
Solr – 強力な検索プラットフォーム
公開: 2022-11-18Solr は、大量のデータを非常に迅速に照会できる強力な検索プラットフォームです。 これは、Apache Lucene 検索ライブラリーの上に構築され、アプリケーションとの統合を容易にする REST のような API を提供します。 Solr の重要な機能の 1 つはそのスケーラビリティです。何十億ものドキュメントとクエリを簡単に処理できます。 Solr は、従来のリレーショナル データベース モデルを使用しないため、NoSQL データベースと呼ばれることがよくあります。 ただし、Solr は従来のデータベースではないため、従来のデータベースとして使用しないでください。 データの保存用ではなく、インデックス作成と検索用に設計されています。 データを保存する必要がある場合は、MongoDB や Cassandra などの NoSQL データベースを使用する必要があります。
Elasticsearch は Solr と競合できる唯一のオープン ソース プロジェクトであり、Solr は世界で最も人気のある 2 つのオープン ソース検索エンジンの 1 つです。 NoSQL は Not Only SQL の略で、データベースだけでなく、従来の SQL とは別のクエリ言語を使用することを意味します。 その優れた全文検索機能にもかかわらず、Solr は NoSQL データベースで非常に役立ちます。 ヘルス データは、古い Explorys および Worklist アプリケーションを介して HBase から直接抽出されました。 Solr は Worklist に 3 つの重要な機能を提供しました。非常に使いやすく、機能は非常に直感的でした。 フィルタリングとソートのプロセスは非常に効率的です。 Solr のフィルター処理はドキュメント ID とキャッシュに基づいているため、フィルター基準を満たすドキュメントの数をほぼ瞬時に計算できます。
Solr は、他のビッグ データ サービスと頻繁に組み合わせられる優れた NoSQL データベース ソリューションです。 パラメーターrows=0 を Solr に送信してフィルターの追加と構成に取り組んでいるユーザーに、すぐにフィードバックを提供しました。 関連性の高い検索エンジンを作成するには、 Solr スキーマを維持するだけでなく、それ以上のことを考慮することが重要です。
Solr をデータベースとして使用できますか?
はい、Solr をデータベースとして使用できます。 これは、データの索引付けと検索に使用できる強力な検索エンジンです。 データを構造化された形式で保存し、すばやく取得するために使用できます。
検索インデックスをデータベースとして使用することは間違っていますか? 私の場合、いくつかの基本的なデータ要素を Solr に格納するという同様のアイデアがありました。 しかし、Solr のアップグレード プロセスは私の考えを変えました。私が間違っていたことを認めなければなりません。 2 つのメジャー バージョンをアップグレードしたが、インデックスを再作成しなかった場合 (たとえば、元のドキュメントを削除してからインデックス ファイル自体を削除した場合)、コアは認識されなくなります。
Algolia、Elastic Observability、Coveo、および Yext は、Apache Solr に代わる人気のある代替手段のほんの一部です。 Algolia は自然言語検索エンジンであり、自然言語で人やトピックについて知っていることに基づいて検索クエリを分析および処理します。 Elastic Observability は、データとアプリケーションにリアルタイムのデータ インサイトを提供するデータ プラットフォームです。 検索エンジン マーケティング プラットフォームである Coveo を使用すると、検索エンジン マーケティングの取り組みをターゲットにして測定することができます。 Yext を利用することで、検索エンジン マーケティング キャンペーンの対象を絞り、測定することができます。
Nosql データベースとは?
