
NoSQL データベースをクエリするさまざまな方法
公開: 2022-11-22Nosql データベースは、さまざまな方法でクエリされます。 一般的なクエリ方法には、キー別、ドキュメント別、列別、グラフ別があります。
NoSQL データベースは、リレーショナル データベース以外の形式でデータを格納できます。 ドキュメント タイプにはキー値フォームとワイド カラム フォームが含まれ、グラフ フォームにはグラフ フォームが含まれます。 2000 年代後半の NoSQL データベースの台頭は、ストレージ コストの劇的な低下によって促進されました。 開発者は、これらのシステムの結果として大量の非構造化データを保存できるため、スケールアップおよびスケールダウンが可能になります。 ドキュメント データベース、キー値データベース、ワイド カラム ストア、およびグラフ データベースは、NoSQL データベースのほんの一例です。 より迅速な結果を得るために、参加をスキップできます。 多くのユースケースは、非常に重要 (例: 金融データ)、楽しい (例: スマートな猫用トイレからの IoT 測定値の保存)、さらにばかげた (例: スマートなトイレからの財務データの保存) の 4 つのカテゴリに分類できます。チュートリアルでは、いつ、なぜ NoSQL データベースを使用する必要があるかについて説明します。
さらに、NoSQL データベースに関するいくつかの誤解を見ていきます。 データベース エンジニアによると、MongoDB は世界で最も人気のある非リレーショナル データベースです。 このチュートリアルを使用して、コンピューターにソフトウェアを必要とせずに MongoDB データベースにクエリを実行する方法を学習します。 MongoDB データベースは、ファイルのコレクションであるクラスターに格納されます。 クラスターを作成するとすぐに、データを Atlas に保存し始めることができます。 好みに応じて、Atlas Data Explorer、MongoDB Shell、または MongoDB Compass でデータベースを手動で作成することができます。 この例では、Atlas のサンプル データセットをインポートします。
NoSQL データベースには、柔軟性、水平方向のスケーリング、超高速のクエリ、および開発者にとっての使いやすさに加えて、多くの利点があります。 新しいドキュメントの挿入、既存のドキュメントの編集、または既存のドキュメントの削除を行うには、データ エクスプローラーを使用します。 集計は、大量のデータを分析するための強力なツールです。 Atlas と Atlas Data Lake のユーザーは、Atlas と Atlas Data Lake を使用して簡単にグラフでデータを表示できます。
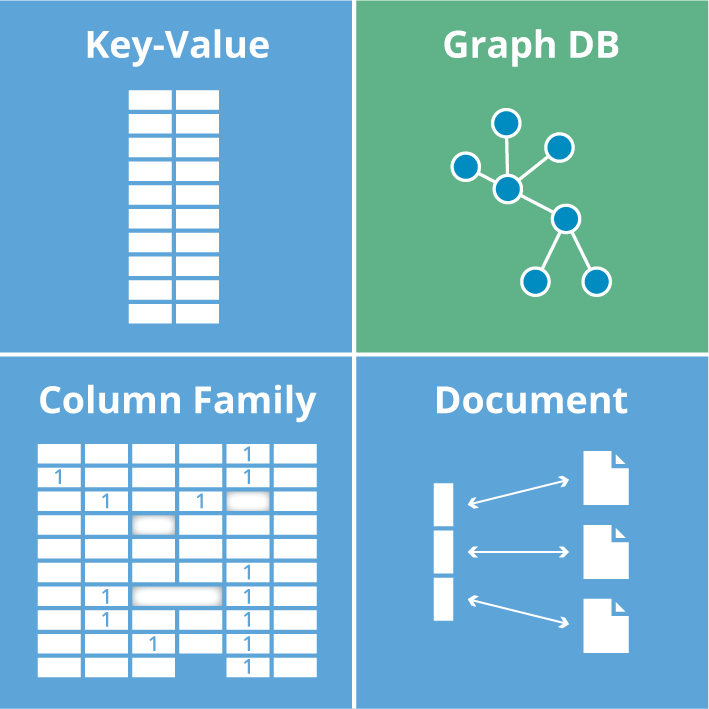
NoSQL データベースは、リレーショナル データベースと同じ方法でドキュメントではなくデータを保存します。 その結果、それらは「SQL だけではない」として分類され、さまざまな柔軟なデータ モデルに分解されます。 NoSQL データベースは、純粋なドキュメント データベース、キー値ストア、ワイドカラム データベースの 3 つのタイプに分けることができます。
非リレーショナル データベース (NGDB) は、リレーショナル データベース (RDBMS) とは異なります。 SQL クエリ言語を使用して、フィールドを持つ一連のオブジェクトを含む任意のデータベースにクエリを実行できます。 NoSQL データベースは、含まれている NoSQL データベースの 1 つです。
NoSQL データベース (SQL データベースだけではない) は、リレーショナル データベースとは対照的に、リレーショナル データ モデルを使用しません。 NoSQL データベースは、リレーショナル データベースとは異なり、SQL クエリ言語を使用せず、代わりに代替言語を使用します。
検索インデックスは、ノード内とリモート検索サービス経由の 2 つの方法でNoSQL システムに保存できます。 NoSQL システムをサポートするノードでは、通常、データとインデックスは同じ順序で格納されます。 一方、NoSQL システムの中には、全文ファイルを検索する際に外部検索サービスを使用するものがあります。
Nosql データはどのようにクエリされますか?
