
NoSQL 데이터베이스: 복제를 통한 고가용성 및 확장성
게시 됨: 2022-11-19다양한 유형의 NoSQL 데이터베이스가 있으며 각각 고유한 기능과 기능이 있습니다. 그러나 많은 NoSQL 데이터베이스의 공통된 특징 중 하나는 여러 서버에 걸쳐 데이터를 복제하는 기능입니다. 복제는 여러 서버에서 데이터를 사용할 수 있도록 한 서버에서 다른 서버로 데이터를 복사하는 프로세스입니다. 복제는 여러 서버에서 데이터를 읽을 수 있도록 하여 향상된 가용성과 성능을 제공할 수 있습니다. NoSQL 데이터베이스는 일반적으로 한 서버가 마스터로 지정되고 다른 모든 서버는 슬레이브로 지정되는 마스터-슬레이브 복제 모델을 사용합니다. 마스터 서버는 데이터 사본을 유지하고 변경 사항을 슬레이브에 복제합니다. 슬레이브는 데이터를 읽는 데 사용할 수 있지만 모든 쓰기는 마스터를 거쳐야 합니다. 복제의 장점 중 하나는 읽기를 여러 서버에 분산시켜 성능을 향상시키는 데 도움이 된다는 것입니다. 복제는 한 서버에 장애가 발생할 경우 여러 데이터 복사본을 제공하여 가용성을 향상시킬 수도 있습니다. NoSQL 데이터베이스는 일반적으로 여러 서버에 걸쳐 데이터를 복제하는 기능으로 인해 고가용성과 확장성을 제공합니다.
마찬가지로 NoSQL 데이터 복제 는 정형, 비정형 및 반정형 데이터를 원활하게 복사 및 저장하고 서버 충돌 시 데이터 손실을 방지할 수 있는 강력한 기능입니다. 이 사이트에서 NoSQL 데이터베이스에 대해 자세히 알아보세요.
마스터-슬레이브 복제와 슬레이브-실행 복제가 모두 발생하고 마스터-슬레이브 복제는 노드를 쓰기와 읽기를 모두 처리할 수 있는 신뢰할 수 있는 복사본으로 지정합니다. 피어 투 피어 복제 프로세스 를 통해 노드는 서로에게 쓸 수 있으며 각 노드는 데이터를 다음 노드로 복사합니다.
MongoDB 복제는 다른 MongoDB 인스턴스 와 공통 데이터 세트를 공유하는 복제 세트 생성을 의미합니다. 복제본 세트에는 데이터를 포함하는 여러 노드가 포함되며 중재자 노드는 선택 사항입니다. 데이터 보유 환경에는 6개의 노드가 있으며 한 구성원은 기본 노드로 지정되고 다른 구성원은 보조 노드로 분류됩니다.
일반적으로 일정량 이상의 결과를 산출하는 실험이나 절차는 성공입니다. 이 경우 DNA 복제가 복사되거나 복제됩니다. 무언가를 복제하는 행위를 복제라고 합니다.
Nosql 데이터 복제란 무엇입니까?
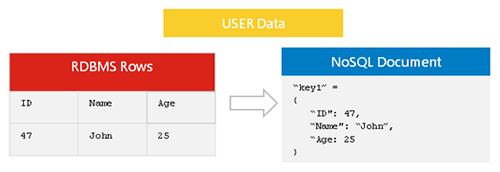
Nosql 데이터 복제는 한 nosql 데이터베이스 에서 다른 데이터베이스로 데이터를 복사하는 프로세스입니다. 백업 생성 또는 여러 서버에 데이터 배포와 같은 다양한 이유로 이 작업을 수행할 수 있습니다. Nosql 데이터 복제는 일반적으로 비동기식으로 수행됩니다. 즉, 데이터 복사본이 원본 데이터의 정확한 복제본일 필요는 없습니다.
수년 동안 데이터 복제는 모든 조직의 데이터 인프라의 필수 구성 요소였습니다. 데이터 복제 시스템은 고가용성, 백업 및 재해 복구를 보장하여 데이터를 보호합니다. 또한 복제는 데이터 일관성과 정확성을 향상시키는 조직의 능력을 지원합니다. 복제 프로세스를 통해 데이터 신뢰성을 향상시키는 방법입니다. 데이터를 복제하면 재해 발생 시 항상 사용 가능하고 백업되도록 할 수 있습니다. 데이터를 복제함으로써 일관성과 정확성도 향상시킬 수 있습니다. 데이터 인프라를 설계할 때 데이터 복제를 고려하는 것이 중요합니다.
Nosql에서 샤딩 및 복제란 무엇입니까?
샤딩과 복제의 차이점은 무엇입니까? 기본 서버 노드는 데이터 복제의 일부로 보조 서버 노드에서 데이터를 복사합니다. 그렇게 함으로써 데이터의 가용성을 높이고 기본 서버에 장애가 발생할 경우 비상 백업으로 만들 수 있습니다. 샤드 키를 사용하여 수평면에서 서버의 확장을 관리합니다.

Nosql 데이터베이스에 데이터 중복성이 있습니까?
