値の結合などが含まれていないためです。 解決策としてのタグ: タグは理論的には回避策として使用されますが、カーディナリティの低いデータにのみ適しています。 一意の ID タグを持つレコードが多数ある場合、大量のメモリが必要になります。
influxDB データベースは SQL データベースに似ていますが、いくつかの違いがあります。 このデータベースは、時系列データを処理するために特別に設計されています。 リレーショナル データベースは時系列データを処理できるという事実にもかかわらず、一般的な時系列ワークロードに対して最適化されていません。
InfluxDB Cloud は、ユーザーがニーズに合わせて迅速に開始し、迅速に拡張できる、完全に管理された弾力性のある時系列データ プラットフォームです。
InfluxData によって作成された時系列データベース (TSDB) は、オープンソースのデータベースです。 Go でこのライブラリを使用すると、運用、アプリケーション メトリック、モノのインターネットセンサー データ、リアルタイム分析などの時系列データを保存および取得できます。
Graphql は SQL または Nosql ですか?
GraphQL では、型システムを使用して、型ベースのクエリ言語である動的クエリでデータを効率的に返します。 SQL (構造化照会言語) は、表形式および階層型データベースのデータ構造の設計、実装、および管理のために広く使用されている古い標準です。 API に NoSQL データベースを使用する場合は、GraphQL を使用してください。
Type Mismatch データベースと GraphQL データベースはどちらも、Cochrane と Herman Camarena によって作成されました。 NoSQL の利点を引き続き利用できるため、NoSQL システムではなく GraphQL を使用して型システムを導入できます。 GraphQL コレクションのドキュメント構造は、いくつかの例外を除いて、ドキュメントごとにわずかに異なります。 GraphQL API のおかげで、開発者はバックエンドのタイプにほぼ対応する必要なデータ タイプを選択できます。 GraphQL の可能性を最大限に引き出すには、型の不一致の問題に対処する必要があります。 言語として、それには多くの利点があり、ミスマッチの問題がそれほど深刻ではありません。 StepZen の JSON2SDL などのツールを使用すると、ジョブをさらに自動化できます。
Graphql はデータ ソースにとらわれない
変更が保存または取得されるデータ ソースに依存しません。 データは、リゾルバーと呼ばれる任意の関数を使用してアクセスおよび操作できます。
Influx は Sql ですか、それとも Nosql ですか?
InfluxDB は、InfluxData によって開発されたリレーショナル データベースです。 は、ビッグデータ、NoSQL、スケーラビリティを組み合わせた無料のオープンソース データベースです。 可用性が高く、書き込み速度が速く、オンデマンドで利用できます。 NoSQL データベースである InfluxDB は、一連の時系列データ ポイントに基づいて、時間の経過に伴う一連のデータ ポイントを格納します。
その目的は、時系列データに使用することです。 各データ系列には、その中の 1 つのポイントを識別するタイムスタンプがあります。 この場合、SQL データベースと同様に、データベース テーブルでは、主キーは常にシステムによって設定されます。 ほとんどの場合、測定値に新しいフィールドを追加するには、ポイントを書き込むだけです。 このセクションで言及されているinfluxDB 用語のより詳細な説明は、用語集に記載されています。 Flux で InfluxDB 1.8 を使用すると、その構文と概念の基本的な理解を得ることができます。 influxDB との対話には、SQL に似たクエリ言語である InfluxQL が使用されます。
SQL 環境は、他の環境から来た人が安心して使えるように設計されています。 このプログラムは、UNION、JOIN、HAVING などの高度な操作をサポートしていません。 サーバーの現在のタイムスタンプを相対時間と now() で使用して、相対時間を計算できます。 このクエリは、foodships データのリストを生成します。 CR-ud データベースは完全な CRUD データベースではなく、afluxDB に似たデータベースです。 データの更新と破棄よりも、データの生成と読み取りを優先するように設計されています。
