
NoSQL 데이터베이스: Impala
게시 됨: 2023-03-03NoSQL은 기존의 관계형 데이터베이스 구조를 사용하지 않는 데이터베이스를 설명하는 데 사용되는 용어입니다. 대신 NoSQL 데이터베이스는 더 간단하고 확장 가능한 솔루션을 제공하도록 설계되는 경우가 많습니다.
Impala는 대용량 데이터 세트를 관리하기 위한 빠르고 확장 가능한 솔루션을 제공하도록 설계된 NoSQL 데이터베이스입니다. Impala는 Google Bigtable 데이터 모델을 기반으로 하며 열 저장 형식을 사용합니다. Impala는 오픈 소스 프로젝트로 제공되며 Cloudera에서 지원합니다.
Apache Impala는 Hadoop 클러스터에 설치되어 시스템에 저장된 데이터에 대해 MPP(대량 병렬 처리)를 수행하는 오픈 소스 SQL 쿼리 엔진입니다. 원래 2012년에 개발된 이 오픈 소스 프로젝트는 "Microsoft Formula 1"로 알려져 있습니다.
Impala 플랫폼을 사용하면 데이터를 이동하거나 변환할 필요 없이 HDFS 및 Apache HBase에 저장된 Hadoop 데이터 에 대해 대기 시간이 짧은 SQL 쿼리를 수행할 수 있습니다.
Impala Sql 기반입니까?
Impala는 Apache Hadoop에서 실행되는 SQL 기반 쿼리 엔진입니다. 사용자는 SQL을 사용하여 HDFS 및 HBase에 저장된 데이터를 쿼리할 수 있습니다. Impala는 Hive 및 Pig와 같은 다른 Hadoop 쿼리 엔진 에 비해 높은 성능과 낮은 대기 시간을 제공합니다.
Impala 분석 MPP 데이터베이스는 업계에서 가장 빠른 통찰력을 제공합니다. CDH와 통합되며 Cloudera Enterprise를 통해 액세스할 수 있습니다. Impala와 같은 Apache Hadoop용 MPP 데이터베이스는 HDFS를 사용하여 더 빠른 통찰력을 제공합니다.
Impala는 데이터베이스입니다
내가 믿는 데이터베이스입니다.
Impala는 기타 도구입니까?
Impala는 ETL 도구가 아니라 프로세스를 통해 데이터를 정리한 후 SQL 쿼리를 수행하는 데 사용할 수 있는 SQL 쿼리 엔진입니다.
Apache Impala는 무엇에 사용됩니까?
SQL과 유사한 쿼리를 사용하여 Impala를 사용하여 다양한 소스에서 데이터를 읽을 수 있습니다. Apache Impala는 Hadoop 분산 파일 시스템 에 저장된 데이터에 액세스할 때 Hive 및 기타 SQL 엔진보다 성능이 뛰어납니다. Impala를 사용하여 Hadoop HBase, HDFS 및 Amazon S3에 데이터를 저장합니다.
기술 스택에서 Apache Impala를 사용하는 19개 기업
Apache Impala는 다양한 대기업에서 널리 사용되는 데이터 처리 엔진 입니다. 보고서에 따르면 Stripe, Agoda 및 Expedia.com을 포함한 19개 기술 회사가 Apache Impala를 사용합니다. Impala 플랫폼은 유연하고 효율적이며 대용량 데이터 세트를 빠르고 효과적으로 처리할 수 있습니다. 이 도구의 광범위한 사용은 그것이 얼마나 유용한지, 그리고 데이터 처리에 얼마나 유용한지를 보여줍니다.
Sql Hive와 Impala의 차이점은 무엇입니까?
Hive의 목표는 여러 변환 및 조인이 필요한 장기 실행 쿼리를 처리하는 것입니다. 지연 시간이 짧고 더 작은 쿼리를 처리할 수 있기 때문에 Impala 쿼리 처리 엔진은 대화형 컴퓨팅에 이상적입니다. Spark는 단기 및 장기 쿼리 외에도 단기 및 장기 쿼리를 모두 지원합니다.
