
Key-Value データベース: 長所と短所
公開: 2023-02-08NoSQL データベースは、大量のデータを処理する必要がある最新のアプリケーションにとって、ますます頼りになる選択肢になりつつあります。 NoSQL データベースにはさまざまな種類がありますが、キー値データベースは最も一般的な選択肢の 1 つです。 キー値データベースは、キーと値のペアの形式でデータを格納するNoSQL データベースの一種です。 キーは、単純なデータ型 (文字列や整数など) から複雑なデータ構造 (配列やオブジェクトなど) まで、関連付けられた値を検索するために使用されます。 キー値データベースは、大量のデータを格納する必要があり、そのデータをすばやく取得できる必要があるアプリケーションに適しています。 非正規化された形式 (つまり、従来の行と列に編成されていないデータ) でデータを格納する必要があるアプリケーションにも適しています。 次のプロジェクトでキー値データベースの使用を検討している場合は、次の点に注意してください。 1. キー値データベースは、大量のデータを格納する必要があるアプリケーションに最適です。 2. キー値データベースは、非正規化形式でデータを格納する必要があるアプリケーションに適しています。 3. キー値データベースは、データに対して複雑なクエリを実行する必要があるアプリケーションには適していません。 4. キー値データベースは、トランザクションをサポートする必要があるアプリケーションには適していません。
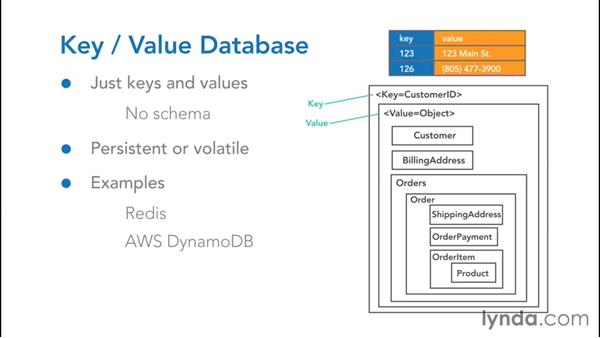
NoSQL データベースに関しては、ユースケースごとに最適な方法はありません。 Dan と James Sullivan によると、ドキュメント データベースとキー値データベースはいくつかの点で異なります。 値ベースのデータベースをフェッチするための SQL スタイルのクエリ言語はないため、代わりにキーが使用されます。 MongoDB や Couchbase などのドキュメント データベースは、検索機能を提供することで概念をさらに一歩進めています。 ドキュメント データベースは、ドキュメントをコレクションに編成します。コレクションは、タイプ別に編成されます。 キーと値のデータベースは、名前空間内のすべてのキーと値のペアのコンテナーです。 製品などの大規模なコレクションはパーティション化できるため、クエリのパフォーマンスを向上させることができます。
各サーバーに作業のサブセットを割り当てることにより、コレクションを複数のサーバーに分割します。 多くのデータベース アプリケーションは、キー値データベースとドキュメント データベースの恩恵を受けます。 Key-Value データベースは、習得が簡単であれば、優れたクエリ パターンとデータ構造を提供できます。 クエリとエンティティの複雑さが増すにつれて、ドキュメント データベースが最適なオプションになる可能性があります。 フィルター条件を使用してインデックスを作成すると、クエリのパフォーマンスを向上させることができます。
膨大な量のデータを処理し、膨大な量の状態変化を処理しながら、分散処理とストレージを通じて何百万もの同時ユーザーにサービスを提供できます。 さらに、キー値データベースには冗長ストレージが含まれているため、ストレージ ノードが破壊された場合でもデータ損失に対処できます。
キー値 Nosql データベースの主な目的は何ですか?
