
MarkLogic의 힘: 한 곳에서 빅 데이터 관리 및 보안
게시 됨: 2023-01-29MarkLogic은 조직이 대량의 데이터를 쉽고 빠르게 저장, 관리 및 검색할 수 있도록 하는 강력한 Nosql 데이터베이스입니다. 확장성이 뛰어나고 고성능을 제공하므로 빅 데이터 애플리케이션에 이상적입니다. 또한 MarkLogic에는 무단 액세스로부터 데이터를 보호하고 데이터 무결성을 보장하는 보안 기능이 내장되어 있습니다.
대량의 데이터를 보다 유연하고 효율적으로 저장하는 방법에 대한 요구에 부응하여 NoSQL이라는 움직임이 탄생했습니다. 이 게시물은 이 새로운 분야에 관심이 있는 모든 사람을 위한 일반적인 입문서입니다. 이러한 노력은 RDBMS 세계 에 존재하는 특정한 한계를 완화하기 위해 만들어졌습니다. 일부 NoSQL 옵션에서는 조인이 불가능하므로 데이터의 여러 복사본을 유지해야 합니다. 글로벌 인덱스가 부족하고 데이터가 검색에 사용되는 키를 사용하여 상용 서버 간에 분할된다는 사실 때문일 가능성이 큽니다. NoSQL 사용자는 Lucene, Solr 및 Sphinx와 같은 전체 텍스트 검색 엔진을 기대하게 되었지만 최고는 아닙니다. MarkLogic 스케일 아웃 솔루션은 페타바이트 용량의 상용 하드웨어에 수평으로 배포할 수 있는 것으로 입증되었습니다.
이는 그 자체로 다른 데이터베이스와는 매우 다른 유형의 데이터베이스입니다. MarkLogic은 특정 문제를 해결할 수 있도록 만들어지지 않았습니다. 처음부터 규모에 관계없이 엔터프라이즈급 애플리케이션을 위한 플랫폼으로 구축되었습니다.
MarkLogic의 차세대 운영 데이터 웨어하우스는 운영 분석을 수행하기 위한 소프트웨어 도구입니다.
http://localhost:8000/appservices/로 이동하여 Application Services 페이지를 찾습니다. MarkLogic Server 의 데이터베이스 섹션을 사용하면 모든 데이터베이스에 액세스하고 데이터베이스를 삭제할 수 있을 뿐만 아니라 데이터베이스를 만들고 구성할 수 있습니다.
Marklogic은 어떤 데이터베이스를 사용합니까?
오늘날 대부분의 조직은 작업을 실행하기 위해 데이터베이스가 필요합니다. 데이터 센터에서 트랜잭션, 운영 및 분석 애플리케이션을 실행하고 광범위한 데이터 소스를 안전하게 관리하는 데 사용됩니다.
MarkLogic의 플랫폼은 콘텐츠의 동시 로드, 쿼리, 조작 및 렌더링을 허용합니다. 자동으로 XML로 변환되어 인덱싱되면 콘텐츠를 빠르게 검색할 수 있습니다. Big Publishing은 XML 요소 쿼리, XML 근접 검색 및 전체 텍스트 검색을 사용하여 검색 기능을 개선했습니다. 4~5개월 내에 회사는 솔루션을 배치하고 사용을 시작할 수 있습니다. Quakezone 카운티 정부는 카운티 직원, 개발자 및 주민들이 보다 쉽게 실시간 정보에 액세스할 수 있도록 하고자 합니다. 빠르고 쉽게 구현될 IT 인프라 솔루션이 필요합니다. MarkLogic을 사용하여 카운티는 데이터를 변환하고 강화하는 등 다양한 방법으로 데이터를 보고 상호 연관시킬 수 있습니다.
Time Traders Services는 기존 시스템을 MarkLogic Server로 교체했습니다. 이 솔루션은 고객의 포털과 이메일에 즉각적이고 관련 있는 정보를 제공하면서 경보 대기 시간 측면에서 크게 줄어듭니다. 금융 거래자는 고객에게 이용 가능한 새로운 연구를 알려줌으로써 사무실과 거래 현장에서 이점을 얻습니다. MarkLogic은 연방 정부의 일급 비밀 시설을 유지 관리하는 데 사용됩니다. Exchange는 MarkLogic이 상용 하드웨어를 최적화할 때 하드웨어 시스템 비용을 절감할 수 있습니다. 고성능을 사용하면 경쟁할 하드웨어 서버가 더 적습니다. 더 크고 더 비싼 서버를 구입하는 대신 확장성이 향상되어 더 많은 상용 서버를 설치할 수 있습니다.
