
5 sposobów na optymalizację bazy danych NoSQL
Opublikowany: 2023-01-12Bazy danych NoSQL stają się coraz bardziej popularne, ponieważ są postrzegane jako bardziej skalowalne i elastyczne niż tradycyjne relacyjne bazy danych . Istnieje kilka sposobów optymalizacji bazy danych NoSQL, które obejmują: 1. Ostrożne zaprojektowanie schematu: Jest to ważne, ponieważ dobrze zaprojektowany schemat może pomóc poprawić wydajność i ułatwić zarządzanie danymi. 2. Indeksowanie danych: może to pomóc poprawić wydajność zapytań. 3. Używanie buforowania: Buforowanie może pomóc poprawić wydajność, przechowując często używane dane w pamięci. 4. Partycjonowanie danych: Może to pomóc poprawić wydajność i skalowalność poprzez dystrybucję danych na wielu serwerach. 5. Monitorowanie wydajności: Jest to ważne, aby zidentyfikować wszelkie wąskie gardła i podjąć działania naprawcze.
Jay Patel, architekt serwisu eBay, opublikował niedawno artykuł na temat modelowania danych przy użyciu magazynu danych Cassandra. Wyjaśnia, w jaki sposób zaprojektowali swój model danych przy użyciu Cassandry, w jaki sposób wykorzystali kolumny i rodziny kolumn oraz w jaki sposób zoptymalizowali wyniki zapytań za pomocą optymalizacji zapytań. Jednym z moich ulubionych spostrzeżeń z ich podejścia jest to, że można je zastosować do dowolnej bazy danych NoSQL. Zanim będzie można zoptymalizować model danych, należy najpierw zrozumieć sposób uzyskiwania do niego dostępu. Kiedy zaczniesz zauważać, że Twoje zapytania trwają dłużej, zdasz sobie sprawę, że Twoja relacyjna baza danych ma problemy z wydajnością. Gdy dane są znormalizowane, jest mniej prawdopodobne, że spowoduje to niepotrzebne sprzężenia lub zapytania n+1. Nawet jeśli denormalizacja jest możliwa w przypadku magazynów danych NoSQL, wiąże się to z kosztami.
Co to jest optymalizacja zapytań w Nosql?
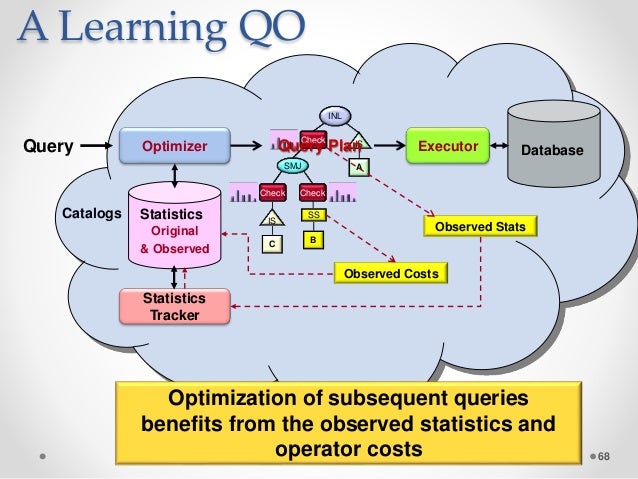
Celem optymalizacji zapytań jest znalezienie najbardziej wydajnego planu. Podczas pomiaru wydajności wykorzystywane są opóźnienia i przepustowość. Optymalizacja oparta na kosztach kosztuje tyle samo, co koszt pamięci, procesora i miejsca na dysku. W świecie NoSQL większość baz danych zapewnia teraz obsługę języka zapytań podobnego do SQL.
