
Bigtable firmy Google: najczęściej używany magazyn danych zorientowany na kolumny
Opublikowany: 2022-12-19Bigtable to zorientowany na kolumny magazyn danych stworzony przez Google. Jest przeznaczony do obsługi dużych ilości danych z dużą elastycznością. Bigtable jest używany przez Google od ponad dekady i stanowi podstawę wielu jego usług, w tym Gmaila, Map Google i YouTube. Chociaż Bigtable nie jest pierwszym magazynem danych zorientowanym na kolumny, jest z pewnością najczęściej używanym i dobrze znanym.
W tym artykule przyjrzymy się trójwymiarowemu modelowi pamięci masowej NoSQL opracowanemu przez firmę Bigtable. Aby zweryfikować poprawność struktury, najpierw przyjrzymy się, jak jest zaimplementowany w kategoriach teoretycznych, a następnie użyjemy do tego klienta Node.js. Model przechowywania w Bigtable różni się od tego, jaki można znaleźć w podobnej bazie danych. Wiele komórek w kombinacji wiersz/kolumna można uporządkować według znacznika czasu na komórkę. Zamiast zapisywać komórki w dowolnej kolejności, każda komórka ma wartość i sygnaturę czasową, aby zapewnić, że komórki są zapisywane w uporządkowanej kolejności. W tym przykładzie użyjemy Node.js i zwykłego JavaScript do zbudowania Google Cloud Bigtable. W tym artykule omówimy, jak utworzyć nową instancję Bigtable za pomocą kodu.
Zaczynamy od stworzenia czystego środowiska, czytania i pisania w nim, a następnie burzenia go. Podczas uruchamiania kodu przy użyciu klienta Node.js Bigtable klient Node.js Bigtable może spowodować błąd aPermission Denied i wygenerować link umożliwiający włączenie interfejsu Cloud Bigtable Admin API. Powinieneś także utworzyć osobne konto usługi w swoim projekcie GCP, aby obsługiwać rolę administratora Bigtable. Aby utworzyć tabelę Bigtable, musimy najpierw zbudować instancję bazy danych i klaster tabel. Po prostu zdefiniuj identyfikator tabeli i rodzinę kolumn w kliencie Node.js, aby to zrobić, i gotowe. Proste wiersze można tworzyć za pomocą Bigtable w bazie danych. Jedynym sposobem wykonywania zapytań dotyczących danych jest użycie klucza wiersza do wykonania zapytania dotyczącego określonego wiersza lub grupy wierszy.
Chociaż czasy pozyskiwania nie mają wpływu na kolejność przechowywania wersji, mają wpływ na sposób ich przechowywania. Nie jest wymagane podanie całego klucza wiersza; wystarczy po prostu przedrostek. Kiedy musisz wysłać zapytanie do wielu wierszy z Bigtable, zawsze radzę korzystać z przesyłania strumieniowego. Podczas korzystania ze strumieniowania Bigtable nie musi buforować danych na serwerze przed wysłaniem wierszy, co skutkuje szybszą wydajnością. Filtry mogą służyć do ograniczania wersji komórek, zwracając tylko te kolumny z określonymi nazwami rodzin lub kolumny z określonymi kryteriami kwalifikacji. Jest to szczególnie przydatne, jeśli masz wiele wersji do zachowania, ale tylko najnowsza jest wymagana do określonych celów. Filtry służą przede wszystkim do zmniejszenia ilości danych, które są przeszukiwane i wysyłane w celu poprawy wydajności zapytań.
Innymi słowy, Cloud Bigtable to baza danych NoSQL przeznaczona do analiz i obciążeń operacyjnych. Ten system baz danych jest wieloplatformową hybrydą, która wykorzystuje Hadoop zamiast HBase, która wykorzystuje kolumnową bazę danych. Bigtable w chmurze może służyć do zasilania aplikacji o dużej przepustowości i skalowalności, o pojemności mniejszej niż 10 MB.
Apache Cassandra, ScyllaDB, Apache HBase, Google BigTable i Microsoft Azure CosmosDB to przykłady sklepów z szerokimi kolumnami.
Tabele nie są tym samym, co relacyjne bazy danych pod względem przechowywania kluczy/wartości. Transakcje można przeprowadzić tylko raz, a łączenia nie są obsługiwane.