MarkLogic Data Hub 의 주요 이점 중 하나는 다른 데이터 소스와 통합할 수 있는 기능입니다. 이 소프트웨어는 ERP 및 CRM과 같은 레거시 시스템은 물론 고객 데이터 웨어하우스 및 스트리밍 데이터 소스와 같은 최신 소스에 쉽게 연결할 수 있습니다. 또한 MarkLogic Data Hub는 광범위한 데이터 형식을 처리할 수 있어 데이터 수집이 간편합니다. 마지막으로 MarkLogic Data Hub는 사용이 매우 쉽습니다. 무료 프로그램이므로 사용하기 위해 비용을 지불할 필요가 없습니다. 또한 이 프로그램은 오픈 소스이므로 특정 요구 사항에 맞게 사용자 지정할 수 있습니다.
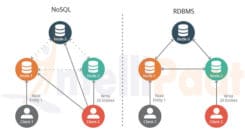
다중 모델 데이터베이스: 두 세계의 장점
다음 표에는 다중 모델 데이터베이스에 대한 가장 일반적인 데이터베이스 유형이 나열되어 있습니다. 다중 모델 데이터베이스를 사용하면 유지 관리 비용이 적게 드는 데이터 모델을 선택할 수 있습니다. MarkLogic의 검색 스타일 인덱싱 및 트랜잭션 데이터 스토리지를 통해 시스템 내에서 데이터를 결합하고 보강할 수 있습니다. 결과적으로 ETL 프로세스를 실행하는 데 사용할 수 있습니다. 또한 MarkLogic은 그래프 데이터베이스이기 때문에 그래프 데이터베이스를 찾는 사람들에게 탁월한 트리플 스택 옵션입니다.
LDAP는 Nosql입니까?
각 NoSQL 데이터베이스에는 자체 프로토콜이 있기 때문에 하나를 선택하면 기본적으로 해당 데이터베이스 유형에 갇히게 됩니다. 서버를 변경해야 한다면 클라이언트도 변경해야 합니다.
Pearson Education에서 사용 중일 때 NoSql은 온라인 수업, 학생 기록 등을 호스팅하는 데 사용되었습니다. 이 경우 팀의 모든 구성원이 Mongo를 신속하게 시작하고 실행해야 했습니다. 전 세계 수십만 대의 서버와 데스크톱에서 사용하는 Ldap 서비스를 잊기 쉽습니다. 389-ds 콘솔 도구를 사용하면 새 객체와 속성을 쉽게 만들 수 있습니다. 클라우드 컴퓨팅 측면에서 wan 복제(멀티마스터)를 보장하기 위해 각 영역에 두 개의 마스터 디스크를 배치합니다. 복제 수준을 미세 조정할 수 있습니다. 스키마를 수정하려면 온라인에서 수정할 수 있습니다.
Nosql의 예는 무엇입니까?
NoSQL 데이터베이스가 사용되는 대부분의 산업은 다양한 목적을 위해 NoSQL 데이터베이스에 의존하고 있습니다. 주어진 경우에 사용되는 NoSQL 데이터베이스 유형은 해당 작업에 영향을 미칩니다. MongoDB와 같은 문서 데이터베이스는 범용 데이터베이스 의 예입니다. 많은 양의 데이터를 키-값 데이터베이스에 저장할 수 있으므로 조회 쿼리가 간단해집니다.
Nosql 데이터베이스의 이점
기존의 관계형 데이터베이스와 달리 NoSQL 데이터베이스는 훨씬 더 동적이고 방대한 데이터 저장소를 허용하는 보다 유연한 구조를 선호하여 기존 데이터 구성 모델에서 탈피한다는 점에서 기존 관계형 데이터베이스와 다릅니다. 이것은 더 많은 트래픽을 위해 데이터 저장소를 확장하거나 다양한 사용자 요구 사항을 충족해야 할 때 이점이 있습니다. NoSQL 데이터베이스에서 사용할 수 있는 고유한 이점으로 인해 항상 인기가 높아지고 있으며 모든 애플리케이션이 이점을 누리는 것은 아닙니다. 더 넓은 범위의 요구 사항을 처리할 수 있는 보다 유연한 데이터 저장소를 찾고 있다면 NoSQL 데이터베이스가 탁월한 선택입니다.