상당한 양의 데이터가 있고 데이터 중복성 을 허용할 수 있는 경우 NoSQL 데이터베이스는 특정 유형의 애플리케이션과 선택적 사용 사례에 가장 적합합니다.
Nosql을 샤딩할 수 있습니까?
마이크로서비스 패턴에 의한 파티셔닝은 NoSQL 환경에서 사용됩니다. 이 패턴은 각 파티션을 여러 서버로 나누는 것을 수반하며, 이 서버는 전 세계 동일한 위치에 있을 수도 있고 없을 수도 있습니다. 이 확장은 데이터 세트의 다른 부분에 액세스하고 고성능을 달성하려는 전 세계 사람들에게 적합합니다.
데이터베이스에서 복제란 무엇입니까?
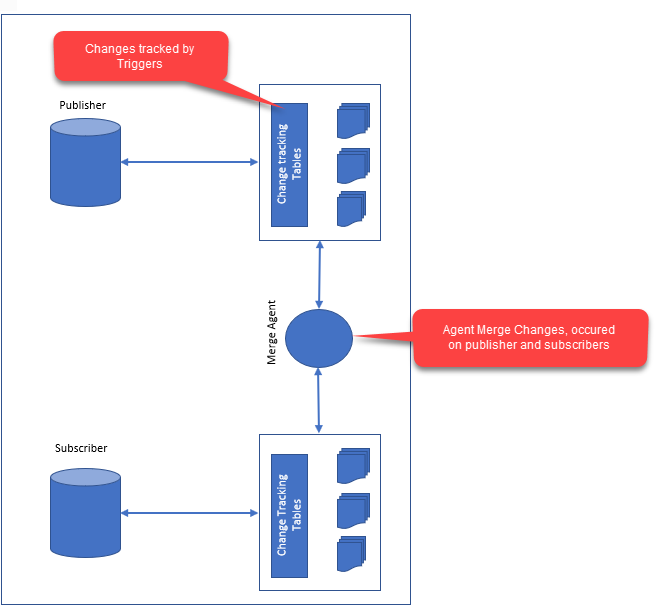
데이터베이스의 복제는 원본 데이터베이스에서 대상 데이터베이스로 데이터를 복사하는 프로세스입니다. 두 데이터베이스는 동일한 서버 또는 다른 서버에 있을 수 있습니다. 복제를 사용하여 데이터 백업을 생성하거나 데이터를 여러 서버에 배포하거나 여러 사용자가 데이터에 액세스할 수 있습니다.
데이터 무결성과 성능은 오늘날 데이터 복제 의 중요한 측면입니다. 데이터 재작성은 구독자에게 보내는 것처럼 간단할 수도 있고 한 번에 여러 실험을 수행하는 것처럼 복잡할 수도 있습니다. 가장 일반적인 복제 형식은 스냅샷 복제입니다. 데이터의 양이 많거나 가입자가 원격인 경우 전체 데이터 세트를 전송합니다. 트랜잭션 복제보다 더 발전된 형태의 복제입니다. 경우에 따라 구독자 또는 데이터에만 데이터 수정 사항을 보내므로 작은 파일이나 로컬 파일에 유용할 수 있습니다. 이것은 더 복잡한 복제 기술입니다. 게시자와 구독자 모두에서 항목을 수정할 수 있으므로 데이터가 크거나 게시자와 구독자가 멀리 있는 상황에서 유용할 수 있습니다. 따라서 이기종 데이터의 복제가 가능하여 다양한 데이터베이스 제품에 액세스할 수 있습니다. 이는 게시자 및 구독자와 같은 여러 유형의 컴퓨터가 있는 대규모 데이터에 특히 유용합니다.
Mongodb에서 복제란 무엇을 의미합니까?
MongoDB 복제는 여러 MongoDB 서버의 데이터 세트를 복제하는 방법입니다. 복제 세트를 사용하여 이를 달성할 수 있습니다. 복제본 세트는 동일한 MongoDB 데이터 세트를 제공하고 동일한 프로세스와 연결된 MongoDB 인스턴스의 모음입니다.
복제 세트를 생성할 때 기본 노드가 자동으로 선택됩니다. 사용 가능해지면 보조 노드가 기본 노드가 되며 가장 높은 복제 세트 지정이 지정됩니다. MongoDB 복제 세트 는 기본 노드와 보조 노드의 역할을 지정하고 두 노드를 모두 사용할 수 있는 경우 MongoDB가 자동으로 기본 노드를 구성합니다. 데이터 세트와 프로세스 측면에서 동일한 MongoDB 인스턴스 모음입니다. 데이터베이스 관리자는 데이터를 복제하여 데이터 중복성을 제공할 수 있습니다. 데이터는 널리 사용 가능합니다. 복제 세트는 복제를 위해 그룹으로 구성된 MongoDB 노드 모음입니다. 복제 세트에는 최소 3개의 MongoDB 노드가 있어야 합니다. 3개 노드 중 하나는 모든 쓰기 작업 수신을 담당하는 기본 노드로 간주됩니다. 첫 번째 복제 세트가 생성되면 기본 노드가 자동으로 선택됩니다.