
더 나은 제품 추천을 위해 선험적 알고리즘 사용
게시 됨: 2018-10-05이 기사에서는 효과적인 제품 추천 방법(소위 장바구니 분석)에 대해 알아봅니다. 특별한 알고리즘(Apriori 알고리즘)을 사용하여 세트로 판매할 제품을 배웁니다. 다른 제품의 웹사이트에서 어떤 제품을 추천해야 하는지에 대한 정보를 얻을 수 있습니다. 이런 식으로 상점의 평균 장바구니 값을 높일 수 있습니다.
지능형 제품 추천 - 교차 판매
온라인 상점에서 매출을 높이는 방법 중 하나는 관련 상품을 추천하는 것입니다.
불행히도 이러한 권장 사항의 가장 일반적인 구현은 동일한 범주의 제품을 표시하는 것입니다. 보고 있는 제품 아래에 이러한 유형의 다른 제품(예: 기타 신발 제안)이 있습니다.
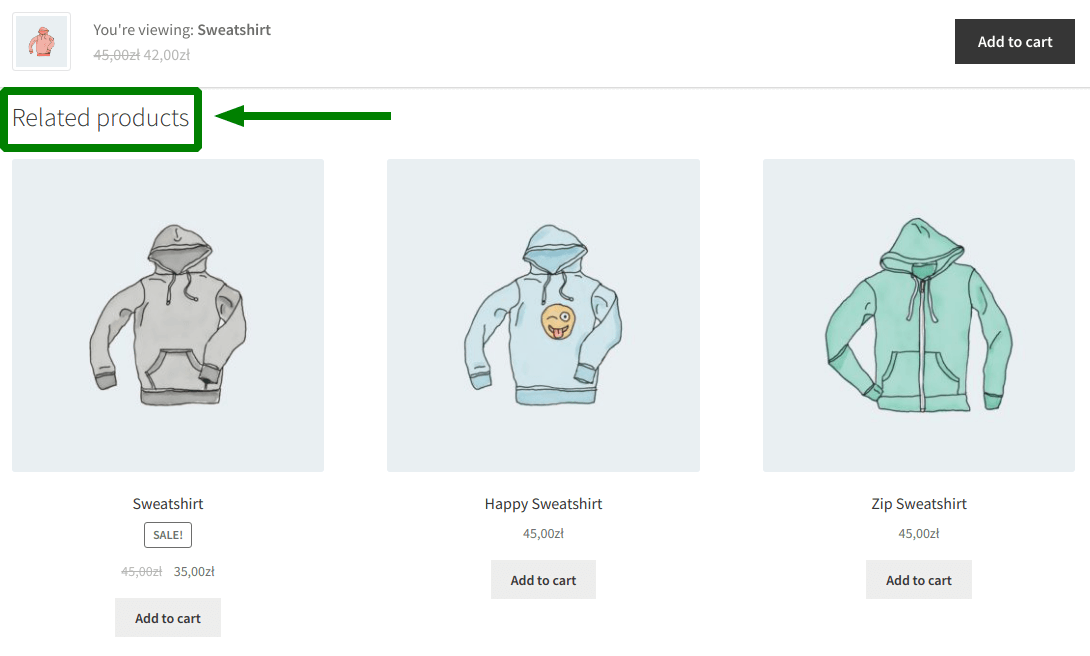
그러나 제품 간의 관계는 상점에 추가된 공동 범주에서 비롯되지 않습니다. 고객이 이미 한 켤레를 장바구니에 넣었을 때 다른 신발을 추천하는 것은 의미가 없습니다. 이런 식으로 우리는 이것이 효과가 있는지 맹목적으로 추측합니다. 고객이 장바구니에 다른 것을 추가할 수도 있습니다.
제품 추천의 본질은 고객이 분명히 관심을 가질 만한 제품을 제공하는 것입니다. 이러한 제품이 무엇인지 어떻게 알 수 있습니까? 통계 덕분에! 그것의 도움으로 우리는 제품 A를 구매하는 대부분의 고객이 B와 C를 구매한다는 것을 알 수 있습니다. 이 경우 우리는 A를 장바구니에 담은 고객에게 B와 C를 추천합니다. 이러한 종류의 제품 추천은 장바구니 페이지에서 가장 잘 작동합니다.