Uber는 SQL 또는 Nosql을 사용합니까?
알고리즘이 없는 데이터베이스를 사용하여 데이터를 저장하는 경우 이를 NoSQL 데이터베이스라고 합니다. NoSQL 데이터베이스는 인덱스 지원이 부족하기 때문에(분산 트랜잭션이 없기 때문에) Uber의 주문 처리 팀은 별도의 테이블을 사용하여 인덱스를 저장합니다.
Uber는 Uber가 PostgreSQL에서 InnoDB로 전환한 이유를 설명하는 기사를 웹사이트에 게시했습니다. 이 게시물은 더 나은 이해를 제공하기 위해 Uber 기사로 구성되었습니다. PostgreSQL은 이 문서에 자세히 설명된 대로 테이블을 인덱싱할 때 행을 업데이트할 때 항상 테이블의 모든 인덱스를 업데이트해야 합니다. 이 접근 방식을 사용하면 인덱싱되지 않은 열을 변경하는 업데이트에 대한 디스크 IO도 증가합니다. 이 문서에서는 클러스터형 인덱스 페널티를 가벼운 단점으로 설명합니다. 이는 보조 인덱스를 사용하여 많은 쿼리를 실행하는 경우 중요합니다. 기사에서는 이 패널티가 select 뿐만 아니라 where 절이 있는 모든 문에 적용된다는 언급을 하지 않습니다. 반면에 Postgres 인덱스 전용 스캔은 매우 쓸모가 없습니다.
향후 중요한 키 저장소 사용 사례에서 잘 작동하는 것으로 보입니다. SQL 프런트 엔드와 함께 작동하도록 의도된 패키지(그러나 기능은 거의 없음)를 사용할 수 있습니다. Uber는 InnoDB 및 MariaDB를 사용하는 것 외에도 자체 데이터베이스(Schemless)를 만들었습니다. 노드 분할은 B-트리에서 중요한 작업입니다. 노드 분할은 하나 이상의 노드가 새 항목을 호스트할 수 없을 때 발생합니다. 최악의 시나리오에서 분할은 루트 노드까지 버블링되며 루트 노드도 분할되고 새 노드로 대체됩니다. 결과적으로 트리 전체가 쓰러져 지수의 균형이 일정하게 유지됩니다.
복제 프로세스의 버그로 인해 트리의 많은 부분을 완전히 복구할 수 없게 될 수 있습니다. 마스터는 복제본이 수행하려는 작업을 결정할 수 없으며 쿼리를 완료하는 데 여전히 필요한 데이터를 삭제할 수 있습니다. 이 문제는 복제 스트림의 응용 프로그램을 구성 가능한 시간 초과로 지연시켜 읽기 트랜잭션이 차례대로 진행되도록 함으로써 해결할 수 있습니다. 일부 엔지니어는 데이터베이스 전문가가 아니며 이 문제를 항상 이해하지 못할 수도 있습니다. 특히 열린 트랜잭션과 같은 낮은 수준의 세부 정보를 가리는 ORM을 사용할 때 그렇습니다. 대부분의 개발자는 트랜잭션을 사용하여 쓰기를 취소할 수 있음을 알고 있습니다. 더 많은 사람들이 회사에 고용되면 그들의 자격은 평균에 가까워집니다. 샘플 크기의 증가는 더 많은 사람을 고용함으로써 이루어집니다.
Uber의 사용 사례에서는 새로운 NoSQL 데이터베이스 인 Schemaless를 사용해야 했습니다. 그들의 기사는 Postgres가 MySQL로 대체되었다고 제안하지만 이것은 사실이 아닙니다. 대신, 그들의 맞춤형 솔루션은 MySQL에 의해 지원됩니다. 이 기사에서는 MySQL에서 PostgreSQL로 전환했을 때 요구 사항이 어떻게 변경되었는지에 대한 언급이 없으므로 알 수 있는 방법이 없습니다. 독자의 마음에 단 한 가지만 눈에 띕니다. Postgres는 끔찍합니다.