InfluxDB と MySQL は、最も広く使用されている時系列データベースの 2 つです。 どちらのオープン ソース ツールも使いやすく、カスタマイズ可能です。 InfluxDB は他のどのデータベースよりもシンプルであるため、時系列データ分析に最適です。 InfluxDB には、MySQL よりも多くの利点があります。 MySQL は、InfluxDB よりもメモリ効率が高く、開発が高速です。 InfluxDB が MySQL よりも優れたツールである 2 つ目の理由は、より安定していることです。 さらに、InfluxDB は MySQL よりも優れた時系列分析のサポートを提供します。 時系列分析には、使いやすく、メモリ効率が高く、信頼できる InfluxDB が適しています。 Cisco、Power Home Remodeling、AT&T、Windstream Communications などの多くの企業が、すでに InfluxDB を使用しています。

Nosql および Sql データベースの長所と短所
SQL データベースは、ドキュメントや JSON などの非構造化データに対して、NoSQL データベースよりも優れた複数行トランザクション処理を提供します。 SQL データベースは、リレーショナル形式で記述されたレガシー システムでも使用されます。 InfluxDB のデータはシャード グループに格納されます。 データはシャード グループに保存され、シャード期間として履歴で定義され、保持ポリシー (RP) によって配置されるタイムスタンプと共に保存されます。 さらに、RPに応じて、シャードグループの持続時間を調整できます。 保持ポリシーの管理に移動して、シャード グループの期間を変更できます。 InfluxDB は、SQL データベースと比較して、その構造と操作の点で多くの違いがあります。 InfluxDB の目的は、履歴データを保存することです。 時系列データはリレーショナル データベースに格納できますが、これらのデータベースは定期的な時系列ワークロード用に最適化されていません。 InfluxDBQL クライアントは、データベース データの SQL クエリを有効にします。
Influxdb とはどのような種類のデータベースですか?
InfluxDB は、外部依存関係のないオープン ソースの時系列データベースです。 メトリック、イベントの監視、および分析の分析に役立ちます。
InflluxDB オープン ソース データベースは、時系列形式で記述され、InfluxData によって維持されます。 時系列データを保存および取得するように設計されたこのプラットフォームは、パフォーマンス メトリックと分析を監視および記録するために使用されます。 InfluxDB のデータベース アーキテクチャは、2 つのデータベースで構成されています。時系列データ用の時系列インデックス (TSI) と、測定、タグ、およびフィールド メタデータ用の逆インデックスです。 オープンソース データベースである InfluxDB は、データを列形式で格納します。 さらに、データ ストレージの列は、経時的なスキャンなどの一般的な時系列クエリをサポートできます。 Time-Structured Merge Tree (TSM) は、InfluxDB で使用される組織構造です。 FileStore は、コンピューター上のすべての TSM ファイルへのファイル アクセスを管理するためにも使用されます。
InfluxDB は、時系列の分析と監視に使用できる、強力で高速、かつ費用対効果の高いデータ ストレージ ソリューションです。 すべてのデータが一度に配信される列方向のデータ配信を使用するため、特定のデータ値を抽出するために行全体を読み取る必要がなくなります。 その結果、InfluxDB は、センサーやシステム データなど、頻繁に大量で高密度になるデータに役立つツールです。 InfluxDB は、ほとんどのデータベースと同様に、シャーディングとインデックス化を使用することにより、高い読み取りおよび書き込みスループットとカラム機能を提供します。 これは、定期的に保持および取得する必要があるセンサーまたはシステム ログからのデータを保存および取得できるため、便利な機能です。 InfluxDB は、時系列の分析と監視に適した強力で柔軟なデータ ストレージ ソリューションです。 この形式には、データを一度に 1 列ずつ配信する列配列、2 倍の速度の読み取りおよび書き込みスループット、高速な検索とスケーリングを可能にするインデックス機能が含まれます。 InfluxDB は、大量の時系列データや、迅速で効率的なデータ ストレージ ソリューションを必要とするものなど、幅広いストレージ要件に最適な選択肢です。
