
Skalowalność pozioma dzięki bazom danych NoSQL
Opublikowany: 2022-11-20Bazy danych NoSQL są skalowalne w poziomie, co oznacza, że można je skalować, dodając więcej węzłów do systemu, w przeciwieństwie do skalowania pionowego, które odnosi się do dodawania większej liczby zasobów do pojedynczego węzła. Oznacza to, że bazę danych NoSQL można podzielić na fragmenty lub na wiele części, a każdy element można przechowywać na osobnym serwerze. Pozwala to na poziome skalowanie bazy danych, które jest znacznie bardziej wydajne i skalowalne niż skalowanie pionowe.
Skalowanie ma kluczowe znaczenie dla baz danych SQL i NoSQL, a koncepcja dzielenia bazy danych na fragmenty jest jego zasadniczą częścią. Dzielimy bazę danych na części (odłamki), jak sugeruje nazwa.
Ponadto w NoSQL brakuje możliwości operacji dynamicznych. Nie ma gwarancji, że związek będzie miał właściwości ACID. Bazy danych SQL są opcją w takich przypadkach. Ponadto, jeśli Twoja aplikacja wymaga elastyczności czasu wykonywania, unikaj NoSQL.
Jakie są wady baz danych NoSQL? Jedną z wad baz danych NoSQL jest brak obsługi transakcji ACID (niepodzielność, spójność, izolacja, trwałość) wymaganej dla transakcji ACID w wielu dokumentach. Wiele aplikacji może używać atomowości pojedynczego rekordu z odpowiednim projektem schematu.
Czy Mongodb można podzielić?
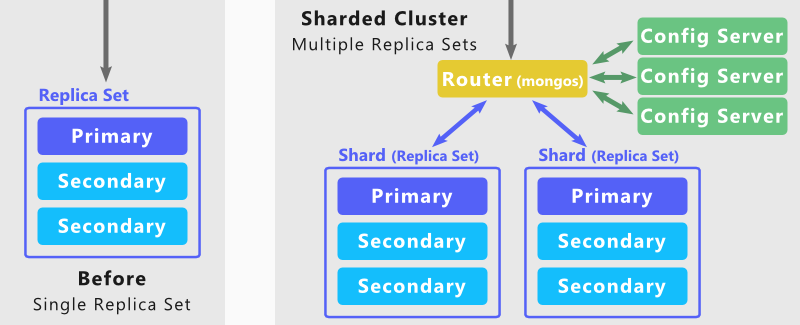
Backend MongoDB jest zbudowany na architekturze shardingu w celu obsługi bardzo dużych zbiorów danych i operacji o wysokiej przepustowości. Duże bazy danych z dużymi ilościami danych lub działające aplikacje o dużej szybkości mogą powodować zmniejszenie wydajności serwera.
Korzystając z MongoDB Sharding, możesz skalować swoją bazę danych, aby obsłużyć nieskończoną liczbę jednoczesnych użytkowników. Osiąga się to poprzez zwiększenie przepustowości odczytów i zapisów, a także pojemności pamięci masowej systemu. Istnieje wiele kolekcji, z których możesz wybierać. Aby zmaksymalizować wydajność klastra, ostrożnie wybierz klucz fragmentu. Baza danych MongoDB NoSQL obsługuje dwa typy dystrybucji danych w klastrach z możliwością dzielenia na części. Dane można podzielić na zakresy przy użyciu wartości klucza zakresu fragmentu. Za pomocą mieszania mieszającego można obliczyć wartość zaszyfrowanego odłamka.
Niektóre klucze cząstkowe mogą być zamknięte, ale ich zahaszowane wartości raczej nie będą znajdować się w tej samej porcji. Skonfigurowanie i włączenie ustawienia Sharding umożliwi dostęp do bazy danych. Upewnij się, że Twoje mongo są połączone. Twoje odłamki również zostaną dodane do klastra. Za każdym razem, gdy wykonasz tę procedurę, zakończysz jedną transakcję dla każdego odłamka. Konieczne jest włączenie ustawienia shardingu w bazie danych. Następnie użyj metody sh.shardCollection(), aby podzielić kolekcję na fragmenty. Właśnie utworzyłeś swój pierwszy klaster podzielony na fragmenty. Do tej pory do interakcji aplikacji używane były routery (instancje mongos).
MongoDB to doskonała baza danych NoSQL dla małych i średnich firm, które wymagają skalowalności i wydajności. Ponadto zawiera funkcje, takie jak sharding, który pozwala na dystrybucję dokumentów między shardami w celu poprawy wydajności. Jeśli Twoja baza danych osiągnie 200 GB lub więcej, procesy tworzenia kopii zapasowych i przywracania mogą zostać spowolnione. W rezultacie, gdy Twoja baza danych MongoDB przekroczy określony rozmiar, zawsze powinieneś skonsultować się z dostawcą MongoDB.
Jakie bazy danych obsługują dzielenie?

