
MapReduce: 대용량 데이터 세트를 위한 프로그래밍 모델
게시 됨: 2023-01-08MapReduce는 클러스터에서 병렬 분산 알고리즘을 사용하여 대규모 데이터 세트를 처리하고 생성하기 위한 프로그래밍 모델 및 관련 구현입니다.
우리는 새로운 기술을 사용하여 방대한 양의 데이터로 작업하는 방식을 변화시키고 있습니다. Hadoop, NoSQL, Spark와 같은 데이터 웨어하우스는 이 분야에서 가장 눈에 띄는 업체 중 일부입니다. DBA와 인프라 엔지니어/개발자는 고도로 정교한 시스템 관리를 전문으로 하는 새로운 종류의 전문가입니다. Hadoop은 데이터베이스 대신 대용량 파일 형태의 병렬 컴퓨팅을 허용하는 소프트웨어 생태계입니다. 이 기술은 빅 데이터의 대량 처리 요구를 지원한다는 측면에서 상당한 이점을 제공했습니다. 대규모 데이터 트랜잭션의 경우 평균 Hadoop 클러스터는 중앙 집중식 관계형 데이터베이스 시스템에서 일반적으로 20시간이 걸리는 대규모 트랜잭션을 처리하는 데 3분밖에 걸리지 않습니다.
mapreduce 클러스터 는 일반 클러스터와 동일한 방식으로 대용량 데이터 세트를 처리하고 생성하는 프로그래밍 모델과 병렬 알고리즘이 있는 클러스터입니다.
Apache Hadoop 에코시스템은 분산 컴퓨팅을 지원하도록 설계되었으며 신뢰할 수 있고 확장 가능하며 바로 사용할 수 있는 환경을 제공합니다. 이 프로젝트의 MapReduce 모듈은 Hadoop(분산 파일 시스템)에 상주하는 거대한 데이터 세트를 처리하는 데 사용되는 프로그래밍 모델입니다.
이 모듈은 Apache Hadoop 오픈 소스 에코시스템의 구성 요소이며 Hadoop 분산 파일 시스템 (HDFS)에서 데이터를 쿼리하고 선택하는 데 사용됩니다. 이러한 선택을 위해 사용할 수 있는 MapReduce 알고리즘을 사용하여 다양한 쿼리에 대해 데이터를 선택할 수 있습니다.
MapReduce를 사용하면 대용량 데이터 처리 작업을 실행할 수 있습니다. C, Ruby, Java, Python 등을 포함한 모든 프로그래밍 언어로 MapReduce 프로그램을 구축할 수 있습니다. 이러한 프로그램을 동시에 사용하여 MapReduce 프로그램을 실행할 수 있으므로 대규모 데이터 분석에 매우 유용합니다.
Mongodb에서 Mapreduce는 무엇을 위해 사용됩니까?
MongoDB의 맵은 사용자가 대규모 데이터 세트를 수행하고 집계된 결과를 생성할 수 있도록 하는 데이터 처리 프로그래밍 모델입니다. MapReduce는 MongoDB에서 맵을 줄이기 위해 사용하는 방법입니다. 이 함수는 map 함수와 reduce 함수의 두 가지 구성 요소로 나뉩니다.
MongoDB의 MapReduce 도구 를 사용하면 대규모 데이터 세트를 구성하고 집계할 수 있습니다. MongoDB에서 이 명령은 많은 양의 데이터를 처리하기 위해 MongoDB의 두 가지 기본 입력인 map 함수와 reduce 함수를 사용합니다. 예제를 정의하려면 아래 단계를 따르십시오. map 함수, reduce 함수 및 예제를 정의합니다.
MapReduce는 문자열을 비교하여 기본 정렬 방법을 사용하는지 여부에 관계없이 기본 정렬 방법을 사용하여 출력을 정렬합니다. 데이터 정렬 방식을 변경하려면 먼저 정렬 알고리즘을 만든 다음 매퍼 클래스를 사용하여 구현해야 합니다.
SpiderMonkey는 널리 사용되는 JavaScript 엔진입니다. 소규모 응용 프로그램에 적합하지만 몇 가지 제한 사항이 있습니다. 예를 들어 SpiderMonkey에는 정렬 알고리즘이 없습니다. 결과적으로 Mapmapper를 사용하여 데이터를 정렬하려면 먼저 자체 정렬 알고리즘을 만들고 이를 Reduce 클래스에 구현해야 합니다.
