
Google의 Bigtable: 가장 널리 사용되는 열 기반 데이터 저장소
게시 됨: 2022-12-19Bigtable은 Google에서 만든 열 기반 데이터 저장소입니다. 높은 수준의 유연성으로 많은 양의 데이터를 처리하도록 설계되었습니다. Bigtable은 Google에서 10년 이상 사용되어 왔으며 Gmail, Google 지도 및 YouTube를 비롯한 많은 서비스의 기반이 되었습니다. Bigtable은 최초의 열 기반 데이터 저장소는 아니지만 확실히 가장 널리 사용되고 잘 알려져 있습니다.
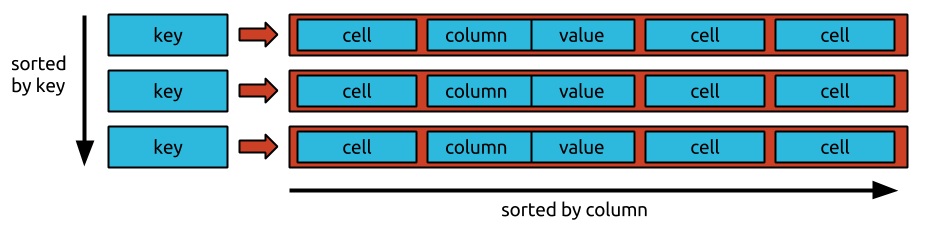
이 기사에서는 Bigtable에서 개발한 3차원 NoSQL 스토리지 모델을 살펴봅니다. 올바르게 구성되었는지 확인하기 위해 먼저 이론적인 용어로 구현되는 방법을 살펴본 다음 Node.js 클라이언트를 사용하여 구현합니다. Bigtable의 스토리지 모델은 유사한 데이터베이스에서 찾을 수 있는 방식과 다릅니다. 행/열 조합의 여러 셀은 셀당 타임스탬프로 정렬할 수 있습니다. 임의의 순서로 셀을 저장하는 대신 각 셀에는 셀이 순서대로 저장되도록 값과 타임스탬프가 있습니다. 이 예에서는 Node.js와 일반 JavaScript를 사용하여 Google Cloud Bigtable을 빌드합니다. 이 문서에서는 코드를 사용하여 새 Bigtable 인스턴스 를 만드는 방법을 살펴보겠습니다.
우리는 깨끗한 환경을 만들고 읽고 쓰고 그런 다음 분해하는 것으로 시작합니다. Node.js Bigtable 클라이언트를 사용하여 코드를 실행할 때 Node.js Bigtable 클라이언트는 권한 거부 오류를 발생시키고 Cloud Bigtable Admin API를 사용 설정하기 위한 링크를 생성할 수 있습니다. 또한 Bigtable 관리자 역할을 처리하려면 GCP 프로젝트에 별도의 서비스 계정을 설정해야 합니다. Bigtable 테이블을 만들려면 먼저 데이터베이스 인스턴스와 테이블 클러스터를 빌드해야 합니다. 이를 위해 Node.js 클라이언트에서 테이블 ID와 컬럼 패밀리를 정의하기만 하면 됩니다. 간단한 행은 데이터베이스에서 Bigtable을 사용하여 만들 수 있습니다. 데이터를 쿼리하는 유일한 방법은 행 키를 사용하여 특정 행 또는 행 그룹을 쿼리하는 것입니다.
수집 시간은 버전이 저장되는 순서와 관련이 없지만 저장 방법에는 영향을 미칩니다. 전체 행 키를 제공할 필요는 없습니다. 단순히 접두사로 충분합니다. Bigtable에서 여러 행을 쿼리해야 하는 경우 항상 스트리밍을 사용하는 것이 좋습니다. 스트리밍을 사용할 때 Bigtable은 행을 보내기 전에 서버에서 데이터를 버퍼링할 필요가 없으므로 성능이 더 빨라집니다. 필터를 사용하여 셀 버전을 제한하여 특정 제품군 이름이 있는 열 또는 특정 자격 기준이 있는 열만 반환할 수 있습니다. 이는 보관할 버전이 많지만 특정 목적을 위해 가장 최근 버전만 필요한 경우에 특히 유용합니다. 필터는 주로 쿼리 성능을 향상시키기 위해 쿼리되고 전송되는 데이터의 양을 줄이는 데 사용됩니다.