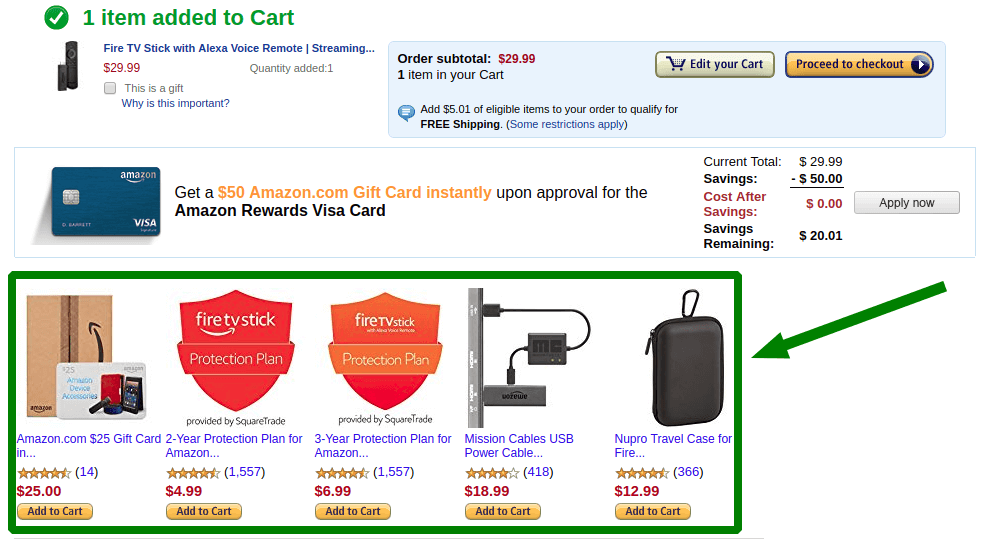
이러한 방식으로 구매하는 고객은 다른 품목을 구매할 수 있다는 정보를 얻습니다. 우리는 특정 구매 경향을 인식하고 후속 고객에 대한 구현을 촉진합니다.
편리한 인터페이스 덕분에 후속 고객은 주문에 추가 제품을 추가할 것입니다. 장바구니의 가치가 높아집니다. 상점은 더 많이 벌 것입니다. 모든 사람이 행복하다 :)
이러한 상향 판매의 경우 상향 판매된 제품에 대해 할인을 적용할 수 있습니다. 이렇게 하면 구매에 대한 고객 만족도가 높아집니다.
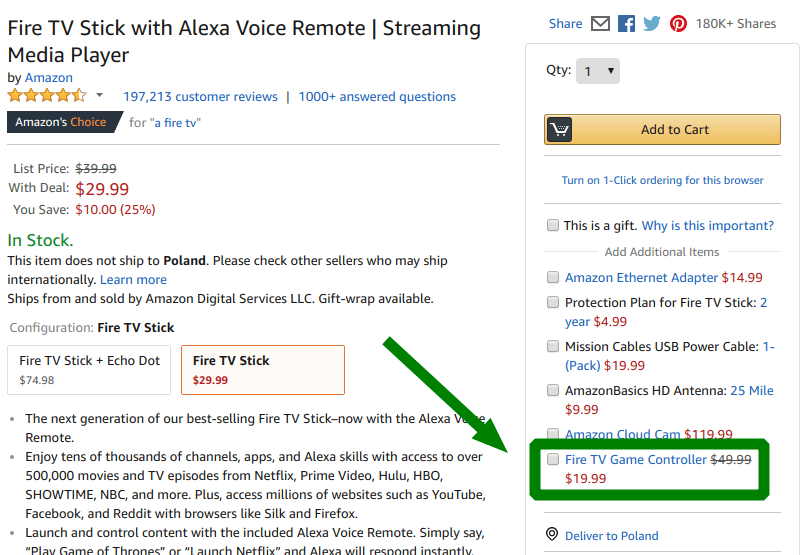
간단히 말해서 선험적 알고리즘
장바구니 분석이란?
질문 - 제품 추천을 위해 제품 주문에서 유용한 데이터를 가져오는 방법은 무엇입니까? 정답은 이른바 카트 분석입니다. 데이터 마이닝 방법입니다.
카트 분석을 위한 효율적이고 인기 있는 알고리즘은 Apriori 알고리즘입니다. 이 알고리즘은 데이터를 마이닝하는 방법과 데이터의 유용성을 평가하는 방법을 정의합니다.
고객 장바구니에 있는 제품의 모든 상관 관계가 권장 사항에 사용되는 것은 아닙니다. 1000년에 1번의 경우가 발생했다면 상점 수준에서 그러한 권장 사항을 구현하는 것은 의미가 없습니다. 이것은 추세가 아니라 단일 사례입니다.
효과적인 구현의 예
온라인에서 우리는 카트 분석이 1990년대에 Wal-Mart에서 사용되었다는 정보를 찾을 수 있습니다. 미국에서 가장 큰 대형 슈퍼마켓 체인 중 하나입니다. 카트 분석 덕분에 맥주와 기저귀의 강한 관계가 발견되었습니다. 데이터 마이닝으로 인해 이러한 이상한 상관 관계가 발생합니다.
