
Projektowanie bazy danych dla danych geolokalizacyjnych: kluczowe zagadnienia
Opublikowany: 2022-12-29Dane geolokalizacyjne to rodzaj danych, który zawiera informacje o położeniu geograficznym określonego obiektu. Aby skutecznie przechowywać i zarządzać danymi geolokalizacyjnymi, ważne jest, aby zrozumieć, jak skonstruować bazę danych dla tego typu danych. Projektując bazę danych dla danych geolokalizacyjnych, należy wziąć pod uwagę kilka kluczowych kwestii. Pierwszym czynnikiem, który należy wziąć pod uwagę, jest poziom szczegółowości, na jakim dane będą przechowywane. Na przykład, czy dane będą przechowywane na poziomie kraju, stanu czy miasta? Poziom szczegółowości będzie miał wpływ na ogólny rozmiar bazy danych i złożoność zapytań, które można uruchamiać na danych. Drugą kwestią jest format, w jakim dane będą przechowywane. Istnieje kilka różnych opcji przechowywania danych geolokalizacyjnych, w tym pary szerokości/długości geograficznej, GeoJSON i KML. Każda opcja ma swoje zalety i wady, dlatego ważne jest, aby wybrać format, który najlepiej pasuje do konkretnych potrzeb aplikacji. Na koniec ważne jest rozważenie strategii indeksowania, która zostanie zastosowana dla danych. Indeksowanie jest ważne ze względu na wydajność, ale może również wpływać na ogólną strukturę bazy danych. W przypadku danych geolokalizacyjnych powszechną strategią indeksowania jest użycie indeksu quadtree. Pamiętając o tych rozważaniach, możliwe jest efektywne zaprojektowanie bazy danych do przechowywania danych geolokalizacyjnych.
Wiele głównych firm technologicznych eksperymentuje z bazami danych NoSQL w obszarach usług opartych na lokalizacji. Strukturalny język zapytań, taki jak SQL, i relacyjna baza danych, taka jak MySQL, działają w przeciwny sposób. Nie ma wspólnych cech między bazami danych NoSQL, a wiele z nich nie wymaga ustalonych schematów tabel ani operacji łączenia. MongoDB (open source), BigTable (zastrzeżony przez Google) i Google Earth (dostępny za pośrednictwem Google Earth) to tylko niektóre z baz danych NoSQL, które mogą obsługiwać dane przestrzenne. Cassandra (baza danych NoSQL opracowana przez Facebooka) i CouchDB (baza danych NoSQL opracowana przez Facebooka) to również platformy oprogramowania typu open source. Można użyć usługi internetowej Amazon SimpleDB. Framework NoSQL to nie tylko kontener magazynów danych; jest ich zbiorem.
Wielu programistów używa technologii NoSQL do rozwiązywania problemów przestrzennych, zamiast polegać na bazie danych. Zamiast tego będą korzystać z usługi lokalnej lub hostowanej. Oczekuj więcej opcji dla baz danych, a nie mniej. To podziękowanie dla Paula Ramseya i jego studentów z Geog897g w Penn State za ich wkład.
Jak zbudowane są bazy danych Nosql?
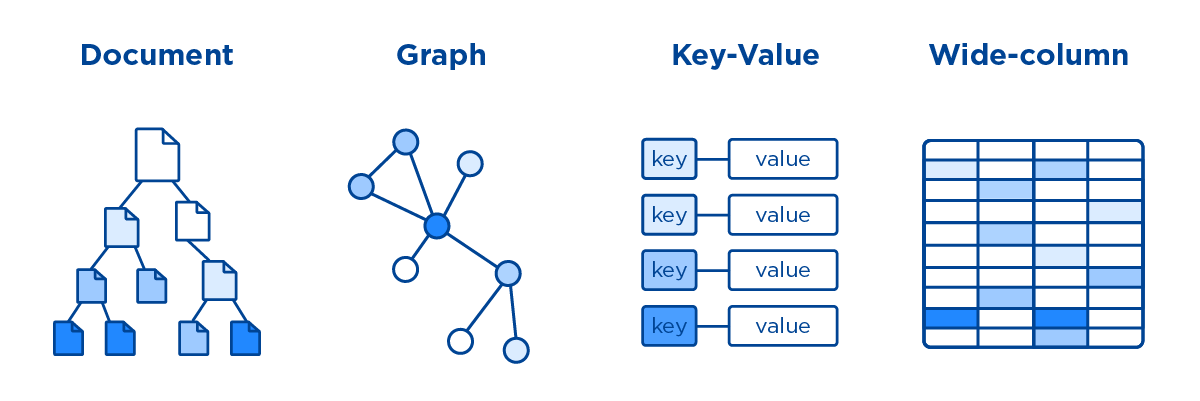
Bazy danych SQL (znane również jako bazy danych NoSQL) przechowują dane inaczej niż tradycyjne bazy danych ze względu na ich nietabelaryczny charakter. Baza danych NoSQL składa się z kilku typów opartych na jej modelu danych. Typy dokumentów obejmują wykresy, wykresy i szerokie kolumny, a także typy klucz-wartość.