Hive는 장기 실행 배치 작업에 더 적합합니다.
도구의 주요 목적은 배치를 처리하는 것이 아닙니다. Hive는 더 작은 데이터 세트를 처리할 수 있는 Impulsa보다 장기 배치 작업에 더 적합합니다.
Impala는 데이터베이스인가
Impala는 열 형식으로 데이터를 저장하는 데이터베이스입니다. 확장 가능하고 대용량 데이터 세트에 고성능을 제공하도록 설계되었습니다.
Impala 초기 릴리스에서는 숫자가 아닌 STRING, VARCHAR, VARCHar2, INT 및 FLOAT와 같은 핵심 열 데이터 유형이 지원되며 BLOB 유형은 지원되지 않습니다. Impala SQL-92에는 일부 SQL 표준 표준 향상 기능이 포함되어 있지만 모든 기능을 통합하지는 않습니다. 데이터가 너무 커서 단일 서버에서 생산, 조작 및 분석할 수 없는 경우 Impala는 다른 데이터 웨어하우스 보다 성능이 뛰어나고 확장성이 더 뛰어납니다. Impala는 가볍기 때문에 로드할 때 데이터 파일의 원래 위치를 제거할 필요가 없습니다. 성능 테스트, 확장성 및 다중 노드 클러스터 구성에 대해 학습하는 첫 번째 단계는 일반적으로 방대한 양의 데이터를 수집하는 것입니다. Cloudera Impala는 대용량 데이터 세트의 데이터 로드 및 대량 읽기에 최적화되어 있어 적은 비용으로 더 많은 작업을 수행할 수 있습니다. HDFS의 멀티메가바이트 블록 크기 덕분에 Impala는 네트워크로 연결된 여러 서버에서 대량의 데이터를 병렬로 처리할 수 있습니다.
정규화된 인덱스를 계획하고 이를 생성하는 데 드는 시간과 노력 대신 Impala에서 수행합니다. Impala의 쿼리 엔진은 데이터 웨어하우스에서 오는 대량의 데이터를 처리할 수 있습니다. 클러스터를 분석하고 노드 간에 작업을 분배하여 소모되는 자원의 양을 줄입니다. 데이터 웨어하우스의 파티셔닝은 Impala에서 친숙한 개념입니다. 파티셔닝은 Impala에서 디스크 I/O를 줄이고 쿼리 확장성을 높입니다. Impala의 내장 테이블에 액세스할 수 없으므로 데이터 파일이 필요합니다. INSERT는 사용 가능한 옵션 중 하나입니다.
두 개의 장난감 테이블을 만들려면 값 설명을 사용하십시오. 배치 지향 소프트웨어를 사용해 왔다면 시도해 볼 수 있습니다. SQL-on- hadoop 기술을 Apache Hive 구성에 통합할 수 있습니다. Impala의 Hive 테이블은 시간 소모적인 방식으로 로드되거나 변환되지 않습니다.
Impala: Hadoop을 위한 강력한 데이터 관리 도구
SQL 구문은 HDFS 및 Apache HBase에 저장된 데이터를 쿼리할 수 있는 Impala 사용자에게 친숙합니다. 이러한 방식으로 기존의 관계형 데이터베이스 대신 Hadoop 및 Impulsa를 사용할 수 있습니다. 또한 기능 덕분에 강력한 데이터 관리 도구입니다. 또한 대용량 데이터 세트에 대한 기능이 인상적이며 이를 매우 쉽게 처리할 수 있습니다.

빅 데이터의 임팔라
Impala는 Apache Hadoop에서 실행되는 오픈 소스 MPP SQL 쿼리 엔진입니다. HDFS 및 HBase에 저장된 데이터에 대한 빠른 대화형 SQL 쿼리를 제공합니다. Impala는 HDFS 및 HBase에 저장된 데이터에 대한 빠른 대화형 SQL 인터페이스를 제공하여 Apache Hadoop의 성능을 개선하도록 설계되었습니다.
