
NoSQL データベース: レプリケーションによる高可用性とスケーラビリティ
公開: 2022-11-19NoSQL データベースにはさまざまな種類があり、それぞれに独自の機能と特徴があります。 ただし、多くの NoSQL データベースに共通する特徴の 1 つは、複数のサーバー間でデータを複製できることです。 レプリケーションとは、あるサーバーから別のサーバーにデータをコピーして、複数のサーバーでデータを使用できるようにするプロセスです。 レプリケーションは、複数のサーバーからデータを読み取れるようにすることで、可用性とパフォーマンスを向上させることができます。 NoSQL データベースは通常、マスター/スレーブ レプリケーション モデルを使用します。このモデルでは、1 つのサーバーがマスターとして指定され、他のすべてのサーバーがスレーブになります。 マスター サーバーはデータのコピーを保持し、変更をスレーブにレプリケートします。 スレーブはデータの読み取りに使用できますが、すべての書き込みはマスターを経由する必要があります。 レプリケーションの利点の 1 つは、読み取りを複数のサーバーに分散することでパフォーマンスを向上できることです。 レプリケーションは、1 つのサーバーに障害が発生した場合にデータの複数のコピーを提供することで、可用性を向上させることもできます。 NoSQL データベースは通常、複数のサーバー間でデータを複製できるため、高可用性とスケーラビリティを提供します。
同様に、NoSQLデータ レプリケーションは、構造化データ、非構造化データ、および半構造化データをシームレスにコピーして保存し、サーバーがクラッシュした場合のデータ損失を防ぐことができる堅牢な機能です。 NoSQL データベースの詳細については、このサイトをご覧ください。
マスター/スレーブ複製とスレーブ実行複製の両方が行われ、マスター/スレーブ複製では、書き込みと読み取りの両方を処理できる権限のあるコピーとしてノードが指定されます。 ピアツー ピアのレプリケーション プロセスにより、ノードは相互に書き込みを行うことができ、各ノードはデータを次のノードにコピーします。
MongoDB レプリケーションとは、共通のデータ セットを他のMongoDB インスタンスと共有するレプリカ セットの作成を指します。 レプリカ セットには、データ ベアリングである多数のノードが含まれており、アービターであるノードはオプションです。 データベアリング環境には 6 つのノードがあり、1 つのメンバーがプライマリ ノードとして指定され、他のメンバーはセカンダリ ノードとして分類されます。
一般に、一定量以上の結果が得られる実験または手順は成功です。 この場合、DNA の複製がコピーまたは複製されます。 何かを複製する行為は、複製と呼ばれます。
Nosql データ レプリケーションとは
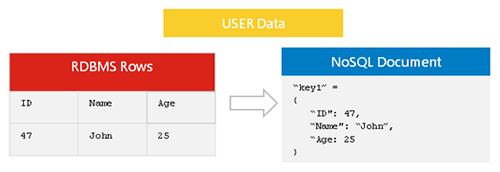
Nosql データ レプリケーションは、あるnosql データベースから別の nosql データベースにデータをコピーするプロセスです。 これは、バックアップの作成や複数のサーバーへのデータの分散など、さまざまな理由で実行できます。 Nosql データ レプリケーションは通常、非同期で実行されます。つまり、データのコピーが元のデータの正確なレプリカである必要はありません。
長年にわたり、データ レプリケーションは、あらゆる組織のデータ インフラストラクチャに不可欠なコンポーネントでした。 データ複製システムは、高可用性、バックアップ、災害復旧を確保することでデータを保護します。 さらに、レプリケーションは、組織がデータの一貫性と正確性を向上させるのに役立ちます。 複製処理によりデータの信頼性を向上させる手法です。 データをレプリケートすることで、データが常に利用可能であり、バックアップされ、災害が発生した場合でも確実にデータを利用できます。 データを複製することで、その一貫性と精度も向上させることができます。 データ インフラストラクチャを設計するときは、データ レプリケーションを考慮することが重要です。
Nosqlのシャーディングとレプリケーションとは?
シャーディングとレプリケーションの違いは何ですか? プライマリ サーバー ノードは、データ レプリケーションの一部として、セカンダリ サーバー ノードからデータをコピーします。 そうすることで、データの可用性を高め、プライマリ サーバーに障害が発生した場合の緊急バックアップにすることができます。 シャード キーを使用して、水平面上のサーバーのスケーリングを管理します。

Nosql データベースにはデータの冗長性がありますか?
かなりの量のデータがあり、データの冗長性が許容できる場合、NoSQL データベースは特定のタイプのアプリケーションと選択的なユース ケースに最適です。
Nosql はシャーディングできますか?