Nosql データベースは、従来のリレーショナル データベース モデルを使用しないデータベースです。 代わりに、キー値データベース、ドキュメント データベース、カラム型データベース、グラフ データベースなど、さまざまなモデルを使用しています。
ドキュメントベースの NoSQL データベースは、リレーショナル データベースと同じ方法でデータを保存します。 データ管理ソフトウェアは、適応性と拡張性が高く、現代のビジネスのニーズにタイムリーに対応できるように構築されています。 ドキュメント データベース、キー値ストア、幅の広い列のデータベース、およびグラフ データベースは、NoSQL データベースの種類のほんの一部です。 世界の 2000 大企業の大半は、ミッション クリティカルなアプリケーションを強化するために NoSQL データベースを急速に採用しています。 これに関連して、5 つのトレンドが、大多数のリレーショナル データベースにとって対処が難しすぎる技術的課題をもたらしています。 固定データ モデルのため、リレーショナル データベースはアジャイル開発の大きな障害となっています。 アプリケーション モデルは、NoSQL のデータ モデルを定義します。
データの構造に関係なく、データは NoSQL モデルでモデル化する必要があります。 JSON 形式は、ドキュメント指向データベースにデータを格納するためのデフォルトです。 ORM フレームワークはこの方法で縮小でき、アプリケーション開発のオーバーヘッド コストを削減できます。 N1QL (ニッケルと発音) は、Couchbase Server 4.0 の一部としてリリースされた SQL-to-JSON クエリ言語です。 このツールは、集計 (GROUP BY)、並べ替え (SORT BY)、結合 (LEFT OUTER / INNER)、およびその他のさまざまな機能もサポートしています。 スケールアウト アーキテクチャを備え、単一障害点がなく、運用上の優れた利点を備えた NoSQL 分散データベースは、最も魅力的な機能の 1 つです。 Web やモバイル アプリを介してオンラインで行われる顧客とのやり取りが増えるにつれて、可用性が問題になります。
NoSQL データベースは簡単に習得して使用できます。 それらは、情報を保存し、本を書き、読むことを目的としています。 また、さまざまなサイズのクラスターを任意のサイズで管理および監視することもできます。 分散 NoSQL データベースに含まれる組み込みのレプリケーションは、データベース自体によって提供されます。追加のソフトウェアは必要ありません。 さらに、ハードウェア ルーターにより、重要なデータへの即時かつ一貫したアクセスが保証されます。 データベース管理者が問題を調査している間、アプリケーションは、データベースが問題を発見するのを待ってから独自の回復を実行する必要はありません。 NoSQL テクノロジは、今日の Web、モバイル、および IoT アプリケーションのプラットフォームとして人気を集めています。
NoSQL データベースの人気が高まっている理由は数多くあります。 大規模な組織のニーズに合わせて拡張でき、適応性があります。 例として、Ryanair と Marriott を MongoDB のクライアントと考えてください。 これらの組織は、MongoDB を使用してモバイル アプリや予約システムを強化するだけでなく、Web サイトを強化するためにも使用しています。 同社の Presto コンテンツ管理システムも NoSQL で構築されています。 このシステムは、会社独自のコンテンツの効率的な管理に役立ちます。
仕事の未来 仕事の未来はリモートです
Nosql データベースでないのはどれ?
NoSQL データベースと非 NoSQL データベースの違いは何ですか? 同社のリレーショナル データベース管理システムである Microsoft SQL Server は、主要な製品です。
2000 年代後半、NoSQL データベースによって、スケーリング、高速なクエリ結果、およびプログラミングの容易化に重点が置かれました。 NoSQL データベースは、柔軟なデータ モデル、スケーラブルなデータ モデル、使いやすいユーザー インターフェイスを備えているため、簡単に作成できます。 SQL (Structured Query Language) リレーショナル データベースは通常、厳格で複雑な表形式のスキーマと、非常に大きな垂直方向のスケーリングで構成されています。 MongoDB の 4.0 リリースにはマルチドキュメント ACID トランザクションのサポートが含まれ、4.2 リリースにはシャード クラスターのサポートが追加されました。 リストにデータ モデルがありません。 ほとんどの NoSQL データベースでは、データの複製ではなく、クエリが最適化されています。 さらに、一部No.