W przeciwieństwie do tradycyjnych relacyjnych baz danych , bazy danych NoSQL przechowują dane w formacie, który jest dla nich unikalny. Najpopularniejsze są typy dokumentów, klucz-wartość, szerokie kolumny i wykresy. Koszt przechowywania danych drastycznie spadł w ciągu ostatniej dekady, co umożliwiło pojawienie się baz danych NoSQL. Deweloperzy mogą przechowywać duże ilości nieustrukturyzowanych danych, ponieważ mogą wykorzystywać te systemy do różnych celów. Bazy danych dokumentów, bazy danych klucz-wartość, magazyny z szerokimi kolumnami i bazy danych wykresów to przykłady baz danych NoSQL. Gdy łączenie nie jest wymagane, skraca się czas wykonywania zapytań. Różnorodność zastosowań rozwiązań IoT waha się od krytycznych (takich jak dane finansowe) do bardziej zabawnych i absurdalnych (takich jak przechowywanie odczytów IoT z inteligentnej kuwety dla kotów).
W tym samouczku dowiesz się, jak wybrać i używać bazy danych NoSQL. Ponadto przyjrzymy się bliżej niektórym powszechnym nieporozumieniom na temat baz danych NoSQL. Według DB-Engines, MongoDB jest najpopularniejszą nierelacyjną bazą danych na świecie. Celem tego samouczka jest nauczenie Cię, jak wysyłać zapytania do bazy danych MongoDB bez instalowania czegokolwiek na komputerze. Klaster MongoDB to miejsce, w którym przechowujesz swoje bazy danych. Pojemność pamięci masowej Atlasa można zwiększyć po skonfigurowaniu go dla klastra. Atlas Data Explorer, MongoDB Shell lub MongoDB Compass to wszystkie możliwe metody ręcznego tworzenia bazy danych.
W wyniku tego do tego skryptu zostaną zaimportowane przykładowe dane z Atlasu. Bazy danych NoSQL mają wiele zalet dla programistów, w tym możliwość równoległego modelowania i skalowania danych, szybkiego wykonywania zapytań dotyczących danych oraz błyskawicznego korzystania z zapytań. Eksplorator danych to najwygodniejszy sposób wstawiania nowych dokumentów, edytowania istniejących i usuwania dokumentów. Możesz analizować swoje dane za pomocą platformy agregacji, która jest jednym z najpotężniejszych dostępnych narzędzi. Wykres to jeden z najprostszych sposobów wizualizacji danych w Atlasie i Atlas Data Lake.
Ze względu na elastyczność baz danych NoSQL mogą one obsługiwać dane nieustrukturyzowane i częściowo ustrukturyzowane. Pozwala to na szybsze i bardziej iteracyjne opracowywanie, ponieważ dane nie muszą być przebudowywane w bazie danych. Bazy danych NoSQL można również skalować w celu obsługi dużych ilości danych, ponieważ obsługują one skalowalność. Wreszcie struktura danych baz danych NoSQL pozwala im obsługiwać dane w zupełnie nowy sposób, który jest dla nich unikalny. Bazy danych NoSQL są idealne dla zestawów danych na dużą skalę, ponieważ można je modyfikować w celu spełnienia unikalnych wymagań.
Który typ bazy danych Nosql jest używany do śledzenia relacji jednostek?
Nie ma jednoznacznej odpowiedzi na to pytanie, ponieważ zależy to od konkretnych potrzeb aplikacji. Jednak niektóre z najpopularniejszych baz danych nosql używanych do śledzenia relacji między jednostkami to MongoDB, Couchbase i Cassandra.