Czy Google Bigtable to baza danych Nosql?
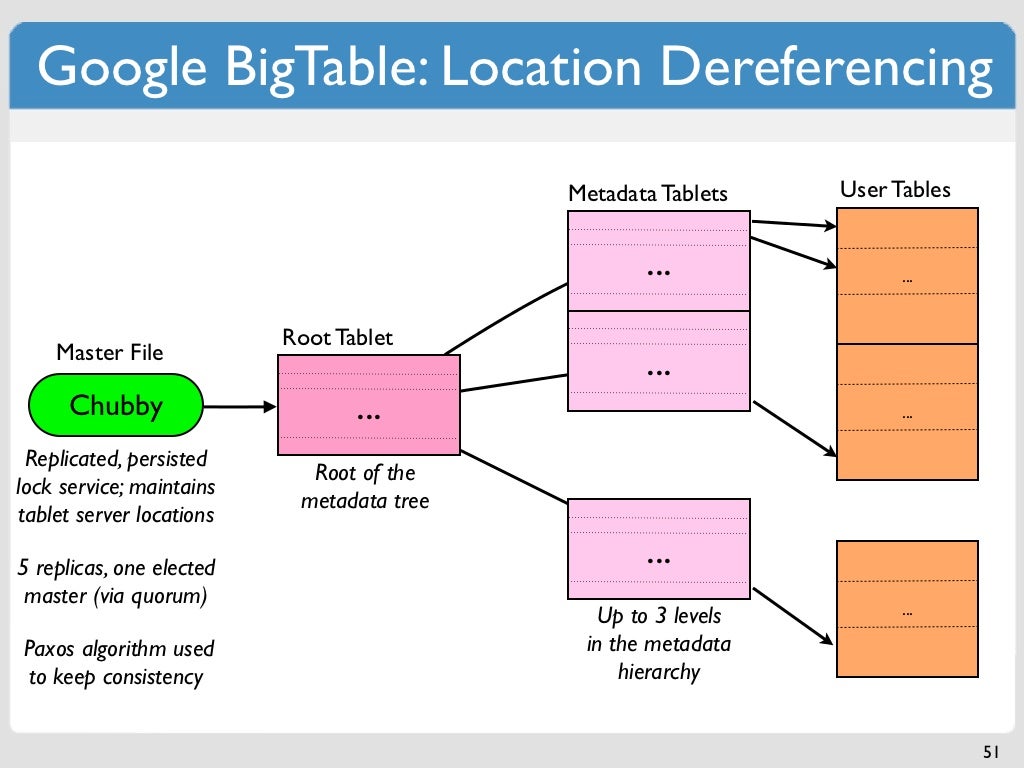
Google Bigtable to baza danych NoSQL przeznaczona do przechowywania i zarządzania dużymi ilościami danych. Bigtable to baza danych zorientowana na kolumny, co oznacza, że dane są zorganizowane w kolumny, a nie wiersze. Dzięki temu doskonale nadaje się do przechowywania stale zmieniających się danych, takich jak dzienniki sieciowe lub dane z mediów społecznościowych. Bigtable jest również wysoce skalowalny, co oznacza, że z łatwością poradzi sobie z dużymi ilościami danych.
Ta baza danych NoSQL może przechowywać szeroki zakres typów danych i jest wyjątkowo stabilna. Obsługuje również sharding i replikację, zapewniając wysoką dostępność i niezawodność bazy danych. Korzysta z niego wiele aplikacji Google, w tym Google Analytics, indeksowanie stron internetowych, MapReduce i Mapy Google, Książki Google, Moja historia wyszukiwania, Google Earth, Blogger.com, Google Code Hosting i aplikacje Google For, które wymagają bazy danych zdolnej do obsługi dużej liczby elementów danych, Datastore to doskonały wybór.
W jakiej kolejności dane są przechowywane w Bigtable?