nosql データを照会する方法はいくつかあります。 1 つの方法は、MapReduce プログラミング モデルを使用することです。 MapReduce を使用すると、マッパー関数とリデューサー関数を記述してデータを処理できます。 nosql データをクエリするもう 1 つの方法は、Apache Giraph のようなグラフ処理フレームワークを使用することです。 Giraph を使用すると、グラフを走査して特定のデータを見つけるプログラムを作成できます。

最近まで、データ モデルとクエリ システムは密接に関連していました。 その結果、データ モデルからクエリ メソッドを抽象化しながら、開発者の生産性を優先するデータベース システムを作成できます。 SABRE は、航空券の発券効率を向上させるために IBM とアメリカン航空が共同で取り組んだ、世界初の商用データベースです。 NoSQL データベースは 2005 年から 2017 年にかけて進化し、クエリ可能性を犠牲にしてスケーラビリティ、アップタイム、冗長性、柔軟性、および柔軟性に対応しました。 これは SQL が期待する使いやすいアドホックな宣言型クエリではありませんが、Riak と MongoDB のオプションとして mapreduce も追加されています。 簡単にスケーリングできるデータベース システムを構築している場合、クエリは後回しにする必要があります。 ドキュメント データベースでは、XQuery と Jsoniq はどちらも階層ドキュメントを操作するように設計されています。
XML を使用する MarkLogic、およびデータ モデルに合わせて調整された XQuery サブセットを使用する ArrangoDB とは対照的に、どちらのデータベースも独自のスーパーセットを使用して XML を実装します。 どちらの言語もディスクに保存されたデータに深く関わっており、どちらもかなりの商用利用が見られます。 ドキュメント データベースは、関連する 2 つのクエリ言語で構成されています。 Couchbase の N1QL クエリ言語 (非一次形式クエリとも呼ばれます) は、構造が SQL に似ています。 関係が強制されないという事実にもかかわらず、相互に依存するドキュメントを作成して保存します。 Couchbase と Cassandra はどちらも、インデックス作成とクエリ機能を向上させるために、インデックスを開発し、この非リレーショナルな方法でデータをクエリするために解析しました。
Nosql はどのようにデータを保存および取得しますか?
Nosql データベース システムは通常、大量のデータの保存と取得に使用されます。 多くの場合、従来のリレーショナル データベース システムよりも高速でスケーラブルです。 Nosql データベースはスキーマレスにすることができます。つまり、定義済みのスキーマは必要ありません。 これにより、多くのアプリケーションでより柔軟で使いやすくなります。
データ ジャーナリストとして、私はますます多くの大規模なデータセットに遭遇してきました。 一般に、Excel は、10,000 行未満のデータセットなど、小規模なデータセットに適したツールです。 NoSQL は、近年、従来のデータベースに代わる実行可能で魅力的な代替手段として浮上しています。 この入門書では、NoSQL システムがデータベースに適している理由について説明します。 NoSQL データベースはテーブルを使用する必要がないため、より高速な代替手段になります。 NoSQL は、ネストされたデータ構造を提供します。 行と列の不一致を処理する必要はありません。
NoSQL データベースでデータ モデルを作成できるため、必要な労力が軽減されます。 この例では、education-portal という私のデータベースを調べる方法を示します。 コレクションに移動したら、show collections と入力してリストを表示します。 次の構文でプロパティを表示します。 *ウェイタン。 次のコマンドを使用して、MongoDB データベースに新しいユーザーを挿入できます。 データベースに one() を挿入します。 ターミナルにリストされているため、新しいオブジェクトは正常に作成されました。 括弧を空白のままにしないと、端末はユーザー コレクションに入力されたすべてのユーザーを一覧表示します。 この例と他の NoSQL データベースでは構文に多少の違いがある場合がありますが、これらの違いは重要ではありません。