
Pig: Apache Hadoop の高レベル プラットフォーム
公開: 2023-02-22Pig は、Apache Hadoop で実行されるプログラムを作成するための高レベルのプラットフォームです。 「Pig」という用語は、プラットフォームのインフラストラクチャ レイヤーを指し、コンパイラと実行環境、および一連の高レベル オペレーターで構成されます。 Pig のインフラストラクチャ層は、開発者が Pig プログラムを作成、保守、および実行するための一連のツールを提供します。 Pig は、 Apache Hadoop エコシステムの一部であるオープン ソース プロジェクトです。 Pig のプログラミング モデルはデータ フローに基づいているため、大量のデータを処理するプログラムを簡単に作成できます。 Pig プログラムは、有向非巡回グラフで実行される一連の演算子で構成されます。 Pig はスケーラブルで効率的で使いやすいため、大量のデータを処理する場合に最適です。
NoSQL ソリューションとして、データを分析してアクセスするための事前定義された特定の方法が必要です。 SQL (UNION、INTERSECT など) は、ビッグ データの世界ではあまり使用されない一般的なクエリ式です。 Hive はバッチおよびビッグ データ処理用に最適化されているため、すべての行を操作することをお勧めします。 Hive は、スケールの利点がある Hadoop よりも運用に費やす時間と費用がはるかに少なくて済みます。 開発システムでの小さなクエリでさえ、RDBMS での同様のクエリよりも桁違いに遅くなる可能性があります。 Hive はクエリ結果をキャッシュしません。 MapReduce では、繰り返しクエリを再送信するのが一般的です。
Hive には次の 2 つのタイプがあります。1) Hive はデータベースではありません。 むしろ、クエリ データに固有の SQL 部分をサポートするクエリ エンジンです。b) Hive は SQL をサポートするデータベースです。c) Hive は SQL 固有のデータベースです。 Hive は Hadoop 用の SQL ベースのデータ ウェアハウス システムで、Pig や Python などが含まれます。 Hive は、 Hadoop データの格納に使用されます。
豚はSQLですか?
個人の主観によるので、この質問に正解・不正解はありません。 pig が sql であると信じている人もいれば、そうでない人もいます。 最終的に、pig が sql であるかどうかを決定するのは個人次第です。
今日、 Apache Hiveと Pig は、急速にビッグ データの代名詞になりつつある 2 つの用語です。 これらのツールを使用すると、データ開発者とアナリストはそれらを使用して MapReduce の複雑さを軽減しながら、高レベルのデータ整合性を維持できます。 Hive は、ETL (抽出、読み込み、および変換) ツールとしても知られるデータ ウェアハウス インフラストラクチャです。 Apache Hive、Pig、および SQL は、データ分析と管理のための 3 つの一般的なツールです。 どのプラットフォームがニーズに最適で、どのくらいの頻度で使用する必要があるかを認識しておく必要があります。 これら 3 つのテクノロジのコンテキストで、Hive、Pig、および SQL を使用する 3 つの異なる方法を見てみましょう。 Apache Hive と Apache Pig が優勢であるにもかかわらず、SQL は依然としてビッグ データの管理と分析の王様です。 それぞれが特定の機能を実行するため、要件はビジネスに合わせて調整されます。 Apache Pig はスクリプトに基づいており、特別な知識を必要としますが、Apache Hive は開発者にとってネイティブな唯一のデータベース ソリューションです。
豚は柔軟性に優れた多才な動物です。 たとえば、Pig は、JSON または XML データを含むログファイルを処理して、データを読み取ることができます。 Web サービスからのデータを Pig に保存することもできます。
マップ データ型、タプル、およびバッグ データ型は、同じ意味で使用できます。 あらゆるソースからのデータを処理できます。
Pig は ETL ツールですか?
ETL ツールをどのように定義するかによって異なるため、この質問に対する決定的な答えはありません。 一般的に言えば、ETL ツールは、1 つ以上のソースからデータを抽出し、ターゲット システムと互換性のある形式に変換して、そのシステムにロードするのに役立つソフトウェア アプリケーションです。 pig はこれらすべての機能を実行できるため、ETL ツールであると言う人もいます。 他の人は、データ変換用に特別に設計されていないため、pig は ETL ツールではないと主張するかもしれません。 最終的に、この質問に対する答えは、ETL ツールの独自の定義によって異なります。

Pig を Etl 処理にどのように使用できますか?
Pig アプリケーションはETL トランザクション モデルとして記述できます。これは、プロセスがオブジェクトからデータを抽出し、ルール セットに基づいてデータストアに変換する方法を記述します。 ユーザーは、ファイル、ストリーム、およびその他のソースからデータを取り込むために、Pig のユーザー定義関数 (UDF) を定義します。
ピッグツールとは?
Pig と呼ばれるプラットフォームまたはツールは、大規模なデータセットを処理します。 このライブラリには、MapReduce プロセスでデータを処理するための高度な抽象化が含まれています。 Pig Latin は、データ分析コードを開発するためのコーディング プロセスで使用される高レベルのスクリプト言語です。
Pig と Sql の違いは何ですか?
