
Jak skalują się bazy danych Sql i Nosql
Opublikowany: 2022-11-18Przy stale rosnącej popularności aplikacji internetowych i ilości generowanych przez nie danych potrzeba baz danych, które można szybko i wydajnie skalować, jest ważniejsza niż kiedykolwiek. Bazy danych SQL i NoSQL to dwa najpopularniejsze wybory programistów poszukujących skalowalnego rozwiązania bazodanowego. Bazy danych SQL istnieją od dziesięcioleci i są tradycyjnym wyborem dla wielu aplikacji. Używają ustalonego schematu, co oznacza, że struktura bazy danych jest z góry zdefiniowana i wszystkie dane muszą być zgodne z tym schematem. Może to utrudnić pracę z bazami danych SQL, gdy zbiory danych są duże i złożone. Z drugiej strony bazy danych NoSQL są stosunkowo nowe i są przeznaczone do pracy z dużymi i złożonymi zbiorami danych. Posiadają elastyczny schemat, co oznacza, że strukturę bazy danych można dowolnie zmieniać. Może to ułatwić pracę z bazami danych NoSQL, ale oznacza również, że mogą one nie być tak niezawodne jak bazy danych SQL. Zarówno bazy danych SQL, jak i NoSQL mają swoje zalety i wady, jeśli chodzi o skalowalność. Bazy danych SQL są trudniejsze w obsłudze, ale są bardziej niezawodne. Bazy danych NoSQL są łatwiejsze w obsłudze, ale mogą nie być tak niezawodne.
W zależności od typu bazy danych można zastosować różne techniki i zasady skalowania. Skalowanie ma kluczowe znaczenie zarówno dla baz danych NoSQL, jak i innych niż NoSQL, a koncepcja dzielenia bazy danych na fragmenty jest kluczowym elementem. Kiedy serwery są rozproszone, zyskujemy możliwość przechowywania większej ilości danych, jednocześnie dziedzicząc problemy systemu rozproszonego. Inżynierowie musieliby ręcznie napisać logikę, aby obsłużyć automatyczne dzielenie na fragmenty w bazie danych mainframe, ponieważ nie obsługuje tego. Jako rozwiązanie umieść serwer proxy, taki jak moduł równoważenia obciążenia, przed usługą zapytań i bazą danych. Serwer proxy można ponownie uruchomić, jeśli fragment jest zbyt duży, co pozwoli na szybsze wykonywanie zapytań. Powszechnie przyjmuje się, że skalowanie baz danych NoSQL jest wysoce zautomatyzowanym procesem, który widzi tylko użytkownik końcowy.
Architektura master-slave opiera się na jednorazowych transakcjach, podczas gdy architektura oparta na shardach opiera się na transakcjach losowych. Zapytanie odczytu skierowane do fragmentów podrzędnych zmniejszy obciążenie fragmentu głównego. Możemy replikować bazę danych na poziomie centrum danych, aby mieć pewność, że mamy kopię zapasową. Węzły mogą komunikować się ze sobą poprzez wymianę informacji. Węzły często komunikują się z określoną liczbą innych węzłów. Węzeł w Cassandrze może po prostu replikować swoje dane w innych węzłach, ponieważ węzły są uważane za równe. Protokół plotek jest podzbiorem całej koncepcji węzłów.
Możesz zrezygnować z pewnych właściwości w rozproszonej bazie danych, aby uzyskać ich więcej. Replikacja danych jest prawie zawsze krytyczna w celu utrzymania dostępności. Na początku będziesz mieć niewielką różnicę w spójności bazy danych, ale z czasem ulegnie to poprawie. Bazy danych SQL są używane do bardziej precyzyjnych danych w systemach finansowych, podczas gdy bazy danych NoSQL są używane do mniej ważnych danych, takich jak liczba wyświetleń.
Dwie metody skalowania bazy danych to skalowanie w pionie i zwiększanie mocy procesora lub pamięci RAM istniejącej maszyny bazy danych. Dodaj więcej maszyn do klastra bazy danych , aby obsłużyć podzbiór wszystkich danych w celu skalowania w poziomie.
Era internetu i przetwarzania w chmurze umożliwiła tworzenie baz danych NoSQL, co ułatwiło wdrożenie architektury skalowalnej w poziomie. Architektura skalowalna w poziomie wymaga rozłożenia przechowywania danych i pracy wymaganej do ich przetwarzania na dużą liczbę komputerów.
Zaletą jest również możliwość obsługi dużych ilości danych. Bazy danych SQL można skalować w pionie, co pozwala załadować większy serwer z większą mocą procesora, pamięci RAM i dysku SSD.