Baza danych MongoDB to baza danych NoSQL, znana również jako baza danych dokumentów. Ta baza danych została zaprojektowana w taki sposób, aby była łatwiejsza w rozwoju niż inne relacyjne bazy danych. Używając metody explain() możemy zobaczyć, jak działa nasze zapytanie. Za pomocą narzędzia Wyjaśnij można utworzyć dokument zawierający plany kwerend, etapy kwerend i nie tylko. W wyniku tego artykułu możemy zrozumieć, w jaki sposób indeks może zmienić etapy skanowania określonej kolekcji. Celem tego artykułu jest omówienie podstaw optymalizacji. Szczegółowe informacje na temat optymalizacji etapu agregacji zostaną omówione w kolejnych artykułach. Czarni przodują w dziedzinach technologii. Ta kolekcja zasobów podkreśla niektóre z rzeczy, które powinniśmy wiedzieć.
Co sprawia, że Nosql jest szybki?
Bazy danych Nosql są zaprojektowane tak, aby były szybkie i skalowalne. Aby to osiągnąć, używają różnych technik, takich jak skalowanie w poziomie, sharding i denormalizacja.
Zdecydowana większość systemów noSQL to po prostu trwałe magazyny kluczy lub wartości (takie jak Projekt Voldemort). Jeśli twoje zapytania są typu, który wymaga wyszukania danej wartości klucza, system, który może to zrobić tak szybko, jak powinien to zrobić RDBMS. Bazy danych dokumentów (takie jak CouchDB) to również popularne systemy nosql. Denormalizacja jest często używana w tych bazach danych do strukturyzowania struktury danych. W rzeczywistości uważam, że wydajność aplikacji można mierzyć liczbą części wymaganych do spełnienia pojedynczego wymagania. Kiedy używany jest NoSQL, wydajność bazy danych NoSQL, takiej jak djondb, może być dziesięć razy większa, jeśli potrzebujesz tylko jednej prostej wstawki. Deweloper będzie mógł pracować wydajniej, ponieważ NoSQL pozwala im zużywać mniej danych.
Nadrzędnym celem NoSQL DATABASES (bez granic) jest utrzymanie wysokiego poziomu skalowalności. Musisz wziąć pod uwagę, jakie typy zapytań wykonujesz, jakich kolumn używasz w tabeli i jakiej implementacji serwera używasz. Jeśli utworzysz więcej węzłów 1000000 obr./min stabilnych 2 ms i użyjesz mniej kodu, otrzymasz szybszy węzeł z wyższą stabilną szybkością i wydajnością.
Co sprawia, że Nosql jest szybszy niż Sql?
Ta metoda obejmuje gromadzenie, konsolidację i podział różnych jednostek danych. W rezultacie baza danych NoSQL wykonuje operacje odczytu i zapisu szybciej niż baza danych SQL.
Dlaczego bazy danych Nosql przejmują popularność
Oprócz różnych czynników, bazy danych NoSQL stają się coraz bardziej popularne. Są proste w użyciu, zdolne do obsługi dużych ilości danych i można je dostosować do konkretnych wymagań aplikacji. Mają wiele zalet oprócz tego, że są elastyczne i można je dostosowywać, czego nie można znaleźć w innych typach baz danych.
Dostrajanie wydajności Nosql

Dostrajanie wydajności Nosql polega na upewnieniu się, że baza danych nosql działa tak wydajnie, jak to tylko możliwe. Istnieje kilka kluczowych obszarów, na których należy się skupić podczas dostrajania bazy danych nosql: 1. Upewnij się, że baza danych jest odpowiednio zindeksowana. 2. Upewnij się, że Twoje zapytania są zoptymalizowane. 3. Upewnij się, że Twoje dane są odpowiednio znormalizowane. 4. Upewnij się, że Twoja baza danych jest poprawnie skonfigurowana. Koncentrując się na tych kluczowych obszarach, możesz mieć pewność, że baza danych nosql działa z najwyższą wydajnością.