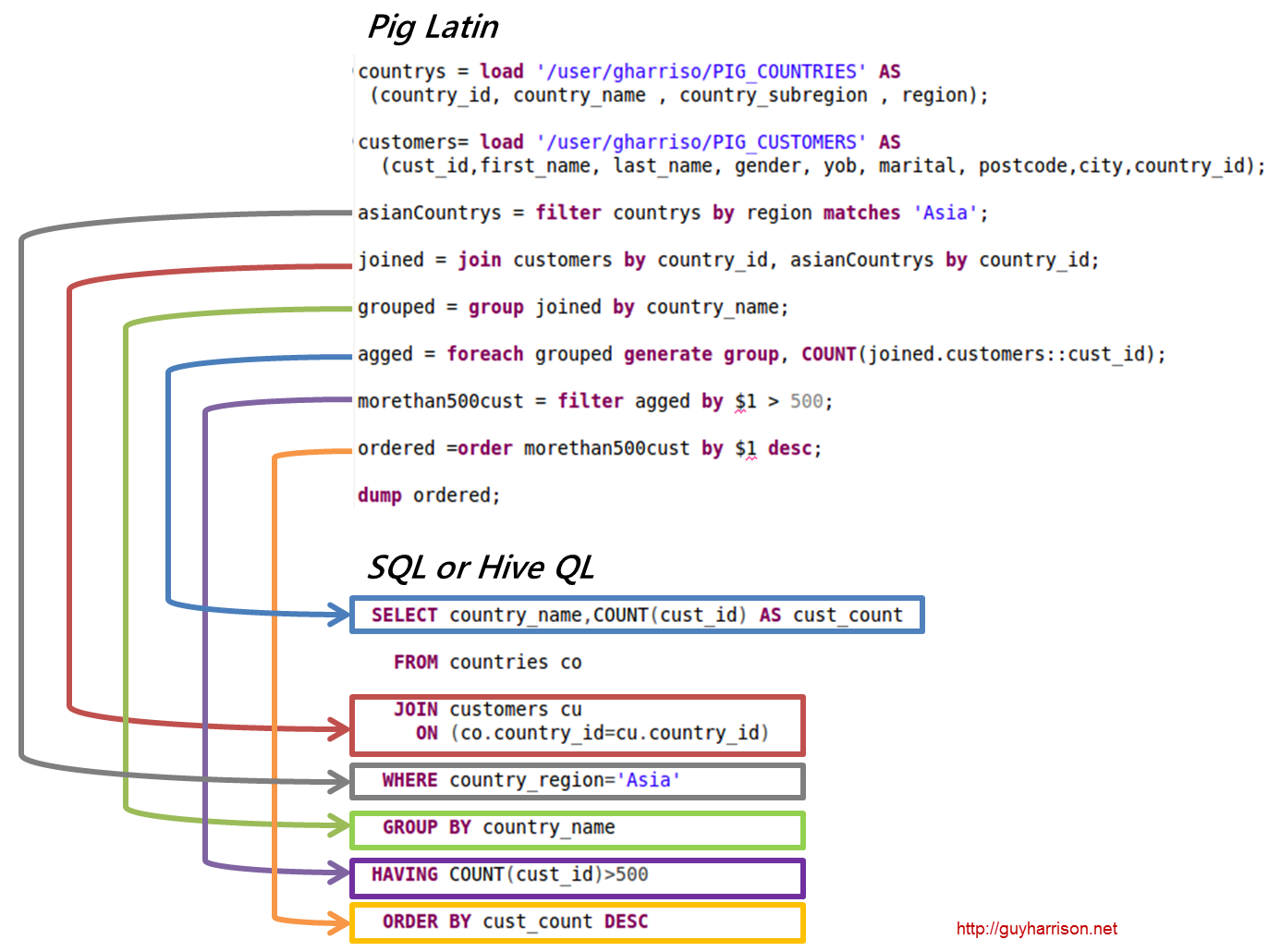
SQL Pig Latinと Apache Pig は手続き型言語です。 SQL は、本質的に宣言型のスクリプト言語です。 スキーマを使用するかどうかは、完全に Apache Pig 次第です。 スキーマを必要とせずにデータを格納できます (値の型は $、$ などに格納されます)。
Pig は Hadoop の一部ですか?
Pig Hadoop アプリケーションは、大規模なデータセットの分析に使用できる高レベルのプログラミング言語です。 Yahoo! の Pig Hadoop プロジェクトは、最初の Hadoop プロジェクトの 1 つです。 一般に、Hadoop の実行時に大量のデータ管理作業を実行します。
大規模データ分析の分野では、Pig Hadoop は高水準のプログラミング言語です。 Apache Pig を使用してデータを分析するには、まず Pig Latin を使用してスクリプトを作成する必要があります。 MapReduce タスクに変換されるスクリプト。 これは、Apache Pig 拡張機能である Pig Engine を利用することで実現されます。 以下の手順に従って、Apache Pig を Linux/CentOS/Windows に (VM または Cloudera 経由で) インストールできます。 最初のステップは、Apache Pig をダウンロードしてインストールすることです。 2 番目のステップは、bashrc ファイルを使用して Apache Pig 環境変数を変更することです。
ステップ 3 で、 Pig のバージョンを確認します。 このファイルは、移動後に別のディレクトリに保存できます。 5 番目のステップは、Pig コマンドをクリックして Grunt Shell (Pig Latin の実行に使用されるスクリプト) を起動することです。
Pig Latin がデータ分析に最適な高水準スクリプト言語である理由
Pig Latin のデータ分析コードは、高水準のスクリプト言語で記述されています。 これは、データ フローを並列処理することを目的とした SQL に似た言語です。
アパッチ豚の例
Pig は、Apache Hadoop で実行されるプログラムを作成するための高レベルのプラットフォームです。 このプラットフォームの言語は Pig Latin と呼ばれます。 Pig は、MapReduce、Tez、または Spark で Hadoop ジョブを実行できます。 Pig Latin は、プログラミングを Java MapReduce イディオムから表記法に抽象化し、MapReduce プログラミングを容易にします。 たとえば、次の Pig Latin ステートメントは上記の Java MapReduce コードと同等です。 A = LOAD 'mydata' USING PigStorage(',') AS (id:int, name:chararray, age:int, gpa:float); ダンプ A;