
Kafka: マイクロサービスのメッセージ ブローカーに最適
公開: 2022-11-19Kafka は分散ストリーミング プラットフォームです。 ログ集計、リアルタイム ストリーム処理、およびイベント ソーシングによく使用されます。 最近では、Kafka がマイクロサービスのメッセージ ブローカーとして人気を集めています。 Kafka は、ActiveMQ や RabbitMQ のような従来のメッセージ キューではありません。 すべてのメッセージを保存する中央サーバーはありません。 代わりに、パブリッシュ/サブスクライブ モデルを使用します。 メッセージはトピックに格納され、各トピックは複数のパーティションを持つことができます。 Kafka は可用性が高く、スケーラブルです。 1 日あたり数十億のメッセージを処理できます。 Kafka も非常に高速です。 メッセージをリアルタイムで処理できます。 Kafka は、マイクロサービス用のメッセージ ブローカーを構築するための優れた選択肢です。 可用性が高く、スケーラブルで、高速です。
リアルタイム メッセージング システムである Kafka は、これを可能にします。 データ ストリームは干渉から保護され、分散またはフォールト トレラントにすることができます。 Kafka データ統合バスは、幅広いプロデューサーとコンシューマーがデータを共有できるようにするデータ交換プロトコルです。 Kafka の機能は、アプリケーションの最後でデータ バッファーとして機能する MongoDB および RDS の機能に似ています。
SQL ベースのスクリプト言語である KSQL は、 Apache Kafkaでリアルタイムのストリーミング データを分析および処理するために使用されます。 KSQL には、データ集約、フィルタリング、結合、セッション化、ウィンドウ処理などのストリーム処理アクティビティを実行できるようにすることを目的とした、ストリーム処理用の対話型フレームワークが含まれています。
Apache Kafka で実証されているように、これは単なる優れたメッセージ ブローカーではありません。 フレームワークの実装には、データベースでの使用に適した多くのデータベースのような機能があります。 その結果、リレーショナル データベースに依存するのではなく、ビジネス イベント レコードとして機能するようになりました。
Kafka アプリケーションは、MongoDB からシンプルかつ効率的な方法でデータをストリーミングすることにより、時間とエネルギーを節約します。 企業が大量のデータを他のサブスクライバーに公開し、複数のデータ ストリームを管理するには、MongoDB が必要です。 Kafka MongoDB 接続サービスを使用すると、開発者は、人気のある業界ツールである MongoDB を使用して複数の非同期ストリームを作成できます。
データベースでは、Apache Kafka がモデルとして機能します。 何百もの企業が ACID 保証を提供し、ミッション クリティカルなタスクを実行するために使用しています。 ただし、ほとんどの場合、Kafka は他のデータベースほど競争力がありません。
Kafka とはどのような種類のデータベースですか?

