
NoSQL データベース: Impala
公開: 2023-03-03NoSQL は、従来のリレーショナル データベース構造を使用しないデータベースを表すために使用される用語です。 代わりに、NoSQL データベースは多くの場合、よりシンプルでスケーラブルなソリューションを提供するように設計されています。
Impala は、大規模なデータ セットを管理するための高速でスケーラブルなソリューションを提供するように設計された NoSQL データベースです。 Impala は Google Bigtable データ モデルに基づいており、列指向のストレージ形式を使用します。 Impala はオープン ソース プロジェクトとして利用でき、Cloudera によってサポートされています。
Apache Impala は、Hadoop クラスターにインストールされ、システムに格納されたデータに対して大規模な並列処理 (MPP) を実行するオープン ソースの SQL クエリ エンジンです。 2012 年に最初に開発されたこのオープンソース プロジェクトは、「Microsoft Formula 1」として知られています。
Impala プラットフォームを使用すると、ユーザーはデータを移動または変換することなく、HDFS および Apache HBase に格納されたHadoop データに対して低レイテンシーの SQL クエリを実行できます。
Impala は SQL ベースですか?
Impala は、Apache Hadoop 上で実行される SQL ベースのクエリ エンジンです。 これにより、ユーザーは SQL を使用して HDFS および HBase に格納されたデータをクエリできます。 Impala は、Hive や Pig などの他のHadoop クエリ エンジンと比較して、高いパフォーマンスと低レイテンシを提供します。
Impala 分析 MPP データベースは、業界で最速の洞察を提供します。 CDH と統合されており、Cloudera Enterprise からアクセスできます。 Impala などの Apache Hadoop 用の MPP データベースは、HDFS を使用して洞察を得るまでの時間を短縮します。
Impala はデータベースです
そう思えるデータベースです。
Impala は Etl ツールですか?
Impala は ETL ツールではありません。プロセスによってデータが消去された後に SQL クエリを実行するために使用できる SQL クエリ エンジンです。
Apache Impala は何に使用されますか?
SQL に似たクエリを使用して、Impala を使用してさまざまなソースからデータを読み取ることができます。 Apache Impala は、Hadoop 分散ファイル システムに格納されたデータへのアクセスに関して、Hive やその他の SQL エンジンよりも優れたパフォーマンスを発揮します。 Impala を使用して、Hadoop HBase、HDFS、および Amazon S3 にデータを保存します。
技術スタックで Apache Impala を使用している 19 社の企業
Apache Impala は、さまざまな大企業で人気のあるデータ処理エンジンです。 レポートによると、Stripe、Agoda、Expedia.com を含む 19 のテクノロジー企業が Apache Impala を使用しています。 Impala プラットフォームは柔軟かつ効率的で、大規模なデータ セットを迅速かつ効果的に処理できます。 このツールが広く使用されていることは、その有用性とデータ処理における有用性を示しています。
Sql Hive と Impala の違いは何ですか?
Hive の目標は、複数の変換と結合を必要とする実行時間の長いクエリを処理することです。 Impala クエリ処理エンジンは、レイテンシが低く、小さなクエリを処理できるため、対話型コンピューティングに最適です。 Spark は、短期クエリと長期クエリに加えて、短期クエリと長期クエリの両方をサポートしています。