キー値 nosql データベースには多くの目的があります。 これらのデータベースを使用する最も一般的な理由には、次のようなものがあります。 -リレーショナル化が容易ではないデータを格納するため -スケールアウトによってパフォーマンスを向上させるため -データ スキーマに柔軟性を提供するため -簡単なデータ配布をサポートするため
各列に一意のインデックスが作成され、アクセスしやすくなるため、主キーを持つテーブルへのアクセスが容易になることがよくあります。 インデックスは要求されたデータを見つけるためにテーブルのすべての行を検索する必要がないため、多くの場合、主キーを持たないテーブルよりも高速にアクセスできます。
Key-Value データベースを使用しない場合
キー値データベースを使用したくない状況がいくつかあります。 1 つの例は、いくつかの基準を満たすすべてのレコードを検索するなど、複雑なクエリをサポートする必要がある場合です。 もう 1 つの例は、キー値データベースでは不可能なトランザクションをサポートする必要がある場合です。 最後に、複数のユーザーによる同時アクセスをサポートする必要がある場合、キー値データベースは最適なオプションではない可能性があります。
一般に、key-value、階層、map-reduce、またはグラフ データベース システムは、実装戦略にはるかに似ています。 データが、それぞれに対して一意の識別子を生成できる単なるリストである場合、KVS は適切です。 これは、新入生のコンピューター サイエンスで学んだデータ構造に似ていました。 NoSQL データベースでは、構造化されていない、予測不可能な、または変化するデータが、保存するのに最適なタイプのデータです。 構造化されたデータがない場合、リレーショナル データベースがあまり役に立たない可能性があります。 正規化されたリレーショナル データの理解と検証は、役立つ重要なリレーションシップと制約を含むテーブルを用意することで簡単に行うことができます。 アプリケーションが小さく、データ構造が複雑な場合は、リレーショナル データベースを使用することで費用を節約できます。 一方、難解な手法は魅力的でやりがいがあり、面白いものですが、従来のアプローチを必要とするアプリケーションは 99.999% にすぎません。 スケーラビリティは、KV の主な理由であるシステムの稼働を維持することとは何の関係もありません。
ただし、キー値ストアの使用にはいくつかの欠点があります。 最初にすべきことは、作業範囲を単純なデータ構造に限定することです。 データにキーと値の形式がない場合は、キーと値のストアが理解できる形式に変換する必要があります。
キー値ストアは、データを格納する汎用性の高い方法であり、アクセスや変更を必要としないデータに特に適しています。
Key-Value ストアのさまざまな用途
キー値ストアが適切な場合、さまざまな状況で使用できます。 キー値ストアは、大量の継続的な読み取りと書き込みを必要とするアプリケーションで使用できます。 キー値ストアはメモリにすばやくアクセスできます。
キー値ストアは何に使用されますか?
低速メモリ システムへの読み取りと書き込みを減らしてアプリケーションを高速化するために、メモリ内データ キャッシュにキー値ストアが頻繁に使用されます。 Hazelcast テクノロジは、メモリにキー値を格納する高速データ検索ツールです。
キー値ストアは、連想配列とは対照的に、連想配列を基本的なデータ モデルとして使用します。 get、put、および delete コマンド ライン プログラムを使用して、データを保存、取得、および更新できます。 Key-Value ストアは、使いやすく、スケーラブルで、移植可能で、柔軟性があり、高速で使いやすく、スケーラブルで移植可能なストレージ ソリューションを備えています。 サイズが大きく、一定の操作ストリームを低レイテンシで処理できるため、優れたパフォーマンスを発揮します。 キャッシュには、ディスクから事前計算またはコピーできるデータが含まれています。 アプリケーションがデータのリクエストを受信し、それがキャッシュにある場合 (ヒットと呼ばれます)、キャッシュを読み取ってサービスを提供できます。 書き込みや更新のパフォーマンスを向上させるためにキャッシュは使用されませんが、キー値ストアは非常に効果的です。

待機時間は、データベースに 100,000 行を挿入してから最初の行を取得するのにかかる時間として計算されます。 データベースにクエリを送信して最初の応答を受信するまでにかかる時間によって、データベースの可用性が決まります。 スループットを評価するために、クエリがデータベースに送信されるまでの時間と最初の応答を測定できます。 データベースのサイズは、ストレージの評価に使用されます。
RonDB は、キー バリュー ストアの評価で最大の待機時間と可用性を提供します。 さらに、最大のスループットとストレージ容量を備えています。
キー値ストアの利点
データベースを作成するには、一連のキーと値を指定する必要があります。 キーは値ではなく、データの個別の識別子であることに注意してください。 これらのキーをデータベースで使用して、データを検索したり、インデックスを作成したりできます。 キーと値のストアを使用する場合、データはキーと値のペアでデータベースに格納されます。 キーと値のペアを分離することはできません。 これらのインデックスを使用すると、大量のデータをすばやく簡単に取得できます。 キー値ストアを使用する場合、すべてのデータを 1 つの場所で追跡する必要はありません。 すべてのデータは、データベースでサポートされている形式のいずれかで保存されます。 特定の形式で保存する必要のないデータは、キー値ストアに保存できます。
キー値 Nosql データベースの例
データベース クエリとテキストの検索は、Couchbase の SQL スタイルのクエリで処理されます。 Amazon DynamoDBは、主に Amazon で使用されるキー値データベースです。 DynamoDB は広く使用されているデータベースであるため、多数のユーザーによって使用されています。
キー値データベースは、データがキー値形式で格納され、読み取りと書き込み用に最適化されたデータベースの一種です。 値がキーに関連付けられている場合、一意のキーまたはいくつかの一意のキーを使用して、関連付けられた値が取得されます。 キーと値のペアのデータ システムの例は MongoDB にあり、幅広いデータベースの例とユース ケースをカバーしています。 MongoDB は、バイナリ JSON ドキュメントの一種であるコレクションにデータを格納します。 MongoDB のネイティブ ドライバーは、Python、C#、C、Node.js などの言語で記述されています。 柔軟なドキュメントを効率的に格納し、ランダム シーク用の追加フィールドのいずれかにインデックスを付ける MongoDB の機能により、MongoDB は魅力的なキー値ストアになります。 マップや辞書など、キーによって値をすばやく取得する必要があるアプリケーションのユースケースでは、MongoDB キー値ストアが使用されます。 MongoDB ドキュメントは大きくなる可能性があるため、アプリケーションはスキーマを使用してインデックスのフットプリントを削減し、アクセスを最適化できます。 属性パターンは、ドキュメントの配列を使用してキーと値の構造を格納するパターンです。
キー値の例とは?