Kafka は、メッセージの保存と取得に使用されるデータベースの一種です。 これは、スケーラブルでフォールト トレラントになるように設計された分散システムです。
これは、Apache Software Foundation のKafka プロジェクトの一部である、Scala と Java で書かれたオープンソースのストリーム処理プラットフォームです。 コンピュータ サイエンスにおけるストリームとは、時間の経過とともに利用可能になる情報要素の集まりです。 ストリームは、一度に 1 つずつ処理されるコンベア ベルト内のアイテムとして定義できます。 ストリームは、最も基本的な形式では、一見無関係な一連のイベントである可能性があります。 イベント ソーシングの概念は、開発者が慣れ親しんでいるデータ ウェアハウジングやデータ分析の概念とは異なります。 Kafka をデータベースとして使用するにはどうすればよいですか? ブルーは、取引にイエスと言う会社です。
Team Red によると、プログラマーは従来のデータベースから Kafka に切り替えるときに大きな間違いを犯しています。 Martin Kleppmann によると、Kafka はすべての人のためのものであるという Team Red のメッセージは、ひいきにされています。 Team Red が Kafka とストリームに関して抱えている問題は、開発者が RDMS を破棄するという問題があることです。 イベントの永続的なログが表示されると、常に履歴コンテキストが保持されるため、監査が容易になります。 データベース管理には多くの利点がありますが、最も難しい側面の 1 つでもあります。 従来のデータベースは、読み取りと書き込みを混同するという 2 つのまったく異なる方法で動作します。 プログラマーが複数のテーブル間で複製されたデータを維持および同期することは重要です。
スケールは、あなたが行くにつれてパターンを変更します。 ストリームは、リーダーとライターの懸念事項が明確に区別されることで区別されます。 Kafka がファイルに書き込む速度と、Elastic Search が更新をプッシュする速度との間には関係がありません。 その結果、 Kafka ユーザーはさまざまなマテリアライズド ビューを生成するためにログを処理します。 マテリアライズド ビューを便利なキャッシュ メカニズムとして機能させるには、初期費用が必要です。 マテリアライズド ビューは、独自のデータの格納とスケーリングに加えて、インフラストラクチャの重要なコンポーネントです。 99% の企業にとって、DBMS は最適な基盤です。
あなたのアプリケーションはこのカテゴリに属する可能性があり、あなたの経歴に基づいた斬新なアーキテクチャを利用できる可能性があります。 データベースをログに置き換えると、多くの重要な機能が失われます。 この機能には、外部キー制約、アトミック (オール オア ナッシング) トランザクション、および同時実行性の問題に役立つ手続き型分離手法が含まれます。 Arjun は、アプリケーションの整合性が常に維持されていることを前提としています。 ほとんどの人が当たり前だと思っている基本的な機能は、ストリームで作業するときに追加の責任になります。 書面による声明から意図を分離することが重要です。 一般的な構成は、変更データ キャプチャ システムと共に Kafka を使用することです。
Team Red によると、データベースのデータ整合性機能は、データ制御を実現するために重要です。 トランザクションを考慮するには、トランザクションを従来のデータベースから分離する必要があります。 そのため、1 冊の文章にコストがかかる場合があります。 アプリケーションが大量の高価な書き込みに対処するのに苦労している場合、より従来型のデータベースへの移行を余儀なくされる可能性があります。 Team Red は、Kafka の前でデータベースを使用すると、その最高の機能が低下することに言及していません。
この設計の利点は、従来のメッセージング システムよりもはるかに優れています。 Kafka の最初の利点は、多数のリクエストを処理できることです。 さらに、データは必要なときにのみディスクに書き込まれるため、Kafka は大量のデータを処理できます。
SQL Server は、ツールのカテゴリに分類されるデータベース ツールです。 このハンドヘルド デバイスは用途が広く信頼性がありますが、使いにくい場合があります。 Kafka と Azure はどちらも非常に有能なプラットフォームですが、Kafka はスケールアップされ、Azure はスケールダウンされます。
SQL Server は、大量のデータ ストレージを必要とする企業にとって優れたツールですが、迅速なスケーリングや高いスループットを必要とする企業にとっては最適な選択肢ではない可能性があります。 パフォーマンスを犠牲にすることなく大量のデータを処理する必要がある企業の場合、Kafka は SQL Server よりも優れた選択肢です。
Kafka: 時系列テレメトリ用の分散ストレージ システム
トピックベースのモデルを採用する Kafka Distributed Storage System は、データを保存します。 データは、リレーショナル データベースではなく、Kafka データベースのトピック ベースのモデルに格納できます。 キューと同じ方法ではありませんが、 Kafka Topicのキューと同様に動作します。 時系列データベースではなく、Kafka フレームワークに多数の時系列を格納できます。
Kafka と Mongodb の違いは何ですか?