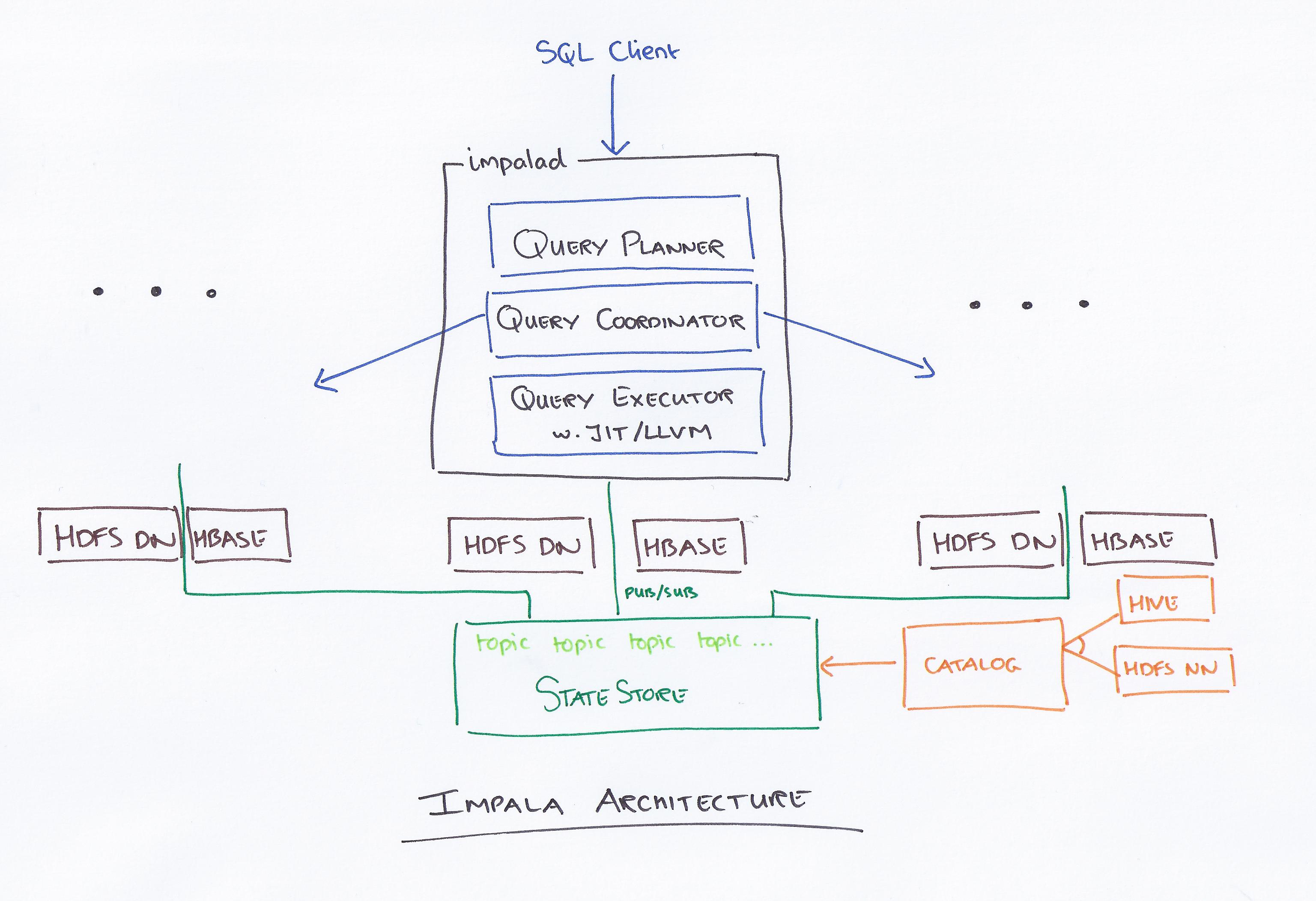
Cloudera가 이끄는 Impala는 새로운 쿼리 시스템입니다. Hadoop에는 HDFS와 HBase가 있으므로 거기에 저장된 PB 수준의 빅 데이터를 쿼리할 수 있습니다. 이 기술은 계산을 위한 하이브와 메모리를 기반으로 하며 데이터 웨어하우스를 고려하여 실시간 일괄 처리 및 다중 동시 처리를 제공합니다. 클라이언트는 임팔라드 네트워크 내의 노드에 쿼리 요청을 보냅니다. 여기서 쿼리 ID는 후속 클라이언트 작업에 대해 반환됩니다. 분석기 생성 프로세스의 첫 번째 단계에서 독립 실행형 실행 계획(단일 머신 계획, 분산 실행 계획)이 생성되고 조인 순서 변경, 술어 푸시다운 등과 같은 SQL도 실행됩니다. 모든 노드는 루프에서 제외되지 않도록 최신 메타 데이터 정보의 복사본을 유지합니다. Hadoop, Hive 또는 Impurbia를 사용하기 전에 먼저 필요한 데이터 처리 소프트웨어를 설치해야 합니다.