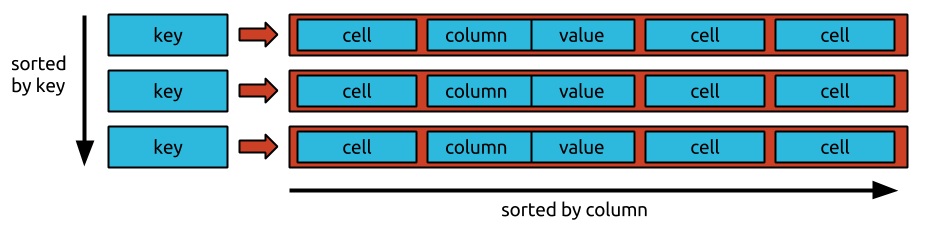
Nie ma określonej kolejności przechowywania danych w bigtable. Dane są przechowywane w przypadkowej kolejności, co utrudnia dostęp do konkretnych danych.
Bigtable Google: nie tylko do przechowywania danych
Dane nie mogą być umieszczone w żadnej określonej kolejności w igtable. Ponieważ Bigtable jest bazą danych zorientowaną na wiersze, wszystkie dane w wierszu są uporządkowane w kolumnach, po których następuje kolumna. Ponieważ dane są przechowywane w odwrotnej kolejności chronologicznej, żądanie najnowszej wartości jest proste i szybkie, ale żądanie najstarszej wartości jest trudne i czasochłonne.
Twoje dane są przechowywane w Colossus, wewnętrznym, długotrwałym systemie plików Google, który jest przechowywany w centrach danych Google, w wyniku korzystania z Colossus przez Bigtable. Bigtable jest darmowy i nie musisz używać klastra HDFS ani żadnego innego systemu plików.
Zapytanie do zewnętrznego źródła danych można wykonać bez tworzenia trwałej tabeli za pomocą polecenia łączenia: Plik definicji tabeli z zapytaniem. Istnieje wbudowana definicja schematu oraz zapytanie. Plik definicji schematu JSON z zapytaniem.
Bigtable kontra magazyn danych
Istnieje kilka kluczowych różnic między Bigtable a Datastore. Po pierwsze, Bigtable to magazyn danych zorientowany na kolumny, podczas gdy Datastore jest zorientowany na wiersze. Oznacza to, że w Bigtable dane są zorganizowane w kolumny, a w Datastore w wiersze. Po drugie, Bigtable nie ma koncepcji transakcji, podczas gdy Datastore tak. Oznacza to, że w Bigtable nie można cofnąć zmian do poprzedniego stanu, podczas gdy w Datastore jest to możliwe. Wreszcie, Bigtable został zaprojektowany z myślą o wysokiej przepustowości i małych opóźnieniach, podczas gdy Datastore został zaprojektowany z myślą o wysokiej dostępności i skalowalności.
Jakiego magazynu danych w chmurze można użyć do tworzenia baz danych Google w chmurze? Ponieważ Bigtable obsługuje duże obciążenia ze złożonymi obciążeniami zaplecza, jest przeznaczony dla większych organizacji i przedsiębiorstw. W przeciwieństwie do SQL, który używa bardziej restrykcyjnego języka zapytań GQL, magazyny danych wykonują transakcje ACID na podzbiorach danych zwanych grupami jednostek (chociaż język zapytań GQL jest znacznie bardziej otwarty). Google Cloud Datastore i Google Cloud Bigtable to dwie odrębne usługi, które mają wiele różnych funkcji. Ponadto informacje na poniższym obrazku mogą pomóc w wyborze odpowiedniego usługodawcy. Powyższe odpowiedzi, a także to, co jest omówione w podręczniku Coursea Google Cloud Platform Big Data and Machine Learning Fundamentals, posłużą mi jako przewodnik po tym artykule.
Jaka jest różnica między Bigtable a Datastore?
Jaka jest różnica między magazynem danych a bazą danych? Zarówno bigtable, jak i datastore są przeznaczone odpowiednio do przetwarzania i analizy dużych ilości danych, podczas gdy datastore jest przeznaczony do danych transakcyjnych o dużej wartości. Datastore jest również znany jako baza danych NoSQL, ponieważ nie jest zgodny z tradycyjnym standardem SQL, co pozwala na przechowywanie danych w bardziej elastyczny i skalowalny sposób. Jakim magazynem danych jest Google Bigtable? Model pamięci masowej Bigtable przechowuje dane w skalowalnych tabelach, które są sortowane według map kluczy i wartości. Tabela składa się z wierszy, z których każdy opisuje pojedynczą jednostkę, oraz kolumn, z których każda zawiera własną wartość. Czy magazyn danych jest przestarzały? Ponieważ interfejs Cloud Datastore API v1beta3 został wydany, nie jest już dostępny. Niemniej jednak produkt Cloud Datastore jest w pełni funkcjonalny i obsługiwany.