マイクロサービス パターンによるパーティショニングは、NoSQL 環境で使用されます。 このパターンでは、各パーティションを複数のサーバーに分割する必要があります。これらのサーバーは、世界中の同じ場所にある場合とない場合があります。 このスケール アウトは、データ セットのさまざまな部分にアクセスして高いパフォーマンスを達成したい世界中の人々に適しています。
データベースにおけるレプリケーションとは
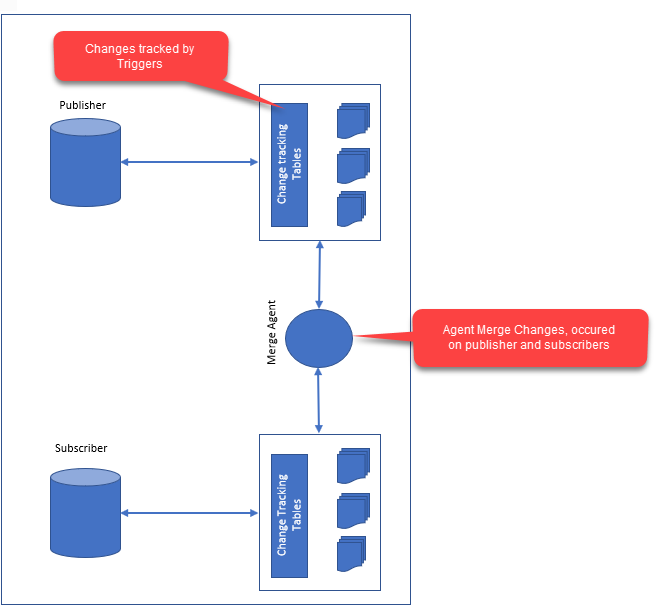
データベースのレプリケーションは、ソース データベースからターゲット データベースにデータをコピーするプロセスです。 2 つのデータベースは、同じサーバー上にあっても、別のサーバー上にあってもかまいません。 レプリケーションを使用して、データのバックアップを作成したり、複数のサーバーにデータを配布したり、複数のユーザーがデータにアクセスできるようにしたりできます。
データの整合性とパフォーマンスは、今日のデータ レプリケーションの重要な側面です。 データの書き換えは、サブスクライバーに送信するのと同じくらい簡単な場合もあれば、一度に複数の実験を行うのと同じくらい複雑な場合もあります。 レプリケーションの最も一般的な形式は、スナップショット レプリケーションです。 大量のデータがある場合、またはサブスクライバーがリモートの場合、データ セット全体をサブスクライバーに送信します。 これは、トランザクション レプリケーションよりも高度な形式のレプリケーションです。 場合によっては、サブスクライバーまたはデータにのみデータの変更を送信します。これは、小さなファイルまたはローカル ファイルで役立つ場合があります。 これは、より複雑なレプリケーション手法です。 パブリッシャーとサブスクライバーの両方で項目を変更できるため、データが大きい場合や、パブリッシャーとサブスクライバーが離れている場合に役立ちます。 したがって、異種データの複製は、さまざまなデータベース製品にアクセスすることが可能です。 これは、パブリッシャーやサブスクライバーなど、複数の種類のマシンを持つ大規模なデータに特に役立ちます。
Mongodb でのレプリケーションとは何ですか?
MongoDB レプリケーションは、複数の MongoDB サーバーのデータ セットを複製する方法です。 これは、レプリカ セットを使用して実現できます。 レプリカ セットは、同じMongoDB データセットを提供し、同じプロセスに関連付けられている MongoDB インスタンスのコレクションです。
レプリカ セットを作成すると、プライマリ ノードが自動的に選択されます。 使用可能になると、セカンダリ ノードがプライマリ ノードになり、レプリカ セットの指定が最も高くなります。 MongoDBレプリケーション セットは、プライマリ ノードとセカンダリ ノードの役割を指定します。両方のノードが使用可能な場合、MongoDB はプライマリ ノードを自動的に構成します。 これは、データ セットとプロセスに関して同一の MongoDB インスタンスのコレクションです。 データベース管理者は、データを複製することでデータの冗長性を提供できます。 データは広く利用可能です。 レプリカ セットは、レプリケーションのためにグループに編成された MongoDB ノードのコレクションです。 レプリケーション セットには、少なくとも 3 つの MongoDB ノードが必要です。3 つのノードのうちの 1 つが、すべての書き込み操作を受け取るプライマリ ノードと見なされます。 最初のレプリカ セットが作成されると、プライマリ ノードが自動的に選択されます。