즉, Cloud Bigtable은 분석 및 운영 워크로드용으로 설계된 NoSQL 데이터베이스 입니다. 이 데이터베이스 시스템은 컬럼형 데이터베이스를 사용하는 HBase가 아닌 Hadoop을 사용하는 교차 플랫폼 하이브리드입니다. Cloud bigtable은 10MB 미만의 용량으로 높은 처리량과 확장성을 갖춘 애플리케이션을 구동하는 데 사용할 수 있습니다.
Apache Cassandra, ScyllaDB, Apache HBase, Google BigTable 및 Microsoft Azure CosmosDB는 와이드 컬럼 저장소의 예입니다.
테이블은 키/값 저장 측면에서 관계형 데이터베이스와 동일하지 않습니다. 트랜잭션은 한 번만 수행할 수 있으며 조인은 지원되지 않습니다.
Google Bigtable은 Nosql 데이터베이스입니까?
Google Bigtable은 대량의 데이터를 저장하고 관리하도록 설계된 NoSQL 데이터베이스입니다. Bigtable은 열 지향 데이터베이스입니다. 즉, 데이터가 행이 아닌 열로 구성됩니다. 따라서 웹 로그 또는 소셜 미디어 데이터와 같이 지속적으로 변경되는 데이터를 저장하는 데 적합합니다. 또한 Bigtable은 확장성이 뛰어나 대량의 데이터를 쉽게 처리할 수 있습니다.
이 NoSQL 데이터베이스는 광범위한 데이터 유형을 저장할 수 있으며 매우 안정적입니다. 또한 샤딩과 복제를 모두 처리하여 데이터베이스의 가용성과 신뢰성을 높입니다. Google 애널리틱스, 웹 인덱싱, MapReduce, Google Maps, Google Books, My Search History, Google Earth, Blogger.com, Google Code Hosting, Google For 애플리케이션 등 많은 Google 애플리케이션에서 사용합니다. 데이터 항목이 많다면 Datastore를 선택하는 것이 좋습니다.
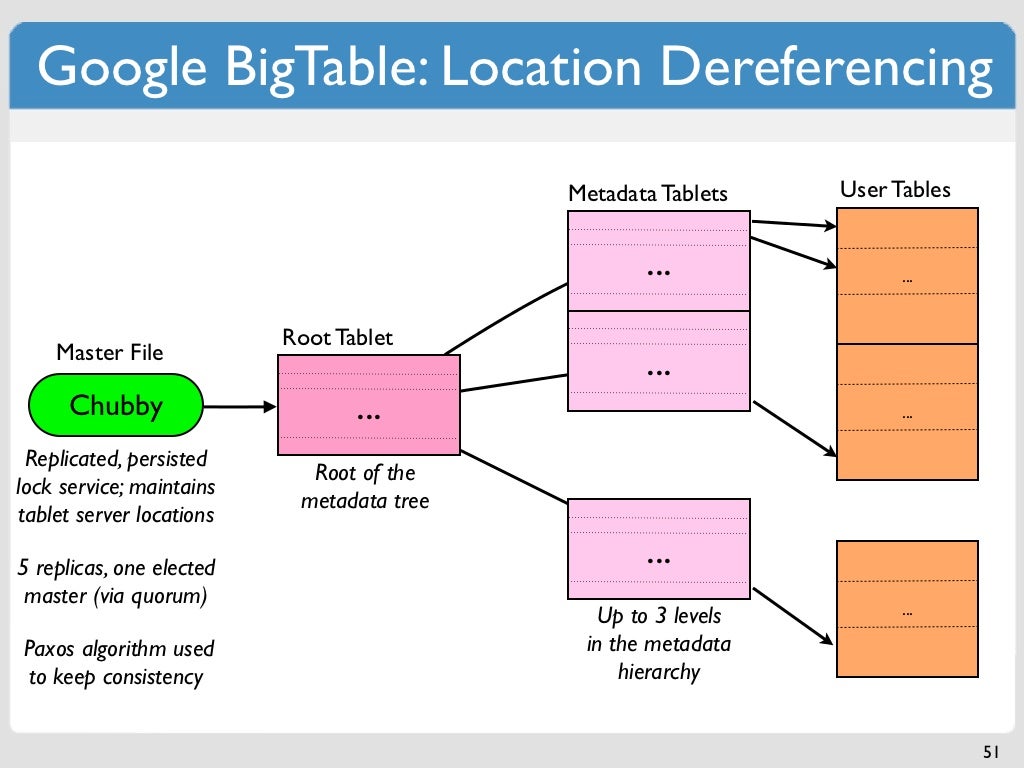
Bigtable에 데이터가 저장되는 순서는?