Impala의 구성 파일을 변경할 수 있습니다. 모든 노드는 Impala에서 구성 변경을 수행합니다. 모든 노드는 MySQL 드라이버 패키지를 데이터베이스에 연결하는 역할을 합니다. 노드는 Bigtop의 Java 경로를 변경합니다.
하이브와 임팔라의 비교
이 세 가지 주요 차이점 외에도 몇 가지 사소한 차이점이 있습니다. Hive에는 HiveQL의 하위 집합이 있는 반면 Implicit에는 HiveQL의 하위 집합이 있습니다. Hive와 Impala는 각각 데이터 웨어하우징과 대화형 쿼리에 사용됩니다. Impala와 달리 Hive는 대화형 컴퓨팅을 위한 것이 아닙니다.
하둡에서 임팔라는 무엇인가
Impala는 Hadoop 클러스터에 저장된 데이터를 위한 오픈 소스 SQL 쿼리 엔진입니다. HDFS, HBase 또는 기타 Hadoop 데이터 소스 에 저장된 데이터에 대한 빠른 대화형 SQL 쿼리를 제공하도록 설계되었습니다.
Impala는 친숙한 Hadoop 구성 요소를 광범위하게 사용합니다. INSERT는 Impala가 읽을 수 있는 유형의 데이터만 쓸 수 있는 반면 SELECT는 Impala가 읽을 수 있는 유형의 데이터를 읽을 수 있습니다. Avro, RCFile 또는 SequenceFile 파일 형식을 사용하는 경우 데이터가 Hive에 로드됩니다. 테이블 및 컬럼 통계 외에도 테이블 통계 및 컬럼 통계를 사용할 수 있습니다. 모든 DDL 및 DML 문은 카탈로그 데몬을 통해 전송되는 경우 Impala 1.2 이상에서 카탈로그 데몬을 사용하여 자동으로 업데이트됩니다. INVALIDATE METADATA 메서드는 액세스한 메타스토어의 모든 테이블에 대한 메타데이터를 반환합니다. 데이터 파일은 새 테이블의 디렉터리에 저장되며 Impala가 실행될 때 파일 이름에 관계없이 읽힙니다.
전반적으로 Apache Hive는 데이터 웨어하우징 플랫폼으로 잘 작동하는 반면 Impala는 병렬 처리에 더 적합합니다. Hive는 내결함성이 있지만 Impulsa는 그렇지 않습니다.
아파치 임팔라
Apache Impala는 Apache Hadoop용 빠른 대화형 SQL 쿼리 엔진입니다. 이를 통해 사용자는 데이터 이동이나 변환 없이 HDFS 및 Apache HBase에 저장된 데이터에 대해 대기 시간이 짧은 SQL 쿼리를 실행할 수 있습니다.