인기에도 불구하고 SpiderMonkey는 정렬 알고리즘을 사용하지 않습니다. SpiderMonkey에는 다른 제한 사항이 있지만 이것은 주목할 만합니다. 예를 들어 SpiderMonkey에는 우수한 가비지 수집기가 없으므로 프로그램이 느려지기 시작하면 더 빠르게 하기 위해 몇 가지 조치를 취해야 할 수 있습니다.
Mapreduce 함수를 사용하는 이유는 무엇입니까?
MapReduce 함수 는 다양한 상황에서 유용할 수 있습니다. 이 방법은 경우에 따라 일괄 데이터 처리에 사용할 수 있습니다. 또한 단일 응용 프로그램이나 프로세스에서 많은 양의 데이터를 처리해야 하는 경우에도 유용합니다. MapReduce 함수는 분산 시스템의 여러 노드에 분산된 데이터를 처리하는 데에도 사용할 수 있습니다. MapReduce 기능을 활용하면 노드의 데이터를 단일 출력으로 결합할 수 있습니다. MapReduce 애플리케이션은 일반적으로 대량의 데이터를 처리하는 데 사용되지만 매우 많은 양을 처리해야 할 수도 있습니다.
왜 맵리듀스라고 불리는가?
MapReduce라고 불리는 이유에 대한 몇 가지 이론이 있습니다. 하나는 맵 축소 알고리즘이 문제를 더 작은 조각으로 분해(매핑)한 다음 해당 조각을 해결하고 다시 결합(축소)하기 때문에 단어장난입니다. 또 다른 이론은 2004년 Google 직원이 작성한 "MapReduce: Simplified Data Processing on Large Clusters"라는 논문에 대한 참조라는 것입니다. 논문에서 저자는 "매핑"과 "축소"라는 용어를 사용하여 제안된 처리 모델의 두 가지 주요 단계를 설명합니다.
그러나 MapReduce 모델은 제한적으로만 사용된다는 점에 유의해야 합니다. 대용량 데이터 세트에는 적합하지 않으며 제대로 작동하려면 병렬화해야 합니다. 이러한 문제를 해결할 때 Apache Spark는 MapReduce에 대한 강력한 대안을 제공합니다. Spark 클러스터 컴퓨팅 시스템은 Hadoop을 기반으로 하며 범용 컴퓨팅 플랫폼으로 작동합니다. 이 도구는 데이터 마이닝 및 기계 학습과 같은 기존 데이터 분석 작업뿐만 아니라 데이터 웨어하우징 및 빅 데이터 분석과 같은 보다 복잡한 데이터 처리 작업의 속도를 높이는 데 사용할 수 있습니다. 이 소프트웨어는 확장 가능하고 내결함성이 있는 프로그래밍 언어인 Erlang을 사용하여 제작되었습니다. 대량의 데이터를 처리할 수 있으며 동시에 여러 시스템에서 실행할 수 있습니다. 또한 Spark는 병렬 처리를 사용하여 여러 노드가 동시에 동일한 작업을 수행할 수 있도록 합니다. 전반적으로 대규모 데이터 분석 작업을 자동화하고 확장성을 높일 수 있는 잠재력이 있습니다. 처리를 병렬화하고 대용량 데이터 세트를 처리해야 하는 경우 MapReduce의 탁월한 대안입니다.
맵리듀스와 집계의 차이점은 무엇입니까?
빅데이터 작업을 할 때 맵리듀스는 대량의 데이터에서 데이터를 추출하는 중요한 방법입니다. 현재 MongoDB 2.2에는 새로운 집계 프레임워크가 포함되어 있습니다. 기능면에서 집계는 mapreduce와 유사하지만 서류상으로는 더 빠릅니다.
이 시나리오에서 MongoDB Aggregation 및 MapReduce는 Sharded 설정의 Docker 컨테이너에서 실행됩니다. Aggregator 파이프라인 성능은 더 빠르고 쉽게 탐색할 수 있기 때문에 mapreduce보다 우수합니다. 문제의 작동 방식은 다음과 같습니다. 트윗은 Twitter 해시태그에서 "den", "denne", "denna", "det", "han", "hon" 및 "hen"(대소문자 구분)과 같은 스웨덴 대명사를 계산합니다. 사용자는 몇 개의 트위터 핸들을 가지고 있습니까? 400만 개 이상의 트윗이 전송되었습니다. 이 실험에서는 먼저 MongoDB 데이터베이스를 만들고 샤딩을 활성화합니다. Twitter 스트림을 데이터베이스로 가져오고 MapReduce 및 Aggregation Pipeline을 사용한 쿼리를 실행했습니다.