데이터가 bigtable에 저장되는 특정한 순서는 없습니다. 데이터는 임의의 순서로 저장되어 특정 데이터에 접근하기 어렵습니다.
Google의 Bigtable: 데이터 저장뿐만 아니라
igtable 내에서 특정 순서로 데이터를 배치할 수 없습니다. Bigtable은 행 기반 데이터베이스이므로 행 내의 모든 데이터는 열로 구성되고 그 뒤에 열이 있습니다. 데이터가 역순으로 저장되기 때문에 가장 최근 값을 요청하는 것은 간단하고 빠르지만 가장 오래된 값을 요청하는 것은 어렵고 시간이 많이 걸립니다.
귀하의 데이터는 Bigtable이 Colossus를 사용한 결과로 Google 데이터 센터 내에 있는 Google 내부의 오래 지속되는 파일 시스템인 Colossus에 보관됩니다. Bigtable은 무료로 사용할 수 있으며 HDFS 클러스터나 다른 파일 시스템을 사용할 필요가 없습니다.
외부 데이터 원본에 대한 쿼리는 결합 명령을 사용하여 영구 테이블을 만들지 않고 수행할 수 있습니다. 쿼리가 포함된 테이블 정의 파일입니다. 인라인 스키마 정의와 쿼리가 있습니다. 쿼리가 있는 JSON 스키마 정의 파일.
Bigtable 대 Datastore
Bigtable과 Datastore에는 몇 가지 중요한 차이점이 있습니다. 첫째, Bigtable은 열 지향 데이터 저장소인 반면 Datastore는 행 지향입니다. 즉, Bigtable에서는 데이터가 열로 구성되고 Datastore에서는 행으로 구성됩니다. 둘째, Bigtable에는 트랜잭션 개념이 없지만 Datastore에는 있습니다. 즉, Bigtable에서는 이전 상태로 변경 사항을 롤백할 수 없지만 Datastore에서는 롤백할 수 있습니다. 마지막으로 Bigtable은 높은 처리량과 짧은 지연 시간을 위해 설계되었으며 Datastore는 고가용성과 확장성을 위해 설계되었습니다.
Google 클라우드 데이터베이스를 구축하는 데 사용할 수 있는 클라우드 데이터 저장소는 무엇인가요? Bigtable은 복잡한 백엔드 워크로드가 포함된 대규모 워크로드를 지원하므로 대규모 조직 및 기업을 대상으로 합니다. 보다 제한적인 쿼리 언어 GQL을 사용하는 SQL과 달리 데이터 저장소는 엔터티 그룹으로 알려진 데이터 하위 집합에 대해 ACID 트랜잭션을 수행합니다(쿼리 언어 GQL은 훨씬 더 개방적이지만). Google Cloud Datastore와 Google Cloud Bigtable은 여러 가지 고유한 기능이 있는 두 가지 별개의 서비스입니다. 또한 아래 이미지의 정보는 적합한 서비스 제공업체를 선택하는 데 도움이 될 수 있습니다. 위의 답변과 Coursea Google Cloud Platform Big Data and Machine Learning Fundamentals 교과서에서 논의된 내용이 이 기사의 가이드 역할을 할 것입니다.
Bigtable과 Datastore의 차이점은 무엇입니까?
데이터 저장소와 데이터베이스의 차이점은 무엇입니까? bigtable과 데이터 저장소는 각각 대용량 데이터 처리 및 분석을 위해 설계되었으며, 데이터 저장소는 가치가 높은 트랜잭션 데이터를 위해 설계되었습니다. Datastore는 기존 SQL 표준을 따르지 않아 보다 유연하고 확장 가능한 방식으로 데이터를 유지할 수 있기 때문에 NoSQL 데이터베이스라고도 합니다. Google Bigtable은 어떤 종류의 데이터 저장소인가요? Bigtable 스토리지 모델은 키 및 값 맵으로 정렬되는 대규모 확장 가능한 테이블에 데이터를 저장 합니다. 테이블은 각각 단일 엔터티를 설명하는 행과 고유한 값이 있는 열로 구성됩니다. Datastore가 더 이상 사용되지 않습니까? Cloud Datastore API v1beta3가 출시되었으므로 더 이상 사용할 수 없습니다. 그럼에도 불구하고 Cloud Datastore 제품은 완벽하게 작동하고 지원됩니다.