NoSQL データベースは、ストレージのフットプリントを削減するために圧縮をサポートしています。 たとえば、グラフ データベースは関係の分析には役立ちますが、毎日のデータの取得にはあまり便利ではない場合があります。 ユース ケースで MongoDB または別のデータベースを使用する方法については、MongoDB を使用する場所のホワイト ペーパーで説明します。 MongoDB Atlas を出発点として使用することは、NoSQL データベースを学習する最も簡単な方法の 1 つです。 MongoDB University では、MongoDB の学習を支援する完全無料のオンライン トレーニングを提供しています。
ただし、NoSQL データベースにはいくつかの欠点があります。 NoSQL データベースは、ACID フリーであるだけでなく、リレーショナル データベースと同じ特性を持っていません。 システムがそれらに依存している場合、アプリケーション内のトランザクションは問題を引き起こす可能性があります。 さらに、NoSQL データベースは通常、SQL データベースと同じレベルの実行時の柔軟性を提供しません。 アプリケーションでデータ モデルを動的に変更する必要がある場合は、NoSQL データベースの使用を避ける必要があります。
次のうち、データベースでないものはどれ?
すべてのクエリ、レポート、およびテーブルはデータベースに関連しているため、リレーションシップはデータベース オブジェクトではありません。 それらは数学に関連しています。
Mongodb は Nosql データベースですか?
MongoDB NoSQL データベース管理プログラムはオープン ソースであり、無料で使用できます。 NoSQL 言語は、従来のリレーショナル データベースに代わるものです。 NoSQL データベースは、大規模なデータ分散に優れています。 ドキュメント指向の情報は、ドキュメント管理ツールである MongoDB を使用して管理、保存、または取得できます。
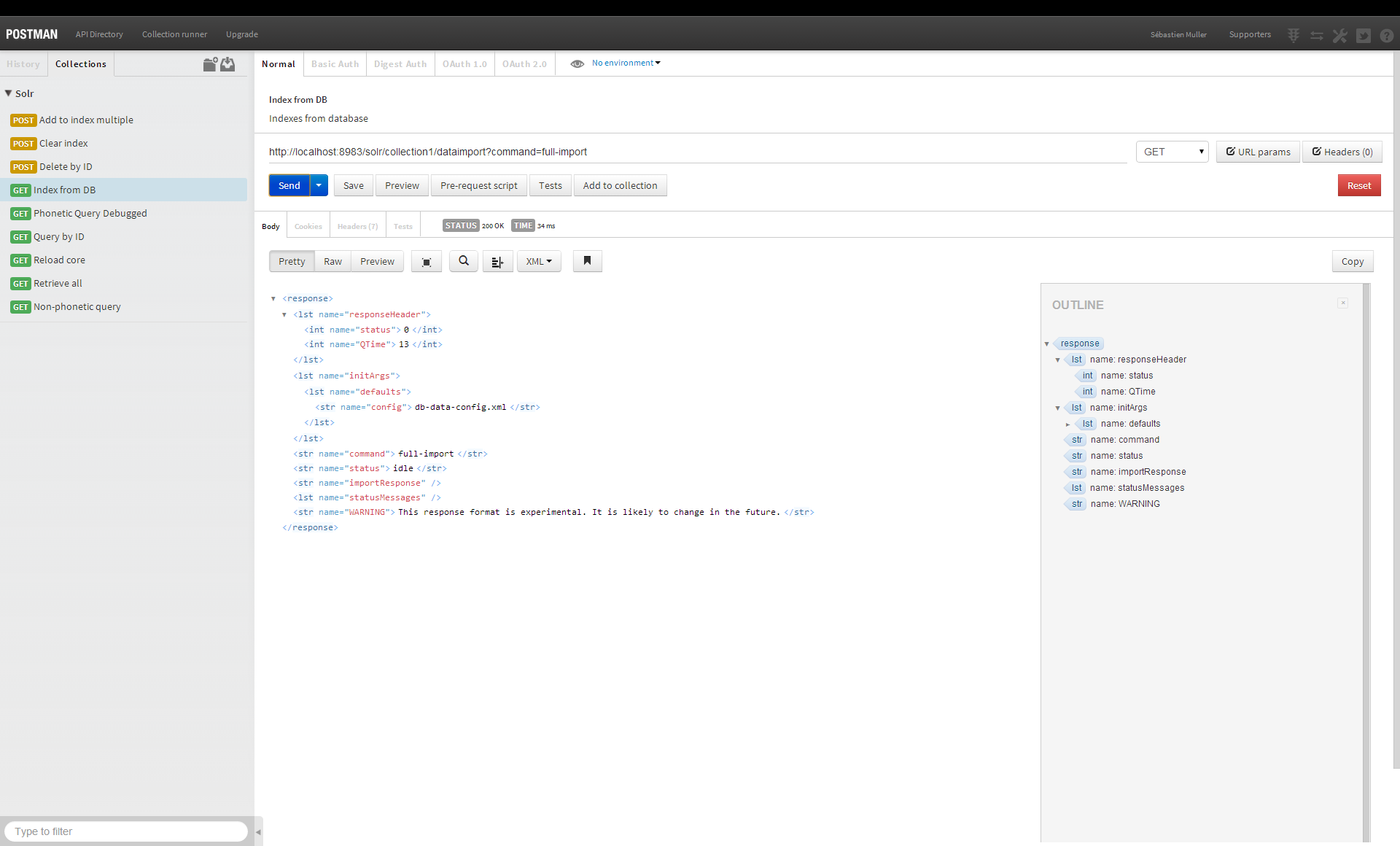
Solrはデータをどのように保存しますか
Apache Solr は、その名前が示すように、ローカル ファイル システムのデータにインデックスを付けます。 HDFS (Hadoop Distributed File System) の結果として、ユーザーは、冗長性とフェイルオーバー機能を備えた大規模な分散ストレージなど、さまざまなメリットを享受できます。 Apache Solr には、HDFS のサポートが含まれています。
他の多くの検索エンジンとは異なり、Solr はテキストを直接検索するのではなくインデックスを検索するため、すぐに結果を生成できます。 本の巻末の索引を読み取ることで、索引からキーワードに関連するページを検索できます。 このインデックスは、データ ディレクトリと呼ばれるディレクトリ内のインデックスとしてデータ ディレクトリに格納されます。 Solr 検索エンジンは、オープンソースの全文検索エンジンである Lucene を利用しています。 Solr と Lucene の関係は、自動車とそのエンジンの関係に似ています。 この記事では、Lucene と Solr の違いについて詳しく説明します。