Mapreduce: 궁극의 데이터 집계 도구
mapReduce 프로그램 은 컬렉션에서 문서 목록을 읽고 미리 정의된 함수 집합을 사용하여 처리합니다. mapReduce 작업은 축소 단계에서 처리될 처리 준비가 된 문서 스트림을 생성합니다. 다양한 상황에서 mapreduce와 aggregation을 결합하는 것이 가능합니다. $group 집계 연산자는 단일 필드에서 문서를 그룹화하는 데 사용할 수 있는 도구입니다. $merge 집계 연산자를 사용하여 여러 문서를 병합하면 새 문서를 만들 수 있습니다. $accumulator 집계 연산자를 사용하여 여러 map-reduce 작업의 결과를 단일 문서로 나타낼 수 있습니다.
Mongodb의 맵리듀스
Mongodb mapreduce 는 대규모 데이터 세트를 위한 데이터 처리 기술입니다. 데이터 분석을 위한 강력한 도구이며 병렬 및 분산 방식으로 데이터를 처리하고 집계하는 방법을 제공합니다. MapReduce는 웹 트래픽 분석, 로그 분석, 소셜 네트워크 분석 등 다양한 도메인의 데이터 분석에 광범위하게 사용되었습니다.

mapReduce 명령 을 사용할 때 컬렉션에서 map-reduce 집계 작업을 실행할 수 있습니다. 지도 기능은 모든 문서를 0 또는 기타 여러 문서로 변환할 수 있습니다. 4.2에서 이전까지의 MongoDB 버전에서 각 방출은 최대 BSON 문서 크기의 절반만 보유할 수 있습니다. MapReduce에서 사용되는 더 이상 사용되지 않는 BSON 유형 JavaScript 코드는 더 이상 지원되지 않으며 코드는 해당 기능에 더 이상 사용할 수 없습니다. 이제 MongoDB 4.4에는 더 이상 사용되지 않는 범위(BSON 유형 15)가 있는 BSON 유형 JavaScript 코드가 포함되지 않습니다. 범위 매개변수는 reduce 함수에서 액세스할 수 있는 변수를 지정합니다. 입력을 줄이기 위해 MongoDB는 BSON 문서 크기를 최대 크기의 절반으로 제한합니다.
서버로 반환된 큰 문서는 반환된 후 후속 축소에서 병합되어 잠재적으로 요구 사항을 위반할 수 있습니다. MongoDB 4.2가 최신 버전입니다. 이 옵션은 동일한 컬렉션 이름으로 새 컬렉션을 만들기 위해 map-reduce뿐만 아니라 새 샤딩된 컬렉션을 만드는 데 사용할 수 있습니다. finalize 함수는 키 값과 reduce 함수에서 감소된 값을 인수로 받습니다. out 매개변수를 구성하기 위한 세 가지 옵션이 있습니다. 새 컬렉션을 만드는 것 외에도 이 옵션은 복제본 세트의 보조 구성원에서 작동하지 않습니다. NonAtomic: false 옵션은 명시적 사양을 전달하기 위해 컬렉션이 이미 존재하는 경우에만 제공될 수 있습니다.
새 문서의 키가 기존 문서의 키와 동일한 경우 새 문서 결과와 기존 문서 모두에서 축소 기능을 사용합니다. collectionName이 설정된 기존의 확정되지 않은 컬렉션인 경우 map-reduce가 작동하지 않습니다. 이 경우 nonAtomic이 참이면 MongoDB가 데이터베이스를 잠그지 못합니다. 이 옵션을 사용하는 복제 세트의 보조 구성원만 세트에서 제외될 수 있습니다. map-reduce 작업을 다시 작성하는 데 사용자 지정 함수가 필요하지 않습니다. cust_id는 cust_id 메서드로 $group 단계 그룹의 값 필드를 계산하는 데 사용됩니다. $merge 단계는 사용 가능한 집계 파이프라인 연산자를 사용하여 $merge 단계의 결과를 출력 컬렉션에 결합합니다.
