
HDF5 데이터 형식: 대규모 데이터 수집을 저장하고 관리하기 위한 매력적인 옵션
게시 됨: 2023-02-13HDF5는 크고 복잡한 데이터 컬렉션을 저장하고 관리하도록 설계된 데이터 형식입니다. 그것은 과학 및 공학 응용 분야에서 자주 사용되며 최근 몇 년 동안 인기가 높아지고 있습니다. HDF5는 데이터베이스가 아니지만 파일 시스템과 유사한 계층적 형식 으로 데이터를 저장하는 데 사용할 수 있습니다. 따라서 HDF5는 대량의 데이터를 저장하고 관리해야 하는 애플리케이션에 매력적인 옵션입니다.
HDF5 및 netCDF4 파일에서 메타데이터 및 원시 데이터를 추출하고 Hadoop 스트리밍을 사용하여 Hadoop 분산 파일 시스템(HDFS) HDF5 커넥터 가상 파일 드라이버(VFD)를 사용하여 Hadoop 데이터를 분석할 수 있습니다.
Hdf5는 데이터베이스입니까?
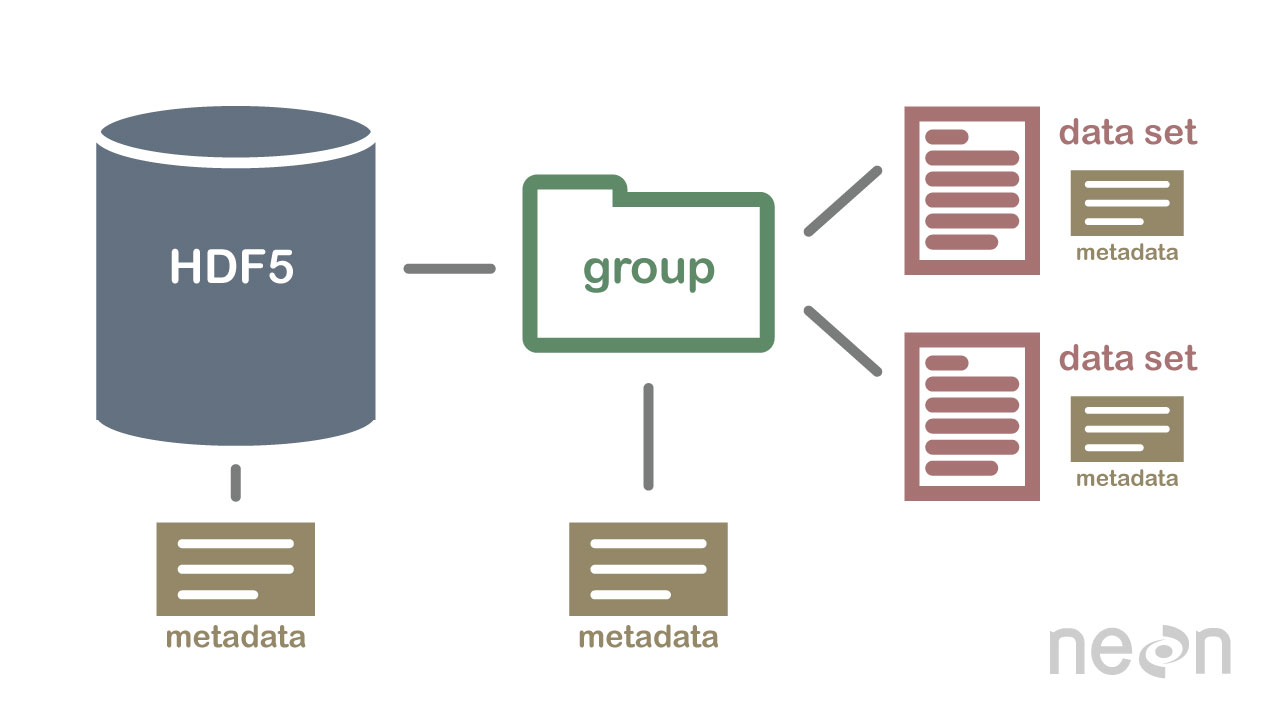
HDF5는 데이터베이스가 아니지만 파일 시스템과 유사한 계층 구조로 데이터를 저장하는 데 사용할 수 있습니다. HDF5는 텍스트, 이미지 및 이진 데이터를 포함한 다양한 형식으로 데이터를 저장하는 데 사용할 수 있습니다.
