
NoSQL データベース: シャーディングとレプリケーション
公開: 2022-11-21NoSQL データベースは、水平方向にスケーリングできるため、大規模なデータ ストレージによく使用されます。 これは、単一ノードのハードウェアをアップグレードするのではなく、システムにノードを追加することでスケーリングできることを意味します。 この水平スケーラビリティを実現する 1 つの方法は、複数のノードにデータを分散するプロセスであるシャーディングを使用することです。 レプリケーションは、NoSQL データベースを拡張できるもう 1 つの方法であり、複数のノードでデータのコピーを作成する必要があります。
SQL データベースと NoSQL データベースの両方で、データベース シャーディングの概念はスケーリングにとって重要です。 名前が示すように、データベースはいくつかのチャンク (シャード) に分割されます。
また、NoSQLデータ レプリケーションを使用して、構造化データ、非構造化データ、および半構造化データをシームレスにコピーして保存することで、サーバーがクラッシュしたときにデータが失われないようにすることもできます。 このページにアクセスすると、NoSQL データベースの詳細を確認できます。
リレーショナル データベースは、水平分割とも呼ばれるシャーディング方式を使用して分割できます。 Amazon Relational Database Service ( Amazon RDS ) は、さまざまな機能を提供することでクラウドでの使用を簡単にするマネージド リレーショナル データベース サービスです。
複製方法では、複数のサーバーからデータをコピーし、それを見つけられる場所に配置します。 レプリケーションでは、マスター コピーとスレーブ コピーが作成され、マスター コピーは書き込みデータを処理する正式なコピーになり、スレーブ コピーは書き込みデータを処理する非同期コピーになります。
Nosql はシャーディングを使用しますか?
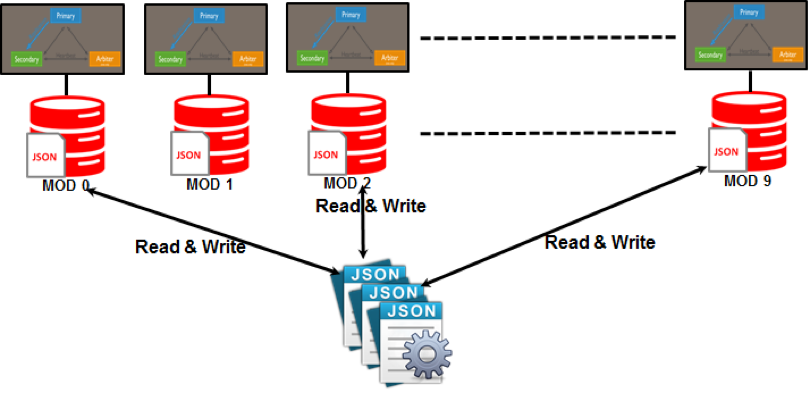
NoSQL では共有などのパーティション パターンが使用されます。 パーティショニングは、ネットワークの残りの部分から独立している可能性が高いサーバーに各パーティションを割り当てるプロセスです。 このスケールアウトにより、可能な限り高いパフォーマンス レベルを維持しながら、多様なデータ セットへのアクセスをグローバル ユーザーに提供できます。
MySQL Cluster がソリューションです。 MySQL Cluster は、ノード間でテーブルを自動的に分割し、データベースを低コストのコモディティ ハードウェア上で水平方向にスケーリングして、SQL を使用するだけでなく、NoSQL API を介して直接、読み取りおよび書き込みの集中的なワークロードを処理できるようにする一連のソフトウェアです。 MySQL Cluster には、ブロックチェーン以外にも使用できる可能性があります。 また、MySQL Cluster を使用してアプリケーションをスケーリングするためにも使用できます。 これは、MySQL Cluster がスケジューリング システムであるためです。 その結果、シャードをいつどのように生成するかを決定することで、アプリケーションをスケーリングできます。 クラウド コンピューティングに依存する必要がないため、これは大きな利点です。 これは、ワークロードが実行されているノードでシャードが生成されるためです。 その結果、必要な並行性の量を制御できます。 その結果、MySQL Cluster は非常に強力な機能セットを備えています。 アプリケーションをスケーリングし、必要な同時実行数を制御するために使用できます。
Nosqlのシャーディングとレプリケーションとは?