Gdy Mango jest obciążone dużym obciążeniem, skrypt MangoNoSql wykonuje w tle zapisy w tle. Funkcja Batch Write Behind umożliwia pisanie za kulisami. Każde zadanie będzie wykonywane równolegle do innych, skupiając się na wartościach punktowych z puli. Jeśli zauważyłeś w swoim systemie jakiekolwiek zdarzenia utraty danych NoSQL, dobrym pomysłem jest zmiana ustawień wydajności. Po naciśnięciu przycisku Wykonaj kopię zapasową teraz zostanie utworzona kolejka zadań do wykonania kopii zapasowej systemu. Wszystkie wartości punktowe, które są gotowe do zapisania na listę pamięci w ramach modułów NoSQL, są przechowywane w mango. Następnie wybiera z listy maksymalnie „Zapis wsadowy za wstawkami na zadanie” i rozpoczyna wątek w celu wstawienia wstawek.
Plusy i minusy Nosql
Podczas tworzenia baz danych NoSQL niezwykle ważne jest, aby były elastyczne i szybkie. Ma mniejszy narzut, ponieważ ma mniej ograniczeń niż SQL. Płytka pamięć NoSQL jest elastyczna, co pozwala na jej dystrybucję w różnych obiektach (dokumentach lub parach klucz-wartość). Baza danych NoSQL jest powszechnie uważana za mającą niski poziom trudności pod względem rozwoju, funkcjonalności i wydajności. Jest łatwy do nauczenia i jest używany przez osoby, które wolą przechowywać dane niezgodne z tradycyjnymi modelami baz danych .
Optymalizacja wydajności Mongodb
MongoDB to potężny system baz danych zorientowany na dokumenty typu open source. Posiada funkcję wyszukiwania opartą na indeksie, która sprawia, że wyszukiwanie danych jest szybkie i łatwe. Jednak, podobnie jak każdy inny system baz danych, wydajność MongoDB można zoptymalizować, aby zapewnić płynne i wydajne działanie. Istnieje kilka podstawowych rzeczy, które można zrobić, aby zoptymalizować wydajność MongoDB. Po pierwsze, ważne jest, aby upewnić się, że znajdują się prawidłowe indeksy. Zapewni to szybkie i łatwe odzyskanie danych. Po drugie, ważne jest, aby baza danych była dobrze zorganizowana. Pomoże to zmniejszyć rozmiar danych i ułatwi wykonywanie zapytań. Wreszcie, ważne jest regularne monitorowanie bazy danych, aby upewnić się, że działa ona płynnie. Postępując zgodnie z tymi prostymi wskazówkami, możliwe jest, aby MongoDB działało płynnie i wydajnie.

W tym poście na blogu Guy Harrison wyjaśnia, jak korzystać z nowej agregacji okien i potoku agregacji w MongoDB 5.0. Data Lake powstało w wyniku eksplozji zainteresowania Big Data i Hadoopem. Opracowano Data Lake, nowoczesną i wydajniejszą alternatywę dla Enterprise Data Warehouse (EDW). W tym tygodniu blog koncentruje się na indeksach B-tree MongoDB oraz na tym, jak tworzyć połączone indeksy w celu optymalizacji wyszukiwań wielokluczowych. Ponadto rozważając – lub stosując – indeksy, rozważamy pewne kompromisy.
Jaka jest poprawa wydajności w Mongodb?
Jeśli znasz swoje wzorce zapytań MongoDB, możesz poprawić wydajność MongoDB poprzez: przechowywanie wyników częstych zapytań podrzędnych w celu zmniejszenia obciążenia odczytami; i wykrywanie wzorców zapytań MongoDB. Upewnij się, że masz indeksy dla każdego pola, które regularnie sprawdzasz. Jeśli zauważysz powolne zapytania, możesz użyć swoich dzienników, aby je zidentyfikować.
Czy Mongodb potrzebuje dużo pamięci RAM?