Sol で格納されたフィールドを使用する方法
ドキュメントのフィールド形式は、Solr で使用されます。 ドキュメントには、単なるデータの集まりである何らかの形式のフィールドが含まれる場合があります。 Solr を使用してドキュメントを検索すると、インデックスが作成されたドキュメント内のすべてのフィールドの一致が結果に含まれます。
保存されたフィールドは、検索する必要はないが、何かを検索するときに表示する必要があるフィールドです。 Solr では、これらは格納されたフィールドとして知られています。 Solr は、インデックス作成アルゴリズムの結果としてすべての格納されたフィールドにインデックスを付けるため、ドキュメントを検索すると、Solr はすべての格納されたフィールドを含む結果を返します。
フィールドを格納することには多くの利点があります。 結果リストにドキュメントのタイトルを表示する場合は、タイトルをファイルとして保存する必要がある場合があります。 これまでに検索したすべてのドキュメントを同じ ID で見つけられるようにしたい場合は、複数回検索してドキュメントの ID を追跡できます。
フィールドを格納して検索結果を表示することもできます。 ラベルが付けられている場合、文書のタイトルが結果リストに表示されることがあります。 複数のサイトでドキュメントを検索して簡単に見つけられるように、ドキュメント ID を表示することもできます。
Solr の機能には、データのインデックス作成と保存の機能が含まれます。 文書に索引を付けるために、Solr は最初に文書内のすべてのフィールドのデータベースを作成する必要があります。次に、各フィールドの位置に関する情報が保存されます。 この種の情報から結果を検索して表示できます。
強力な検索機能に加えて、Solr では強力なドキュメント検索アプリケーションを使用できます。 クエリに基づいてユーザーにデータを提供する場合、それはユーザーのクエリに基づいています。
Solr データベースのチュートリアル
solr データベースは、 solr ソフトウェアを使用してデータのインデックス作成と検索を行うデータベースの一種です。 これは、大量のデータの索引付けと検索を非常に迅速に行うために使用できる強力なツールです。
このチュートリアルは Solr 8 で検証されているため、古いバージョンでも動作する可能性があります。 id フィールドは、すべての Lucene および Solr で既に定義済みであるため、正しい方法でインデックスを作成できるフィールドのタイプを理解する必要があります。 動的フィールドは、事前に定義しなくてもオンザフライで作成できるため、いつでも変更できます。 Solr が全文検索に使用するLucene ライブラリは、新しい詳細がクエリに提示されるように定期的に更新する必要がある特定時点のスナップショットを採用しています。 データ形式にとらわれない JSON または XML とは対照的に、Solr はデータ形式にとらわれません。