電話帳は好例であり、キーは個人または企業の名前であり、値は電話番号です。 株式取引データは、キーと値のペアの例です。
Mongodb はキー値データベースですか?
MongoDB では、各ドキュメントが本質的にフィールド値構造である BSON (Binary JSON) ドキュメントのコレクションがキー値ストアです。
キー値データベースの欠点
キー値データベースにはいくつかの欠点があります。 1 つは、データの保存と取得に関して、他の種類のデータベースよりも効率が悪い可能性があることです。 もう 1 つの欠点は、クエリが難しくなり、特定の情報を見つけるのが難しくなることです。 最後に、他のタイプのデータベースよりもスケーリングが難しい場合があります。
キー値データベースは、キーを任意のタイプのデータである値に編成するデータベースです。 標準のリレーショナル データベースには収まらないデータのコレクションを格納するキー値データベースを作成することができます。 ドキュメント データベースの値に対応するキーに基づいてデータを格納する代わりに、構造化データが格納されます。 キーと値のデータベースとキャッシュには、ユースケースと実際の動作の点でいくつかの類似点があります。 本質的に、キャッシュは、データに対する要求の応答性を高めるために提供されるデータのコピーであり、書き込みまたは更新要求を受け入れません。 分散キー値データベースは、ネットワークを介して相互に接続され、複数のノードにデータを格納するタイプのデータベースとして定義できます。
キー値データベースはトランザクションをサポートしていますか?
キー値データベースはトランザクションをサポートしていますか? トランザクションは、キー値ストアで実行できます。
Key-Value データベースの使用例
キーと値のデータベースは、キーと値のペアを使用してデータを格納するタイプのデータベースです。 キーはデータの識別に使用され、値はデータの格納に使用されます。 キー値データベースは、頻繁にアクセスまたは更新されるデータを格納するためによく使用されます。
キー値データベースは、最も一般的なタイプの NoSQL データベースの 1 つです。 非常にシンプルに構築されており、このタイプのデータ モデルでは非常に高速に実行できます。 NoSQL の設計理念により、柔軟性と迅速な開発、および使いやすいアプリケーションの作成が可能になります。 キー値ストアは高速で信頼性が高いため、プログラマーは通常、フィルターやコントロールで発生する可能性のある問題を回避します。 Key-Value ストアは、最も人気があり広く使用されているデータベースの 1 つであり、私たちは日常生活でそれらに依存しています。 key-value ストアによると、従来のリレーショナル データベースは、拡張が容易で、システム間を簡単に移動できるため、多数の読み取りおよび書き込み操作を処理するようには設計されていません。 これらのツールは、リレーショナル データベースと非リレーショナル データベースのギャップに対処するだけでなく、それらにも対処します。 データを分析する場合でも、ユーザーを処理する場合でも、両方を組み合わせることでパイプラインの効率を向上させることができます。
キーと値のペアを使用する利点
キーと値のペアは、他のオブジェクトにリンクせずにオブジェクトを保存する機能が必要な場合に最適です。 キーと値のペアに顧客 ID のリストがある場合、顧客を処理する必要があるときに、ID を使用して配列ルックアップを実行できます。
構成ファイルは、キーと値のペアのもう 1 つの一般的なアプリケーションです。 たとえば、新しいソフトウェア パッケージの構成ファイルを作成して、パッケージの場所と名前を保存することができます。 ファイルの各行には、キーと値のペアのペアが含まれます。キーはファイルの名前で、値はその場所です。
キーと値のペアを使用する場合、データの場所を覚えておく必要はありません。 検索ボックスでファイルを検索するだけで、キーを思い出すことができます。 これにより、ある場所から別の場所に変更する必要がないため、ファイルの読み取りと保守が容易になります。
他のオブジェクトに接続するために必要なデータを格納する必要がある場合は、データベースを使用することをお勧めします。 データベース内のデータにアクセスするために使用する構文と規則は、さまざまな方法で変更できます。 データベースを使用すると、使用する顧客情報を顧客ルックアップ テーブルに格納できます。
データベース内のオブジェクト間の関係を追跡できます。 また、探しているデータを簡単に検索できるようになり、関係を気にせずに新しいオブジェクトをデータに追加できるようになります。