빅테이블 데이터베이스
Bigtable은 구조화된 데이터를 관리하기 위한 분산 스토리지 시스템으로 수천 개의 상용 서버에서 페타바이트 규모의 매우 큰 크기로 확장되도록 설계되었습니다. Bigtable은 열 기반 데이터베이스로, 데이터가 행이 아닌 열로 저장됨을 의미합니다.
테이블은 수십억 개의 행에 도달할 수 있는 행과 열이 있는 희박하고 밀도가 높은 구조입니다. bigtable은 대기 시간이 짧은 대량의 데이터를 저장하는 데 탁월한 선택입니다. 짧은 지연 시간에 높은 읽기 및 쓰기 처리량을 지원하기 때문에 MapReduce 작업에 적합한 데이터 소스입니다. Bigtable 테이블을 사용하는 경우 쿼리를 더 쉽게 만들기 위해 테이블이 태블릿이라는 연속 행 블록으로 분할됩니다. Google이 사용하는 Colossus라는 파일 시스템에서 태블릿은 SSTable 형식으로 저장됩니다. Bigtable 노드 는 Bigtable 인스턴스의 일부인 각 태블릿의 하위 집합입니다. 클러스터에 노드를 추가하면 처리할 수 있는 동시 요청 수가 증가할 수 있습니다.

행에는 열 패밀리, 열 타임스탬프 및 키의 조합인 키 또는 값 항목 집합이 포함됩니다. Bigtable은 모든 데이터를 원시 바이트 문자열과 같은 방식으로 처리합니다. Bigtable은 변이 를 순차적으로 저장하고 정기적으로 압축하기 때문에 지정된 시간에 저장할 수 있는 변이의 수는 더 많은 저장 공간을 필요로 합니다. Bigtable은 자동화된 정교한 알고리즘을 사용하여 데이터를 압축합니다. 삭제는 실제로 새로운 유형의 돌연변이이기 때문에 단기적으로 더 많은 저장 공간이 필요합니다. Google의 독점 저장 방법을 사용하면 표준 HDFS 3방향 복제로 달성되는 데이터 내구성을 능가하는 데이터 내구성을 달성할 수 있습니다. Bigtable 테이블에 대한 액세스를 관리하는 것 외에도 GCP 프로젝트의 ID 및 액세스 관리(IAM) 섹션에서 사용자에게 역할을 할당하여 다른 GCP 서비스에 대한 액세스를 관리할 수 있습니다. Google Cloud의 기본 암호화 정책에 따라 클라우드의 모든 데이터는 암호화된 데이터에 사용하는 것과 동일한 강화된 키 관리 시스템을 사용하여 저장 상태에서 암호화됩니다. 백업을 사용하면 테이블의 스키마 및 데이터 복사본을 저장한 다음 나중에 해당 데이터 복사본을 새 테이블로 복원할 수 있습니다.
빅테이블 대 카산드라
Cassandra와 Bigtable은 서로 다른 방법을 사용하여 읽기 및 쓰기 작업을 수행해야 하는 처리 노드를 결정합니다. Cassandra에서는 파티션 키를 키라고 하지만 Bigtable에서는 행 키를 키라고 합니다. Cassandra에 대한 로드 밸런싱 정책은 프로세스의 일부로 클라이언트가 검토해야 합니다.
분산 데이터베이스는 여러 사람이 공유하는 데이터베이스입니다. 이 회사는 시스템에 다차원 키-값 저장소를 통합하여 수만 개의 QPS(초당 쿼리)를 처리할 수 있습니다. 이 문서의 목표는 두 데이터베이스 시스템을 비교하고 대조하는 것입니다. Bigtable의 주요 기능은 다음과 같습니다. 구조화된 데이터용 분산 스토리지 시스템 보고서가 작성되었습니다. Bigtable이 데이터 세트에 범위 재조정이 필요하다고 판단하면 스토리지 계층이 처리 계층과 분리되어 있기 때문에 처리 노드가 데이터 범위를 변경하는 것은 간단합니다. Bigtable은 또한 토폴로지에서 최대 4개의 클러스터로 구성된 지리적으로 분산된 클러스터 전체에서 비동기 복제를 지원하는 데 사용할 수 있습니다. Cassandra의 내결함성은 조정 가능한 일관성 수준과 연결되어 있습니다.