계층적 형식(HDF5)의 데이터는 과학 연구에 매우 유용합니다. HDF5 파일 시스템은 매우 효율적이라는 점에서 파일 시스템과 유사하므로 탁월한 형식입니다. 이 형식으로 인코딩된 데이터의 경우 액세스하기 어려울 수 있습니다. 이 가이드는 Apache Drill이 HDf5 데이터 세트에 쉽게 액세스하고 쿼리하는 데 어떻게 도움이 되는지 안내합니다. Drill은 defaultPath 옵션을 통해 개별 HDF5 파일에 액세스할 수 있습니다. 이는 쿼리 시간 동안 또는 구성을 통해 table() 함수를 직접 실행하여 수행됩니다. 이 쿼리의 결과는 아래 표에서 확인할 수 있습니다. 그런 다음 Drill은 열을 선택하고 개별적으로 필터링하거나, 필터링하거나, 집계하거나, 쿼리할 수 있는 다른 데이터와 결합할 수 있습니다.
HDF5 사양은 데이터 배열을 저장하기 위한 파일 형식을 정의합니다. 데이터 배열은 문자열, 부동 소수점, 복합 및 정수 데이터를 포함하여 모든 유형의 데이터로 구성될 수 있습니다. 배열은 모든 크기의 데이터를 포함할 수 있으며 모든 모양이 될 수 있습니다. HDF5에서 데이터셋을 생성하기 위해서는 먼저 헤더 파일을 생성해야 합니다. 헤더 파일에는 데이터 세트 및 메타데이터에 대한 정보가 포함됩니다. 헤더 파일에는 데이터 세트의 이름과 데이터 세트의 버전 번호라는 두 가지 중요한 정보가 포함되어 있습니다. 데이터 배열은 데이터 세트의 데이터를 저장하는 데 사용됩니다. 블록은 데이터 배열의 데이터로 구성됩니다. 데이터 배열에서 각 데이터 블록은 연속적인 데이터 세트를 포함합니다. 데이터세트의 블록 수는 데이터세트의 바이트 수에 따라 결정됩니다. HDF5 사양에 따라 다양한 방법을 통해 데이터에 액세스할 수 있습니다. 인덱싱 방법은 데이터 집합에서 데이터를 가져오는 데 가장 일반적으로 사용됩니다. 이러한 방법을 사용하면 액세스하려는 데이터 배열에 블록 이름을 입력하여 데이터에 액세스할 수 있습니다. 구조 방법은 데이터 세트의 데이터에 액세스하는 데 사용할 수 있습니다. 이러한 방법을 사용하면 데이터 배열의 구조를 사용하여 데이터에 액세스할 수 있습니다. 다음 예제에서는 구조 메서드의 오프셋 및 길이 값을 사용하여 데이터 배열의 데이터에 액세스할 수 있습니다. 데이터 세트에서 데이터를 가져오는 또 다른 방법은 함수 메서드를 사용하는 것입니다. 데이터에 대한 헤더 파일에서 함수를 선택하여 방법 중 하나를 사용하여 데이터를 얻을 수 있습니다. 데이터 배열에 접근하는 방법은 헤더 파일의 값을 배열의 데이터 배열 요소로 정의하여 사용할 수 있습니다. 마지막으로 액세스 방법을 사용하여 데이터 세트의 데이터에 액세스할 수 있습니다. 이러한 방법을 사용하면 헤더 파일에 설정된 액세스 권한을 사용하여 데이터에 액세스할 수 있습니다. 즉, 읽기 권한을 사용하면 액세스 방법을 통해 데이터 배열의 데이터에 액세스할 수 있습니다. HDF5 규격을 이용하여 다양한 방법으로 데이터를 생성하고 사용할 수 있습니다. create 메소드는 데이터 세트를 생성하는 가장 일반적인 메소드입니다. create 메서드를 사용하면 데이터셋의 이름과 데이터셋의 버전 번호를 입력하여 데이터셋을 생성할 수 있습니다. HDF5 사양 외에도 다양한 방법으로 데이터 세트를 사용할 수 있습니다. 가장 일반적으로 사용되는 방법.

Hdf5는 관계형 데이터베이스입니까?
HDF5는 관계형 데이터베이스가 아닙니다.
Graphql은 Nosql인가 Sql인가?