これは、分散システムに基づく、分散、分割、複製されたコミット ログ サービスです。 ユニークなデザインにもかかわらず、メッセージング システムの重要なコンポーネントです。 一方、MongoDB は「巨大なアイデアのデータベース」と表現されています。
Kafka はそのままではキューイングをサポートしていないため、システムのコンシューマ バージョンにハックする必要があります。 リレーショナル データベースが必要な場合は、別のツールを使用するとより効果的です。 MongoDB は、使いやすさや柔軟性など、さまざまな理由から優れた選択肢です。 Apache のユーザー サポートが利用可能です。 Confluent には、Kafka プロジェクトと同時に Linkedin で作成された Kafka (支払う意思がある場合) があります。 自動バックアップを実行し、クラスターを自動的にスケーリングするベンダーを持つことは非常に便利です。 MongoDB に詳しいシステム管理者または DBA がいない場合は、MongoDB ホスティングを専門とするサード パーティを利用することをお勧めします。
最も基本的な形式の Kafka は、メッセージをキューに入れることを目的としています。 Cassandra のストレージ エンジンは、データがどれほど大きくなっても、データへの一定時間の書き込みを保証します。 MongoDB はカスタムの map/reduce 実装と分析用のネイティブ Hadoop サポートを提供しますが、Cassandra は提供しません。 コストは通常妥当であるため、ホストされているのがあなたであろうと別のプロバイダーであろうと違いはありません。
カフカ対。 従来のデータベース システム
Kafka と従来のデータベース システムにはいくつかの違いがあることに注意することが重要です。
Kafka はストリーミング プラットフォームであるため、大量の事前処理を必要とせずに、高速のデータ取り込みを処理できます。
Kafka の実行時に、データはディスク読み取りではなくテール読み取りによって消費されます。
ページ キャッシングを使用すると、Kafka の往復データベース アクセスの必要性が減少します。
ダウンストリームの顧客にデータを送信するために、Kafka は pub/sub メッセージングを採用しています。
Kafka データベースとは
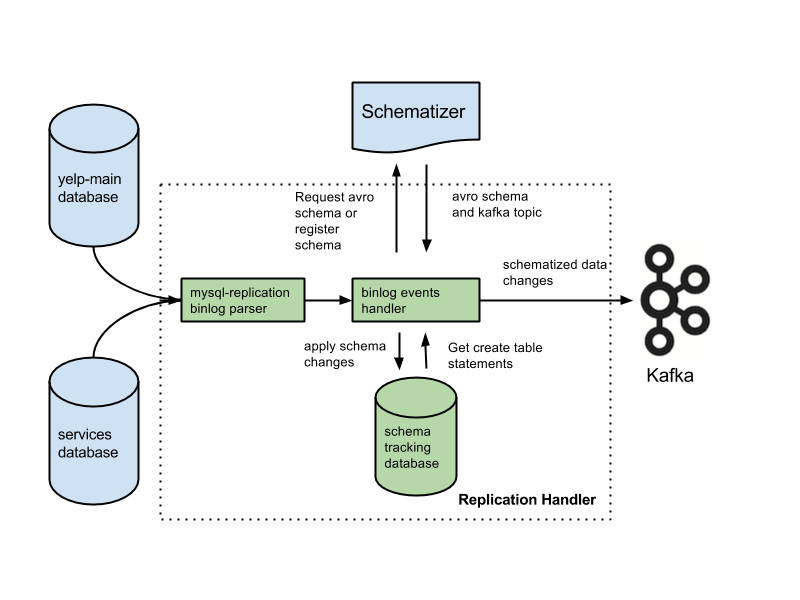
Kafka は、ストリーミング データの格納によく使用されるデータベースです。 これは、スケーラブルでフォールト トレラントになるように設計された分散システムです。 Kafka は、リアルタイム データ パイプラインとストリーミング アプリの構築によく使用されます。 高スループットと低レイテンシを処理できます。
近年、Kafka などのメッセージ ブローカーの人気が高まっています。 支持者によると、Kafka はデータ管理のパラダイム シフトです。 Kafka をプライマリ データ ストアとして使用しても分離されないことを覚えておくことが重要です。 データベース システムで発生するすべての問題は、将来的に解決されます。 ハッカーは、自律アーキテクチャの欠陥を悪用してデータを盗むことができます。 2 人のユーザーが同じアイテムを同時に購入しようとすると、両方とも成功し、両方の在庫が不足します。 Gaslight アプライアンスの実行時にタイムトラベル機能を使用するこれらのアーキテクチャは、イベント駆動型アーキテクチャに依存しています。
大量のデータを管理することは、Kafka の優れた使い方です。 従来の DBMS を使用してトランザクションを分離する必要があります。 アドミッション コントロールには OLTP データベースを使用し、イベント生成には CDC を使用し、ビューが表示されるときにダウンストリーム コピーをモデル化して、データベースを裏返しにします。
Kafka は、大量のデータを保存して日常的に処理するためにも使用できます。 バッチまたはストリーミング モードでビッグ データを処理できることは、他の方法よりも優れています。 たとえば、 Kafka プロセスを使用して、複数のサーバーからログ ファイルを取得し、それらをデータベースまたは検索インデックスに格納できます。 リアルタイムでデータを処理するために使用できるストリーミング API も利用できます。