Jak skalują się bazy danych Nosql?
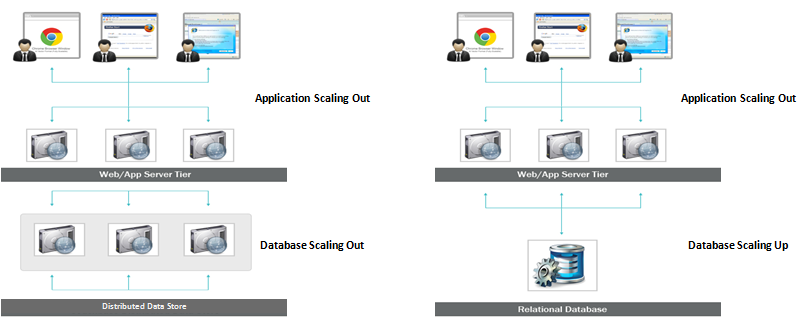
Ponieważ bazy danych SQL są skalowalne w pionie, można zwiększyć obciążenie pojedynczego serwera, zwiększając ilość pamięci RAM, dysku SSD lub procesora w bazie danych SQL. Z drugiej strony bazy danych NoSQL są skalowalne w poziomie, co oznacza, że mogą łatwiej obsługiwać zwiększony ruch, dodając więcej serwerów.
Rahim Yaseen z Couchbase przeprowadza nas przez kilka krytycznych punktów. Do organizacji napływa ogromna ilość danych, które szukają sposobów zarządzania, przechowywania i wykorzystywania tych danych. Kluczową decyzją w zarządzaniu bazą danych jest skalowanie w poziomie lub w górę. Ręczny podział na fragmenty, w którym każda rejestracja jest przypisana do innej kabiny, umożliwia rozłożenie rejestracji na kilka stanowisk odprawy. Ponieważ istnieje dobrze zdefiniowany, z góry zdefiniowany schemat, to działa. Gdybyś miał automatyczne wybieranie numeru, musiałbyś iść do każdej budki i poszukać osób o nazwisku S. Baza danych dokumentów ma wiele kluczowych wzorców bezpośredniego dostępu, które wymagają bezpośredniego dostępu do danych za pomocą jednego klawisza i przejścia do innego dokumentu za pomocą powiązany klucz. Indeksowanie wtórne i zapytania to dwa główne wyzwania w przypadku danych rozproszonych.
Ponieważ każdy węzeł musi uczestniczyć w wykonywaniu zapytania w celu uruchomienia zapytania, użycie techniki zmniejszania mapy jest niepotrzebne. Wraz ze wzrostem ilości danych skalowanie w stylu RDBMS staje się coraz mniej praktyczne. Awaria architektury skalowania leżącej u podstaw dużego zestawu danych prawie na pewno doprowadzi do jednego dużego punktu awarii. Jako klasyczny przykład ultraskalowego klastra bez współdzielenia, Internet jest jednym z nich.
Bazę danych NoSQL można skalować w poziomie, aby zaspokoić potrzeby szerokiego grona użytkowników. Możliwe jest ich użycie na dowolnej maszynie, bez konieczności posiadania specjalistycznego sprzętu. W rezultacie NoSQL jest doskonałym wyborem dla systemów, które wymagają możliwości szybkiego skalowania lub bez rozległej wiedzy.
Jak skalują się bazy danych SQL?
Skala to liczba, która ma wartość po prawej stronie przecinka dziesiętnego. Liczba ta ma na przykład dokładność 5 i skalę 2. W SQL Server numeryczne i dziesiętne typy danych mogą osiągnąć maksymalną dokładność 38 bitów. Domyślne maksimum programu SQL Server we wcześniejszych wersjach wynosiło 28.
W tym artykule przedstawię kilka podstawowych pomysłów i wskazówek dotyczących skalowania tradycyjnych relacyjnych baz danych . Powszechnie przyjmuje się, że skalowanie powinno odbywać się pionowo (na jednym serwerze bazy danych) przy użyciu lepszego sprzętu. Podczas wybierania typów danych zawsze ważne jest zrównoważenie wydajności i funkcjonalności. Normalizacja i denormalizacja danych to dwa podstawowe sposoby myślenia o optymalnych typach danych. Podczas analizowania dużych ilości danych wstępne przetwarzanie danych może być korzystne. Używając odpowiednich indeksów w tabelach, można znacznie poprawić wydajność. Musimy dokładnie wiedzieć, w jaki sposób nasz planista zapytań obsługuje nasze zapytania, aby upewnić się, że wykonuje zadanie prawidłowo.