데이터 복제 토폴로지 전략을 구성하여 지리적 복제를 정의할 수 있습니다. 일반적으로 QUORUM(또는 일부 데이터 센터에서는 LOCAL_QUORUM) 설정이 사용됩니다. 성공적인 것으로 간주되려면 작업의 일관성 수준 설정이 코디네이터 노드에 응답하는 복제 노드 다수와 일치해야 합니다. 데이터 센터 및 랙 구성을 사용하는 Cassandra의 복제본은 기존 복제본과 비교할 때 더 많은 스트레스를 견딜 수 있습니다. 읽기 및 쓰기 작업을 수행할 때 토폴로지는 일관성을 보장하는 데 필요한 노드를 결정합니다. Bigtable 인스턴스는 단일 클러스터 또는 최대 4개의 대형 복제본 그룹을 포함할 수 있습니다. Bigtable 및 Cassandra는 넓은 열 저장소인 NoSQL 데이터 저장소 입니다.
Bigtable의 행 키는 테이블의 전역 데이터를 순서대로 정렬하는 데 사용됩니다. Bigtable의 노드는 Bigtable의 노드 기능의 일부로 태블릿이라고도 하는 키 범위에 대한 노드 책임의 균형을 자동으로 조정합니다. 클라이언트의 Bigtable 서비스 는 전송하는 열 데이터 유형을 적용하지 않습니다. Bigtable에서 테이블의 각 열에는 성이 할당됩니다. 테이블에 종종 더 많은 컬럼 패밀리(테이블당 최대 컬럼 수는 100개)가 있음에도 불구하고 각 테이블에는 적어도 하나의 컬럼 패밀리가 필요합니다. 행 키 교차는 두 개의 셀(열 한정자와 결합된 열 패밀리)로 구성됩니다. Cassandra와 Bigtable에는 읽기 및 쓰기 작업을 위한 처리 노드를 선택하는 방법이 있습니다.
Cassandra에서는 파티션 키가 식별되지만 Bigtable에서는 행 키가 사용됩니다. 다중 클러스터 정책과 같이 데이터 센터를 인식하는 로드 밸런싱 정책은 장애 조치 가능성을 제공합니다. 두 데이터베이스 모두 쓰기를 완료하는 데 유사한 방법을 사용하며 속도를 위해 최적화되었습니다. 데이터는 변경할 수 없는 SSTable 파일을 통해 두 데이터베이스에 저장됩니다. Cassandra에서 코디네이터는 여러 복제본이 응답하기 전에 쓰기가 완료되었음을 클라이언트에 알려야 합니다. 각 행 키는 하나의 노드에만 할당되므로 Bigtable에서 성공적인 쓰기는 하나의 노드의 응답으로만 확인할 수 있습니다. 두 데이터베이스의 셀은 병합된 SSTable에 포함되지 않을 수 있습니다.
CQL 쿼리의 WHERE 절 때문에 Cassandra에서 둘 이상의 행을 반환하는 것은 불가능합니다. 키 범위를 담당하는 노드만 Bigtable에서 컨설트하면 됩니다. 처리 노드에서 읽을 수 있는 데이터의 양을 제한할 수 있습니다. 압축 단계에서는 SSTable이 정기적으로 병합되고 Bigtable과 Cassandra에 저장된 데이터가 SSTable에 저장됩니다. 각 셀의 타임스탬프 버전 수를 관리하는 규칙은 없지만 다른 행 크기 제한이 있을 수 있습니다. Colossus의 복제 시스템은 데이터 내구성을 보장합니다. Cassandra와 마찬가지로 Bigtable에는 많은 공통 프로그래밍 언어를 위한 명령줄 인터페이스와 클라이언트 라이브러리가 있습니다.