Baza danych Bigtable
Bigtable to rozproszony system pamięci masowej do zarządzania danymi strukturalnymi, który został zaprojektowany do skalowania do bardzo dużego rozmiaru: petabajtów danych na tysiącach zwykłych serwerów. Bigtable to baza danych zorientowana na kolumny, co oznacza, że dane są przechowywane według kolumn, a nie wierszy.
Tabela jest rzadką, gęsto wypełnioną strukturą z wierszami i kolumnami, które mogą sięgać miliardów wierszy. Bigtable to doskonały wybór do przechowywania dużych ilości danych z niskimi opóźnieniami. Ponieważ obsługuje wysoką przepustowość odczytu i zapisu przy małych opóźnieniach, jest odpowiednim źródłem danych dla operacji MapReduce. Podczas korzystania z tabeli Bigtable jest ona podzielona na bloki ciągłych wierszy, zwane tabletami, aby ułatwić zapytania. W systemie plików o nazwie Colossus, z którego korzysta Google, tablety są przechowywane w formacie SSTable. Węzeł Bigtable to podzbiór każdego tabletu, który jest częścią instancji Bigtable. Dodanie węzłów do klastra może zwiększyć liczbę jednoczesnych żądań, które może obsłużyć.

Wiersz zawiera zestaw wpisów klucza lub wartości, które są kombinacją rodziny kolumn, sygnatury czasowej kolumny i klucza. Bigtable traktuje wszystkie dane w ten sam sposób: jako surowe ciągi bajtów. Ponieważ Bigtable przechowuje mutacje sekwencyjnie i regularnie je kompaktuje, liczba mutacji, które można przechowywać w danym czasie, wymaga więcej miejsca do przechowywania. Bigtable kompresuje Twoje dane za pomocą zaawansowanego algorytmu, który jest zautomatyzowany. Ponieważ delecje są w rzeczywistości nowymi typami mutacji, w krótkim okresie wymagają więcej miejsca do przechowywania. Zastrzeżone metody przechowywania danych firmy Google umożliwiają osiągnięcie trwałości danych przewyższającej trwałość uzyskiwaną w przypadku standardowej replikacji trójstronnej HDFS. Oprócz zarządzania dostępem do tabel Bigtable możesz zarządzać dostępem do innych usług Google Cloud, przypisując role użytkownikom w sekcji zarządzania tożsamością i dostępem (IAM) swojego projektu Google Cloud. Zgodnie z domyślną zasadą szyfrowania Google Cloud wszystkie dane w chmurze są szyfrowane w stanie spoczynku przy użyciu tych samych systemów zarządzania wzmocnionymi kluczami, których używamy do naszych zaszyfrowanych danych. Korzystając z kopii zapasowej, możesz zapisać kopię schematu i danych tabeli, a następnie odtworzyć tę kopię danych w nowej tabeli w przyszłości.
Bigtable kontra Cassandra
Cassandra i Bigtable używają różnych metod do określenia, który węzeł przetwarzający powinien wykonywać operacje odczytu i zapisu. W Cassandrze klucz partycji jest określany jako klucz, podczas gdy w Bigtable klucz wiersza jest określany jako klucz. Zasady równoważenia obciążenia dla Cassandry muszą zostać sprawdzone przez klienta w ramach tego procesu.
Rozproszona baza danych to taka, która jest współużytkowana przez kilka osób. Ta firma zawiera w swoim systemie wielowymiarowe magazyny klucz-wartość, dzięki czemu może przetwarzać dziesiątki tysięcy zapytań na sekundę (QPS). Celem tego dokumentu jest porównanie i zestawienie dwóch systemów baz danych. Kluczowe funkcje Bigtable obejmują: Opracowano dokument dotyczący rozproszonego systemu przechowywania danych strukturalnych. Jeśli Bigtable stwierdzi, że dla zbioru danych wymagane jest ponowne zrównoważenie zakresu, węzeł przetwarzający może łatwo zmienić zakresy danych, ponieważ warstwa przechowywania jest oddzielona od warstwy przetwarzania. Bigtable może być również używany do obsługi replikacji asynchronicznej w rozproszonych geograficznie klastrach składających się z maksymalnie czterech klastrów w topologiach. Tolerancja błędów Cassandry jest powiązana z jej poziomem dostrajanej spójności.