カフカ対Sql
一般に、Kafka と MySQL は、メッセージ キューとデータベース アプリケーションの 2 つのタイプに分類されます。 ほとんどの開発者は、Kafka を高スループットで分散型のスケーラビリティ ソリューションと見なしていますが、MySQL はそのシンプルさ、パフォーマンス、および使いやすさから最も人気があると見なされています。
Kafka の Pub-Sub メッセージングは、大量のデータを処理できる、分散型で耐障害性のある高スループット システムです。 MySQL は、世界で最も人気のあるオープン ソース データベースであり、ミッション クリティカルで高負荷の運用システムでの使用を目的としています。 開発者は、その高いスループット、分散アーキテクチャ、およびスケーラビリティにより、Kafka が MySQL よりも強力であると考えています。 一方、SQL、Free、および Easy は、MySQL ユーザーがそれを好む主な理由です。 データベース管理システム (DBMS) を実際に体験したい場合は、PostgreSQL をお勧めします。 Vital Beats では、主に Postgres を使用しています。Postgres を使用すると、コマンド ラインをサポートしながら、効果的なデータ管理とバックアップの間で望ましいバランスを実現できるからです。 データベースをオンプレミスまたはクラウドでホストすることを計画している場合、最初の連絡先は PaaS (Platform as a Service) データベースです。 MongoDB は 1 つのドキュメントと同じレベルでデータを書き込むため、トランザクションがないと整合性が取りにくくなります。
Amazon DynamoDB や AWS RedShift に見られるようなドキュメント ストアは、MongoDB に見られるキーと値のペア (または列ストア) とは大きく異なります。 開発時間が短縮されるため、#Nosql データベースを使用してクエリを実行する方が高速で簡単です。 不動産業界の初心者として、時間の経過とともに生産性の高いデータベースを選択したいと考えています。 単一リージョンのデプロイで AWS で Aurora Postgres を実行する場合、これは私が推奨する最高のプラットフォームの 1 つです。 3 つのクラウド環境で PostgreSQL を使用すると、より優れたマルチリージョン レプリケーションを体験できます。 それらを正しく構成すると、これら 3 つのデータベースのいずれも、効率的で、スケーラブルで、信頼性の高い長期的なパフォーマンスを発揮します。 Uber は、より機敏で信頼性の高いデータ転送システムの必要性など、さまざまな理由で Postgres から MySql に切り替えました。
OPS Platform の最高技術責任者は、Postgres はその速度と使いやすさから、同社の製品にとって最も効果的な長期的な選択肢であると述べました。 MySQL 7.x と比較すると、MySQL 8.0 ではトランザクションがより迅速に処理されます。 データベースはより安全ですか? 暗号化キーをランダムに変更することはできますか? MySQL と MongoDB は、最も人気のある 2 つのオープン ソース データベースです。 データを簡単に保存できるだけでなく、MongoDB を使用して、コンテンツ配信ネットワーク (CDN) 経由で大量の受信データを保存できます。 他のオブジェクト リレーショナル データベースに対する Postgres の主な利点は、拡張性と標準への準拠に重点を置いていることです。

通常の B ツリー インデックスとハッシュ インデックス、および式インデックスと部分インデックス (テーブルの一部にのみ影響するインデックス) を作成できます。 Redis と Kafka の最も基本的な違いは、エンタープライズ メッセージング フレームワークの使用です。 選択する際にクラウドネイティブなテクノロジーを探しています。 サービス ディスカバリに加えて、NATS を使用して、負荷分散、グローバル マルチクラスタ、およびその他の操作を置き換えることができます。 Redis が実行しない唯一のことは、純粋なメッセージ ブローカーとして機能することです (執筆時点)。 その結果、より一般的なメモリ内キー値ストアになります。 膨大な音楽ライブラリがあるにもかかわらず、私の曲は 2 時間以上の長さになることがよくあります。