Java で Solr 検索エンジンを使用する方法
Solr サーバーに接続するには Java クライアントが必要なので、org.apache.solr.client.solrjimpl ファイルを使用します。 HttpSolrServer プロトコルを使用するクラスは、HttpSolrServer という名前です。 このクラスは、Java Socket を使用して Solr サーバーと通信します。 Solr サーバー アプリケーションを作成するときは、最初に適切なクラスをロードする必要があります。 たとえば、Java では、org.apache.solr.client.solrj.impl ファイルを使用してSolr 検索機能にアクセスできます。 org.apache.solr.client.solrj.request クラスは、SolrServer クラスのコンポーネントです。 このクラスは RequestHandler クラスを作成します。 この強力な検索エンジンにより、必要な情報を簡単に見つけることができます。 Solr サーバーにアクセスするには、Java クライアントを使用します。
Solr対Lucene
Apache プロジェクトの Solr と Lucene に関して言えば、それらは同じコンポーネントで構成されています。 一方、Apache Solr はスタンドアロン サーバーですが、多くの高度な機能を備えています。 一方、Apache Lucene は、データのインデックス作成 (格納) と検索を行う Java ライブラリ ベースのソリューションです。
キャッシュがあるため、Solr は静的データ フィールドに利点があり、結果の取得が容易になります。 時系列データは、時系列データに加えて、フィルターとグループ化機能を使用する Elasticsearch によって頻繁に処理されます。
Solr対Elasticsearch
この質問には、個人のニーズと好みに依存するため、決定的な答えはありません。 ただし、Solr と Elasticsearch の主な違いには次のようなものがあります。
-Solr は従来のリレーショナル データベース モデルに基づいていますが、Elasticsearch はドキュメント指向のアプローチを使用しています。
-Solr は通常、大規模なデータ セットのインデックス作成と検索に高速ですが、Elasticsearch は一般にスケーラブルです。
-Solr は、結合やネストされたオブジェクトなどのより高度なクエリ機能をサポートしていますが、Elasticsearch はより単純なクエリ構文を備えています。