MongoDB wymaga 1 GB pamięci RAM do działania na jednym zasobie. Jeśli system musi rozpocząć zamianę pamięci na dysk, będzie to miało poważny wpływ na wydajność i należy tego unikać.
Czy Mongodb ma Optymalizator zapytań?
Kiedy indeks jest dostępny w MongoDB, optymalizator zapytań określa, który plan zapytania jest najbardziej wydajny i zapisuje go w pamięci podręcznej. Liczba „jednostek pracy” (prac) wykonanych przez plan wykonania zapytania służy do określenia najbardziej wydajnego planu zapytania, gdy planista zapytań sprawdza plany kandydatów.
Narzędzie do optymalizacji zapytań Mongodb
Mongodb zapewnia narzędzie do optymalizacji zapytań, które pozwala użytkownikom poprawić wydajność ich zapytań. To narzędzie umożliwia wizualizację planu wykonania zapytania i optymalizację zapytania na podstawie wyników. Narzędzie pozwala również użytkownikom przeglądać plan wykonania zapytania w różnych formatach, w tym JSON, BSON i CSV.
MongoDB zapewnia statystyki wykonywania zapytań w ramach systemu kontroli. Te informacje mogą być wykorzystane przez programistę do optymalizacji zapytania. Na przykład karta Wyjaśnij plan umożliwia użytkownikom graficzną ilustrację statystyk planu. Oprócz queryPlanner, egzekucjiStats i allExecutionPlans, do wyjaśniania można użyć trybów szczegółowości. Unikalne, częściowe, rzadkie (nie indeksuj dokumentów bez pola indeksu), ukryte (nie wyświetlaj wyników narzędzia do planowania zapytań) i indeksy wielokluczowe są obsługiwane przez MongoDB. Zamiast używać kluczy prefiksów indeksu lub różnych porządków sortowania, do indeksów używany jest indeks złożony. MongoDB optymalizuje wydajność zapytań, używając dwóch oddzielnych indeksów lub prefiksów podczas łączenia dwóch indeksów lub ich prefiksów.
Potok Mongod zawiera etap pasujący do pola, które nie jest indeksowane. Prostym rozwiązaniem jest przepisanie etapu dopasowywania w celu wykorzystania pola już istniejącego i zindeksowanego. Optymalizator wyszukuje jednostki pracy, które należy wykonać podczas wykonywania każdego planu kandydującego. W przypadku uruchamiania aplikacji intensywnie korzystających z odczytu należy zwiększyć rozmiar zestawów replik i wykonać podział na fragmenty. Należy monitorować stan i czas trwania replikacji. Prawda: aktualizuj wszystkie pasujące dokumenty tak wydajnie, jak to możliwe, korzystając z wielu. Sprawdź metryki blokady w określonej kolejności.
Długi czas blokady może oznaczać, że struktura zapytania lub architektura systemu nie działa poprawnie. Przetwarzanie wsadowe poprawia efektywność wykorzystania zasobów. Na przykład wydarzenia w Kafce można konsumować partiami, a nie porcjami. Nie można zindeksować zapytania w kolekcji podzielonej na fragmenty, jeśli indeks nie zawiera klucza do kolekcji. Korzystając z $planCacheStats, możesz lepiej zrozumieć informacje o pamięci podręcznej na etapie agregacji. Oznacza to również, że pamięć podręczna planu będzie miała limit rozmiaru tylko 0,5 GB, czyli taki sam limit rozmiaru jak we wcześniejszej wersji.
Magazyny danych Nosql
Zamiast przechowywać dane w tabelach, bazy danych NoSQL przechowują dane w dokumentach. W rezultacie określamy je jako „nie tylko SQL”, dzięki czemu można je sklasyfikować jako elastyczne modele danych przy użyciu różnych metod. Bazy danych NoSQL są podzielone na cztery typy: bazy danych zawierające wyłącznie dokumenty, magazyny klucz-wartość, bazy danych o szerokich kolumnach i bazy danych wykresów.