オーディオ ファイルをデータベースの行に数時間保存する場合の問題は、簡単に検索できないことです。 必要に応じて、Backblaze b2 や AWS S3 などのクラウド ストレージ サービスにオーディオ ファイルを保存することを検討してください。 IoT World で MQTT Broker を使用するソリューションはありますか? データセンターの1つに収容されています。 現在、アラートおよびアラーム関連の目的で処理中です。 私たちの主な目標は、操作の複雑さとメンテナンス コストを削減する軽量な製品を使用することです。 Apache Kafka をこれらの追加のサードパーティ API 呼び出しと統合できれば理想的です。
RabbitMQ アプリは、再試行とキューイングの両方に最適です。 各メッセージを複数のユーザーが処理する必要がない場合は、RabbitMQ を使用できます。 Kafka を使用して確認付きのシステムを提供することは意味がありません。 Kafka イベント状態マネージャーは、永続化されたイベント状態マネージャーと同様に、ストリーム API を使用してさまざまなデータ ソースを変換およびクエリできます。 RabbitMQ フレームワークは、1 対 1 のパブリッシャーまたはサブスクライバー (またはコンシューマー) にとって理想的であり、ファンアウト交換を構成して複数のコンシューマーを有効にできると考えています。 Pushnami プロジェクトは、あるデータベースから別のデータベースにライブ データを移行する方法を示しています。 フロントエンド (Angular)、バックエンド (Node.js)、フロントエンド (MongoDB) はそれぞれネイティブであるため、データ交換ははるかに簡単でした。
翻訳層を避けるために、関係から階層への部分をスキップしました。 MongoDB オブジェクトのサイズを有限に保ち、正しいインデックスを使用することが重要です。 1960 年代には、最も初期の電子カルテ (EMR) の一部で、ドキュメント指向のデータベースである MUMPS が使用されていました。 すべての病院記録の最大 40% を格納する MongoDB は、堅牢な医療データベースと見なされています。 ただし、ネイティブでサポートされていないジオクエリを実行するための非常に巧妙な方法がいくつかありますが、これは長期的には非常に遅くなります. Amazon Kinesis は、数十万のソースから毎秒数十万のデータファイルを処理します。 RabbitMQ を使用すると、どのアプリからでも簡単にメッセージを送受信できます。 Apache ActiveMQ は高速で、さまざまな言語にまたがるクライアントをサポートし、堅牢なスクリプト言語です。 Hadoop データは、Spark という高速な汎用処理エンジンを使用して処理されます。
カフカ対モンゴッド
Mongodb は強力なドキュメント指向データベースであり、さまざまなアプリケーションに適した多くの機能を備えています。 Kafka は、リアルタイム データ パイプラインとストリーミング アプリケーションの構築に使用できる高性能ストリーミング プラットフォームです。
ソースとしての MongoDB から他の MongoDB ソースまたは他の MongoDB ソースへの転送は、Kafka to MongoDB アプリケーションとシームレスに行うことができます。 MongoDB Kafka Connector の助けを借りて、データを効率的に転送する方法を学びます。 この機能を使用すると、組織用にまったく新しい ETL パイプラインを作成できます。 Confluent は、ソースとシンクとして機能するさまざまなコネクタを提供し、ユーザーが 2 つの間でデータを転送できるようにします。 Debezium MongoDB コネクタは、Kafka MongoDB ユーザーが MongoDB データベースに接続できるようにする接続メカニズムの 1 つです。 Confluent Kafka を開始する前に、システムで実行されていることを確認する必要があります。 KStream、KSQL、または Spark Streaming などのその他のツールなどの機能を使用して、Kafka でデータを分析できます。