Każdy system współpracujący z alternatywnymi bazami danych SQL jest określany jako NoSQL. W przeciwieństwie do tradycyjnych tabel wierszowo-kolumnowych używanych w systemach zarządzania relacyjnymi bazami danych, modele danych używane w tej aplikacji składają się z różnych struktur. Bazy danych NoSQL znacznie się od siebie różnią. Bazy danych dokumentów o architekturze skalowalnej w poziomie są powszechnie używane do implementacji najczęściej stosowanych baz danych dokumentów. Platformy e-commerce, platformy handlowe i tworzenie aplikacji mobilnych to tylko kilka przykładów zastosowań. Szczegółowo badamy MongoDB i PostgreSQL, porównując je ze sobą. Dane te można zebrać w kilka sekund za pomocą kolumnowej bazy danych.
Nie są w stanie konsekwentnie zapisywać danych ze względu na ich metodę zapisywania danych. Bazy danych Graph są zoptymalizowane pod kątem przechwytywania i wyszukiwania połączeń między elementami danych w ramach ich możliwości wyszukiwania i przechwytywania. Korzystając z tych metod, można efektywniej łączyć wiele tabel w języku SQL.
Który typ bazy danych Nosql najlepiej nadaje się do przechowywania danych ze złożonymi relacjami?
Baza danych dokumentów to baza danych pozbawiona schematów, umożliwiająca zdefiniowanie schematu bez konieczności wcześniejszego przestrzegania go. Za pomocą tego systemu możemy przechowywać złożone dane w formatach dokumentów, takich jak XML i JSON.
Który typ bazy danych Nosql wykorzystuje krawędzie i relacje w swojej strukturze?
Ukierunkowana struktura grafu służy do reprezentowania danych w bazie danych Graph Base NoSQL. Graf składa się z węzłów i krawędzi. Graf jest reprezentacją zbioru obiektów, z którymi niektóre pary obiektów są połączone jakimś rodzajem łącza.
Geoprzestrzenny Nosql
Dane geoprzestrzenne to dane zawierające składnik geograficzny, taki jak szerokość i długość geograficzna. Bazy danych Nosql dobrze nadają się do przechowywania i wyszukiwania danych geoprzestrzennych. Wiele baz danych nosql ma wbudowaną obsługę typów i operacji danych geoprzestrzennych .
Dane przestrzenne (pliki, bazy danych, usługi sieciowe) to rodzaj danych, które przechowują informacje geograficzne i mogą być wykorzystywane w aplikacjach rozpoznających lokalizację. Dane z warstwy przestrzennej mogą służyć do reprezentowania warstwy graficznej na mapie, ale można ich również używać do analizowania cech geograficznych i lokalizacji. Był to specjalny typ systemu zarządzania bazą danych, który obsługiwał tylko obiekty przestrzenne i był używany głównie przez analityków przestrzennych. Dane przestrzenne nazywamy punktami, liniami i obszarami informacji kartograficznej, ponieważ są one stworzone do ich przechowywania i obsługi. Ogólnie rzecz biorąc, profesjonalni graficy używali oprogramowania komputerowego do mapowania ESRI do tworzenia (statycznych) map. Oprócz importowania danych, twórcy stron internetowych mogą wysyłać do nich zapytania za pomocą warstwy aplikacji mapowania sieciowego uwzględniającej lokalizację, korzystając z przestrzennej bazy danych. Podczas uzyskiwania dostępu do danych przestrzennych programiści najczęściej tworzą mapę, czy to online, w aplikacji mobilnej, czy na komputerze stacjonarnym.
Kiedy zaczniesz używać danych przestrzennych jako kolejnego obiektu ze współrzędnymi, zauważysz, jak dobrze współpracują one z bazami danych NoSQL. Wykorzystanie obliczeń opartych na klastrach umożliwia wzrost danych przestrzennych w czasie, a zasoby zapytań są łatwo dostępne. Aplikacje te ułatwiają ukrywanie bardziej złożonych zapytań przestrzennych, które są powszechnie używane za kulisami. Przestrzenne bazy danych często po prostu obliczają prostokąt wokół każdej z funkcji w zbiorze danych i używają go jako przybliżonego indeksu do zapytania. Używają MBR, aby określić, jak blisko siebie znajdują się obiekty, aby móc zignorować obiekty, które są zbyt daleko od siebie, aby były ważne. Żądania dokumentów mogą być realizowane przy użyciu oprogramowania NoSQL opartego na N1QL/SQL, takiego jak Couchbase. Za pomocą obiektów geoprzestrzennych można bezpośrednio łączyć z nimi aplikacje niższego szczebla.
