
Apache HBase가 다음 빅 데이터 프로젝트를 위한 최선의 선택인 이유
게시 됨: 2022-11-16Apache HBase는 Google의 Bigtable을 모델로 한 오픈 소스 비관계형 분산 데이터베이스이며 Java로 작성되었습니다. Apache Software Foundation의 Apache Hadoop 프로젝트의 일부로 개발되었으며 HDFS(Hadoop Distributed File System) 위에서 실행되어 Hadoop에 Bigtable과 유사한 기능을 제공합니다. Bigtable과 마찬가지로 HBase는 높은 처리량으로 대량의 데이터를 처리하도록 설계되었으며 데이터에 대한 짧은 대기 시간 액세스가 필요한 애플리케이션에 적합합니다.
NoSQL 데이터베이스인 HBase는 랜덤 액세스로 데이터를 저장하고 검색하는 데 사용됩니다. 데이터 모델은 동적이고 유연하여 제한 없이 모든 유형의 데이터를 저장할 수 있습니다. HBase는 대량 작업(예: 인덱싱, 분석 등)을 수행하기 위해 Apache Hadoop의 MapReduce와 통합될 수 있습니다. HBase는 여러 버전의 단일 레코드가 포함된 희박한 다차원 정렬 맵 기반 데이터베이스입니다. Hadoop MapReduce 지원 이 내장되어 있어 빛의 속도와 병렬로 많은 양의 데이터를 처리할 수 있습니다. HBase 아키텍처는 HMaster, HRegion, Hlog 및 HBase의 네 가지 주요 구성 요소로 구성됩니다. ZooKeeper는 몇 가지 필수 기능을 제공하는 것 외에도 몇 가지 필수 서비스를 제공하는 오픈 소스 프로젝트입니다.
ZooKeeper에는 구성 데이터의 분산 동기화를 허용하는 기능이 포함되어 있습니다. HBase에서 노드가 실패하면 zkQuorum은 오류 메시지를 생성하고 복구를 시작합니다. 석유 및 석유, 마케팅 및 광고, 은행 및 주식 시장은 HBase가 사용되는 영역 중 일부에 불과합니다.
분산 파일 시스템으로서 HBase에서 HDFS를 사용하면 몇 가지 이점이 있습니다. 따라서 데이터베이스는 단기간에 수십억 행에 이르는 대용량 데이터 세트를 저장할 수 있으므로 빠른 분석이 가능합니다.
데이터베이스 관리에 대해 열 중심의 비관계형 접근 방식을 사용합니다. 정보는 개별 열에 저장되고 각 열에 고유한 고유 행 키를 사용하여 인덱싱됩니다. 이 아키텍처는 개별 행과 열을 빠르고 효율적으로 검색할 뿐만 아니라 테이블의 개별 열에 대한 효율적인 검색 프로세스를 제공합니다.
Apache Hbase 회사 이름WebsiteRevenueFacebookwww.Facebook.com$1170억Hortonworks Incwww.hortonworks.com7500만JP Morgan Chasewww.JPMorganChase.com1300억 Palo Alto Networks Incwww.palo Alto
MongoDB에는 선택할 수 있는 몇 가지 유형의 프로젝션, 필터링 및 집계 함수가 있습니다. 데이터와 키 값을 쌍으로 연결하는 Hbase와 달리 키 값은 다른 응용 프로그램과 공유할 수 있습니다. MongoDB는 네이티브 텍스트 인덱스와 HBase 데이터 복제 를 제공하여 텍스트 검색을 수행할 수 있도록 합니다.
Hadoop은 Nosql 데이터베이스입니까?

Hadoop은 빅 데이터를 저장하고 처리하기 위한 오픈 소스 소프트웨어 프레임워크입니다. 분산 파일 시스템(HDFS)과 MapReduce를 사용하여 데이터를 처리하고 분석합니다. Hadoop은 전통적인 관계형 데이터베이스가 아니지만 비슷한 방식으로 데이터를 저장하고 처리하는 데 사용할 수 있습니다.