Kiedy spojrzymy na strukturę naszych danych, możemy określić, czy dodać indeksy, czy przepisać nasze zapytanie. Cztery podstawowe poziomy izolacji zdefiniowane w standardzie SQL:1992 w dużym stopniu wpłyną na to, jak korzystamy z naszego systemu bazodanowego . Przed podjęciem decyzji, czy kompresja w warstwie aplikacji przyniesie pożądane korzyści, należy najpierw zbadać, w jaki sposób przechowywane są dane i czy kompresja jest wymagana. Ponieważ wstawienie kolumny w określonym miejscu zajmuje dużo czasu, preferowane jest wstawienie nowej kolumny na końcu tabeli. Maska bazy danych może być już zaśmiecona skompresowanymi danymi. Możemy skalować operacje zapisu w poziomie, dodając więcej serwerów, ale możemy również używać replik tylko do odczytu, aby zwiększyć naszą pojemność. Partycjonowanie na sterydach pozwala nam przechowywać części tabeli bazy danych (shard) na różnych serwerach.
Sharding to proces przechowywania danych w bazach danych. Inne rozszerzenie bazy danych, takie jak TimescaleDb lub PostGIS, może służyć do poprawy wydajności przetwarzania i przechowywania danych. Istnieje możliwość przenoszenia danych z jednego systemu do drugiego i tam je przetwarzać. Możemy również przesłać go do analitycznej bazy danych, takiej jak Hadoop lub Clickhouse. Dystrybucja Apache Spark to bezpłatne oprogramowanie typu open source do rozproszonego przetwarzania w klastrach, którego można używać do obliczeń danych na dużą skalę. Inne sposoby przenoszenia danych obejmują kopiowanie bazy danych, wyodrębnianie danych przy użyciu SQL i tak dalej. Jeśli wybierzesz dostawców chmury, takich jak AWS lub Azure, powinieneś mieć świadomość, że nie obsługują oni zarządzanych baz danych SQL.
To ograniczenie jest jeszcze większe, gdy mamy do czynienia z dużymi zestawami danych, które są rozproszone w wielu węzłach. Te zestawy danych są dzielone przez MySQL Cluster na możliwe do zarządzania fragmenty i równolegle dystrybuowane do węzłów. Jeśli baza danych ma migawkę w dowolnym momencie, nie będzie musiała czekać na zwrócenie wyniku przez zapytanie. W rezultacie można wykorzystać tę zaletę skalowalności do analizowania dużych zestawów danych w czasie rzeczywistym lub masowego przetwarzania danych. MySQL Cluster to doskonały wybór dla obciążeń wymagających prostej obsługi ze względu na łatwość obsługi, pozwalającą zaoszczędzić pieniądze i czas przy zachowaniu tych samych funkcji, co tradycyjna relacyjna baza danych. Klaster MySQL to świetna opcja dla firm, które chcą skalować swoje bazy danych w poziomie, nie rezygnując z wydajności. Zamiast tradycyjnego systemu relacyjnych baz danych, firmy mogą zaoszczędzić pieniądze i czas, wykorzystując MySQL Cluster.

Stany Zjednoczone Ameryki to kraj zbudowany na idei wolności, kraju wolności
Czy Nosql czy Sql są bardziej skalowalne?
W większości przypadków bazy danych SQL mogą być skalowalne w pionie. Pojedynczy serwer można rozbudować o większą pojemność procesora, pamięci RAM lub dysku SSD, aby obsłużyć większy ruch. Bazy danych NoSQL można skalować w poziomie. Dzieląc na fragmenty, możesz zwiększyć liczbę serwerów w swojej bazie danych NoSQL, co pozwala obsłużyć większy ruch.
Aplikacje wymagają większej skalowalności, ponieważ stają się bardziej złożone. Należy również wziąć pod uwagę magazyny danych, które można wydajnie i łatwo skalować. Podstawowe rozróżnienie między nimi polega na tym, czy baza danych powinna być „ASL”, czy „NoSQL”. Bazy danych SQL istnieją od dawna, podczas gdy bazy danych NoSQL są dobrze znane ze swojej łatwości skalowalności. Każda operacja w bazie danych NoSQL wymaga użycia fragmentacji. Każda operacja na danych musi zawierać metodę kwalifikującą, która identyfikuje węzeł, w którym znajdują się dane. Dane są przechowywane na wielu komputerach, co ułatwia operacje na danych nawet na maszynach o niskim poborze mocy.