ウェアハウスへのデータ入力には、手動のスクリプトとカスタム コードが必要です。 Hevo のノーコード データ パイプライン プラットフォームを使用すると、コーディングなしでシンプルなデータ パイプライン システムを作成できます。 Hevo の透明な価格設定プラットフォームにより、ELT 支出のすべての詳細をリアルタイムで確認できます。 試用期間は 14 日間で、24 時間年中無休のサポートが含まれています。 エンド ツー エンドの暗号化は、最も厳しいセキュリティ認定を使用して行われます。 Hevo を使用すると、Kafka および MongoDB のデータを 150 の異なるデータ ソース (40 の無料ソースを含む) に安全に転送できます。
Kafka と Mongodb とは何ですか?
MongoDB Kafka コネクタは、Kafka トピックからのデータをデータ シンクとして MongoDB に保持し、それらのトピックへの変更をデータ ソースとして公開する Confluent-verified コネクタです。
Kafka をデータベースとして使用することの長所と短所
Kafka に適したデータベースはどれですか? 原則として、Kafka を使用してデータベースを作成できます。 その結果、何十年にもわたってデータベース管理システムを悩ませてきたすべての主要な問題が調査されます。 データベース管理システム (DBMS) は、データの編成とクエリを行うソフトウェアの一種です。 これらは、大規模なアプリケーションや、複数のユーザーがアクセスする必要があるデータを格納するために必要です。 DBMS は、リレーショナルと非リレーショナルの 2 つのタイプに分類されます。 リレーショナル モデルは、リレーショナル DBMS で情報を表す標準的な方法です。 それらは使いやすく、テーブルに編成されたデータを格納するために使用できるため、人気があります。 リレーショナル モデルを使用しない DBMS は、他のモデルを使用する DBMS ほど強力ではありません。 データは、データのストリームなど、より効率的に整理するために、テーブル以外の形式でも保存されます。 Kafka モデルは、さまざまな目的に使用できるデータベースの作成に使用されます。 ストリーム処理は、新しいデータ表現モデルである Kafka の中心です。 データ管理システム (DMS) は、データ管理の重要なコンポーネントです。 ただし、Kafka をデータベースとして使用するのは難しい場合があります。 DBMS が遭遇する最も一般的な問題のいくつかは、パフォーマンス、スケーラビリティ、および信頼性です。 Fivetran の CEO である George Fraser と Materialise の CEO である Arjun Narayan がこの投稿を共同執筆しました。
Kafka 永続性データベース
Kafka 永続データベースは、高可用性でスケーラブルな方法でkafka クラスターにデータを格納する方法を提供します。 デフォルトでは、kafka はメモリ内データベースを使用してデータを保存しますが、これは運用環境の展開には適していません。 kafka 永続性データベースを使用して、kafka データにより信頼性の高いストレージ オプションを提供できます。
LinkedIn は 2011 年にオープンソースの Apache kaffef を作成しました。このプラットフォームにより、リアルタイム データを非常に低いレイテンシとスループットでフィードできます。 ほとんどの場合、データは外部システムからKafka Connectを介してインポートおよびエクスポートできます。 新しいソリューションは、非効率的なストレージ パフォーマンスや十分に活用されていないドライブなどの問題を解決するのに役立ちます。 アーキテクチャの課題にもかかわらず、ローカル フラッシュは Kafka システムに最適な選択肢です。 Kakfa の各トピックは 1 つのドライブでしかアクセスできないため、十分に活用されないことが増えます。 同期も困難な場合があり、その結果、コストと効率の問題が発生します。