MongoDB에서는 데이터베이스가 JSON(JavaScript Object Notation) 데이터 모델을 기반으로 하기 때문에 문서가 필요하지 않습니다. 빠르고 간단하게 사용할 수 있을 뿐만 아니라 잘 정의된 색인 및 검색 기능을 제공하도록 설계되었습니다. 맵/리듀스 알고리즘은 분산 저장 시스템인 Hadoop에서 방대한 데이터 세트를 처리하는 데 사용됩니다. 이 제품은 데이터 분석 및 보관을 위한 비용 효율적인 솔루션을 제공하도록 설계되었습니다.
Hbase는 SQL을 사용합니까?
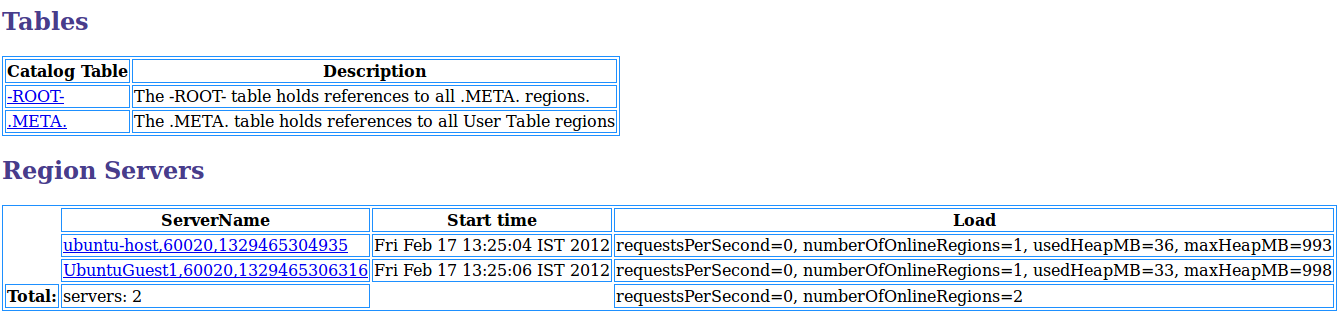
HBase는 관계형 데이터베이스가 아니며 데이터 쿼리에 SQL을 사용하지 않습니다. HBase는 대규모 데이터 세트에 대한 빠른 읽기/쓰기 액세스에 최적화된 키/값 저장소 디자인을 사용합니다.
높은 확장성, Hadoop 맵 축소 프로그래밍 지원 및 잘 알려진 Google BigTable 백서의 구현으로 인해 HBase는 구조화되지 않은 데이터 스토리지를 위한 탁월한 선택입니다. HBase의 사용 편의성은 대량의 데이터를 빠르게 처리해야 하는 웨어하우스 애플리케이션의 주요 장점입니다.
Hbase 쿼리 언어란?
JSON 스타일의 선언적 언어인 Jaspersoft HBase 쿼리 언어를 사용하면 HBase에서 검색할 데이터를 지정할 수 있습니다. HBase REST 서버 인터페이스를 사용할 때 커넥터는 쿼리를 적합한 API 호출로 변환한 다음 HBase 인스턴스 에서 실행합니다.
Hbase 테이블 사용의 이점
컬럼 패밀리란? 열 패밀리는 공통 이름과 데이터 유형을 공유하는 열 모음을 참조할 수 있습니다. 직원 이름에는 id,name,hired_on,fired_on 열이 포함될 수 있습니다. HBase 테이블 을 사용하면 어떤 이점이 있습니까? HBase 테이블은 다음과 같은 이점을 제공합니다. HBase의 열 지향 설계를 통해 희박하거나 구조화되지 않은 데이터를 쉽게 저장하고 액세스할 수 있습니다. 내결함성 때문에 HBase는 간헐적인 데이터 손실이나 손상을 견딜 수 있습니다. HBase는 사용이 매우 간단하기 때문에 빅 데이터 스토리지 사용을 빠르게 시작할 수 있습니다. HBase는 확장성이므로 클러스터에 더 많은 서버를 추가하여 더 큰 데이터 세트를 처리할 수 있습니다.
Hbase가 좋지 않은 이유는 무엇입니까?