Nosql 데이터베이스가 Ube에 완벽한 이유
Uber의 MySQL 데이터베이스는 NoSQL 데이터베이스 위에 구축되어 있기 때문에 이 데이터베이스를 사용하고 있다는 것을 텍스트에서 유추할 수 있습니다. 또한 이 NoSQL 데이터베이스가 데이터를 캐시하고 큐에 저장하는 데 사용되고 있음을 데이터에서 추론할 수 있습니다. Amazon은 데이터베이스 기반 애플리케이션 개발을 위한 포괄적인 도구 세트를 제공하는 또 다른 NoSQL 데이터베이스 회사입니다.
마크로직 Nosql
MarkLogic은 개발자가 대량의 데이터를 처리하는 애플리케이션을 쉽고 빠르게 구축할 수 있게 해주는 강력한 NoSQL 데이터베이스입니다. MarkLogic은 사용하기 쉽고 확장하기 쉬우므로 대량의 데이터를 관리해야 하는 조직에 이상적인 선택입니다.
MarkLogic Server는 처음부터 사용자가 대량의 이기종 데이터를 쉽게 검색할 수 있도록 구축된 데이터베이스입니다. MarkLogic은 데이터베이스 내부, 검색 스타일 인덱스 및 애플리케이션 서버 동작을 동시에 실행할 수 있는 통합 시스템으로 통합합니다. XML 및 JSON 문서는 데이터 모델로 사용되며 트랜잭션 데이터는 트랜잭션 데이터 저장소 에 저장됩니다. 문서 데이터는 XML 또는 JSON으로 시작할 수 있지만 수집된 후에는 변환될 수도 있습니다. 문서 데이터 모델은 일반적으로 동일한 문서의 모든 관련 데이터를 포함하므로 데이터가 공개되기 전에 비정규화됩니다. XML 콘텐츠는 문서의 콘텐츠 모델 클래스를 나타내는 스키마로 정의할 수 있습니다. 특정 문서를 특정 방식으로 구성해야 하는 경우 문서에 대한 식별자를 갖는 것이 중요합니다.
XML 스키마는 Schemas 데이터베이스로 가져오거나 Config 디렉토리에 배치할 수 있습니다. 그런 다음 특정 앱 서버 또는 서버 그룹에 대한 스키마 집합을 지정할 수 있습니다. MarkLogic은 또한 SQL Data Modeling Guide에 정의된 대로 SQL 보기에 대한 컨텍스트를 제공하는 가상 SQL 스키마를 지원합니다. MarkLogic Server는 메모리에 저장된 RDF 트리플에서 시맨틱 데이터를 검색, 저장 및 관리할 수 있습니다. Semantics는 기계가 읽을 수 있는 데이터(및 데이터 간의 관계에 대한 정보) 교환을 허용하는 일련의 W3C 표준입니다. MarkLogic을 사용하면 기본 SPARQL 및 SPARQL 업데이트와 JavaScript, XQuery 및 REST를 사용하여 이러한 유형의 데이터를 저장, 검색 및 관리할 수 있습니다. MarkLogic Server의 메커니즘 제품군을 사용하여 이진 데이터 관리를 최적화할 수 있습니다.

이진 문서는 일련의 임계값에 의해 결정되는 크기에 따라 저장될 수 있습니다. MarkLogic은 동시에 여러 프로세서용으로 설계된 단일 스레드 응용 프로그램입니다. 외부 통신에 사용할 수 있는 다양한 소켓 포트가 있습니다. MarkLogic 플랫폼 은 속도와 확장성을 모두 제공하도록 설계되었습니다. MarkLogic의 고급 쿼리는 테라바이트 단위의 데이터로 작성됩니다. 가장 큰 라이브 배포는 이제 200테라바이트와 10억 개의 문서를 초과했습니다. 클러스터를 사용하면 높은 수준의 가용성이 달성됩니다.
이 유형의 서버는 일반적으로 4개 또는 8개의 코어, 64GB 또는 128Gb 또는 더 큰 용량의 상자에 들어 있습니다. Elastic Load Balancer(ELB)는 Amazon Elastic Compute Cloud(EC2)에 내장되어 있어 MarkLogic 클러스터 가 애플리케이션 트래픽을 자동으로 분산하고 균형을 맞출 수 있습니다. EC2 환경의 가용성을 향상시키기 위해 D-노드를 같은 위치에 클러스터링할 수 있습니다.