両方のテクノロジに貢献する大規模なコミュニティがあり、専門家による支援が利用できます。 Elasticsearch は、以前は Apache 2.0 として知られており、オープン ソースでした。 2021 年のバージョン 7.11 のリリース以降、Elasticsearch は Server Side Public License の下で無料で使用できるようになります。 これは、情報の取得や分析を必要とする企業レベルのテキスト検索を対象としています。 Elasticsearch では全文検索も可能で、PDF や Word などのリッチなドキュメントを読むことができます。 Elasticsearch は Solr よりも多くのヒープ メモリを必要とします (1 GB 対 512 MB) が、これらのデフォルトは変更できます。 Elasticsearch プラットフォームでは、クラスターのリバランスとデータ クレンジングを組み合わせることで、より多くの自動化が可能になります。
シャーディングは、Solr と Elastic でサポートされている複数のサーバーにデータを分散する方法です。 Solr と ElasticSearch はどちらも、大規模で関与するコミュニティと同様の機能を備えた人気のある検索エンジン データベースです。 Elasticsearch は Solr よりもユーザー フレンドリーで、スケーリングが容易で、優れた分析機能とクエリ機能を備えています。 両方のデータベースで使用できる Apache Tika ライブラリを使用すると、全文検索を実行し、豊富なドキュメントを読み取ることができます。
Apache Solr の使用法
ドキュメントや電子メールの添付ファイルのインデックス作成と検索、および複数の Web サイトのインデックス作成と検索ができるため、Web サイトだけでなくエンタープライズ検索でも人気のあるツールです。
検索アプリの作成に使用されるオープンソースの検索プラットフォームです。 これは、人気のある全文検索エンジン Luceneに基づいています。 Solr は、エンタープライズ運用の準備ができている、クラウドネイティブで柔軟性の高いプラットフォームです。 並列クエリは、2016 年にリリースされた Solr の最新バージョンである Solr 6.0 で有効になりました。Solr プラットフォームを使用すると、大規模な (ビッグデータ) アプリケーションのインデックスをスケーリング、配布、および管理できます。 Solr を使用する場合、Java スキルを持つプログラマーである必要はありません。 Lucene の代わりに、オートコンプリートを含む検索ボックスを作成するための非常にシンプルで使いやすいサービスを提供します。
Apache Sol の多くの利点
Apache Solr 検索エンジンは、大小の組織の間で人気のある検索エンジンです。 このソフトウェアは非常に汎用性が高く、データ分析やデータ検索など、さまざまな状況で使用できます。 Solr は、エンタープライズ検索機能を提供するサービスであり、大量のデータを管理するための理想的な選択肢です。