SQL과 같은 기능은 HBase HBase 를 사용하여 실행할 수 없습니다. SQL 구조를 지원하지 않기 때문에 쿼리 최적화가 없습니다. HBase는 대규모 순차 입력 또는 출력 액세스가 있는 CPU 및 메모리 집약적인 반면 Map Reduce 작업은 일반적으로 고정 메모리에 바인딩된 입력 또는 출력이며 CPU 및 메모리 집약적입니다.
Hbase: 임의 읽기 및 쓰기 작업을 위한 최고의 데이터 스토리지 솔루션
임의 읽기 및 임의 쓰기 작업을 모두 수행하는 애플리케이션과 임의 읽기 및 임의 쓰기 작업을 사용하는 애플리케이션에 이상적입니다. HBase는 실시간 데이터 액세스가 필요한 애플리케이션에도 적합합니다.
Hbase는 카산드라와 같은가요?

여러 서버와 동일한 파일 버전에서 실행되는 Cassandra와 달리 Hbase는 하나의 데이터 서버에서 실행됩니다. 결과적으로 Hbase 읽기는 Cassandra 읽기보다 액세스하기 쉽습니다. Hbase의 데이터는 더 빠른 읽기를 수행할 수 있는 블룸 필터와 블록 캐시가 있는 HDFS에 저장됩니다.
대규모 데이터 집합을 처리할 수 있는 이러한 NoSQL 데이터베이스는 Cassandra 및 HBase에서 구축했습니다. 그들은 공통된 특성을 포함하여 많은 공통된 특성을 공유합니다. 겉으로 보기에 둘 다 뚜렷합니다. 이 기사에서는 관련된 요소 측면에서 HBase와 Cassandra가 어떻게 다른지 살펴보겠습니다. Cassandra는 HBase와 마찬가지로 Hadoop 인프라 가 있지만 DBMS와 인프라도 다릅니다. Cassandra는 추가 컴퓨팅 성능이 필요하지 않습니다. 블룸 필터를 통한 인덱싱은 HBase가 하는 일입니다.
Cassandra를 사용하면 임의 파티션이 있는 단일 WAN 주소에서 여러 행을 복제할 수 있습니다. Cassandra에는 여러 데이터 소스가 아닌 단일 데이터 소스가 있는 것이 좋습니다. 또한 Cassandra Cluster는 HBase Cluster 보다 설치가 쉽습니다.
Hbase 대 Cassandra: 어느 것이 더 낫습니까?
Cassandra와 HBase는 동시에 읽고 쓸 수 있지만 Cassandra가 더 빠릅니다. 또한 Cassandra는 HBase보다 빠릅니다.
Hbase 대 Mongodb
HBase와 MongoDB를 비교할 때 확실한 승자는 없습니다. 두 시스템 모두 고유한 강점과 약점이 있습니다. HBase는 많은 양의 데이터를 처리하는 데 더 적합한 반면 MongoDB는 더 유연하고 사용하기 쉽습니다.
couchbase와 4년을 보낸 후 MongoDB로 전환했고 전환이 원활했습니다. 기업 지원을 받았음에도 불구하고 우리는 Couchbase에 대해 끔찍한 경험을 했습니다. 전체 텍스트 검색에서 다양한 쿼리를 실행하면 여러 유형의 결과가 자주 반환됩니다. Windows에서 인덱스를 올바르게 구성하는 방법은 없습니다. 프로덕션 서버는 최대 6명의 사용자를 지원할 수 있습니다. 메모리 내 캐시를 처리하는 것 외에도 Couchbase에는 더 작은 Memcached 인스턴스가 포함되어 있습니다. 5000개의 문서는 각각 8GB의 RAM을 차지합니다. 그것에 대해 의심의 여지가 없습니다! Couchbase 인스턴스에는 5000개 미만의 문서, 20개 미만의 인덱스가 있었고 RAM 소비는 항상 8GB를 넘었습니다.
Amazon DynamoDB와 Apache HBase의 주요 차이점은 Amazon DynamoDB가 대형 테이블에 대한 빠른 레코드 조회(및 업데이트)를 제공하는 HDFS를 기반으로 구축된다는 점입니다. HDFS와 같은 분산 파일 시스템은 대용량 파일을 저장하는 데 이상적입니다. 반면에 HBase는 HDFS를 기반으로 구축되었으며 대형 테이블에 대한 레코드 조회(및 업데이트)를 쉽게 수행할 수 있습니다.