Aby skalowanie sklepów NoSQL było łatwiejsze, stosuje się proste maszyny towarowe. Opierając się na NoSQL, użytkownik zakłada, że wstępnie zaplanuje i ustrukturyzuje dane w taki sposób, aby wszystkie wymagane dane dla określonej operacji mogły zostać pobrane za jednym razem z tego samego węzła. Dane muszą być również znormalizowane w węzłach (wstępnie przygotowane dane do działania), aby mogły zostać znormalizowane. W NoSQL możesz łączyć pliki, ale nie oczekuj połączeń w stylu SQL ze zoptymalizowanymi strukturami. Aplikacje w świecie NoSQL wierzą, że spójność danych jest zapewniona w czasie. Sensowne jest, aby systemy NoSQL zapewniały przełączniki umożliwiające wprowadzanie zmian w zakresie spójności wykraczających poza to, co jest wymagane. Ważnym aspektem każdej decyzji dotyczącej architektury, podobnie jak każdego innego aspektu, jest przyjrzenie się przypadkowi użycia i wybranie odpowiedniego magazynu danych.
Wybór odpowiedniej bazy danych ma kluczowe znaczenie, ponieważ wymaga dużej liczby użytkowników. MongoDB, Apache HBase i Cassandra to bazy danych NoSQL, które można wdrażać szybciej niż standardowe bazy danych . Powodem tego jest to, że nie są zgodne z modelem ACID, co może skutkować niższą wydajnością. Z drugiej strony bazy danych NoSQL są w stanie działać na wysokim poziomie, gdy jest to wymagane. Wybierając bazę danych, upewnij się, że jest ona odpowiednia dla Twoich potrzeb.
Dlaczego warto używać relacyjnych baz danych?
Skalowanie bazy danych w pionie ma sens, ponieważ jest dobrze chroniona i ma małe opóźnienia. Nierelacyjnym bazom danych, w przeciwieństwie do relacyjnych baz danych zgodnych ze standardem ACID, brakuje spójności i bezpieczeństwa pod względem wydajności i skalowalności. Baza danych NoSQL to doskonały wybór do skalowania poziomego, ponieważ nie ma ograniczeń co do liczby serwerów i można ją szybko skalować ze względu na niską szybkość przetwarzania.
Dlaczego Sql nie jest skalowalny w poziomie?
SQL nie jest skalowalny w poziomie, ponieważ jest systemem zarządzania relacyjnymi bazami danych (RDBMS). Systemy RDBMS nie są zaprojektowane do skalowania w poziomie. Są zaprojektowane do skalowania w pionie, co oznacza, że są zaprojektowane do skalowania w górę poprzez dodanie większej liczby zasobów (procesora, pamięci itp.) do pojedynczego serwera.
Dlaczego Nosql jest lepszy do skalowania w poziomie?
Bazę danych NoSQL można skalować w poziomie. Oprócz obsługi większego ruchu, sharding umożliwia dodanie większej liczby serwerów do bazy danych NoSQL. Nie jest tajemnicą, że bazy danych NoSQL są preferowanym wyborem w przypadku dużych i często zmieniających się zbiorów danych, ponieważ ich możliwości skalowania w poziomie przewyższają możliwości skalowania w pionie.
Jak skalować bazę danych Nosql
skalowanie baz danych nosql to proces zwiększania zdolności systemu do obsługi zwiększonych obciążeń poprzez dodawanie większej liczby zasobów. Proces skalowania bazy danych nosql można podzielić na dwa główne podejścia: skalowanie pionowe i skalowanie poziome.
Skalowanie pionowe to proces dodawania większej liczby zasobów do pojedynczego węzła w systemie, na przykład dodawania większej liczby rdzeni procesora, pamięci lub pamięci masowej. Takie podejście można wykorzystać do zwiększenia pojemności bazy danych nosql w celu obsługi większej liczby danych lub większej liczby użytkowników.
Skalowanie w poziomie to proces dodawania większej liczby węzłów do systemu. Takie podejście można wykorzystać do zwiększenia pojemności bazy danych nosql w celu obsługi większej liczby danych lub większej liczby użytkowników poprzez dodanie większej liczby węzłów do systemu i rozłożenie obciążenia między węzłami.