Konfigurując strategię topologii replikacji danych, można zdefiniować replikację geograficzną. Ogólnie używane jest ustawienie aQUORUM (lub LOCAL_QUORUM w niektórych centrach danych). Aby operacja została uznana za pomyślną, ustawienie poziomu spójności musi zostać spełnione, a większość węzłów repliki odpowiada węzłowi koordynującemu. Wykorzystując konfiguracje centrów danych i szaf, repliki Cassandry są w stanie wytrzymać większe obciążenia w porównaniu z tradycyjnymi replikami. Podczas przeprowadzania operacji odczytu i zapisu topologia określa, które węzły są potrzebne do zagwarantowania spójności. Instancja Bigtable może zawierać pojedynczy klaster lub grupę maksymalnie czterech dużych replik. Bigtable i Cassandra to magazyny danych NoSQL, które są magazynami z szerokimi kolumnami.
Klucz wiersza Bigtable służy do sortowania danych globalnych w tabeli według kolejności. Węzły Bigtable automatycznie równoważą odpowiedzialność węzłów za kluczowe zakresy, znane również jako tablety, w ramach funkcji węzłów Bigtable. Usługa Bigtable klienta nie wymusza typów danych kolumn, które wysyła. W Bigtable każda kolumna w tabeli ma przypisane nazwisko. Pomimo faktu, że tabele często mają więcej rodzin kolumn (maksymalna liczba kolumn w tabeli to 100), każda tabela wymaga co najmniej jednej rodziny kolumn. Przecięcie klucza wiersza składa się z dwóch komórek (rodzina kolumn połączona z kwalifikatorem kolumny). W Cassandrze i Bigtable istnieje metoda wyboru węzła przetwarzającego dla operacji odczytu i zapisu.
W Cassandrze identyfikowany jest klucz partycji, podczas gdy w Bigtable używany jest klucz wiersza. Zasady równoważenia obciążenia uwzględniające centra danych, takie jak zasady dotyczące wielu klastrów, zapewniają możliwość przełączania awaryjnego. Obie bazy danych używają podobnej metody zakończenia zapisu i zostały zoptymalizowane pod kątem szybkości. Dane są przechowywane w dwóch bazach danych za pośrednictwem niezmiennych plików SSTable. W Cassandrze koordynator musi powiadomić klienta, że zapis został zakończony, zanim odpowie kilka replik. Pomyślny zapis w Bigtable może potwierdzić tylko odpowiedź z jednego węzła, ponieważ każdy klucz wiersza jest przypisany tylko do jednego węzła. Komórki w obu bazach danych mogą nie zostać uwzględnione w połączonej tabeli SSTable.
Ze względu na klauzulę WHERE w zapytaniu CQL niemożliwe jest zwrócenie więcej niż jednego wiersza w Cassandrze. W Bigtable wymagana jest konsultacja tylko z węzłem odpowiedzialnym za zakres kluczy. W węźle przetwarzającym istnieje możliwość ograniczenia ilości danych, które można odczytać. Podczas fazy zagęszczania SSTables są regularnie scalane, a dane przechowywane w Bigtable i Cassandra są w nich przechowywane. Nie ma żadnych reguł regulujących liczbę wersji sygnatury czasowej dla każdej komórki, ale mogą obowiązywać inne ograniczenia wielkości wierszy. Gwarancje trwałości danych zapewnia system replikacji Colossus. Bigtable, podobnie jak Cassandra, ma interfejs wiersza poleceń i biblioteki klienckie dla wielu popularnych języków programowania.
