
Hadoop HDFS i NoSQL: potężna kombinacja dla dużych zbiorów danych
Opublikowany: 2023-01-05Hadoop to platforma typu open source, która umożliwia rozproszone przetwarzanie dużych zbiorów danych w klastrach komputerów przy użyciu prostego modelu programowania. HDFS to rozproszony system plików Hadoop , który zapewnia skalowalny i odporny na błędy sposób przechowywania danych. Bazy danych NoSQL to nowa klasa baz danych, które zostały zaprojektowane w celu zapewnienia skalowalnej, elastycznej i wydajnej alternatywy dla tradycyjnych relacyjnych baz danych.
Podstawowa różnica między Hadoop i HDFS polega na tym, że Hadoop to platforma open source do przechowywania, przetwarzania i analizowania danych, podczas gdy HDFS to system plików, który umożliwia użytkownikom dostęp do danych Hadoop. W rezultacie HDFS jest modułem Hadoop .
Zarówno SQL, jak i Hadoop mogą zarządzać danymi na różne sposoby. Framework Hadoop służy do składania komponentów oprogramowania, podczas gdy framework SQL służy do składania baz danych. W przypadku dużych zbiorów danych niezwykle ważne jest rozważenie zalet i wad każdego narzędzia. Platforma Hadoop przechowuje dane tylko raz, podczas gdy Hadoop przechowuje znacznie większą liczbę zestawów danych.
Hadoop nie jest bazą danych, ale oprogramowaniem, które pozwala na masowe przetwarzanie równoległe. Ta technologia umożliwia bazom danych NoSQL (takim jak HBase) rozproszenie danych na tysiącach serwerów przy niewielkim spadku wydajności.
Hadoop nie przechowuje danych w taki sam sposób, jak pamięć relacyjna. Serwer rozproszony to jedna z aplikacji, która korzysta z niego najczęściej. Chociaż jest to baza danych Hadoop , nie kwalifikuje się jako relacyjna baza danych, ponieważ przechowuje pliki w HDFS (rozproszony system plików).
Jaka jest różnica między Nosql a Hdfs?
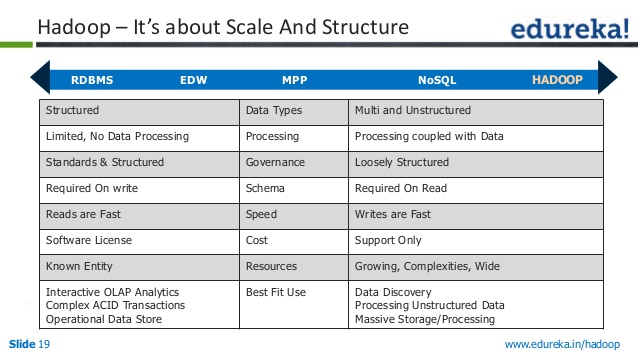
Jest to system plików i jest również określany jako system plików. Jest już jasne, że ta aplikacja oferuje szereg funkcji. Skąd masz te rzeczy z NOSQL? Będziemy w stanie przetwarzać duże ilości danych w czasie rzeczywistym, ponieważ nie wymaga od nas korzystania z relacyjnych baz danych ani innych funkcji.
Menedżer magazynu HBase, który działa w Hadoop, zapewnia losowe odczyty i zapisy o małych opóźnieniach. System HBase wykorzystuje funkcję auto-shardingu, w ramach której duże tabele są dystrybuowane dynamicznie. Każdy serwer regionu jest odpowiedzialny za obsługę zestawu regionów, a tylko jeden serwer regionu może obsługiwać jeden region (tj. HMaster i HRegion to dwie główne usługi świadczone przez HBase. Komponent HRegion tabeli HBase jest odpowiedzialny za obsługę podzbiory danych tabeli Po uruchomieniu Serwera Regionów jest on przypisywany do każdego Regionu W rezultacie master nie jest zaangażowany w operacje odczytu i zapisu.