Hive は長時間実行されるバッチ ジョブに適しています
ツールの主な目的は、バッチを処理することではありません。 Hive は、小規模なデータ セットを処理できる Impulsa よりも長期的なバッチ作業に適しています。
Impalaはデータベースですか
impala は、データを列形式で格納するデータベースです。 スケーラブルで、大規模なデータ セットに対して高いパフォーマンスを提供するように設計されています。
Impala の初期リリースでは、数値ではなく STRING、VARCHAR、VARCHar2、INT、および FLOAT のコア列データ型がサポートされており、BLOB 型はサポートされていません。 Impala SQL-92 には、SQL 標準規格の拡張機能がいくつか含まれていますが、それらすべてが組み込まれているわけではありません。 データが大きすぎて単一のサーバーで生成、操作、および分析できない場合、Impala は他のデータ ウェアハウスよりも優れたパフォーマンスを発揮し、スケーラビリティに対応しています。 Impala は軽量であるため、ロード時にデータ ファイルの元の場所を削除する必要はありません。 パフォーマンス テスト、スケーラビリティ、およびマルチノード クラスタ構成について学習するための最初のステップは、通常、膨大な量のデータを収集することです。 Cloudera Impala は、大規模なデータ セットでのデータの読み込みと一括読み取り用に最適化されているため、少ないリソースで多くのことを実行できます。 HDFS の数メガバイトのブロック サイズにより、Impala は複数のネットワーク サーバー間で大量のデータを並行して処理できます。
正規化されたインデックスとその作成にかかる時間と労力を計画する代わりに、Impala でそれを行います。 Impala のクエリ エンジンは、データ ウェアハウスからの大量のデータを処理できます。 クラスターを分析し、ノード間でタスクを分散して、消費されるリソースの量を削減します。 データ ウェアハウスのパーティショニングは、Impala ではおなじみの概念です。 パーティショニングにより、ディスク I/O が削減され、Impala でのクエリのスケーラビリティが向上します。 Impala の組み込みテーブルにはアクセスできないため、データ ファイルが必要です。 INSERT は、使用可能なオプションの 1 つです。
2 つのおもちゃのテーブルを作成するには、value ステートメントを使用します。 バッチ指向のソフトウェアを使用している場合は、試してみてください。 SQL-on- hadoop テクノロジーをApache Hive 構成に組み込むことができます。 Impala の Hive テーブルは、時間のかかる方法でロードまたは変換されません。
Impala: Hadoop 向けの強力なデータ管理ツール
SQL 構文は、HDFS および Apache HBase に格納されたデータをクエリできる Impala のユーザーにはなじみ深いものです。 このように、従来のリレーショナル データベースではなく、Hadoop と Impulsa を使用できます。 さらに、その機能のおかげで強力なデータ管理ツールです。 さらに、大規模なデータセットに対するその機能は印象的であり、それらを非常に簡単に処理できます.

ビッグデータにおける Impala
Impala は、Apache Hadoop 上で動作するオープン ソースの MPP SQL クエリ エンジンです。 HDFS および HBase に格納されたデータに対して、高速でインタラクティブな SQL クエリを提供します。 Impala は、HDFS および HBase に格納されたデータに高速でインタラクティブな SQL インターフェイスを提供することにより、Apache Hadoop のパフォーマンスを向上させるように設計されています。
