
NoSQL データベースは、高速データ検索に最適なソリューションです。
公開: 2023-02-09NoSQL データベースは、結合が遅すぎるか、データの重複が多すぎる状況でよく使用されます。 さらに、多くの NoSQL データベースは水平方向に拡張できるように設計されているため、複数のサーバー間で簡単にシャーディングできます。 結合は、すべてのデータを 1 つのサーバーに配置する必要があるため、水平方向のスケーリングにはあまり適していません。
Oracle などの従来のデータベースで使用される一般的な結合演算子は、Oracle NoSQL Database をサポートしていません。 ただし、同じテーブル階層内のテーブル間の別のタイプの結合はサポートしています。 同じ座標を持つ行のみを結合できるため、同じ場所にある行は効率的な結合を可能にする場合があります。
このプロセスでは、JOIN 句で関連する列を使用して、2 つ以上のテーブルの行を結合します。 ほとんどの Oracle NoSQL データベースでは、ユーザーが階層関係が区別されているテーブルからデータを抽出しようとするときに、結合が使用されます。
埋め込みは、MongoDB で一般的に見られるパターンの 1 つです。 正規化は、プロセスの一部が個別のコンポーネントに分割されるときに発生します。 ピースは通常、mongo の単一のドキュメントであるため、結合は必要ありません。
参加しませんか? MongoDB などのドキュメント指向のデータベースは、非正規化されたデータを格納することを目的としています。 コレクション間にはまったく関係があってはなりません。 2 つ以上のドキュメントで同じデータが必要な場合は、繰り返す必要があります。
Nosqlで結合は可能ですか?

はい、nosql データベースでは結合が可能です。 ただし、nosql データベースは多くの場合、よりスケーラブルでパフォーマンスが高くなるように設計されているため、リレーショナル データベースほど一般的ではありません。 結合は、複数の nosql コレクションからのデータを結合するために使用できますが、他の操作よりも高価になる可能性があります。
新しい $lookup 演算子を使用すると、MongoDB 3.2 の $lookup 演算子を使用して、2 つ以上のコレクションに対して left-outer-join 操作を実行できます。 集計は、単純な検索クエリよりも理解が難しく、通常、完了するまでに時間がかかります。 それらは複雑な検索操作において強力で不可欠ですが、脆弱でもあります。 MongoDB の集計クエリは、他のクエリと同じ方法で実行され、パイプライン演算子の配列を渡します。 ドキュメントには、テキスト、日付、および評価情報に加えて、日付、評価、およびそれを書いたユーザーへの参照が含まれています。 現在、ユーザーの評価に基づいて最新の 20 件の投稿を時系列の逆順に表示しています。 $lookup 機能は、MongoDB 3.2 に追加された重要な機能です。
NoSQL データベースで少量のリレーショナル データを使用する場合、より困難な問題のいくつかを克服することが有益な場合があります。 $lookup 演算子は定期的に使用しないでください。 大量のデータが必要な場合は、リレーショナル データベース (SQL) を使用します。
Mongodb は結合に適していますか?