Marklogic 데이터베이스란?
MarkLogic은 개발자가 모든 유형의 데이터로 작업하는 데 필요한 도구를 제공하여 애플리케이션을 더 빠르게 구축할 수 있게 해주는 강력한 NoSQL 데이터베이스입니다. MarkLogic은 문서 지향 데이터베이스의 기능과 키-값 저장소의 유연성을 결합한 유일한 NoSQL 데이터베이스로, 오늘날의 최신 애플리케이션에 이상적인 플랫폼입니다.
데이터 관리를 위한 통합 시스템을 제공하는 강력한 데이터 관리 플랫폼입니다. XML 및 JSON의 문서 데이터 모델이 사용되며 트랜잭션 저장소에 문서를 저장합니다. 데이터 허브는 데이터 레이크 위에 위치하며, 선별되고 안전하며 중복 제거되고 인덱싱되며 쿼리 가능한 고품질 데이터를 포함합니다. 또한 MarkLogic Data Hub는 데이터 레이크에서 데이터를 안전하게 저장하고 검색하는 자동화된 데이터 계층화를 통해 대규모 데이터 세트를 관리하도록 설계되었습니다.
그래프 데이터베이스가 대체되는 이유
그래프 데이터베이스는 수동으로 관리하기 어려운 다양한 형식으로 데이터를 저장하기 위한 이동 옵션으로 빠르게 자리잡고 있습니다. 기존의 SQL 데이터베이스 는 이러한 유형의 쿼리를 처리할 수 없으며 이러한 유형의 쿼리를 처리하는 데 매우 유용할 수 있습니다. SQL 데이터베이스가 처리할 수 있는 방식으로 데이터를 쿼리해야 하고 데이터를 그래프에 저장해야 하는 경우 MarkLogic이 좋은 선택입니다.
Marklogic 데이터베이스 대 Mongodb
MarkLogic의 엔터프라이즈 NoSQL 데이터베이스에는 필요한 모든 기능이 하나의 플랫폼에 포함되어 있습니다. 반면에 MongoDB는 대규모 아이디어를 구성하는 데 사용됩니다. MongoDB는 다양한 방식으로 구조화할 수 있는 JSON 유사 문서에 데이터를 저장하는 MongoDB 서비스입니다.
META 데이터가 있는 경우 모든 것을 매우 빠르게 검색하기 때문에 MarkLogic을 사용할 수 있습니다. 필요한 경우 관계형 데이터베이스를 사용하는 것보다 더 나은 대안이 있습니다. MongoDB는 놀라운 유연성과 사용 편의성으로 인해 다양한 애플리케이션을 위한 놀라운 도구입니다. 거의 모든 분야에서 오픈 소스가 사용된다는 사실에도 불구하고 백엔드 데이터베이스는 매우 중요합니다. MarkLogic의 고객 지원은 매우 신속하고 전문적입니다. 그들은 주요 문제와 생산 품질 문제에 신속하게 대응합니다. 나는 MongoDB의 리소스를 사용하여 그 힘의 일부를 활용할 수 있기를 고대하고 있습니다.
몇 가지 측면만 개선하거나 더 간단하게 만들 수 있습니다. MongoDB에 대해 잘 아는 DBA 또는 시스템 관리자가 아직 없는 경우 해당 분야를 전문으로 하는 MongoDB 호스팅 공급자와 함께 가야 합니다. 데이터 세트가 커지면 Cassandra의 스토리지 엔진을 사용하여 지속적인 쓰기를 생성할 수 있습니다. MongoDB는 기본 Hadoop 지원을 사용하여 분석에 사용할 수 있습니다.
Marklogic 그래프 데이터베이스
MarkLogic은 그래프 데이터베이스입니다. 그래프 데이터 모델을 사용하여 데이터를 저장하고 쿼리합니다. 그래프 데이터베이스는 그래프 데이터 모델을 사용하여 데이터를 저장하고 쿼리하는 데이터베이스입니다.