또한 Amazon DynamoDB는 키/값이자 문서 저장소인 Apache HBase와 달리 키/값이자 문서 저장소입니다. Amazon DynamoDB와 Apache HBase as NoSQL 데이터 스토어를 보다 완벽하게 비교하려면 Amazon DynamoDB의 키/값 데이터 모델을 고려하십시오.

Hbase 대 Mongodb: 어느 것이 더 나은 데이터베이스입니까?
HBase를 사용하면 대량의 데이터를 쉽게 저장하고 쿼리할 수 있습니다. 이 클라우드 기반 시스템은 적응력이 뛰어나고 내구성이 있으며 다양한 비즈니스에 이상적인 선택이 될 수 있는 고유한 기능이 많이 있습니다. MongoDB는 메모리 집약적인 애플리케이션을 위한 뛰어난 NoSQL 데이터베이스이지만 Hadoop은 더 나은 공간 관리를 제공합니다.
Hbase 대 카산드라
Hbase 플랫폼은 대용량 데이터베이스의 데이터 저장에 사용되는 반면 Cassandra 플랫폼 은 대량의 수집 및 데이터 저장에 사용할 수 있습니다. 실시간으로 대화형 데이터 및 트랜잭션 처리를 위해 Cassandra를 사용하는 것이 가장 좋습니다.
(스토리지) Cassandra vs Hbase – 차이점은 무엇입니까? Apache Cassandra 는 가장 안정적이고 확장 가능한 데이터 어레이 리포지토리를 생성하도록 설계되었기 때문에 NoSQL 시스템 클래스로 간주됩니다. Cassandra 사용자는 오픈 소스 구성 요소를 사용하여 커뮤니티에 기여할 수 있었고 이를 통해 모든 문제와 쿼리를 논의할 수 있었습니다. Cassandra의 데이터베이스 관리 시스템은 매우 효율적입니다. 개발자는 여러 멀티 코어 시스템의 기능을 활용할 수 있습니다. Cassandra의 열에는 사용자의 선호도 가중치가 행으로 포함됩니다. Zookeeper, Hbase 마스터, 데이터 노드, 네임 노드를 포함하는 Hadoop 인프라는 Hbase를 실행하는 데 사용됩니다.
Cassandra는 특정 쿼리 언어와 SQL을 모델로 한 CQL을 사용합니다. Zookeeper 프로토콜은 다른 노드에서 데이터를 수집하는 데 사용됩니다. 반면 Cassandra는 작은 정보를 대규모 데이터베이스에 저장하는 데 사용되는 Hbase보다 대규모 데이터 수집 및 저장에 더 적합합니다.
Cassandra가 Netflix를 위한 최고의 Nosql 솔루션인 이유
Cassandra와 HBase의 세계에서는 매우 다릅니다. HBase의 아키텍처는 데이터 관리만 지원하는 반면 Cassandra의 아키텍처는 다른 시스템에 의존하지 않고 데이터 저장 및 관리를 지원하도록 설계되었습니다.
HBase는 현재 여러 조직에서 사용하고 있으며 내부적으로는 모두 사용하고 있습니다. NoSQL 저장소가 필요할 때 다양한 문제를 해결하고 다양하고 고유한 솔루션을 제공할 수 있습니다. HBase의 NoSQL 스토리지 솔루션은 시장에서 최고입니다.
Cassandra는 Netflix의 전 세계적으로 분산된 스트리밍 서비스를 위한 인프라 구성 요소일 뿐만 아니라 Amazon Web Services에서도 사용할 수 있습니다.
아파치 Hbase
HBase는 Google의 Bigtable을 모델로 한 오픈 소스 분산형 열 지향 저장소입니다. Bigtable이 Google 파일 시스템에서 제공하는 분산 데이터 저장소를 활용하는 것처럼 HBase는 Hadoop 및 HDFS 위에 Bigtable과 같은 기능을 제공합니다. HBase 기능 에는 선형 및 모듈식 확장성, 일관된 짧은 대기 시간 읽기 및 쓰기, 자동 및 구성 가능한 테이블 샤딩이 포함됩니다.