Influxdb 対 Mongodb
InfluxDB の結果は、データの取り込みとディスク ストレージのパフォーマンスに関して、MongoDB よりもはるかに優れていることを示しました。 データの取り込みに関しては、 InfluxDB はMongoDB よりも 4 倍優れています。 InfluxDB は、MongoDB とは対照的に、20 倍の圧縮を提供しました。
カウチベースを 4 年以上使用した後、MongoDB に切り替えましたが、これ以上ないほど満足しています。 企業のサポートを受けましたが、Couchbase パートナーとしてリストされていたにもかかわらず、その経験はひどいものでした. 適切に実行するには、最小要件で少なくとも 6 台のサーバーが必要です。 本番環境では 6 台のサーバーが必要になります。 インメモリ キャッシュを処理するために、小さい Memcached インスタンスが Couchbase インスタンスに同梱されています。 このプログラムには 8GB の RAM があり、5000 のドキュメントをサポートできます。 私はここで冗談を言っているわけではありません。 Couchbase インスタンスでは、5000 未満のドキュメント、20 未満のインデックス、および 8 GB を超える RAM がありました。
InfluxDB データベースは、時系列データに非常に適しています。 その結果、開発者がデータ セキュリティを完全に制御できるため、機密データの保存に最適です。 さらに、InfluxDB のコミュニティ サポートは優れており、必要に応じて組織に簡単に連絡できます。
Orientdb が最高のグラフ データベースである理由
MongoDB とは対照的に、OrientDB には多くの利点があります。
OrientDB はスキーマフリーであるため、データ モデルを簡単にモデル化できます。
OrientDB は ACID に準拠しているため、データの一貫性と耐久性が維持されます。
OrientDB のパフォーマンスは MongoDB よりも優れているため、時系列データの保存に最適です。
グラフ データベースを探している場合は、OrientDB が最適な選択肢となる可能性があります。 True Graph Engine をマスターすると、他のデータ タイプを処理したり、他のシステムを実装したりする必要がなくなります。
Influxdbの長所
InfluxDB を気に入る理由はたくさんあります。 – まず、InfluxDB は非常に簡単にインストールして実行できます。 実際、わずかな構成で、わずか数分でインスタンスを稼働させることができます。 – 次に、InfluxDB は優れた書き込みパフォーマンスを備えています。 汗をかくことなく、毎秒数百万のデータポイントを簡単に処理できます. – 第三に、InfluxDB には非常に柔軟なデータ モデルがあり、ニーズに合わせて簡単にカスタマイズできます。 – 第 4 に、InfluxDB には、さまざまな種類のクエリをサポートする豊富なクエリ言語があります。 – 第 5 に、 InfluxDB はさまざまな種類のデータ ソースやアプリケーションとうまく統合されます。 全体として、InfluxDB は時系列データに最適です。 使いやすく、優れたパフォーマンスを発揮し、非常に柔軟です。
InflluxDB は時系列データベースです。 このユース ケースのパフォーマンスを最大化するには、主に機能面でトレードオフを行うことが重要です。 ごく最近のタイムスタンプを持つデータが書き込みの大部分を占め、昇順で追加されます。 問題のデータが更新されることはめったになく、論争の的となる更新もめったにありません。 設計者が一時的で連続しないデータを処理してパフォーマンスを向上させることは困難でした。 多数の読み取りと書き込みを行うデータベースは、それを処理するのに十分な大きさである必要があります。
最も強力な時系列データベースは、InfluxDB Cloud と時系列データベースを組み合わせたサービスです。 この無料のツールは使いやすく、高速で、サーバーレスで、弾力性があり、Docker や Prometheus などの一般的なツールをサポートしています。 オープン ソースの InfluxDB の人気により、同社は業界で最も成功したビジネスの 1 つに成長しました。 この年、InfluxData の範囲が劇的に拡大し、世界中で 450,000 を超える InfluxDB のアクティブなインスタンスが実行されました。 シンプルで迅速にデプロイできる強力な時系列データベースを必要とするデータ サイエンティストやエンジニアは、InfluxDB Cloud の理想的な候補です。