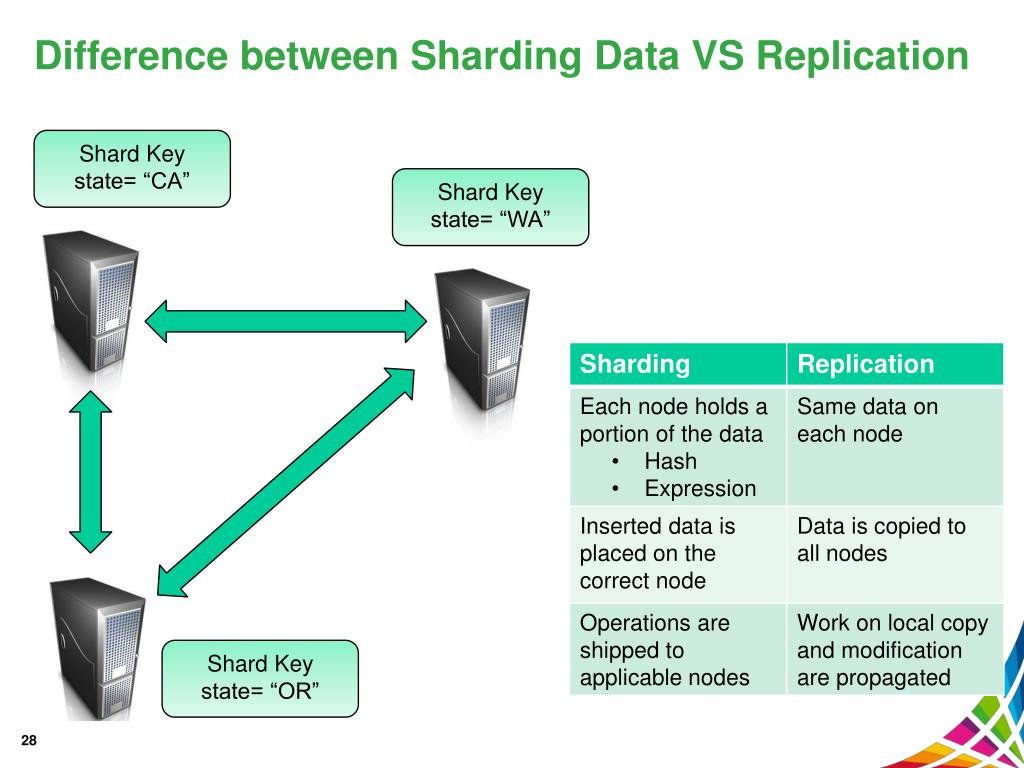
レプリケーションとシャーディングの違いは何ですか? データ複製とは、プライマリ サーバー ノードからセカンダリ サーバーノードにデータを転送することです。 これは、プライマリ サーバーに障害が発生した場合のバックアップとして、データを確実に利用できるようにするのに役立ちます。 この関数は、シャード キーを使用してサーバーを水平方向にスケーリングするために使用できます。
シャーディングの利点
パーティション分割する必要があるが、それをレプリケートするためのリソースが不足しているデータを扱っている場合、さまざまな状況で間隔を空けることが有益な場合があります。 読み取りをスケーリングする必要がある場合はレプリケーションが役立ちますが、データの書き込みはシャーディングを使用するとより効率的に処理できます。 間違ったシャード キーを選択すると、システムのパフォーマンスに悪影響を及ぼす可能性があります。
Mongodb はシャーディングを使用しますか?