Celem tego bloga jest zademonstrowanie, w jaki sposób język programowania R oraz pakiet mapowania Leaflet mogą łatwo żądać danych i generować wyniki. Prawdziwa bitwa toczy się na zewnątrz za pomocą zapytań. Pełnoprawne aplikacje GIS i przestrzenne bazy danych są również w stanie generować duże ilości danych. Specyfikacja obejmuje wiele różnych typów i funkcji obiektów przestrzennych. Inną popularną formą łączenia przestrzennego jest łączenie punktów, w szczególności grupowanie punktów w wielokąty. Najtrudniejszym aspektem jest zaprojektowanie systemu w oparciu o geometrię obliczeniową, co wiąże się z tworzeniem nowych cech. Nie można przecenić znaczenia zarządzania zasobami, ponieważ jest to trudne.

Jaki jest związek między Nosql a danymi przestrzennymi?
Ponieważ NoSQL jest stworzony do obsługi dużych obciążeń, poleganie na nim w aplikacjach GIS zawsze dodaje dodatkową warstwę luksusu ze względu na jego rozproszony charakter obliczeniowy. Kiedy używane są klastry, dane przestrzenne rosną w czasie, a zasoby zapytań można łatwo rozszerzyć.
Korzyści z używania indeksu geoprzestrzennego
Musisz utworzyć indeks przestrzenny w MongoDB, aby móc korzystać z danych przestrzennych w MongoDB. Indeks ten umożliwia wydajniejsze wykonywanie zapytań dotyczących kolekcji kształtów i punktów przestrzennych dzięki wykorzystaniu go jako indeksu zapytań przestrzennych. Do zlokalizowania wszystkich miejsc w dokumencie można użyć indeksu geoprzestrzennego, który wykorzystuje różne kryteria, takie jak szerokość i długość geograficzna. Jakie są korzyści z używania indeksu mapowania? Indeks mapy może przyspieszyć proces lokalizowania obiektów w dokumentach, ponieważ do ich lokalizowania może używać indeksu geograficznego. Poniższy przykład to miejsce, w którym można znaleźć wszystkie restauracje w Twoim mieście. Ponieważ indeks geoprzestrzenny opiera się na szerokości i długości geograficznej, łatwo jest znaleźć dokumenty odpowiadające Twoim kryteriom. Podobnie użycie indeksu geoprzestrzennego może pomóc w zlokalizowaniu obiektów, które niekoniecznie znajdują się w tym samym obszarze. Możesz wyszukać wszystkie dokumenty z szerokością i długością geograficzną, które znajdują się w określonym obszarze geograficznym. Łatwo jest znaleźć wszystkie potrzebne dokumenty, które mają szerokość i długość geograficzną na podstawie twoich kryteriów za pomocą indeksu geoprzestrzennego. Jak utworzyć indeks geoprzestrzenny? Aby utworzyć indeks geoprzestrzenny, należy najpierw utworzyć kolekcję danych zawierającą dane, które mają zostać zindeksowane. Wymagany jest indeks przestrzenny, po którym następuje kolekcja. Ostatnim krokiem jest wygenerowanie zapytania, które używa indeksu geoprzestrzennego do lokalizowania obiektów. O czym należy pamiętać podczas pracy z psy GIS? Podczas pracy z danymi przestrzennymi należy przestrzegać następujących wskazówek. Podczas wyszukiwania obiektów w dokumencie zawsze lepiej jest używać indeksu geoprzestrzennego. Kiedy robisz GIS, upewnij się, że twoje dokumenty są w odpowiednim formacie. Podczas wysyłania zapytań do obiektów zawsze należy podać współrzędne referencyjne. Zakładanie, że dokument zawiera informacje geograficzne, nigdy nie jest dobrym pomysłem. Przed użyciem indeksu zawsze dobrze jest przejrzeć format danych.