Hadoop은 분산 파일 시스템과 MapReduce를 사용하여 방대한 양의 데이터를 저장하고 처리합니다. 분산 컬럼 지향 데이터베이스인 HBase는 Hadoop 위에 구축됩니다. 이 프로젝트는 오픈 소스이며 수평 확장이 가능합니다. Google과 유사한 Google의 빅 테이블은 구조화된 데이터에 대한 임의 액세스를 허용합니다. 반면에 HBase는 Hadoop 파일 시스템 위에 위치하며 파일 시스템에 대한 읽기 및 쓰기 액세스를 제공합니다. HDFS 파일 시스템은 직접 또는 HBase를 통해 데이터를 저장하는 데 사용할 수 있습니다. 열 기반 데이터베이스인 HBase는 행이 정렬되는 방식으로 구성됩니다. 테이블은 둘 이상의 열 패밀리를 가질 수 있으며 각 열 패밀리는 둘 이상의 열을 가질 수 있습니다.
하둡 대. 에이치베이스
크고 희소한 데이터 세트는 Hadoop에서 보다 효율적으로 처리됩니다. 실시간으로 데이터를 처리할 때 HBase의 처리 능력은 다른 플랫폼보다 월등합니다.
Hbase 대 하이브
Hive와 HBase는 Hadoop에서 작동하는 서로 다른 두 가지 기술입니다. Hive는 MapReduce 작업을 실행하는 SQL 유사 엔진이고 HBase는 NoSQL 키/값 데이터베이스입니다. Hive는 실시간으로 쿼리할 수 있는 강력한 쿼리 엔진인 반면 HBase는 실시간으로 쿼리할 수 있는 강력한 쿼리 엔진입니다.
Apache Hadoop과 Apache HBase는 거의 모든 경우에 다양한 용도로 사용할 수 있는 서로 다른 두 가지 빅 데이터 기술입니다. 빅 데이터 시스템의 관점에서 볼 때 모든 기술은 서로 결합되어야 합니다. Hive와 HBase의 차이점은 무엇입니까? Apache Hadoop MapReduce 및 HBase를 결합하여 NoSQL 데이터베이스를 생성할 수 있습니다. HBase의 가장 큰 허점 중 하나는 임의 액세스 가능성을 허용하는 서비스 부족입니다. 또한 기성 지역 서버를 사용하여 수평으로 확장하고 가용성이 높고 일관성이 있으며 지연 시간이 적은 No SQL 데이터베이스 스펙트럼에서만 사용되는 것으로 알려져 있습니다. Hadoop은 Hive와 HBase의 두 가지 고유한 방식으로 사용됩니다. Hive는 MapReduce 작업을 실행하는 SQL과 유사한 엔진인 반면 HBase는 키와 값이 있는 NoSQL 데이터베이스입니다. 경쟁자를 두는 것보다 이 두 가지 기술이 협력해야 합니다.
다음 데이터 프로젝트를 위한 Hive 또는 Hbase?
Hive는 오랫동안 사용되어 왔습니다. 시장의 다른 데이터 웨어하우스에 비해 HBase를 사용하면 몇 가지 이점이 있지만 아직 초기 단계입니다. Hive는 많은 조직에서 데이터 웨어하우스 배포를 위한 인기 있는 선택입니다. NoSQL 데이터베이스의 전체 기능이 필요하지 않지만 여전히 NoSQL 저장소가 필요한 상황에 탁월한 선택입니다. HBase의 NoSQL 스토리지 솔루션은 시장에서 최고입니다.
카산드라 노스크
Cassandra는 고가용성과 수평적 확장성이 필요한 애플리케이션에 완벽한 강력한 NoSQL 데이터베이스입니다. Cassandra는 사용하기 쉽고 다양한 애플리케이션에 이상적인 선택이 되도록 강력한 기능 세트를 제공합니다.