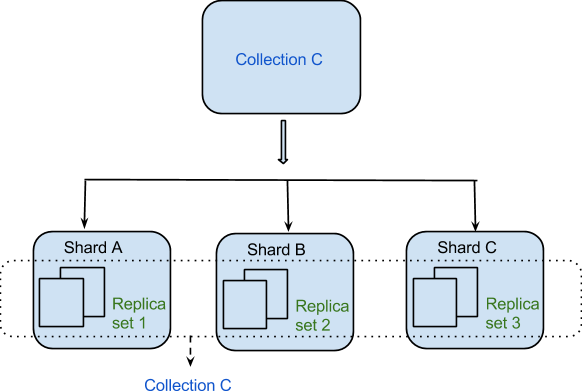
データは、シャーディングによって分散された方法でマシン間で分散されます。 MongoDB はシャーディングを採用して、高レベルのスループットを必要とする大規模な展開をサポートします。 多数のデータ セットまたは高スループット アプリケーションを含むデータベース システム用に単一のサーバーを構築するのは困難な場合があります。
Ranged Sharding の問題を解決するための最も一般的な戦略は、最も一般的な意味でアプローチすることです。 クラスターのルートノードには、クラスターのデータセンターからの距離に基づいて分割できる事前定義された数のシャードがあります。 プライマリ ノードは、データ セットで作成される最初のノードであるため、ルート ノードと呼ばれます。 別のタイプのフラグメントは、二次フラグメントと呼ばれます。 範囲指定またはハッシュ トランザクションの両方が可能です。 特定のシャードのハッシュ キー値によって、生成できるデータの量が決まります。 識別子は、トランザクション内の各データのハッシュ キーによって作成されます。 各戦略には、多数の長所と短所があります。 データセットが大きい場合とは対照的に、データセットが小さい場合は範囲シャーディングを実装する方が簡単で、小さい場合はより効率的です。 データセットが大きい場合、ハッシュはより効率的です。 MongoDB の速度に対する評判は、他の MongoDB サービスへのデータの委任をサポートしているという事実に由来しています。 データ セット フラグメントを MongoDB の複数のサーバーに分散して、データ処理速度を向上させることができます。 MongoDB は、シャーディングに加えて、複数のレプリケーション オプションをサポートしています。 その結果、レプリケーションにより、一連のデータを複数のサーバーに分散して一貫性を維持できます。 情報が常に正確で最新であることを確認するには、データの複製が必要です。 さらに、MongoDB の分散クラスターは、パフォーマンスの向上に役立つ場合があります。 Sraving は、レプリケーションと同じ方法で、あるサーバーから別のサーバーに大量のデータを転送するための手法です。 シャード キーは、あるサーバーから別のサーバーにコピー (または「シャード」) できるデータのアイテムです。 MongoDB のシャード クラスター間でデータを分散するための 2 つの主な方法は、範囲ベースと分散です。 ハッシュは、暗号化されたサーバーを使用して実行できます。 物事を分割することで、複数のことを達成できます。

Mongodb をシャードする必要がありますか?