Impala의 아키텍처 개념을 통해 HDFS를 사용하여 다른 어떤 쿼리 엔진보다 효율적으로 대화형 쿼리를 처리할 수 있습니다. Hive는 디스크 I/O 작업으로 인해 훨씬 느리지만 Apache는 완전히 다른 엔진이기 때문에 훨씬 빠릅니다. Impulsa는 훨씬 더 빠른 기술을 사용하고 Presto는 유사한 아키텍처를 사용하기 때문에 Impulsa와 Presto 사이에는 차이가 없습니다. Parquet 파일의 경우 Impala가 가장 잘 수행합니다. 분석가의 쿼리를 기반으로 분할해야 하는 데이터를 결정합니다. Compute Stats Statistics를 사용하면 특히 둘 이상의 테이블(조인)이 관련된 경우 쿼리가 훨씬 쉬워집니다. 일주일에 네 번 Impala 카탈로그 서버 충돌이 발생했고 쿼리를 완료하는 데 너무 오래 걸렸습니다.
또한 생성하는 파일의 양은 쿼리 성능에 큰 영향을 미칩니다. 결과적으로 우리는 파티션을 관리하고 약 256MB의 최적 파일 크기로 병합하기 시작했습니다. 각 파티션에는 하나의 파일만 있다고 명시되어 있습니다(크기가 > 256MB가 아닌 경우). Implicit에서 지원하는 모든 데이터 유형 중에서 가장 적합한 컬럼 유형을 선택해야 합니다. 사용자가 액세스하는 동시 쿼리 또는 Y 메모리 수를 제한하려면 Impala 승인 제어를 사용하십시오. 쿼리가 30분 이상 지속되면 죽은 것으로 간주됩니다.
빅 데이터를 위한 최고의 엔진: Impala
Impala 엔진은 대규모 클러스터용으로 특별히 설계된 Hadoop 데이터 처리 엔진 입니다. Hadoop의 표준 MapReduce 엔진보다 훨씬 적은 에너지와 훨씬 적은 자원을 사용합니다. Implicit은 분산 파일 시스템 HDFS를 기본 데이터 저장 매체로 사용하며 HDFS의 중복성에 의존하여 노드별로 하드웨어 또는 네트워크 중단을 방지합니다. 테이블 데이터를 나타내는 데이터 파일은 친숙한 HDFS 파일 형식과 압축 코덱으로 물리적으로 표현됩니다.
병렬 처리 쿼리 엔진
병렬 처리 쿼리 엔진은 쿼리를 병렬로 처리하도록 설계된 데이터베이스 엔진 유형입니다. 이는 다중 프로세서, 다중 코어 또는 다중 시스템을 사용하여 수행할 수 있습니다. 병렬 처리는 특히 복잡한 쿼리의 경우 쿼리 엔진의 성능을 크게 향상시킬 수 있습니다.
멀티프로세서 컴퓨터는 복잡한 쿼리를 동시에 실행할 수 있는 실행 계획으로 변환하여 한 번에 많은 양의 데이터를 처리할 수 있도록 하는 데 사용됩니다. 고성능을 위해서는 우수한 쿼리 응답 시간 또는 높은 쿼리 처리량과 같은 효율적인 실행이 필요합니다. 효율적인 병렬 실행 기술과 쿼리 최적화를 사용하여 수행됩니다.
병렬 처리: Etl의 미래?
높은 수준의 쿼리는 병렬 쿼리 처리를 사용하여 다중 프로세서 컴퓨터에서 효율적으로 실행할 수 있는 실행 계획으로 변환될 수 있습니다. 병렬 처리는 병렬 및 분산 데이터를 결합하는 기술과 병렬 데이터베이스 시스템 에서 제공하는 다양한 실행 기술을 사용합니다. 병렬 쿼리 처리는 ETL에서 전송하도록 할당된 각 소스 테이블의 레코드 집합을 동일한 크기의 청크로 나눈 다음 각 소스 테이블에 대한 데이터 변환 프로세스를 주기로 수행하여 데이터를 청크별로 연속적으로 선택함으로써 구현됩니다. .