Bazy danych obsługujące sharding są zazwyczaj zaprojektowane do działania na wielu serwerach, przy czym każdy serwer obsługuje część bazy danych. Pozwala to na rozproszenie bazy danych na wielu serwerach, co może poprawić wydajność i skalowalność.
Sharding w Nosql

Wzorce partycjonowania oparte na technologiach NoSQL obejmują mieszanie. Partycjonowanie polega na umieszczeniu każdej partycji na potencjalnie oddzielnym serwerze — prawdopodobnie na całym świecie. Użytkownicy z całego świata mogą korzystać z tego skalowania w poziomie, co umożliwia im dostęp do różnych części zestawu danych w tym samym czasie.
Zbiory danych są dystrybuowane poprzez przechowywanie ich w wielu bazach danych w celu osiągnięcia pożądanego rezultatu. Ponieważ takie podejście pozwala na dzielenie większych zestawów danych na mniejsze fragmenty, do ich przechowywania można używać wielu węzłów danych. Ponieważ dane są rozproszone na wielu komputerach, baza danych podzielona na fragmenty może obsłużyć więcej żądań niż pojedynczy komputer. Wykorzystując Sharding do obsługi zwiększonego obciążenia w nieograniczonym zakresie, możesz zwiększyć przepustowość, pojemność i dostępność w swojej bazie danych. Gdy obciążenie jest głównie zapisywane do odczytu, replikacja danych zapewni znaczny wzrost wydajności i może w ogóle nie być konieczne korzystanie z dzielenia na fragmenty. W przypadku obciążenia opartego głównie na pisaniu lub mieszanego z odczytem i zapisem wymagana jest inna architektura. Istnieje wiele różnych typów i architektur shardingu.

Korzystanie z fragmentacji opartej na zakresach jest prostą i bezpośrednią metodą podziału poziomego; jednak o jego skuteczności zadecyduje dostępność odpowiednich kluczy i wybór odpowiednich zakresów. Zaszyfrowany lub algorytmiczny rekord podziału na fragmenty jest stosowany jako dane wejściowe, gdzie funkcja lub algorytm skrótu jest używany do generowania danych wyjściowych lub wartości skrótu. Dane można przechowywać w pojedynczej przestrzeni fizycznej za pomocą dzielenia na fragmenty opartego na mieszaniu. W relacyjnej bazie danych dane powiązane z określoną tabelą mogą być rozproszone w innych tabelach. Nawet jeśli nie można uzyskać odpowiedniego klucza, haszowanie danych wejściowych umożliwia równomierną dystrybucję danych między fragmentami. Może pomóc w zmniejszeniu operacji nadawania, a także zwiększyć wydajność. Usługa shardingu oparta na geografii przechowuje również powiązane dane w jednym miejscu na jednym serwerze. Odłamek dystansowy to taki, który jest rozproszony geograficznie, w którym klucz do klucza jest kluczem zlokalizowanym geograficznie dla odłamków. Istnieje wiele innych opcji, które nie zostały omówione w tym artykule, dotyczące przydzielania geoodłamków.
Co to jest dzielenie w Sql?
Magazyn danych można rozmieścić w wielu bazach danych za pomocą metody mieszania, a następnie przechowywać na wielu komputerach. Pozwala to na dzielenie większych zestawów danych na mniejsze fragmenty i przechowywanie ich w wielu węzłach danych, co zwiększa ogólną pojemność systemu.
Ten algorytm nie gwarantuje równomiernego podziału danych
Ten algorytm, zgodnie z tym algorytmem, gwarantuje, że dane będą równomiernie rozłożone na shardach, ale nie gwarantuje, że będą one równomiernie rozłożone na shardach. Wiersz w kolumnie partycji z nazwą danych user_id zostanie równo rozłożony na pięć fragmentów; jednak wartości danych dla pięciu fragmentów nie zostaną równo podzielone.
Czy Mongodb używa Shardingu?
Korzystając z kombinacji technik, wiele maszyn może udostępniać dane za pomocą metody Sharding. Podczas wdrażania dużych zestawów danych i wykonywania operacji o dużej objętości MongoDB stosuje sharding. Systemy baz danych z dużą ilością danych lub aplikacjami, które wymagają dużej przepustowości, mogą zajmować znaczną ilość pojemności pamięci masowej.
Przyszłość shardingu: Postgresql
Zrób plan na przyszłość. Wdrożenie rozwiązania shardingu jest nie tylko możliwe, ale jest to również wymagany krok. W ramach tego procesu wymagane jest regularne dostrajanie i optymalizacja. Należy mieć świadomość, że dzisiejsze rozwiązania shardingu szybko ewoluują i należy być na bieżąco. PostgreSQL poczynił znaczne postępy w obszarze shardingu w ciągu ostatnich kilku lat, więc jeśli potrzebujesz rozwiązania, którego można używać na wielu platformach, powinieneś poważnie rozważyć jego użycie.
Nosql Sharding kontra partycjonowanie
Partycjonowanie i algorytmy sortowania dużego zestawu danych na mniejsze sekcje są analogiczne. Dane są dzielone na partycje, dzięki czemu można je rozmieścić na wielu komputerach, podczas gdy sharding umożliwia ich dystrybucję na wielu komputerach. Ogólnie rzecz biorąc, partycjonowane dane są dzielone na podzbiory w oparciu o pojedynczą instancję bazy danych .
Partycjonowanie przez odejmowanie jest rodzajem partycji, oprócz partycjonowania poziomego. Inną metodą jest podział pionowy, w którym dzielisz tabelę na mniejsze części. Replikacja partycji pionowej jest nazywana partycjonowaniem pionowym. Aby podzielić dane, skopiuj schemat, a następnie użyj klucza fragmentu. Oto kilka przykładów, kiedy należy podzielić stół. Gdy dane są podzielone na partycje, często łatwiej jest wykonywać zapytania. Załóżmy, że aplikacja zawiera tabelę Order zawierającą historyczny rekord zamówień i że ta tabela jest dzielona na partycje co tydzień. Gdy zamawiasz zamówienia na jeden tydzień, będziesz mieć dostęp tylko do jednej sekcji tabeli Zamówienia. Procedura czyszczenia partycji dla tego zapytania mogłaby teoretycznie umożliwić jego działanie 100 razy szybciej.