Jeśli chodzi o radzenie sobie z nieustrukturyzowanymi i obszernymi danymi, bazy danych NoSQL, takie jak MongoDB i Cassandra, wyróżniają się na tle tradycyjnych relacyjnych baz danych. Firmy z dużymi obciążeniami danymi, takimi jak Big Data, wolą używać tych narzędzi do szybkiego przetwarzania i analizowania ogromnych ilości zróżnicowanych i nieustrukturyzowanych danych. MongoDB przechowuje dane w kolekcjach, podczas gdy hadoop przechowuje dane w innym systemie plików znanym jako HDFS. W wyniku tej różnicy korzystne jest posiadanie innej architektury. Wyszukiwanie danych w MongoDB jest również znacznie szybsze niż przeszukiwanie pojedynczych plików. Ponadto, ponieważ mongodb jest przeznaczony do środowisk o dużej objętości, dobrze nadaje się do obsługi dużych ilości danych przy stosunkowo niskich kosztach. Zaleca się, aby firmy, które potrzebują rozwiązań Big Data, korzystały z baz danych NoSQL. Mają wiele zalet w porównaniu z tradycyjnymi bazami danych pod względem szybkości przetwarzania i analiz, a także dobrze nadają się do analizy i zarządzania danymi na dużą skalę.
Czy Hadoop jest bazą danych Nosql?
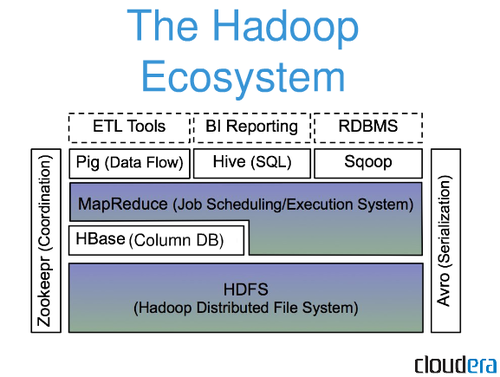
Hadoop nie jest tradycyjnym systemem zarządzania relacyjnymi bazami danych. Jest to rozproszony system plików, który pomaga przechowywać i przetwarzać duże zbiory danych w klastrze serwerów towarowych. Hadoop zaprojektowano z myślą o skalowaniu od pojedynczych serwerów do tysięcy maszyn, z których każda oferuje lokalne obliczenia i pamięć masową.
Wykorzystanie danych na ogromną skalę jest rewolucjonizowane przez nowe technologie. Infrastruktura Big Data ma wielu graczy, w tym Hadoop, NoSQL i Spark. Administratorzy baz danych i inżynierowie/programiści infrastruktury pracują teraz dla nich, aby zarządzać złożonymi systemami w ramach nowego rodzaju administratorów baz danych i inżynierów infrastruktury. Ponieważ Hadoop jest ekosystemem oprogramowania, a nie bazą danych, umożliwia obliczanie ogromnych ilości danych z szybkością, która jest zarówno wydajna, jak i efektywna. Korzyści, jakie zapewnia w przypadku ogromnych ilości danych, które obsługuje, zmieniły zasady przetwarzania dużych zbiorów danych. Transakcję dużych danych, na przykład taką, której ukończenie zajmuje 20 godzin w scentralizowanym systemie relacyjnej bazy danych, można zrealizować w klastrze Hadoop w ciągu zaledwie trzech minut.