Jeśli masz działające środowisko Node.js, będziesz w stanie ukończyć ten samouczek. Stworzyłem folder o nazwie nodejs-dynamodb-sample zawierający zaimportowane przeze mnie pliki DynamoDB. Zobacz moją stronę GitHub, aby uzyskać link do próbki. Przykładowa aplikacja jest dostępna do wyszukiwania i pobierania danych filmów z DynamoDB. W tym artykule użyjemy usługi Amazon Identity and Access Management (IAM) do przechowywania danych w S3 i uzyskiwania dostępu do DynamoDB w Amazon Web Services (AWS). Aby móc korzystać z usługi IAM firmy Amazon, należy najpierw zarejestrować się i utworzyć użytkownika. Możesz utworzyć nowe konto POST /movies, wprowadzając tytuł i rok filmu.
Jeśli chcesz śledzić filmy z określonego roku, wprowadź pole z kluczem. Następnie możesz przejść do tworzenia własnej aplikacji na podstawie tej. Jeśli nie usuniesz swoich tabel po ich użyciu, ryzykujesz poniesieniem kosztów hostingu i obsługi AWS. Odwiedzając konsolę DynamoDB w Amazon Web Services, możesz zobaczyć, ile masz miejsca w AWS. Możesz przeglądać pozycje w tabeli w tabeli Pozycje, uzyskiwać dostęp do metryk z aplikacji i sprawdzać szacowany koszt miesięczny, klikając opcję „Filmy”. Kod do tego ćwiczenia można znaleźć na mojej stronie GitHub, https://github.com/adamfowleruk/nodejs-dynamodb-sample.
Plusy i minusy baz danych Nosql i Sql
Z różnych powodów bazy danych NoSQL stały się alternatywą dla tradycyjnych baz danych SQL . Proces skalowania jest w dużej mierze niewidoczny dla użytkownika końcowego, ponieważ został zaprojektowany z myślą o skali. Dzięki temu idealnie nadają się do zastosowań wymagających dużej przepustowości lub małych opóźnień. Bazy danych NoSQL lepiej nadają się do danych nieustrukturyzowanych, takich jak dokumenty, podczas gdy bazy danych SQL lepiej nadają się do transakcji wielowierszowych. Ogólnie rzecz biorąc, istnieje różnica w sposobie obsługi transakcji w każdym typie bazy danych. Bazy danych SQL wyróżniają się wierszami tabeli dla transakcji, podczas gdy bazy danych NoSQL wyróżniają się dokumentami dla transakcji. Chociaż ta różnica nie zawsze jest oczywista, w niektórych przypadkach może być znacząca.
Jak Nosql skaluje się w poziomie
Bazy danych Nosql są zaprojektowane tak, aby były skalowalne, co oznacza, że mogą obsłużyć rosnące ilości danych i ruch bez spowalniania. Jednym ze sposobów osiągnięcia tego celu jest skalowanie w poziomie, co oznacza dodawanie kolejnych serwerów do systemu w razie potrzeby. Kontrastuje to ze skalowaniem w pionie, co oznacza dodawanie mocniejszych serwerów.
Bazy danych Nosql są łatwiejsze do skalowania w poziomie
Ponieważ bazy danych NoSQL są wolne od schematów, skalowanie w poziomie jest łatwiejsze, ponieważ obiekty można przechowywać na różnych serwerach bez konieczności łączenia wierszy. Ładujesz bazę danych systemu z wielu serwerów w ramach skalowania poziomego.
Różnica między Sql a Nosql
Bazy danych SQL to relacyjne bazy danych, które używają ustrukturyzowanego języka zapytań do przechowywania i pobierania danych. Bazy danych NoSQL to nierelacyjne bazy danych, które nie używają ustrukturyzowanego języka zapytań i często są bardziej skalowalne i wydajniejsze niż bazy danych SQL.
Strukturalne języki zapytań (SQL) należą do najczęściej używanych i popularnych języków programowania w systemach zarządzania relacyjnymi bazami danych . Dane przechowywane i pobierane w modelach NoSQL innych niż formularze tabelaryczne są łatwiej dostępne. Oba produkty są wymienione z pełnym zrozumieniem ich zalet i wad, aby zapewnić jasny obraz ich zalet i wad. SQL jest najpopularniejszym językiem programowania dla RDBMS i służy do przechowywania danych nieustrukturyzowanych, częściowo ustrukturyzowanych i ustrukturyzowanych, podczas gdy NoSQL jest najpopularniejszym językiem programowania do przechowywania danych ustrukturyzowanych, nieustrukturyzowanych i częściowo ustrukturyzowanych. W zależności od wymagań i projektu, nad którym pracujesz, dobra opcja jest lepsza. Istnieje rozróżnienie między tymi dwoma typami: pierwszy koncentruje się na złożonych zapytaniach o spójności danych i właściwościach ACID, podczas gdy drugi jest oparty na obiektach i może obsługiwać szeroki zakres typów danych.