Przechowywanie danych geoprzestrzennych
Przechowywanie danych geoprzestrzennych odnosi się do procesu przechowywania danych cyfrowych, które są powiązane z fizyczną lokalizacją. Tego typu dane można wykorzystać do tworzenia map i innych wizualizacji, które pomagają ludziom zrozumieć otaczający ich świat. Istnieje wiele sposobów przechowywania danych geoprzestrzennych, w tym korzystanie z baz danych, plików i usług sieciowych.
Dane geoprzestrzenne typu open source, takie jak Internet rzeczy (IoT), dobrowolna informacja geograficzna (VGI) i otwarte dane geoprzestrzenne, zyskują na popularności. Proces importowania bazy danych PostgreSQL/PostGIS jest uproszczony dzięki HOGS, narzędziu wiersza poleceń. Został opracowany w celu zademonstrowania wydajności tradycyjnego układu pamięci masowej i magazynu dokumentów NoSQL. Chociaż obietnica szybkości NoSQL może wydawać się atrakcyjna, ma też wady. W rezultacie, aby zrozumieć, czy naprawdę możemy porzucić zasady systemów zarządzania relacyjnymi bazami danych (RDBMS), musimy najpierw to rozważyć. HOGS to narzędzie wiersza poleceń Open Source, które wykorzystuje bibliotekę Open Source GDAL/OGR do automatyzacji importowania heterogenicznych danych geoprzestrzennych do baz danych a/postGIS. Magazyny dokumentów, bazy danych wykresów, obiektowe bazy danych i magazyny klucz-wartość to przykłady magazynów danych NoSQL.
Magazyny dokumentów przechowują dane jako dokumenty, a nie tabele w relacyjnej bazie danych, ponieważ nie mają jawnego schematu. Ze względu na łatwość użycia są często używane w połączeniu z zestawami danych typu open source. Standard GeoJSON, który jest używany zarówno przez MongoDB, jak i CouchDB, służy do zapewniania możliwości przestrzennych. Amirian i in. badaj modele zorientowane na dokumenty o 19% szybciej niż modele relacyjne dla danych przestrzennych o dużych wielokątach. Amirian wraz ze współpracownikami przetestował trzy różne strategie przechowywania „ geoprzestrzennych dużych zbiorów danych ” przy użyciu Microsoft SQL Server 2012, przy udziale użytkowników. Układ dokumentu XML (NoSQL document-store) zapewniał najlepszą wydajność i skalowalność podczas ich konfiguracji.
Kilka wyników ich badań pokazuje, że modele oparte na dokumentach powinny być brane pod uwagę w szerokim zakresie scenariuszy przepływu pracy. Używanie MongoDB do wyszukiwania punktów i danych złożonych zapewnia trzykrotnie wyższą wydajność niż PostGIS przy sześciokrotnie większej szybkości. Mimo to PostgIS przewyższa MongoDB ponad 3-krotnie w zapytaniach o promień, gdy promień zapytania wzrasta. Mimo to autorzy przyznają, że bazom danych NoSQL brakuje pewnych możliwości podobnych do RDBMS, ale stwierdzają, że to się zmieni w przyszłości. Python został wybrany jako język do wdrożenia systemu HOGS ze względu na jego wieloplatformową dostępność i integrację z bibliotekami open source, takimi jak GDAL/OGR i GEOS, a także wieloplatformową integrację. Baza danych jest przechowywana na dwa różne sposoby: przechowywanie funkcji i zestawów danych. Tabela cech zawiera wiersze dla każdego atrybutu, kolumnę geometrii i kolumnę identyfikatora cechy; każdy wiersz zawiera funkcję ze zbiorem danych.
Kolumna zawiera identyfikator. Kolumny Geometria i Identyfikator są oddzielnymi kolumnami, które oprócz tabeli są zorganizowane w kolumny. Główną różnicą jest to, że wszystkie atrybuty są przechowywane w jednej kolumnie typu jsonb. HOGS może być używany do obsługi wersjonowania zestawów danych przy użyciu przyrostowych numerów wersji i powiązanych znaczników czasu. HOGS wykorzystuje zarówno NoSQL, jak i tradycyjny układ pamięci oparty na tabelach. Podczas fazy importu pliki każdego zestawu danych są odczytywane i analizowane przed zapisaniem ich w bazie danych przy użyciu instrukcji COPY. Ponieważ każdy plik w imporcie jest osobnym plikiem, ta faza może być wykonywana równolegle z innymi plikami. Szybkość importu, szybkość zapytań i rozmiar bazy danych zostały zmierzone dla każdego układu przechowywania danych.