シャーディングによってパフォーマンスが向上するかどうかは定かではありませんが、場合によってはパフォーマンスが向上することが示されています。 さらに、結果として、シャーディングは、堅牢なバックアップと復元の確保など、独自の一連の課題をもたらします。 シャーディング戦略を決定する前に、そうすることの長所と短所について考える必要があります。
Nosql でのシャーディング
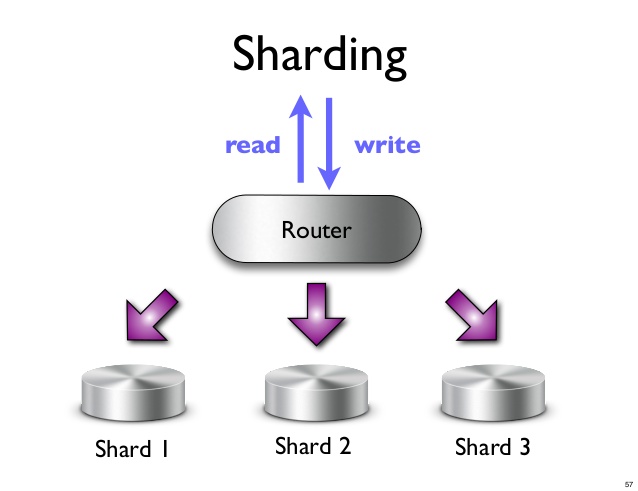
シャードは、データベースまたは検索エンジン内のデータの水平分割です。 各シャードは、独立したデータベースまたは検索エンジン インスタンスです。 NoSQL データベースでは、ドキュメントのコレクションがシャードに分割され、それぞれが個別のサーバーに格納されます。
シャーディングとレプリケーション
レプリケーションとシャーディングの違いは、レプリケーションがデータの複製であるのに対し、シャーディングはデータを個別のチャンクに分割することです。 この場合、シャーディングに基づいてコレクションをいくつかの部分に分割しました。 データベースを取得すると、すべてのデータ セットの画像が得られます。
シャーディングの利点
同時ユーザー数を増やしてパフォーマンスを向上させるために、データは複数のマシンに分割されます。 データは、各マシンの個別のパーティションに保存されます。
Nosql でのレプリケーション
NoSQL データベースでレプリケーションを処理するには、いくつかの方法があります。 1 つの方法は、変更が加えられるたびに、データベースがセカンダリ サーバーに自動的にレプリケートすることです。 これにより、プライマリ サーバーがダウンした場合に備えて、常にバックアップを利用できるようになります。 もう 1 つの方法は、データをセカンダリ サーバーに定期的に手動で複製することです。 これにより、管理者はレプリケーションが発生するタイミングをより詳細に制御できますが、障害が発生した場合にセカンダリ サーバーが最新の状態にならない可能性があることも意味します。
データベースのシャーディングとは
シャーディングは、データベース内のデータを水平方向に分割するプロセスです。 シャーディングでは、データベースはシャードと呼ばれる小さな部分に分割されます。 各シャードは個別のサーバーに保存されます。 シャーディングのプロセスは、負荷を複数のサーバーに分散することで、データベースのパフォーマンスを向上させるのに役立ちます。
シャーディングの助けを借りて、単一のデータを単一のトランザクションで複製できます。 データセットを小さな断片に分割して複数のサーバーに分散させると、システム全体のストレージ容量を増やすことができます。 場合によっては、データが大きく、それを維持するために複数のサーバーが必要な場合に役立ちます。 外部データ ラッパーは、リモート サーバーからデータを読み取るためにも使用され、データ ストレージをさらに柔軟にします。
パーティショニングとシャーディングの違いは何ですか?
パーティショニングとシャーディングは、大量のデータ コレクションを小さなフラグメントに構造化するための 2 つのアプローチです。 シャーディングとパーティションはどちらも、データが複数のコンピューターに分散されていることを意味しますが、それらは別個のものです。 データベース インスタンスを分割する手順では、その中のデータのサブセットをグループ化する必要があります。
シャーディングに最適なデータベースは?
データベースのシャーディングは、Cassandra、HBase、HDFS、MongoDB、Redis でサポートされています。 PostgreSQL、Memcached、Zookeeper、MySQL、および Sqlite をネイティブにサポートしていないデータベースは、データベースと見なされます。 アプリケーションにデータベースのサポートが組み込まれていない場合は、Jarryd ロジックがアプリケーションに存在する必要があります。
SQLでシャーディングは可能ですか?
ただし、範囲ベースのシャーディング (基本的には水平方向) を実装して、アプリケーションに対してより透過的にすることは可能です。 SQL Server でこれを行う一般的な方法は、パーティション ビューを使用することですが、必ずしもそうである必要はありません。