요점으로 가자. 맥주와 아기 기저귀는 종종 금요일 밤에 젊은이들이 구입했습니다. 이 지식 덕분에 분석가는 상점에 변경 사항을 도입했습니다. 첫째, 그들은 이러한 제품을 더 가깝게 둡니다. 둘째, 마케팅 활동을 수정했습니다. 대형 슈퍼마켓은 제품에 대한 모든 판촉 및 할인을 적용합니다. 금요일에는 두 제품 중 하나만 할인하기로 결정했습니다. 대부분의 경우 둘 다 어쨌든 구입합니다. 이러한 방식으로 매장은 추가 매출을 얻고 마케팅 활동을 절약할 수 있었습니다.
전통적인 상점 분석에 사용되는 많은 원칙과 방법은 전자 상거래에도 적용될 수 있습니다. 그들 중 일부는 구현하기 더 쉽습니다. 클릭, 트래픽, 사이트에서 보낸 시간 등 온라인 상점을 쉽게 모니터링할 수 있습니다. 추천 시스템을 개선하기 위해 장바구니에 있는 제품의 데이터를 사용하는 것도 가치가 있습니다.
여기에서 좋은 예가 아마존입니다. 주문의 20% 이상이 다양한 유형의 추천 시스템을 통해 생성됩니다.
기본 컨셉
Apriori 알고리즘은 제품 간의 관계를 보여줄 뿐만 아니라 설계 덕분에 중요하지 않은 데이터를 거부할 수 있습니다. 이를 위해 두 가지 중요한 개념을 소개합니다.
- 지원 - 발생 빈도
- 자신감 - 규칙의 확실성
알고리즘을 통해 이 두 지표의 최소값을 결정할 수 있습니다. 따라서 우리는 권장 사항에 대한 품질 가정을 충족하지 않는 거래를 거부합니다.
이 알고리즘의 작업은 반복적입니다. 우리는 한 번에 모든 데이터를 처리하지 않습니다. 덕분에 알고리즘은 데이터베이스의 계산 수를 제한합니다.
알고리즘의 실제 동작을 보여드리겠습니다. Apriori 알고리즘의 핵심 요소인 지지 와 확신 의 사용에 대해 설명하겠습니다.
Apriori 알고리즘의 작동 원리
예를 들어 초기 가정
단순화된 예를 사용하겠습니다. A, B, C, D라는 4개의 제품이 매장에 있다고 가정해 보겠습니다. 고객은 다음과 같은 7개의 트랜잭션을 수행했습니다.

- A, B, C, D
- 에이, 비
- B, C, D
- 에이,비,디
- 나, 다
- CD
- 비, 디
우리는 Apriori를 사용하여 제품 간의 관계를 결정할 것입니다. 지원 으로 값을 3으로 설정했습니다. 이는 규칙이 주어진 반복에서 3번 발생해야 함을 의미합니다.
첫 번째 반복
첫 번째 반복을 시작하겠습니다. 우리는 제품이 주문에 얼마나 자주 등장했는지 결정합니다.
- A - 3번
- B - 6회
- C - 4번
- D - 5회
이 제품들은 각각 3번 이상 주문에 등장했습니다. 모든 제품은 지원 요구 사항을 충족합니다. 다음 반복에서 각각을 사용할 것입니다.
두 번째 반복
이제 두 제품 세트를 기반으로 제품에서 연결을 찾습니다. 우리는 고객이 한 주문에 두 개의 선택한 제품을 함께 넣는 빈도를 찾습니다.
- A, B - 3회
- A, C - 1회
- A, D - 2회
- B, C - 3회
- B, D - 4회
- C, D - 3회
보시다시피 {A, C} 및 {A, D} 세트는 지원 가정을 충족하지 않습니다. 3회 미만으로 발생합니다. 따라서 다음 반복에서 제외합니다.
세 번째 반복
다음과 같은 세 가지 제품으로 구성된 세트를 찾습니다.
- 고객 주문에서 발생
- 집합 {A, C} 및 {A, D} 자체를 포함하지 않음
따라서 {B, C, D}의 집합입니다. 주문으로 두 번만 발생하므로 지원 가정을 충족하지 않습니다.
결과
우리의 가정은 다음 세트를 충족합니다.
- A, B - 순서대로 3번 발생
- B, C - 3번도
- B, D - 4회
이 예는 알고리즘의 작동을 설명하기 위한 것일 뿐입니다. 대부분의 온라인 상점의 경우 데이터 계산이 훨씬 더 복잡해질 것입니다.
백분율로 표시되는 지원
지원 이 모든 트랜잭션에서 규칙의 전역 공유를 정의한다는 점을 추가할 가치가 있습니다. 우리는 최소 요구 사항을 숫자 값으로 지원 하기로 동의했습니다. 3. 그러나 백분율을 설정할 수 있습니다. 이 경우:
- A, B는 약 42.9%에 해당하는 지지도를 가지고 있습니다. 7건의 거래에 대해 3번 발생합니다.