Istnieje więcej niż jeden język SQL do wyboru. MongoDB, czysta baza danych dokumentów, jest jednym z typów baz danych NoSQL; Cassandra, szerokokolumnowa baza danych, to kolejna; a Neo4j, baza danych wykresów, to kolejna. Ta funkcja została stworzona przez SQL-on- Hadoop . SQL-on-Hadoop to nowa klasa narzędzi analitycznych, które łączą sprawdzone zapytania SQL ze strukturami danych Hadoop. SQL-on-Hadoop umożliwia programistom korporacyjnym i analitykom biznesowym współpracę z Hadoop w klastrach obliczeniowych, umożliwiając uruchamianie znanych zapytań SQL. Zalety SQL-on-hadoop. Liczne zalety SQL-on-Hadoop, oprócz łatwości użytkowania, są warte czasu i zasobów programistów i analityków danych korporacyjnych. Na początek mogą pracować z Hadoopem w klastrach obliczeniowych, co pozwoli im szybko i łatwo rozpocząć pracę z analizą dużych zbiorów danych. SQL-on-Hadoop pozwala im również wykorzystać znane zapytania SQL, ułatwiając im naukę analizy dużych zbiorów danych. Co więcej, SQL-on-Hadoop udostępnia funkcję mapowania/zmniejszania Hadoop, a także bogate możliwości analizy danych, które oferuje.
Bazy danych Nosql zyskują na popularności
W rezultacie bazy danych NoSQL stają się coraz bardziej popularne ze względu na ich skalowalność, wydajność odczytu/zapisu i elastyczność danych. Na rynku istnieje kilka dobrych przykładów baz danych NoSQL, w tym DynamoDB, Riak i Redis.
Hive to lekka i modułowa baza danych NoSQL o doskonałych wskaźnikach wydajności. Jest napisany w czystym języku programowania Dart i jest popularny wśród programistów ze względu na swoją prostotę.
Jaka jest różnica między Hadoop a bazą danych?

Podczas gdy RDBMS nie przechowuje i nie przetwarza danych, Hadoop raczej przechowuje i przetwarza dane jako rozproszony system plików. Z drugiej strony RDBMS to ustrukturyzowana baza danych, która przechowuje dane w wierszach i kolumnach i może być aktualizowana za pomocą SQL i prezentowana w różnych tabelach.
Przyjęcie technologii i narzędzi big data wzrosło w szybkim tempie. Dystrybucja Hadoop typu open source działa w rozproszonym systemie plików i umożliwia wymianę i przetwarzanie dużych zbiorów danych. RDB to podstawowy system zarządzania bazami danych, który jest używany w najprostszej formie przez wszystkie systemy zarządzania bazami danych, takie jak Microsoft SQL Server, Oracle i MySQL. Pomimo tego, że RDBMS został sklasyfikowany jako ewolucja, bardziej przypomina każdą inną standardową bazę danych niż duże przedsięwzięcie. Nie jest to baza danych, ale raczej rozproszony system plików, w którym można przechowywać i przetwarzać duże zbiory plików danych. Chociaż systemy takie jak Hadoop mogą zapewniać lepszą wydajność, istnieją pewne wady, o których rzadko się mówi. Musisz pomyśleć o tym, jak zarządzać klastrem Hadoop, bezpieczeństwem, Presto lub jakimkolwiek innym używanym interfejsem.
Większość systemów relacyjnych baz danych, takich jak SQL Server i Oracle, jest znacznie łatwiejsza w użyciu. Większość organizacji boryka się z poważnym problemem związanym z brakiem wystarczającej liczby wykwalifikowanych pracowników, którzy potrafią efektywnie obsługiwać Hadoop, a także ze znacznymi kosztami talentów. Jeśli masz 10 000 pracowników, będziesz potrzebować wielu danych, aby śledzić ich wszystkich. Informacje te mogą być przechowywane w Presto na różne sposoby. Partycja daty może być używana do przechowywania pozycji osoby każdego dnia. Z drugiej strony RDBMS może służyć jako przykład modelu danych. Jedynym sposobem użycia tej metody jest posiadanie dostępu do danych z poprzedniego dnia.
Jaka jest kluczowa różnica między relacyjnymi bazami danych a dużymi danymi?