Apache Cassandra는 무료로 사용할 수 있는 널리 사용 가능한 Apache 커뮤니티 프로젝트입니다. Apache Cassandra를 사용하면 여러 상용 서버에서 고속 정형 및 비정형 데이터를 저장하고 관리할 수 있습니다. Google Bigtable 및 Amazon Dynamo와 함께 작동하는 Cassandra를 사용하면 사용자가 모든 위치에서 데이터베이스를 관리할 수 있습니다. 높은 수준의 가용성을 제공하며 주요 문제가 없습니다. Cassandra는 일부 대규모 IT 회사에서 배포했습니다. Instagram은 매일 약 8천만 장의 사진을 Cassandra 데이터베이스에 업로드합니다. Apache Cassandra와 MongoDB로 구성되어 있습니다. 다중 노드 Cassandra 클러스터는 갑작스러운 수요 급증을 충족하기 위해 Cassandra를 쉽게 확장할 수 있는 매우 간단한 방법입니다.
카산드라는 Nosql인가?
Cassandra와 같은 NoSQL 데이터베이스를 배포할 수 있습니다. NoSQL 데이터베이스는 가볍고 오픈 소스이며 비관계형이며 디자인이 공정하게 분산되어 있습니다. 수평 확장 능력과 유연한 방식으로 스키마를 정의하는 능력이 특징입니다.
몽고디비 노SQL
MongoDB의 문서 모델은 관계형이 아니므로 데이터베이스가 됩니다. 이는 소위 NoSQL 데이터베이스(NoSQL = Not-only-SQL)라는 점에서 Oracle, MySQL 및 Microsoft SQL Server와 같은 기존 관계형 데이터베이스와 구별됩니다.
MongoDB는 가장 널리 사용되는 NoSQL 데이터베이스 중 하나이며 데이터를 JSON 형식으로 저장할 수 있습니다. MongoDB의 성능, 확장성 및 가용성은 SQL, Oracle 및 Oracle과 같은 다른 데이터베이스 스크립팅/분석 언어와 유사합니다. 이 장의 목적은 NoSQL의 기본 개념과 유형을 설명하는 것입니다.
Mongodb는 어떤 유형의 Nosql입니까?
문서 데이터베이스는 복잡한 데이터 구조로 함께 연결된 여러 키로 구성됩니다. 문서는 다양한 키-값 쌍, 키-배열 쌍 등을 포함할 뿐만 아니라 중첩될 수 있습니다. 문서 데이터베이스인 MongoDB는 Google Docs와 매우 유사합니다.
Mongodb가 최고의 Nosql입니까?
세 번째로 좋은 NoSQL 데이터베이스는 범용 문서 데이터베이스 역할을 하도록 설계된 MongoDB입니다. 문서 지향적이기 때문에 단일 위치에 모든 정보를 구성할 수 있으므로 단일 주제에 대한 모든 정보에 간단하게 액세스할 수 있습니다.
귀하에게 가장 적합한 데이터베이스는 무엇입니까?
결국 각각 장단점이 있는 두 데이터베이스 사이에 확실한 승자는 없습니다. 데이터베이스는 사용자의 특정 요구 사항과 기본 설정에 맞게 조정되어야 합니다.
Mongodb Nosql은 어떻게 작동합니까?
MongoDB는 무료로 사용할 수 있는 NoSQL 데이터베이스입니다. 비관계형 데이터베이스로서 정형, 반정형 및 비정형 데이터를 처리할 수 있으며 모든 파일 형식을 처리할 수 있습니다. 문서 지향 데이터 모델과 비정형 쿼리 언어를 사용합니다. 매우 유연한 MongoDB는 여러 유형의 데이터를 저장하고 결합할 수 있습니다.
Mongodb: 크고 작은 회사를 위한 선택
MongoDB는 확장이 가능하고 성능이 우수하기 때문에 미션 크리티컬 애플리케이션에 탁월한 선택입니다. 결과적으로 Netflix, Uber 및 Airbnb는 수년 동안 가장 까다롭고 가장 큰 애플리케이션을 구동하기 위해 이를 사용하는 회사 중 하나입니다.
MongoDB 플랫폼을 사용하면 신생 기업과 소규모 기업에서 간편하게 사용할 수 있습니다. 또한 클라우드 스토리지에 매우 적합하여 기업이 필요에 따라 확장하거나 축소할 수 있습니다.