예를 들어, $out 단계는 컬렉션 agg_alternative_1의 출력을 작성하는 데 사용할 수 있습니다. 각 입력 문서는 맵 기능으로 처리할 수 있습니다. 주문의 각 항목은 개수 1과 주문의 항목 수량을 모두 포함하는 새 개체 값과 연결됩니다. reduceVal에서 count 필드는 배열 요소에 의해 생성된 count 필드의 합계를 나타냅니다. finalize 함수가 avg라는 계산된 필드를 포함하도록 reduceVal 개체를 수정하면 수정된 개체가 사용자에게 반환됩니다. $unwind 단계는 문서를 항목 배열 필드를 사용하여 각 배열 요소에 대한 문서로 나눕니다. $project 단계는 두 필드 -id 및 value를 포함하여 mapreduce의 출력을 미러링하기 위해 출력 문서를 재구성합니다.
새 결과와 동일한 키를 가진 기존 문서가 없으면 기존 문서를 덮어씁니다. out 매개변수를 지정하면 컬렉션에 결과를 쓰려는 경우 mapReduce가 다음 형식의 출력으로 문서를 반환합니다. 출력이 인라인으로 작성된 경우 결과 문서의 배열이 반환됩니다. 각 문서에는 원본 문서의 이름과 수신자 문서의 이름이라는 두 개의 필드가 있습니다. -id 필드에 키 값을 입력하면 키 값을 줄이거나 확정하기 위한 값 필드가 생성됩니다.
Mongodb에서 방출이란 무엇입니까?
맵 함수로서 맵 함수는 언제든지 emits (key,value)를 호출하여 키와 값을 포함하는 출력 문서를 생성할 수 있습니다. MongoDB 4.2 및 이전 버전의 단일 내보내기는 MongoDB의 BSON 파일 최대 크기의 절반만 보유할 수 있습니다. MongoDB 버전 4.4부터 제한이 제거됩니다.
Mongodb가 유연하고 확장 가능한 데이터를 위한 최선의 선택인 이유
엄격한 스키마가 없기 때문에 MongoDB는 종종 NoSQL과 연결됩니다. 엄격한 스키마가 없기 때문에 데이터는 애플리케이션에 편리한 모든 형식으로 저장할 수 있습니다. 데이터베이스의 유연성은 확장 또는 축소할 때 중요한 이점을 제공합니다. 이는 데이터가 애플리케이션의 요구 사항에 맞는 방식으로 저장될 수 있음을 의미하기 때문입니다.
ER 다이어그램이 있는 데이터 다이어그램을 사용하여 다양한 데이터 조각 간의 관계를 시각화할 수 있습니다. ER 다이어그램은 데이터 모음을 나타내는 일련의 노드를 나타내며 노드 간의 연결은 식별자 역할을 합니다.
MongoDB는 관계형 데이터베이스가 아니기 때문에 관계가 적용되지 않습니다. ER 다이어그램은 데이터 내에 존재하는 관계를 묘사하고 이를 시각화하는 데에도 도움이 됩니다.
MongoDB는 유연하고 확장 가능한 데이터를 위한 탁월한 선택입니다. 유연성을 통해 애플리케이션에 적합한 방식으로 데이터를 저장할 수 있으며 확장성 덕분에 대용량 데이터 세트를 빠르고 쉽게 처리할 수 있습니다.
맵 축소 Mongodb 예제
MongoDB에서 map-reduce는 컬렉션에서 데이터를 집계하기 위한 데이터 처리 패러다임입니다. 함수형 프로그래밍의 map 및 reduce 함수와 비슷합니다.
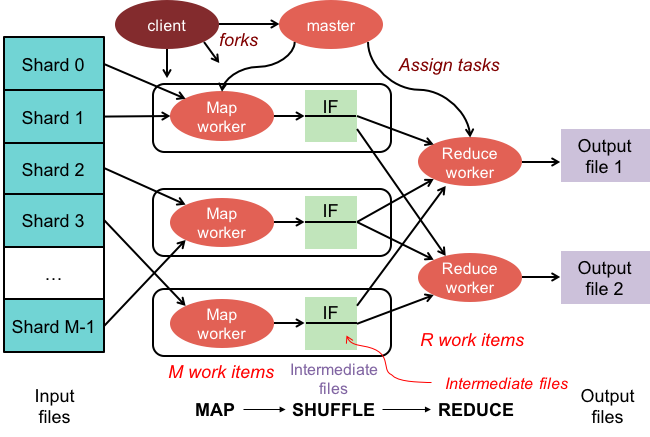
맵 축소 작업에는 다음 두 단계가 있습니다.