Podstawowa różnica między relacyjnymi bazami danych a dużymi danymi polega na tym, że relacyjne bazy danych są zoptymalizowane do przechowywania danych strukturalnych, podczas gdy duże zbiory danych są zoptymalizowane do przechowywania danych nieustrukturyzowanych i częściowo ustrukturyzowanych. Relacyjna baza danych jest modelowana na podstawie modelu relacyjnego, podczas gdy duża baza danych jest modelowana na podstawie modelu rozproszonego. Ustrukturyzowane dane mogą być efektywnie przechowywane i przetwarzane w relacyjnych bazach danych. Tabela zawiera dane i umożliwia dostęp i pobieranie w języku zapytań strukturalnych (SQL). Big data definiuje się jako wszelkie dane, które są nieustrukturyzowane lub częściowo ustrukturyzowane.

Jaka jest różnica między Hadoop a Mongodb?
Ponieważ MongoDB działa w C, lepiej zarządza pamięcią niż jakakolwiek inna baza danych. Hadoop to oparty na Javie zestaw oprogramowania, który zapewnia platformę do przechowywania, pobierania i przetwarzania danych. Hadoop optymalizuje przestrzeń skuteczniej niż MongoDB.
MongoDB była bazą danych NoSQL (nie tylko SQL) utworzoną w C. Hadoop to platforma oprogramowania typu open source złożona głównie z języka Java, która umożliwia przetwarzanie dużych ilości danych. Ponadto Atlas MongoDB obejmuje wyszukiwanie pełnotekstowe, zaawansowaną analizę i intuicyjny język zapytań. Hadoop skutecznie przechowuje i przetwarza duże ilości danych, ale robi to w małych partiach. W MongoDB dostępnych jest wiele wbudowanych narzędzi do przetwarzania danych w czasie rzeczywistym. Dzięki złączom do zewnętrznych narzędzi, takich jak Kafka i Spark, MongoDB upraszcza pobieranie i przetwarzanie danych. Przewag Hadoop i MongoDB nad tradycyjnymi bazami danych w dziedzinie big data jest wiele. Hadoop, rozproszony system plików, może być używany do radzenia sobie z ogromnymi plikami. MongoDB to jedyna baza danych, która pod względem wydajności może zastąpić tradycyjną bazę danych.
Rdbms vs Nosql vs Hadoop
Istnieją trzy główne typy magazynów danych — RDBMS, NoSQL i Hadoop. Każdy z nich ma swoje mocne i słabe strony, dlatego ważne jest, aby wybrać odpowiedni dla swoich potrzeb.
RDBMS (Relational Database Management System) to najpopularniejszy typ magazynu danych. Jest łatwy w użyciu i łatwy do skalowania. Jednak nie jest tak elastyczny jak NoSQL czy Hadoop, a jego utrzymanie może być droższe.
NoSQL (Not Only SQL) to nowszy typ magazynu danych, który staje się coraz bardziej popularny. Jest bardziej elastyczny niż RDBMS i może być bardziej skalowalny. Jednak nie jest tak łatwy w użyciu i może być droższy w utrzymaniu.
Hadoop to typ magazynu danych przeznaczony dla dużych zbiorów danych. Jest bardzo skalowalny i może obsłużyć wiele danych. Jednak nie jest tak łatwy w użyciu jak RDBMS czy NoSQL, a jego utrzymanie może być droższe.
Podejście przedsiębiorstwa do przechowywania, przetwarzania i analizowania danych można znacznie poprawić dzięki platformie Apache Hadoop . Jezioro danych może obsługiwać wiele rodzajów obciążeń analitycznych na tym samym sprzęcie i oprogramowaniu, a także zarządzać wolumenami danych na dużą skalę. Analitycy mogą teraz efektywnie wchodzić w interakcje z danymi w ruchu, korzystając z narzędzi takich jak Apache Impala i Apache Spark. Hadoop, w przeciwieństwie do Relational Database Management System (RDBMS), nie ma takich samych możliwości jak baza danych, ale jest bardziej rozproszonym systemem plików zdolnym do przetwarzania ogromnych ilości danych. Ilość danych, które można łatwo i skutecznie przetworzyć, określa się mianem wolumenu danych. Innymi słowy, można zoptymalizować cały proces wolumenu danych w określonym przedziale czasu. Posiada możliwość przechowywania i przetwarzania danych z szerokiej gamy źródeł oraz przygotowania ich do analizy.