SSD に障害が発生した場合、SSD のデータを完全に再構築する必要があります。 この時間のかかる手順により、クラスターのパフォーマンスが低下します。 Kafka は、信頼性とパフォーマンスのトレードオフを平坦化するため、NVMe/TCP ベースのストレージに最適です。
Kafka は素晴らしいメッセージング システムですが、データを保存するための完璧なソリューションではありません
Kafka は、データの保存に使用できる優れたメッセージング システムです。 Kafka の保持オプションの 1 つは、-1 の保持時間です。これは、生涯の保持を意味します。 ただし、Kafka の信頼性は、従来のデータベースの信頼性にはほど遠いものです。 Kafka はデータをディスク、チェックサム、およびフォールト トレランスのためにレプリケートして保存することに注意することが重要です。 Kafka はメッセージの送受信に使用できますが、データの保存には最適な選択ではありません。
カフカとは
Kafka は、高速で、スケーラブルで、耐久性があり、フォールト トレラントなパブリッシュ/サブスクライブ メッセージング システムです。 Kafka は、LinkedIn、Twitter、Netflix、Airbnb などの企業のプロダクションで使用されています。
Kafka はシンプルでわかりやすい設計になっています。 これは、マシンのクラスター上で実行され、水平方向にスケーリングできる分散システムです。 Kafka は、高スループットと低レイテンシーを処理するように設計されています。
Kafka は、リアルタイムのストリーミング データ パイプラインとアプリケーションを構築するために使用されます。 リアルタイムでデータを処理および集計するために使用できます。 Kafka は、イベント処理、ロギング、および監査にも使用できます。
LinkedIn は、リアルタイムのデータ フィードを処理するために 2011 年に Kafka を立ち上げました。 Kafka は現在、Fortune 100 の 80% 以上で使用されています。 Kafka Streams APIは、オンザフライ処理を可能にするように設計された強力で軽量なライブラリです。 一般的な分散データベースに加えて、Kafka には分散コミット ログの抽象化が含まれています。 メッセージング キューとは異なり、Kafka は、高いスケーラビリティを備えた、適応性が高く、フォールト トレラントな分散システムです。 一例として、Uber で乗客とドライバーのマッチングを管理したり、British Gas でリアルタイム分析を提供したりするために使用できます。 多くのマイクロサービスは Kafka に依存しています。 Confluent のクラウドネイティブで完全なフル マネージド サービスは、Kafka よりも優れています。 Confluent を使用すると、履歴データとリアルタイム データを 1 つの統一された信頼できるソースに統合することで、最新のイベント駆動型アプリケーションのまったく新しいカテゴリを簡単に構築できます。
Kinesis の助けを借りて、幅広いデータ ストリームを処理できるため、強力で用途の広いストリーム処理プラットフォームになります。 速度、シンプルさ、および幅広いデバイスとの互換性により、人気のあるプラットフォームです。 その信頼性から、最も人気のあるストリーミング プラットフォームの 1 つです。 耐久性に優れているため、大量のデータを問題なく処理できます。 さらに、広く使用され、サポートされている有名なプラットフォームであるため、パートナーやインテグレーターを簡単に見つけて、使い始めることができます。 強力で信頼できるストリーミング プラットフォームを探しているなら、Kinesis が最適です。
Kafka: データベースに取って代わるメッセージング システム