1. 매핑 단계는 컬렉션의 각 문서에 매핑 기능을 적용합니다. 매핑 함수는 각 입력 문서에 대해 하나 이상의 개체를 내보냅니다.
2. reduce 단계는 map 단계에서 내보낸 문서에 reduce 함수를 적용합니다. reduce 함수는 개체를 집계하고 단일 개체를 출력으로 생성합니다.
예를 들어 기사 모음을 생각해 보십시오. map-reduce를 사용하여 각 기사의 단어 수를 계산할 수 있습니다.
먼저 각 문서에 대한 키-값 쌍을 내보내는 매핑 함수를 정의합니다. 여기서 키는 기사 ID이고 값은 기사의 단어 수입니다.
다음으로 각 키의 값을 합산하는 reduce 함수를 정의합니다.
마지막으로 컬렉션에서 map-reduce 작업을 실행합니다. 결과는 집계된 데이터가 포함된 문서입니다.
mongosh에는 데이터베이스가 있습니다. mapReduce() 메서드는 mapReduce 명령을 둘러싼 래퍼입니다. 사용자 정의 집계 표현식이 없는 집계 파이프라인 대안과 같은 이 섹션의 몇 가지 예가 제공됩니다. Map-Reduce to Aggregation Pipeline Translation Examples를 사용하여 사용자 정의 표현식으로 맵을 번역할 수 있습니다. 사용 가능한 집계 파이프라인 연산자를 사용하여 사용자 지정 함수를 정의하지 않고도 맵 축소 작업을 변경할 수 있습니다. 지도 기능은 입력의 각 문서를 처리하는 데 사용할 수 있습니다. 각 항목에는 숫자 1, 주문 수량 및 항목 목록을 포함하는 새 값과 연결된 자체 객체 값이 있습니다.
현재 문서의 키가 새 문서의 키와 같으면 해당 문서를 덮어씁니다. 사용자 지정 함수를 정의하는 대신 집계 파이프라인 연산자를 사용하여 맵 축소 작업을 다시 작성할 수 있습니다. $unwind 단계는 항목 배열 필드별로 문서를 분해하여 각 배열 요소에 대한 문서를 생성합니다. $project 단계가 출력 문서의 형태를 변경하면 map-reduce 출력이 미러링됩니다. 작업은 새 결과와 동일한 키를 가진 기존 문서를 덮어씁니다.
Hadoop에서 매퍼 기능이란 무엇입니까?
리듀서는 통일된 답변을 생성하기 위해 매퍼의 데이터를 결합해야 합니다. 축소 출력은 생성된 결과의 하위 집합을 각각 나타내는 맵 출력 집합이 입력으로 허용될 때 생성됩니다.
매퍼는 데이터를 관리 가능한 청크로 나눈 다음 크기에 따라 각 청크를 작업에 할당하는 데 사용됩니다. 입력 데이터는 수행할 작업을 나타내는 매개변수가 있는 매퍼 기능에 의해 수신됩니다.
일련의 항목은 출력에서 매퍼에 의해 매핑된 데이터 청크에 해당합니다. 결과적으로 맵 출력은 리듀서로 전달되어 리듀서 출력으로 변환됩니다.
오류는 매퍼 기능으로도 처리됩니다. 이 경우 매퍼는 지도 출력이 아닌 오류 출력을 반환합니다. 감속기는 이 데이터를 처리할 수 없기 때문에 매퍼는 오류 메시지를 반환합니다.
하둡 생태계
Hadoop 생태계는 빅 데이터를 처리하고 저장하기 위한 플랫폼입니다. 이는 여러 구성 요소로 구성되며 각 구성 요소는 데이터 처리 및 저장에서 특정 역할을 수행합니다. 생태계의 가장 중요한 구성 요소는 HDFS(Hadoop Distributed File System), MapReduce 프레임워크 및 Hadoop 공통 라이브러리 입니다.