W niewielkiej ilości RDBMS mógł zarządzać tylko danymi ustrukturyzowanymi i częściowo ustrukturyzowanymi. Hadoop nie jest w stanie obsługiwać danych z różnych źródeł ani żadnej struktury strukturalnej. Czas reakcji, skalowalność i koszt to tylko niektóre z innych ważnych czynników, które należy wziąć pod uwagę.
Dlaczego Rdbms jest wciąż najpopularniejszym systemem zarządzania bazami danych
Najszerzej stosowanym systemem zarządzania bazami danych na świecie jest RDBMS. Zapewnia szeroki zakres funkcji, a także jest wyjątkowo niezawodny. Relacyjna baza danych najlepiej nadaje się do przechowywania danych, do których dostęp ma wielu użytkowników.
Bazy danych NoSQL zyskują na popularności częściowo ze względu na ich przewagę wydajności nad relacyjnymi bazami danych. Pozwalają również przechowywać duże ilości danych, których nie trzeba udostępniać wielu użytkownikom.
Hadoop Nosql
W klastrze sprzętowym Hadoop przechowuje Big Data. W razie potrzeby masz możliwość zmiany dowolnej funkcji, która nie działa lub spełnia Twoje potrzeby. Natomiast system zarządzania bazą danych NoSQL to rodzaj systemu zarządzania bazą danych, który służy do przechowywania danych ustrukturyzowanych, częściowo ustrukturyzowanych i nieustrukturyzowanych.
Czy Hdfs jest bazą danych
System plików HDFS to rozproszony system plików, który działa na zwykłym sprzęcie. Pojedynczy klaster Apache Hadoop można skonfigurować do obsługi setek (a nawet tysięcy) węzłów za pomocą tej funkcji. Apache Hadoop, który obejmuje również MapReduce i YARN, składa się z kilku głównych komponentów.
Wysoce wydajny dostęp do danych zapewnia Hadoop Distributed File System (HDFS), który jest składnikiem systemu operacyjnego Hadoop . Węzeł podstawowej nazwy klastra jest odpowiedzialny za śledzenie miejsca przechowywania danych pliku klastra. Oprócz zarządzania dostępem do plików węzeł Nazwa zarządza dostępem do plików, takimi jak odczyty, zapisy, tworzenie, usuwanie itd. Firma Yahoo wprowadziła rozproszony system plików Hadoop w ramach swoich wymagań dotyczących umieszczania reklam online i wyszukiwarek. Protokół HDFS udostępnia przestrzeń nazw systemu plików w celu przechowywania danych użytkownika. Węzły danych mogą komunikować się ze sobą podczas normalnych operacji na plikach, ponieważ komunikują się ze sobą. Rozproszony system plików Hadoop (HDFS) jest składnikiem wielu jezior danych typu open source. HDFS jest używany przez eBay, Facebook, LinkedIn i Twitter do analizowania dużych ilości danych. W przypadku awarii węzła lub sprzętu replikacja danych jest wymagana do prawidłowego działania HDFS.
Przykład bazy danych Hadoop
Baza danych Hadoop to baza danych korzystająca z rozproszonego systemu plików (HDFS) Hadoop jako podstawowego magazynu. Bazy danych Hadoop są zwykle używane do przechowywania dużych ilości danych, które są zbyt duże, aby zmieściły się na jednym serwerze.