MongoDB の結合機能が MongoDB 3.2 でサポートされるようになりました。これは、MongoDB コレクションの結合操作に対する新しい Lookup 操作の導入のおかげです。
MongoDB は非構造化データの消費を恐れません。 MongoDB 結合をマージ結合およびハッシュ結合と比較すると、マージ結合およびハッシュ結合はまだ実行できません。 ネストされたループをあるインデックスから別のインデックスに結合できるようにするインデックスを提供することで、ルックアップを支援できます。 ただし、「JOIN」のパフォーマンスを劇的に改善するという点では、そうすることができません。 次のクエリでは、MongoDB のグラフィカル ユーザー インターフェイスである Studio 3T の SQL クエリ機能を使用して、次の MongoDB スクリプトを実行します。 結果は、個々の注文数とそれらの注文の合計額を明らかにします。これらは両方とも、個々の顧客と店舗の連絡先の数によって測定されます。 インデックスについては、このノートで説明します。
コレクションから少数のフィールドのみが必要な場合は、これらのフィールドを実際のクエリ基準とともに含む「カバリング インデックス」を使用すると、はるかに優れた結果が得られます。 その結果、売上高のインデックスを作成しました。 個人の ID 番号。 個人に関連付けられたエンティティ ID と売上。 販売用の OrderHeaders これらのタイプのフィールドでは、クラスター化インデックスに似た単一の _id フィールドが使用されます。 結合順序に反映される集約の順序は、Studio 3T での結合の順序を反映するため、実行時間が 4.2 秒短縮されます。 MongoDB と SQL Server は同じサーバーを共有し、後者は 160 ミリ秒で同じMongoDB 集約を管理します。
この場合、請求書から取引の記録を見ています。 それらを変更してはならない正当な理由がいくつかありますが、そうではありません。 MongoDB の調理済みフォーマットで履歴データを準備して維持するだけです。 このような中間コレクションで事前集計することにより、レポートの時間を 25 ミリ秒に短縮します。 コードの完全なサンプルはここにあります: これは、私のマシンで 120 ミリ秒を集計します。これは、関連する手順を考慮すると非常に印象的です。 同様に、営業担当者のレポートも正確でなければなりません。 これは、'sales' と 'positions' という単語を組み合わせて数秒で実行できます。
最初に $null の販売員 (通信販売の顧客) からすべてのレコードを削除することにより、48 ミリ秒ですべてのレコードを削除できます。 最終レポートに必要なドキュメントとすべてのルックアップのリストが揃うまで、並べ替えは延期する必要があります。 開始する前に、マッチングと投影を開始する必要があります。 パイプラインが各ドキュメントを通過するとき、必要なデータのみが入力されるように、パイプラインをスリムに保つことが重要です。 最後に、集約パイプラインでステージが実行される順序を見つけることが重要です。
これにより、2 つ以上のソースからのデータの集約が可能になるため、データ分析を実行する際のオプションの幅が広がります。 さらに、データを特定のカテゴリに分類できるため、データを特定のカテゴリに分類して簡単に見つけることができます。
MongoDB の構造は、多くの点で他のデータベース システムの構造とは異なります。 これにより、データの取得が高速化され、データの管理と保存が向上します。 さらに、より多くのデータに対応できるデータベースの容量により、スケールアップが可能です。
その巨大なパワーにより、MongoDB には他のデータベース システムにはないいくつかの機能があります。 その結果、データ分析とデータ保存のための非常に効率的な方法です。
Mongodb の Join 関数
MongoDB を使用すると、2 つのコレクションを 1 つのデータベースに結合できます。これは非常に人気のある機能です。 MongoDB の結合構文は SQL Server よりも強力であり、結合操作はより効率的です。
ただし、MongoDB はコレクション間のクエリ結合をサポートしていません。 MongoDB では、$lookup 集計関数を使用して結合操作を実行できます。
Nosql を使用すべきではない理由
NoSQL プラットフォームは、動的操作もサポートしていません。 酸特性が一定であるという保証はありません。 たとえば、機密データを扱っている場合は、SQL データベースを選択できます。 さらに、実行時の柔軟性が必要な場合は、NoSQL を避ける必要があります。
データベース NoSQLは、データベース NoSQL と比較して、ストレージ領域が小さく、CPU とメモリが少ないように最適化されています。 また、柔軟性が低く、大規模に使用するとより効果的です。 同じタイプのデータの複数のコレクションは、異常なデータ構造の影響を受けます。 その結果、インデックスと同期ノードの数が増加し、データ量が増加し、それらの更新にかかる時間が増加します。 従来の NoSQL サーバーは、最終的な整合性を維持することを目的としているため、変更が行われる前にインデックスやノードを介して変更を伝達する必要はありません。 一部の NoSQL メンバーは、新しいインデックスの作成を隠す場合があります (たとえば、RavenDB は自動インデックスを作成します)。 また、MongoDB データベース全体をインデックス化せずにスキャンできる人もいます。

NoSQL データベースを使用する場合は、アクセス パターンに合わせて設計する必要があります。 不明な場合や頻繁に変更される場合は、変更が必要になることがあります。 OLAP システムはデータを細分化する必要があるため、ドキュメント指向の NoSQL データベースはアトミックな消費を意図していません。 To Be Continued オプションは、NoSQL のデータ整合性の問題に対処するために使用できます (グラフベースの NoSQL を除く)。 Amazon DynamoDB は、昨年 ACID 準拠になったばかりで、ゲームでは少し遅れていました。
NoSQL データベースには、NoSQL データベースとの SQL 命令の非互換性や、パフォーマンス データに関連するパフォーマンスの問題に対するサポートの欠如など、いくつかの欠点があります。 さらに、noSQL データベースはリレーショナル データベースと同じ仕様に従っていないため、互換性のあるソフトウェアを見つけて使用することがより困難になります。
SQL データベースが Nosql よりも優れている理由
nosql データベースよりも SQL データベースを使用する方が安定して高速です。
同等の Nosql 結合
nosql の結合に直接相当するものはありませんが、同様の結果を得る方法がいくつかあります。 最も一般的な方法は、データを非正規化することです。つまり、複数のドキュメント間でデータを複製します。 これは手動で行うことも、MongoMapper などのツールを使用して処理することもできます。 これを行う別の方法は、map/reduce を使用することです。これはもう少し複雑ですが、より柔軟な場合があります。
リレーショナル データベースへの参加
リレーショナル データベースでの結合操作の類似点は何ですか?