Norweski organ zajmujący się kartografią, znany jako N50, udostępnił otwarty zestaw danych dla każdego testu porównawczego. Zbiór danych Norwegii kontynentalnej w skali 1:50 000 zawiera osiem podzbiorów danych (zbiorów obiektów) z wieloma warstwami topologicznymi. Po wyodrębnieniu danych w kompletnym zbiorze danych znajduje się 3415 plików o łącznej wielkości 7,9 GB. Metoda importu oparta na tabeli jest o 44% szybsza niż metoda importu jsonb. Importowanie układu tabeli zajmuje około godziny i 19 minut, podczas gdy układ jstrelb trwa około trzech godzin. Uzyskaliśmy 840 geometrii zapytań z dzienników zapytań tego systemu, korzystając z szybkości importu układu tabeli. Te wielokąty pokrywają kontynent norweski w zakresie od 1 do 100 metrów.
Wszystkie metryki pokazują, że układ oparty na tabelach działa lepiej niż układ NoSQL w stylu jsonb. Ze względu na sposób przechowywania atrybutów i liczbę używanych tabel może to stanowić problem. PostgreSQL/PostGIS jest używany przez obie bazy danych i obie bazy danych używają typów geometrii PostGIS. Podstawową różnicą między zapytaniami do danych a plikami jsonb jest rozmiar tabeli; wspólna tabela w plikach jsonb jest większa niż wspólna tabela w zapytaniach danych. Wiele zestawów danych można podzielić na osobne zestawy danych na podstawie typów funkcji, które w nich zawierają. W porównaniu z układem połączonych tabel magazynu dokumentów NoSQL odkryliśmy, że tradycyjny układ z jedną tabelą na zestaw danych przewyższa układ połączonych tabel magazynu dokumentów NoSQL w przypadku jednorodnych zestawów danych. HOGS może być zautomatyzowany i nie wprowadza dodatkowej złożoności poprzez wykorzystanie GDAL/OGR w systemie GDAL/OGR.
Pojedyncza tabela różnych zestawów danych z heterogeniczną mieszanką funkcji wydaje się łatwiejsza w obsłudze, ale ten rodzaj układu nie działa z innymi pakietami GIS. Następnym krokiem jest ustanowienie dokładniejszej konfiguracji testu porównawczego, która obejmuje większy zestaw zestawów danych. Nie zaleca się używania typu danych jsonb w Postgresie do przechowywania jednorodnych zestawów danych w kontekście metadanych dla danych geosynchronicznych . Jeśli wymagania dotyczące przestrzeni dyskowej dla pojedynczej instancji bazy danych nie przekraczają wymagań innej instancji bazy danych, instrukcja zostaje utrzymana. Tradycyjne technologie RDBMS mogą być wykorzystywane do wydajnego przechowywania i wyszukiwania dużych ilości danych geoprzestrzennych. Instrukcja obsługi MongoDB 2018. Według Del Alby typ danych JSONB w PostgresQL przyspiesza operacje.
Czy uważasz, że Nosql poradzi sobie z danymi o użytkowaniu gruntów i pokryciu terenu? Nat Ecodyn. Ta książka została opublikowana w 11:438 do 4426. Możesz opublikować ten artykuł, o ile przestrzegasz licencji Creative Commons (https://creativecommons.org/licenses/by/ 4.0/) na dowolnym nośniku. Według autora nie ma sprzecznych interesów. Pomimo faktu, że opublikowane mapy i powiązania instytucjonalne zawierają roszczenia jurysdykcyjne, Springer Nature jest nadal neutralny.
Wiele zastosowań Gis
Systemy informacji geograficznej (GIS) mogą być wykorzystywane do różnych celów, w tym do mapowania miejsc zbrodni, badań nad zmianami klimatycznymi i zarządzania gruntami. Dostępnych jest kilka rodzajów oprogramowania GIS, z których każdy jest bardziej dostosowany do określonego zadania. ESRI, MapInfo i TopoGIS to przykłady popularnych pakietów oprogramowania GIS.