Semantic Graph Developer's Guide는 Semantic Graph 분야에 관심이 있는 모든 사람이 반드시 읽어야 할 책입니다. 이 가이드에 포함된 항목은 다음과 같습니다. 데이터를 다운로드할 수 있습니다. Persondata의 DBPedia 전체 샘플(Turtle 및 영어 모두)을 사용하여 Turtle 또는 영어 단어를 사용하는 방법을 보여줄 수 있습니다. 문서 데이터베이스에는 기본적으로 활성화할 수 있는 삼중 인덱스와 컬렉션 어휘가 있습니다. 트리플에 대한 데이터베이스를 사용하기 전에 두 옵션이 모두 활성화되어 있는지 확인하십시오. mlcp는 Windows 데스크톱 환경에서 트리플을 대량 로드하는 데 이상적인 방법입니다. 네이티브 SPARQL 함수 또는 내장 sem:sparQL 함수는 모두 MarkLogic 쿼리 를 실행하는 데 사용할 수 있는 방법입니다. 데이터 세트 다운로드 섹션에서는 샘플 데이터 세트를 로드했다고 가정합니다.
Marklogic 데이터 허브
MarkLogic의 Data Hub는 여러 소스에서 데이터를 수집하고 조화시키고 마스터한 다음 검색 및 분석하는 무료 오픈 소스 소프트웨어 인터페이스입니다. 이 솔루션은 MarkLogic Server에서 실행되며 미션 크리티컬 애플리케이션을 위한 통합 플랫폼을 제공하기 위한 것입니다.
Marklogic은 무엇에 사용됩니까?
MarkLogic은 데이터를 보다 효과적으로 저장, 관리 및 검색할 수 있는 강력한 데이터베이스입니다. 다양한 산업 분야의 조직에서 응용 프로그램과 웹 사이트를 강화하는 데 사용됩니다. MarkLogic은 대량의 데이터와 복잡한 쿼리를 처리하는 데 특히 적합합니다.
마크로직 서버
MarkLogic Server는 개발자가 구조나 위치에 관계없이 모든 데이터를 활용하는 정교한 애플리케이션을 쉽고 빠르게 구축할 수 있는 강력한 NoSQL 데이터베이스 플랫폼 입니다. MarkLogic Server는 관계형 및 NoSQL 세계의 장점을 모두 결합한 고유한 아키텍처를 기반으로 구축되어 개발자가 필요에 가장 적합한 방식으로 데이터 작업을 수행할 수 있는 유연성을 제공합니다.
문서 관리를 위해 특별히 생성된 DatabaseClient 인스턴스인 DocumentManager를 사용하여 문서를 관리할 수 있습니다. XML 문서를 읽는 방법을 시연하려면 Marklogic의 Java 기반 ReadXMLDocument.java를 사용하십시오. Java ReadMetadata 라이브러리는 수신한 문서 유형을 감지하는 방법과 이를 적절하게 처리하는 방법을 보여줍니다. 텍스트 문서를 삽입하는 것은 PDF 문서를 삽입하는 것과 유사하지만 StringHandle을 사용하거나 이전 예제에 표시된 형식을 제공해야 합니다. Java API를 사용하여 다양한 방법으로 문서 및 메타데이터에 액세스할 수 있습니다. DeleteDocument.java 메서드를 사용하여 한 번에 여러 문서를 삭제할 수 있습니다. 많은 비율의 문서 다운로드.
하나의 문서를 업로드해야 하므로 다이제스트 인증 체계를 사용할 때 한 번에 하나의 문서에 비용이 많이 들 수 있습니다. MarkLogic에서는 검색 및 쿼리와 같은 용어를 사용하는 상황에 관계없이 동일한 방식으로 사용합니다. 광범위한 검색 결과를 표현하려는 경우 쿼리 구문은 이를 위한 간단하고 강력한 방법입니다. 쿼리 관리자에서 초기 문자열 쿼리 인스턴스를 가져온 후 쿼리 관리자의 setCriteria 메서드를 사용하여 검색 텍스트를 지정합니다. 간단한 검색이라도 MarkLogic의 기본 검색 구성에서 사용하면 매우 강력할 수 있다는 것은 사실입니다. 쿼리 정의에 지정된 대로 각 쿼리를 구현하는 데 세 가지 방법이 사용됩니다. 처음 두 옵션을 사용하면 쿼리 위치 또는 컬렉션 집합을 지정할 수 있습니다.