각 노드에는 Bigtable의 SSTable이 할당되며 여기에 저장된 데이터는 해당 노드에서 제공됩니다. Cassandra 클러스터의 크기를 조정할 때 Bigtable과 마찬가지로 스토리지 복제본을 고려할 필요가 없습니다. 솔리드 스테이트 드라이브(SSD) 또는 하드 디스크 드라이브(HDD)는 Bigtable 인스턴스 에 가장 일반적으로 사용되는 스토리지 유형입니다. Cassandra가 입증한 것처럼 내결함성을 달성하기 위한 스토리지 밀도 손실이 없습니다. 최소한의 노력과 가동 중지 시간으로 작업 요구 사항을 충족하도록 Bigtable 인스턴스를 확장할 수 있습니다. 클러스터는 4개뿐이지만 각 클러스터는 전 세계 지원되는 모든 클라우드 지역에서 생성할 수 있습니다. Google은 대표 데이터 및 쿼리로 Bigtable의 성능을 테스트하여 노드당 QPS 측정항목을 생성할 것을 권장합니다.
Cassandra는 Bigtable 관리 구성 요소를 사용하여 많은 관리 기능을 수행합니다. largetable 백업은 클러스터에 개체로 저장되는 복원 가능한 테이블 복사본을 만듭니다. 백업은 노드 리소스를 적게 사용하고 클라우드 스토리지보다 저렴합니다. Bigtable을 백업하는 또 다른 방법은 Cloud Storage로 관리 데이터 내보내기를 사용하는 것입니다. OS 패치, 노드 복구, 노드 복구, 스토리지 압축 모니터링, SSL 인증서 교체와 같은 내부 유지 관리 작업은 모두 Bigtable 서비스에서 원활하게 처리됩니다. 대시보드는 Bigtable Google Cloud 콘솔 페이지 의 인스턴스, 클러스터 및 테이블 수준에서 처리량 및 사용률 측정항목을 모니터링하는 데 사용할 수 있습니다. 모니터링 대시보드를 사용하여 고급 성능 조정을 수행할 수 있습니다.
Bigtable 백서는 대규모 확장을 지원하는 데이터 스토리지 시스템에 대해 설명합니다. 데이터의 각 테이블은 여러 파티션으로 나뉩니다. 행 키를 사용하거나 행 키 범위를 사용하여 테이블을 쿼리할 수 있습니다. Bigtable 백서는 노드 클러스터 전체에 테이블 작업을 분산하는 방법도 설명합니다. 오픈 소스 데이터베이스인 Apache Cassandra는 Bigtable 백서의 일부 개념을 기반으로 합니다. 데이터 센터는 데이터를 제공하는 서버 간에 스토리지가 공유되는 분산 노드 아키텍처를 사용합니다. Bigtable의 데이터 저장소 시스템에 대한 액세스는 cbt 명령줄 인터페이스 및 클라이언트 라이브러리를 사용하여 제공됩니다. Bigtable에는 Python 외에도 다양한 프로그래밍 언어가 포함되어 있어 애플리케이션과 간단하게 통합할 수 있습니다.
서비스로서의 Google의 Datastax Astra Cassandra: 간편한 배포 및 확장
Google의 DataStax Astra Cassandra as a Service는 Cassandra에 대해 배우기에 탁월한 선택입니다. Kubernetes Operator의 사용자 인터페이스를 사용하면 Cassandra 배포를 간단하게 구성, 관리 및 확장할 수 있습니다.
빅테이블 문서
Bigtable 설명서 는 이 강력한 도구에 대해 배울 수 있는 훌륭한 리소스입니다. Bigtable의 기능에 대한 개요와 사용 방법에 대한 자세한 정보를 제공합니다. 설명서는 잘 구성되어 있고 따라하기 쉽기 때문에 이 강력한 도구에 관심이 있는 모든 사람에게 유용한 리소스가 됩니다.
Google Cloud Platform은 Google의 Bigtable 데이터베이스 호스팅을 담당합니다. OpenTSDB 2.1 이상은 Google의 백엔드와 연동하여 사용하면 간단합니다. Bigtable 인스턴스를 만들고 Bigtable HBase 셸을 사용하여 TSDB 테이블을 설정하고 TSD를 시작하기만 하면 됩니다. Bigtable의 클라이언트는 현재 베타 버전이며 다양한 변화를 겪고 있습니다.
Bigtable의 효율적인 데이터 레이아웃
Bigtable은 MapReduce 작업에도 적합합니다. 효율적인 데이터 레이아웃으로 인해 MapReduce는 단기간에 많은 양의 데이터를 처리할 수 있습니다.