Platforma open source do przechowywania i przetwarzania dużych zbiorów danych w sposób rozproszony na zwykłym sprzęcie, Apache Hadoop jest używana w różnych aplikacjach. Jest to wersja open source paradygmatu Google, który został użyty w ich dokumencie MapReduce z 2004 roku. W tym artykule omówimy niektóre z najczęściej zadawanych pytań przez początkujących w ekosystemie Big Data. Platforma Apache Hadoop koncentruje się na rozproszonym przetwarzaniu danych, a nie na przechowywaniu bazy danych lub relacyjnej pamięci masowej. Pomimo obecności składnika pamięci masowej znanego jako HDFS (Hadoop Distributed File System), który przechowuje pliki używane do przetwarzania, HDFS należy do kategorii relacyjnej bazy danych. Hive, jak również HiveQL, mogą być używane do wysyłania zapytań do pamięci HDFS HDFS, która jest wbudowana w HDFS.
Jaki jest przykład Hadoop?
Hadoop może być używany przez firmy świadczące usługi finansowe do oceny ryzyka, budowania modeli inwestycyjnych i tworzenia algorytmów handlowych; Hadoop był również używany do pomocy w tworzeniu tych aplikacji i zarządzaniu nimi. Ta technologia jest używana przez sprzedawców detalicznych, aby pomóc im lepiej zrozumieć i obsługiwać swoich klientów poprzez analizę ustrukturyzowanych i nieustrukturyzowanych danych.
Wiele zastosowań Hadoop
Hadoop może być używany do zarządzania danymi w aplikacjach do obsługi dużych zbiorów danych, takich jak analiza dużych zbiorów danych, analiza danych w czasie rzeczywistym, badania naukowe i hurtownie danych. W rezultacie jest to wszechstronna i elastyczna platforma, idealna do szerokiego zakresu zastosowań.
Czy Spark jest bazą danych Nosql
NoSQL DataFrame, zgodnie z dokumentacją, jest formatem źródła danych dla Spark DataFrame. DataPruning i filtrowanie (przesuwanie predykatów) są dostępne w tym źródle danych, co umożliwia uruchamianie zapytań platformy Spark na mniejszych ilościach danych i ładowanie tylko danych wymaganych dla aktywnego zadania.
Połączenie ze sobą bazy danych Apache Spark i NoSQL (Apache Cassandra i MongoDB) wymaga dużego wysiłku taktycznego. Ten blog dotyczy tworzenia aplikacji Apache Spark na zapleczu NoSQL. TCP/IP sPark to popularny park rozrywki z dużą liczbą przejażdżek w dobrze znanych sekcjach CassandraLand i MongoLand. Kiedy nasza aplikacja Spark wyszukiwała dane z DOE, kręciła się i była sfrustrowana. Lekcja jest taka, że kluczowa sekwencja Cassandry jest krytyczna w procesie pobierania danych. CassandraLand ma również popularną kolejkę górską o nazwie Partitioner. Klienci korzystający z kolejek górskich są zachęcani do śledzenia historii swoich przejazdów, aby operatorzy mogli śledzić, kto jechał nią każdego dnia. Mongo Lekcja 1 – Prawidłowe zarządzanie połączeniami MongoDB Podczas aktualizowania danych, takich jak status nowego członkostwa w parku Departamentu Energii, indeksy Mongo mogą być bardzo pomocne. W przypadku konkretnych aktualizacji MongoDB i Spark powinny zapewnić odpowiednie zarządzanie połączeniami i indeksację.
Spark: przyszłość dużych zbiorów danych
Apache Spark, rozproszony system przetwarzania opracowany we współpracy z Apache Software Foundation, to oparty na technologii Hadoop system przetwarzania dużych zbiorów danych. Platforma open source, której można używać do optymalizowania dużych zbiorów danych i wypełniania luki między modelami proceduralnymi i relacyjnymi. Ponadto Spark obsługuje MongoDB, dzięki czemu może być używany do analiz w czasie rzeczywistym i uczenia maszynowego.