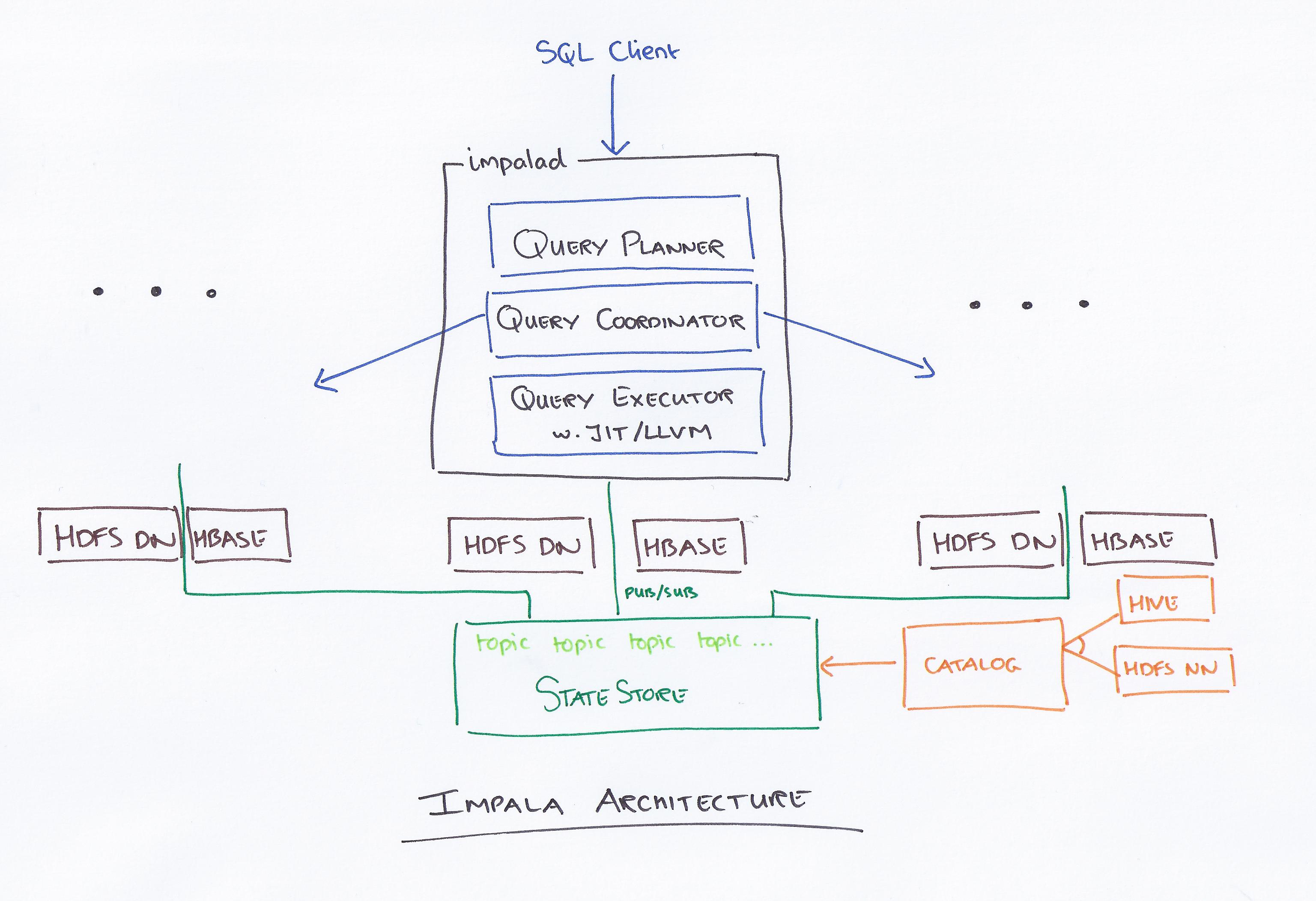
Cloudera が率いる Impala は、新しいクエリ システムです。 Hadoop には HDFS と HBase があるため、そこに格納されている PB レベルのビッグ データをクエリできます。 この技術は、計算用のハイブとメモリ、およびデータ ウェアハウスを考慮したものであり、リアルタイムのバッチ処理と複数の同時処理を提供します。 クライアントは、impalad ネットワーク内のノードにクエリ要求を送信します。そこでは、後続のクライアント操作のためにクエリ ID が返されます。 アナライザーの作成プロセスの最初のステップで、スタンドアロン実行プラン (単一マシン プラン、分散実行プラン) が生成され、結合順序の変更、述語のプッシュ ダウンなどの SQL も実行されます。 すべてのノードは、最新のメタデータ情報のコピーを保持して、ループから取り残されないようにします。 Hadoop、Hive、または Impurbia を使用する前に、まず必要なデータ処理ソフトウェアをインストールする必要があります。
Impala の設定ファイルを変更できます。 すべてのノードは、Impala で構成変更を実行します。 すべてのノードは、MySQL ドライバー パッケージをデータベースに接続する役割を果たします。 ノードは Bigtop の Java パスを変更します。
ハイブとインパラの比較
これら 3 つの主要な違いに加えて、いくつかの小さな違いもあります。 Hive には HiveQL のサブセットがあり、Implicit には HiveQL のサブセットがあります。 Hive と Impala は、それぞれデータ ウェアハウジングと対話型クエリに使用されます。 Impala とは対照的に、Hive は対話型コンピューティングを対象としていません。
Hadoop の Impala とは
Impala は、Hadoop クラスターに格納されたデータ用のオープン ソース SQL クエリ エンジンです。 HDFS、HBase、またはその他のHadoop データ ソースに格納されたデータに対して、高速でインタラクティブな SQL クエリを提供するように設計されています。
Impala は、使い慣れた Hadoop コンポーネントを幅広く採用しています。 INSERT は Impala が読み取ることができる型のデータのみを書き込むことができますが、SELECT は Impala が読み取ることができる型のデータを読み取ることができます。 Avro、RCFile、または SequenceFile ファイル形式を使用する場合、データは Hive にロードされます。 表および列の統計に加えて、表の統計および列の統計を使用できます。 すべての DDL および DML ステートメントは、Impala 1.2 以降では、catalogd デーモンを介して送信された場合、catalogd デーモンを使用して自動的に更新されます。 INVALIDATE METADATA メソッドは、アクセスされたメタストア内のすべてのテーブルのメタデータを返します。 データ ファイルは新しいテーブルのディレクトリに保存され、Impala の実行時にファイル名に関係なく読み込まれます。
全体として、Apache Hive はデータ ウェアハウス プラットフォームとして優れたパフォーマンスを発揮しますが、Impala は並列処理に適しています。 Hive は耐障害性がありますが、Impulsa はそうではありません。
アパッチ インパラ