GraphQL의 주요 목표는 유형 시스템을 사용하여 데이터를 더 빠르고 효율적으로 반환하는 것입니다. SQL(구조적 쿼리 언어)은 테이블 형식 또는 관계형 데이터베이스 시스템 에 데이터를 저장하는 데 더 오래되고 널리 사용되는 언어입니다. API를 NoSQL 데이터베이스 위에 구축하려면 GraphQL을 사용하는 것이 좋습니다.
Type Mismatch는 Herman Camarena와 Roger Cochrane이 만든 GraphQL 및 NoSQL 데이터베이스입니다. GraphQL을 사용하면 NoSQL 시스템이 아닌 유형 시스템이 도입되어 NoSQL 시스템에서 생성된 유연성이 제거될 수 있습니다. GraphQL 컬렉션에는 구조가 일관되고 몇 가지 예외가 포함된 다양한 문서가 포함되어 있습니다. GraphQL에는 백엔드 유형과 일치하는 데이터 유형 세트가 내장되어 있으므로 개발자는 생성할 데이터 유형을 선택할 수 있습니다. GraphQL은 잠재력을 완전히 실현하기 위해 유형 불일치 문제를 해결해야 합니다. 기능면에서 많은 장점으로 인해 낮은 수준의 불일치 솔루션을 제공합니다. 작업은 StepZen의 JSON2SDL과 같은 도구로 점점 더 자동화됩니다.
보다 탄력적이고 효율적인 애플리케이션을 만드는 데 사용할 수 있는 강력한 도구이지만 SQL은 대체할 수 없습니다. 유지 관리 측면에서 이것은 일부 작업을 더 어렵게 만들기 때문에 부정적인 영향을 미칠 수 있습니다.
Graphql: 모든 데이터베이스를 위한 쿼리 언어
GraphQL 쿼리 언어를 사용하면 클라이언트와 서버가 서로 통신할 수 있습니다. GraphQL 인스턴스는 데이터 소스 또는 영구 상태에서 변경 사항을 검색하고 유지할 수 있습니다. 확인자는 데이터에 액세스하고 조작하는 데 사용되는 임의의 함수 집합입니다. API는 다양한 데이터베이스에서 사용할 수 있으며 GraphQL은 어느 데이터베이스와 함께든 사용할 수 있습니다. MongoDB 데이터베이스는 다양한 유형의 데이터에 독립적인 널리 사용되는 데이터 소스 데이터베이스 입니다.
Nosql은 B 트리를 사용합니까?
NOSQL 데이터베이스는 관계형 모델을 기반으로 하지 않기 때문에 B 트리를 사용하지 않습니다. NOSQL 데이터베이스는 종종 키-값 쌍, 문서 저장소 또는 그래프 데이터베이스를 기반으로 합니다.
B-트리는 MongoDB의 기본 인덱싱 구조입니다. 데이터 저장 에서 B-트리는 보다 효율적인 방법입니다. 정수와 문자열을 함께 사용하는 경우 데이터를 구성할 수 있습니다. 따라서 데이터 양이 많은 데이터베이스는 사용을 고려해야 합니다. B 트리는 많은 공간을 차지할 수 있기 때문에 효율적인 모델입니다. 이는 많은 양의 데이터를 유지해야 하는 데이터베이스에 유용합니다. B-트리는 특정 방식으로 데이터를 구성해야 하는 데이터베이스에도 적합합니다.
어떤 데이터베이스가 B-트리를 사용합니까?
오랫동안 사용되어 왔으며 광범위한 데이터베이스에서 사용할 수 있습니다. NoSQL 데이터베이스는 B-트리 엔진 외에도 B-트리 엔진 위에 구축할 수 있습니다. 예를 들어 MongoDB는 B-트리의 데이터를 인덱싱합니다. 몇 가지 예외가 있지만 알고리즘은 DBMS에서 관계형 데이터베이스와 동일합니다. 문자열과 정수를 사용하여 B-트리에서 데이터를 구성할 수 있습니다.
어떤 데이터베이스가 B-트리를 사용합니까? 다음 기사에서 Mysql은 Btree와 B+tree를 모두 사용합니다. SQL Server는 BTree 형식의 키 기반 지속 데이터를 기반으로 인덱스를 저장합니다. 결과적으로 이러한 트리의 각 노드는 단일 페이지로 나타납니다.