リレーショナル データベースでの SQL 結合は、クエリ、フィルター、およびグループ操作を実行するという点で、パイプライン操作に似ています。
Mongodb が参加
MongoDB Join は、MongoDB が 2 つのデータ コレクションを結合する方法です。 これは、単一の結果を作成するために複数のコレクションのデータを結合する必要がある場合に便利です。 たとえば、結合を使用して、ユーザーのコレクションからのデータを投稿のコレクションと組み合わせることができます。
MongoDB オープンソース NoSQL データベースは、大量のデータを格納するための優れた選択肢です。 従来のデータベースと MongoDB の主な違いは、コレクションとドキュメントではなくテーブルと行を使用することです。 キーと値のペアは、MongoDB の最も基本的な単位の 1 つです。 このブログでは、Join と Lookup の主要なタイプである MongoDB Join の使用方法を紹介します。 MongoDB 3.2 では、コレクションに対して Join 操作を実行できる新しい Lookup 操作が導入されています。 相関サブクエリの構文は、MongoDB 5.0 以降で簡単に使用できます。 MongoDB Join を使用する場合、いくつかの制限事項に従う必要があります。
例として、次のスニペットは、次のドキュメントを使用して、レストランと注文を含むコレクションを作成します:restaurants. これらのコレクションの両方を注文する必要があります。 レストランの名前と住所は? 注文間で名前と配列の一致を指定する必要があります。 以下の順番でドリンクとドリンクが並びます。 以下の結果が提供されます。
Nosql データベース
Nosql データベースは、ほとんどのデータベースで使用されている従来のリレーショナル モデルを使用しないデータベースです。 代わりに、より柔軟なスキーマレス アプローチを使用します。 これにより、よりスケーラブルになり、多くのアプリケーションでの作業が容易になります。
NoSQL データベースのデータは、リレーショナル データベースではなくドキュメントに格納されます。 その機能には、柔軟性、スケーラビリティ、および急速に変化するデータ管理要件に対応する機能が含まれます。 ドキュメント データベース、キー値ストア、幅の広い列のデータベース、およびグラフ データベースは、NoSQL データベースの例です。 Global 2000 の組織は、ミッション クリティカルなアプリケーションを強化するために NoSQL データベースを急速に採用しています。 その理由は、ほとんどのリレーショナル データベースが処理するのが難しすぎる 5 つの傾向があるためです。 リレーショナル データベースは、MongoDB データベースとは異なり、固定データ モデルに基づいているため、アジャイル開発では使用できません。 アプリケーション モデルは、NoSQL を使用する場合のデータ モデルを定義します。
NoSQL は、データのモデリングに固定的な方法を課しません。 ドキュメント指向のデータベースは、通常、データを格納するためのデファクト フォーマットとして JSON で格納されます。 この場合、オーバーヘッドがないため、ORM フレームワークは不要になります。 N1QL (ニッケルと発音) は、SQL を JSON に拡張するために使用できる強力なクエリ言語として、Couchbase Server 4.0 で導入されました。 標準の SELECT / FROM / WHERE ステートメントをサポートするだけでなく、集計 (GROUP BY)、並べ替え (SORT BY)、結合 (LEFT OUTER / INNER) などもサポートできます。 NoSQL 分散データベースの主な利点の 1 つは、そのスケールアウト アーキテクチャと単一障害点がないことです。 Web やモバイル アプリを介してオンラインで行われる顧客とのやり取りが増えるにつれて、サービスの可用性がますます重要な考慮事項になりつつあります。