- B, C는 동일한 지원
- B, D는 약 57.14%에 해당하는 지지도를 가지고 있습니다. 7개의 트랜잭션에 대해 4번 발생합니다.
이 예에서 지원 요인의 높은 비율은 적은 수의 제품에서 비롯됩니다. A, B, C, D의 4가지 상품만 있습니다.
예를 들어, 1000개의 제품이 있는 상점에서 주문의 절반에 항상 두 개의 동일한 제품이 있을 가능성은 거의 없습니다.
이 예는 의도적으로 단순화되었습니다. 상점에서 알고리즘을 사용할 때 이를 고려해야 합니다. 매장, 업종 등 개별적으로 지원의 최소값을 설정해야 합니다.
최종 결론
자신감 의 문제가 남아 있습니다. 초기 집합이 발생한 모든 규칙에 대해 주어진 규칙의 발생을 지정합니다.
그것을 계산하는 방법?
{A, B} - 주문 3회 발생 초기 세트는 A입니다. 이 제품도 3회 주문으로 등장했습니다. 따라서 신뢰는 100%입니다.
이 쌍을 미러 이미지로 만들어 보겠습니다. {B, A} 주문이 3번 발생했습니다. 여기서 변경된 사항은 없습니다. 쌍은 동일합니다. 그러나 초기 세트가 변경됩니다. B입니다. 이 상품은 6건의 거래가 발생했습니다. 이것은 50% 수준에서 우리에게 자신감을 줍니다. 제품 A는 제품 B가 발생한 트랜잭션의 절반에서만 발생했습니다.
- A와 B는 100% 신뢰
- B와 A는 50% 신뢰
- B와 C는 50% 신뢰
- C와 B는 75% 신뢰
- B와 D의 신뢰도는 66.7%입니다.
- D와 B는 80% 신뢰
단순화된 예(제품 4개, 거래 7개)는 다음 권장 사항을 제공합니다.
- 에이 -> 나
- 나 -> 디
- C -> B
- 디 -> 나
여기서 첫 번째 제품은 사용자가 장바구니에 추가하는 제품입니다. 두 번째는 이것이 우리가 추천하는 것입니다.
결론
장바구니 분석은 상품 추천 시스템에 매우 효과적인 방법입니다. 그러나 위의 알고리즘에 따른 수동 데이터 처리는 상상할 수 없습니다. 특히 대형 매장에서는 더욱 그렇습니다.
효과적인 카트 분석을 위해서는 편리한 구현이 필요합니다. Apriori 알고리즘은 수동 데이터 처리가 아닌 프로그램 원칙에 따라 작동해야 합니다.
네트워크에는 Python으로 Apriori 알고리즘이 구현되어 있습니다.
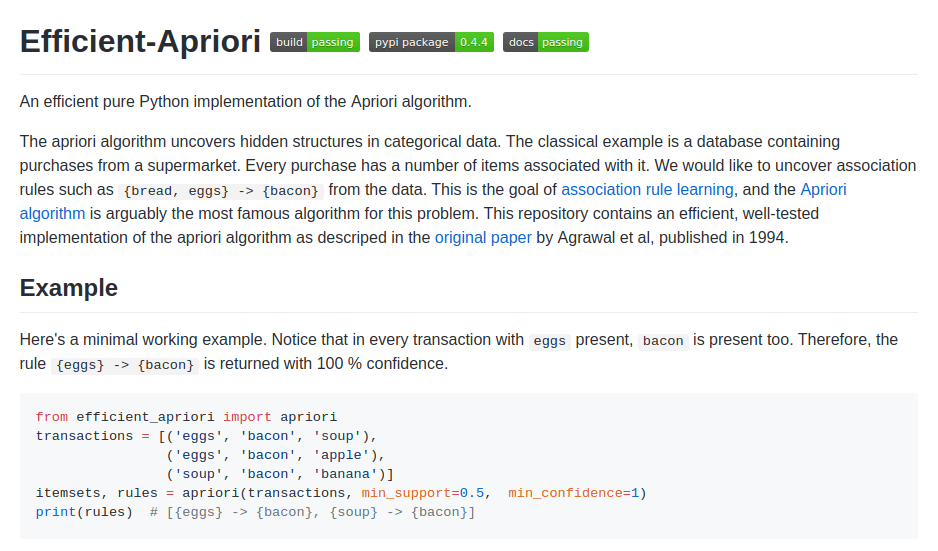
그러나 스크린샷에서 볼 수 있듯이 이를 사용하려면 프로그래밍 기술이 필요합니다.
또한 전자 상거래 팁을 확인하십시오 →