リアルタイム データ フローは、リアルタイム ストリーミング データ パイプラインおよびアプリケーションを構築するためのメッセージング システムである Kafka を使用して、変化するデータ環境に適応するように作成できます。 ビッグ データは、Scala と Java で記述された Kafka を使用して、リアルタイムのイベント ストリームを通じて処理されます。 Kafka 接続は、あるポイントから別のポイントに拡張でき、ソース間でデータを送信するためにも使用できます。 イベント ストリーミング プラットフォームは、イベントのライブ ストリーミングを提供することを目的としています。 データベースを Kafka のようなメッセージング ソリューションと比較するのは不公平です。 Kafka の機能により、データベースは不要になりました。
Kafka はデータベースではない
Kafka はデータベースではありませんが、データベースと組み合わせて使用されることがよくあります。 これは、システムの異なるコンポーネント間でメッセージを送信するために使用できるメッセージ ブローカーです。 多くの場合、システムのさまざまな部分を分離して、個別にスケーリングできるようにするために使用されます。
Apache Kafka をデータベースに置き換えることは可能ですが、便宜上そうしないでください。 主人公が中古のミッドエンジンのイタリア製スーパーカーを購入してそれぞれ 10,000 ドルを得たトップ ギア エピソードは、主人公がそれぞれ 10,000 ドルを与えられた古いトップ ギア エピソードを思い出させました。 2011 年、LinkedIn は Kafka をリリースし、このエピソードは同じ年に放映されました。 フル機能のメッセージング プラットフォームに投資することなく、最低限の永続的なメッセージングを行うことができます。 大前提とは、基本的なルールがあることです。 プロデューサー プロセス中に記録された各イベントのテーブル (またはバケット、コレクション、インデックスなど) を作成します。 コンシューマー インスタンスから定期的にデータベースをポーリングし、処理中にコンシューマーの状態を更新します。
モデルが適切に機能するためには、生産者と消費者が同時に機能できる必要があります。 Kafka の本をガイドとして使用し、記録を単に読むのではなく無期限に保存することを検討してください。 一方、ばらばらな消費者グループは、挿入時にレコードを複製し、消費後にレコードを削除することで実装できます。 Kafka は永続的なオフセットを採用して、ユーザー定義のデータ ファニングを有効にし、複数のばらばらなコンシューマーをサポートします。 この機能を廃止するには、ゼロからサービスを開発する必要があります。 時間ベースのパージの概念を実装することは難しくありませんが、スカベンジャーのロジックをホストする必要があります。 Kafka では、すべてのアクター (コンシューマー、プロデューサー、および管理者) をきめ細かく制御できます。
コモディティ サーバーやクラウド サーバーで 1 秒あたり数百万件のレコードを問題なく処理できます。 Kafka は、非機能的な意味で、プロデューサー側とコンシューマー側の両方で高レベルのスループットに最適化されています。 Kafka を使用すると、この分野で他の追随を許さない分散型の追加専用ログになります。 消費段階でメッセージを削除する従来のメッセージ ブローカーとは異なり、Kafka は消費後にメッセージをパージしません。 データベースのスループットと待機時間は、専用のハードウェアと高度に焦点を絞ったパフォーマンス チューニングを使用して大幅に改善する必要があることはほぼ確実です。 ブローカーとの調剤は、一見魅力的かもしれません。 Kafka などのストリーミング イベント プラットフォームを使用すると、その構築に費やされた膨大なエンジニアリング作業を利用できます。
現在展開するソリューションを確実に維持するには、高い水準で維持できることを確認する必要があります。 イベント ストアの機能の大部分は、データベースを使用してのみ実装できます。 万能のイベント ストアはありません。 重要なイベント ストアは、ほとんどの場合、1 つ以上の既製のデータベースに支えられた特注の実装であることはほぼ確実です。 効率的な検索のためにデータを整理する分野でデータベースを使用できますが、(ほぼ) リアルタイムでデータを配布する目的でデータベースを使用することは避けてください。