NoSQL データベースは、インストール、構成、スケーリングが簡単なため、さまざまなアプリケーションに最適です。 本の内容を整理し、メモを書き留め、保管するように設計されています。 また、小さなクラスターから大きなクラスターまで、あらゆるサイズで使用できます。 NoSQL データベースを実行するために別のソフトウェアは必要ありません。 これは分散されており、データ センター間の組み込みのレプリケーションが含まれています。 さらに、ハードウェア ルーターを介した即時のフェールオーバーが可能になるため、アプリケーションは、データベースが障害を検出して独自の復旧を実行するのを待つ必要がなくなります。 NoSQL の人気が高まっており、今日の Web、モバイル、モノのインターネット (IoT) アプリケーションで最も人気のあるデータベース テクノロジとなっています。
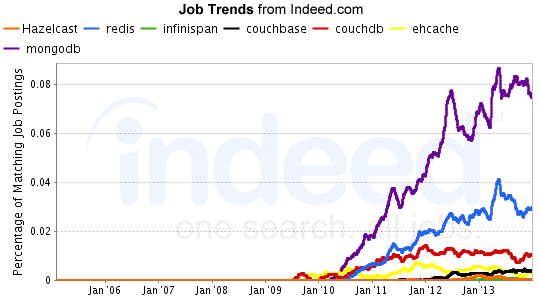
MongoDB は、さまざまな主要指標において明らかにリーダーです。
高い人気と安定性を備えたデータベースを探しているなら、MongoDB が最適です。 市場で最も人気のあるデータベースの 1 つとなる多数の機能を備えているため、多くのアプリケーションで好まれています。 MongoDB は ACID トランザクションをサポートしていないため、決定を下す際にはこのことを念頭に置くことが有益な場合があります。
Nosql データベース: 概要
ドキュメントベースの NoSQL データベースは、JSON と XML の両方の形式でデータを格納できます。 これは、列ベースのストレージ モデルを備えたドキュメント ベースの NoSQL データベースです。 キー値 NoSQL データベースのデータはペアで格納されます。 Redis NoSQL データベースは、キー値データベースの優れた例です。 通常、SQL データベースには、NoSQL データベースのディメンションよりも大きな列が含まれます。 幅の広い NoSQL データベースの例である MongoDB は、人気のある NoSQL データベースです。 データは、グラフベースの NoSQL データベースを使用してグラフに格納されます。 Neo4j は、MongoDB を使用するグラフベースの NoSQL データベースです。
Oracle Nosql データベース
Oracle NoSQL Databaseは、データベース管理をほとんどまたはまったく必要とせずに、高可用性と水平方向のスケーラビリティを提供するように設計された分散キー値データベースです。 Oracle NoSQL Database は、Berkeley DB Java Edition に基づいており、豊富なデータ型のセットを持つ単純なキー値モデルを使用します。
Oracle NoSQL SDK for Spring Data の Spring Data 実装モジュールは、SDK に組み込まれています。 Oracle NoQL DatabaseクラスタまたはOracle NoQL Cloud Serviceへの接続または接続に使用できます。 プロジェクトの pom.xml ファイルに maven 依存関係を組み込むことで、SDK を使用できます。 以下を目安に選んでいただけると便利です。 Oracle Spring は、Oracle.com で入手できます。 NosqlDbConfig で使用されるメソッドは次のとおりです。 エンティティ クラスを定義する必要があります。
Nosql データを格納するためのリポジトリを作成する必要があります。 次に、アプリケーションのメイン クラスを記述します。 org.springframework.boot:spring-boot をインストールすると、すべてのコンポーネントにアクセスできます。