Apache Impala は、Apache Hadoop 用の高速でインタラクティブな SQL クエリ エンジンです。 これにより、ユーザーは、データの移動や変換を必要とせずに、HDFS および Apache HBase に格納されたデータに対して低レイテンシーの SQL クエリを発行できます。
Impala のアーキテクチャ コンセプトにより、HDFS を使用した対話型クエリを他のどのクエリ エンジンよりも効率的に処理できます。 Hive はディスク I/O 操作のためにはるかに遅くなりますが、Apache はまったく異なるエンジンであるため、はるかに高速です。 Impulsa ははるかに高速なテクノロジを使用し、Presto は同様のアーキテクチャを採用しているため、Impulsa と Presto の間に違いはありません。 Parquet ファイルに関しては、Impala が最高のパフォーマンスを発揮します。 アナリストのクエリに基づいて、どのデータを分割する必要があるかを決定します。 Compute Stats Statistics を使用すると、特に複数のテーブル (結合) が含まれる場合に、クエリがはるかに簡単になります。 Impala カタログ サーバーが 1 週間に 4 回クラッシュし、クエリの完了に時間がかかりすぎました。
さらに、作成するファイルの量は、クエリのパフォーマンスに大きく影響します。 その結果、パーティションの管理を開始し、約 256MB の最適なファイル サイズにマージしました。 各パーティションには 1 つのファイルしかないことが示されています (サイズが 256MB を超える場合を除く)。 Implicit でサポートされているすべてのデータ型の中から、最も適切な列の型を選択する必要があります。 ユーザーがアクセスする同時クエリ数または Y メモリを制限するには、Impala アドミッション コントロールを使用します。 クエリが 30 分以上続いた場合、そのクエリは無効であると見なされます。
ビッグデータに最適なエンジン: Impala
Impala エンジンは、大規模なクラスター用に特別に設計されたHadoop データ処理エンジンです。 Hadoop の標準的な MapReduce エンジンよりもはるかに少ないエネルギーを使用し、消費するリソースも大幅に少なくなります。 Implicit は、分散ファイルシステム HDFS をプライマリ データ ストレージ メディアとして採用し、HDFS の冗長性に依存して、ノードごとにハードウェアまたはネットワークの停止を防ぎます。 テーブル データを表すデータ ファイルは、使い慣れた HDFS ファイル形式と圧縮コーデックによって物理的に表されます。
並列処理クエリ エンジン
並列処理クエリ エンジンは、クエリを並列処理するように設計されたデータベース エンジンの一種です。 これは、複数のプロセッサ、複数のコア、または複数のマシンを使用して実行できます。 並列処理は、特に複雑なクエリの場合、クエリ エンジンのパフォーマンスを大幅に向上させることができます。
マルチプロセッサ コンピューターを使用して、複雑なクエリを同時に実行できる実行プランに変換し、一度に大量のデータを処理できるようにします。 高いパフォーマンスを得るには、クエリの応答時間の短縮やクエリのスループットの向上など、効率的な実行が必要です。 これは、効率的な並列実行手法とクエリの最適化を使用して実現されます。
並列処理: Etl の未来?
高レベルのクエリは、並列クエリ処理を使用してマルチプロセッサ コンピューターで効率的に実行できる実行プランに変換できます。 並列処理では、並列データと分散データを組み合わせる手法と、並列データベース システムによって提供されるさまざまな実行手法が使用されます。 並列クエリ処理は、転送に割り当てられた各ソース テーブル内のレコードのセットを同じサイズのチャンクに分割し、各ソース テーブルに対してデータ変換プロセスをサイクルで実行し、チャンクごとに連続してデータを選択することにより、ETL で実装されます。 .