마지막으로 서버에 저장된 사용자 지정 검색 옵션 집합과 쿼리를 연결할 수 있습니다. 다음은 검색 결과 목록입니다. 프로그램을 실행하고 콘솔을 검사하면 MarkLogic이 검색 결과를 XML로 나타내는 방법을 확인할 수 있습니다. 자습서 프로젝트에는 Search ResultsAsJSON이라는 Java 스크립트가 포함되어 있습니다. 자바. 프로그램을 실행하면 서버에서 가져온 원시 JSON 검색 결과가 표시됩니다. getMatchResults() 메서드를 호출하여 POJO 형식의 Getsearch 결과를 얻습니다.
문자열을 전달하여 MatchDocumentSummary 개체의 배열을 가져올 수 있습니다. 문서에 검색 적중이 포함되어 있으면 MatchLocation 개체로 나타낼 수 있습니다. 이름을 명시적으로 지정하지 않으면 명명된 기본 옵션이 사용됩니다. Mark Logic에서의 중요성 때문에 제약 조건이 자주 사용됩니다. 전체 옵션 세트에 대한 구성은 옵션 세트를 생성하거나 교체할 때 src/main/ml-options/options에 저장됩니다. 여기에 나열된 제약 조건은 다양한 형태로 사용할 수 있습니다. 프로그램을 만드십시오.
이 메서드는 CollectionSearch java와 동일한 결과를 반환해야 합니다. 이 새로운 검색 문자열의 결과로 이제 Shakepeare 컬렉션 기준이 태그 제약 조건에 의해 검색 문자열의 일부로 제공됩니다. 보시다시피 다음 명령을 사용하여 구성을 배포합니다. 대신 새 명령 프롬프트를 열고 mlwatch로 이동하면 스크립트 변경 사항이 Mark Logic으로 푸시됩니다. 값 제약 조건과 유사한 단어 제약 조건의 관점에서 단어의 키나 요소가 아닌 단어의 컨텍스트를 테스트합니다. 일치하는 단어도 어간 어간에 의해 형성되는데, 이는 전략 및 전략과 같이 유사한 단어가 사용됨을 의미합니다. 형태소 분석을 활성화하려면 src/main/ml-config/databases/content-database 파일을 생성/수정해야 합니다.
아래 명령을 실행하면 절차를 이해하는 데 도움이 됩니다. gradle mlUpdateIndexes 모듈은 gradle mlReindexDatabase 모듈에서 인덱스 테이블을 업데이트하는 데 사용됩니다. 속성 제약 조건을 사용하여 메타데이터로 문서의 속성을 검색할 수 있습니다. 수집 중에 추출되고 문서 속성으로 저장된 메타데이터를 사용하여 이미지를 생성합니다. '속성'이라는 단어 검색을 입력하면 해당 문서 속성에만 적용됩니다. search() 메소드는 조회 관리자에서 조회를 실행하는 데 사용됩니다.
Marklogic은 무엇을 위해 사용됩니까?
MarkLogic Server는 트랜잭션, 운영 및 분석 애플리케이션을 실행하기 위해 다양한 데이터를 저장하고 관리하는 소프트웨어 도구입니다.
데이터 허브: 데이터 관리를 위한 원스톱 솔루션
데이터 허브를 사용하면 데이터 레이크에서 데이터를 관리하고 액세스하는 방법을 완벽하게 제어할 수 있습니다. MarkLogic에서 자동화된 데이터 계층화는 데이터가 데이터 레이크에서 안전하게 저장되고 액세스되도록 보장하며 데이터 통합을 단순화합니다.
Marklogic에 어떻게 연결합니까?
MarkLogic을 설치 및 실행한 후 브라우저 기반 관리 인터페이스(http://localhost:8001/)로 이동하여 개발자 라이센스를 얻고 관리자를 구성하는 방법을 배우십시오.
Marklogic: Rest API가 있는 앱 서버
REST API 클라이언트 애플리케이션을 사용하여 REST API 인스턴스를 사용하여 MarkLogic Server와 상호 작용하는 것이 점점 보편화되고 있습니다. MarkLogic은 500명의 직원을 고용하고 있으며 시장에서 가장 규모가 큰 앱 서버 공급업체 중 하나입니다. 수익 예측에 따르면 2021년에는 직원당 평균 수익이 $200,000이고 최고 수익이 $100.0 백만이 될 것입니다.