Magazyn danych Redis to magazyn par klucz-wartość typu open source w pamięci, opracowany przez IBM. Może być używany do przechowywania danych sesji w celu szybszego dostępu, oprócz buforowania, kolejkowania i kolejkowania, i jest tańszy niż tradycyjne bazy danych . Baza danych NoSQL jest często używana jako rozszerzenie, a nie zamiennik relacyjnej bazy danych. Bazowy typ trwałości ma inny zestaw cech niż ten, który jest przechowywany w relacyjnej bazie danych. PyMongo, które jest zbudowane przy użyciu kodu Pythona, umożliwia interakcję z jedną lub kilkoma instancjami MongoDB za pomocą wspólnego interfejsu. Python ORM zbudowany wokół PyMongoEngine jest specjalnie zaprojektowany dla MongoDB. Celem Graph Databases jest zapewnienie kompleksowego przeglądu magazynów danych NoSQL i porównanie ich z innymi typami magazynów danych. Poniżej znajduje się krótki opis NoSQL i jego zastosowań, a także opis twierdzenia o spójności, dostępności i tolerancji partycji (CAP). dane sesji mogą być przechowywane w pamięci szybciej niż w tradycyjnej bazie danych z pamięcią trwałą.
Bazy danych NoSQL charakteryzują się następującymi cechami: łatwe skalowanie, wysoka dostępność i małe opóźnienia dostępu do danych. Aplikacje bazodanowe są zaprojektowane do przetwarzania większej liczby typów danych niż tradycyjne bazy danych. Ułatwia przechowywanie danych dzięki uproszczonemu modelowi, co pozwala na szybsze i wydajniejsze przetwarzanie. Ponadto nadają się do analizy danych na dużą skalę. Bazy danych NoSQL mają wiele zalet w porównaniu z konwencjonalnymi bazami danych . Zaletą ich posiadania jest to, że można je skalować, zapewniać wysoki poziom dostępności i niski poziom opóźnień w dostępie do danych.
Dlaczego bazy danych Nosql przejmują popularność
Korzystanie z baz danych NoSQL ma wiele zalet w porównaniu z tradycyjnymi relacyjnymi bazami danych i stają się one coraz bardziej popularne. Projekt ObjectStore, który pozwala na bardziej efektywne wykorzystanie technik programowania obiektowego, jest jednym z głównych powodów tego stanu rzeczy. Bazy danych NoSQL, oprócz skalowalności, oferują również szereg innych zalet. Dane można łatwo obsługiwać, ponieważ są duże i można je przetwarzać w krótkim czasie. Dla każdej firmy poszukującej niezawodnej i skalowalnej bazy danych dokumentów MongoDB jest doskonałym wyborem. Ponadto jest darmowy i jest popularnym wyborem dla firm każdej wielkości.
Indeks tekstowy Mongodb
Indeksy tekstowe MongoDB obsługują przetwarzanie tekstu specyficzne dla języka, w tym tokenizację, stemming i specyficzne dla języka stopwords. Można ich używać z dowolnym polem zawierającym tekst oparty na języku.
Tworzenie indeksów tekstowych w MongoDB jest tak proste, jak użycie metody createIndex(). Podstawową funkcją indeksu tekstowego jest identyfikacja dowolnego elementu w łańcuchu lub tablicy elementów w tekście. Indeksy złożone oprócz klucza indeksu tekstowego zawierają zarówno rosnące, jak i malejące klucze indeksu. W takim przypadku przeszukajmy kolekcję postów studentów, tworząc indeks tekstowy w polu tytułu. MongoDB podsumowuje wyniki każdego pola indeksu w dokumencie, mnożąc jego wagę przez całkowitą liczbę dopasowań. Domyślna waga pola indeksu to jeden, więc możesz ją zmienić za pomocą metody createIndex() . Możesz utworzyć wiele indeksów tekstowych, używając specyfikatora symboli wieloznacznych ($**).