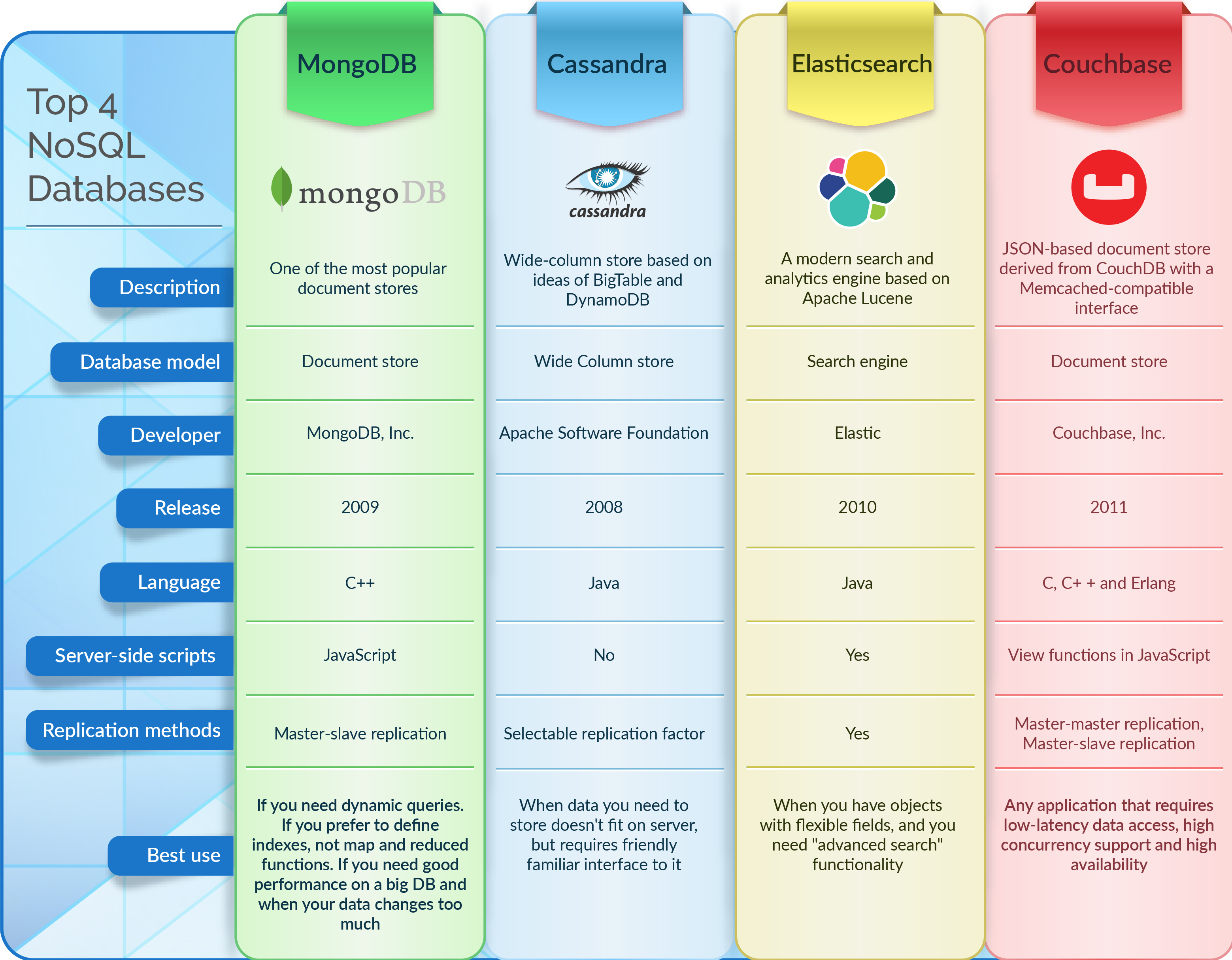
便利な Nosql データベース ソリューション
今日利用できる有用な NoSQL データベース ソリューションは数多くあります。 NoSQL データベースは、多くの場合、従来のリレーショナル データベースよりもスケーラブルでパフォーマンスが優れています。 また、通常は柔軟性が高く、データ モデリングとスキーマの進化が容易になります。 一般的な NoSQL データベースには、MongoDB、Cassandra、HBase などがあります。
今後、開発者は NoSQL データベースを使用しなくなります。 これらのデータベースが、一般的なアプリケーションを強化するための共通のツールとなる未来がここにあります。 一部の一般的なアプリケーションが NoSQL データベースで実行されること、および NoSQL がこれらのアプリケーションに最適である理由に気付いていない可能性があります。 1996 年、Forbes はビジネス誌として初めて Web サイトを立ち上げました。 Forbes は、1 億 4000 万人のオンライン ユーザーのニーズを満たすために、サービスを MongoDB Atlas に移行しています。 COVID-19 パンデミックの影響により、出版物はクラウド インフラストラクチャに移行し、困難な時期に対処することができました。 BangDB は、Accenture のリード スコアリング アプリケーションの NoSQL データベースとして選ばれました。
Facebook Messenger は、Cassandra NoSQL データベース上で動作し、単一障害点がないため、複数のプラットフォームにわたって運用を拡張できます。 Bigtable は、さまざまな Google Mail トランザクションを提供するオンライン企業である Google Bigtable を支援する Google Mail のコンポーネントです。 Espresso データベースは、すべての LinkedIn アプリケーションが正常に機能することを保証します。 BangDB を無料でダウンロードして、それが適切なツールであるかどうかを確認してください。
Nosql データベースの利点
多くの NoSQL データベースを使用して、構造化データ、半構造化データ、および非構造化データを 1 つのデータベースに格納およびモデル化できるため、データ構造とセマンティクスの格納およびモデル化に最適です。 従来のリレーショナル データベースよりも優れたパフォーマンスと安定性を実現でき、開発者にとって実装が容易になります。 NoSQL データベースの人気が高まっているため、今後も人気が高まる可能性があります。
モンゴッド »
MongoDB は強力なドキュメント指向のデータベース システムです。 インデックスベースの検索機能を備えているため、データをすばやく簡単に取得できます。 MongoDB はスケーラビリティ機能も提供し、大規模なデータを処理できるようにします。