Każdy węzeł ma przypisany SSTable w Bigtable, a dane w nim przechowywane są obsługiwane przez ten węzeł. Podczas ustalania rozmiaru klastra Cassandra nie trzeba uwzględniać replik pamięci masowej, tak jak ma to miejsce w przypadku Bigtable. Dyski półprzewodnikowe (SSD) lub dyski twarde (HDD) to najczęściej używane typy pamięci masowej dla instancji Bigtable . Jak wykazała Cassandra, nie ma utraty gęstości pamięci masowej w celu osiągnięcia odporności na awarie. Możliwe jest skalowanie instancji Bigtable w celu spełnienia wymagań dotyczących obciążenia przy minimalnym wysiłku i minimalnym przestoju. Chociaż istnieją tylko cztery klastry, każdy klaster można utworzyć w dowolnym obsługiwanym regionie chmury na całym świecie. Google zaleca przetestowanie wydajności Bigtable za pomocą reprezentatywnych danych i zapytań w celu wygenerowania wskaźnika QPS na węzeł.
Cassandra wykonuje wiele funkcji administracyjnych przy użyciu komponentów zarządzanych przez Bigtable. Kopie zapasowe dużych tabel tworzą przywracalne kopie tabeli, które są przechowywane jako obiekty w klastrze. Kopie zapasowe zużywają mniej zasobów węzła i są tańsze niż przechowywanie w chmurze. Inną metodą tworzenia kopii zapasowych Bigtable jest użycie zarządzanego eksportu danych do Cloud Storage. Wewnętrzne zadania konserwacyjne, takie jak łatanie systemu operacyjnego, odzyskiwanie węzłów, naprawa węzłów, monitorowanie upakowania pamięci masowej i rotacja certyfikatów SSL są bezproblemowo obsługiwane przez usługę Bigtable. Pulpity nawigacyjne są dostępne do monitorowania wskaźników przepustowości i wykorzystania na poziomie instancji, klastrów i tabel na stronie konsoli Bigtable Google Cloud . Możesz użyć pulpitu nawigacyjnego monitorowania, aby przeprowadzić zaawansowane dostrajanie wydajności.
Artykuł Bigtable opisuje system przechowywania danych, który obsługuje masowe skalowanie w poziomie. Każda tabela w danych jest podzielona na pewną liczbę partycji. Możesz wykonać zapytanie w tabeli, używając klucza wiersza lub zakresu kluczy wierszy. Artykuł Bigtable opisuje również metodę dystrybucji pracy tabeli w klastrze węzłów. Apache Cassandra, baza danych typu open source, opiera się na niektórych koncepcjach z dokumentu Bigtable. Centra danych wykorzystują rozproszoną architekturę węzłów, w której pamięć jest współdzielona między serwerami obsługującymi dane. Dostęp do systemu przechowywania danych Bigtable zapewnia interfejs wiersza poleceń cbt oraz biblioteki klienckie. Oprócz Pythona Bigtable zawiera wiele języków programowania, co ułatwia integrację z aplikacjami.
Google Datastax Astra Cassandra jako usługa: łatwa do wdrożenia i skalowania
Google DataStax Astra Cassandra as a Service to doskonały wybór do nauki o Cassandrze. Interfejs użytkownika Kubernetes Operator ułatwia konfigurowanie, zarządzanie i skalowanie wdrożenia Cassandra.
Dokumentacja Bigtable
Dokumentacja Bigtable jest doskonałym źródłem wiedzy o tym potężnym narzędziu. Zawiera przegląd funkcji i możliwości Bigtable, a także szczegółowe informacje o tym, jak z niego korzystać. Dokumentacja jest dobrze zorganizowana i łatwa do prześledzenia, co czyni ją cennym źródłem informacji dla wszystkich zainteresowanych poznaniem tego potężnego narzędzia.
Google Cloud Platform odpowiada za hosting bazy danych Google Bigtable . Jest prosty w użyciu OpenTSDB 2.1 i nowszych, gdy jest używany w połączeniu z zapleczem Google. Wszystko, co musisz zrobić, to utworzyć instancję Bigtable, skonfigurować tabele TSDB przy użyciu powłoki Bigtable HBase i uruchomić TSD. Klienci Bigtable są obecnie w fazie beta i przechodzą różne zmiany.
Wydajny układ danych Bigtable
Bigtable jest również dobrze przystosowany do operacji MapReduce. Ze względu na wydajny układ danych, MapReduce może obsłużyć duże ilości danych w krótkim czasie.