
Jak przechowywać uporządkowane dane w bazie danych NoSQL
Opublikowany: 2022-11-17Bazy danych NoSQL są często używane do przechowywania danych nieustrukturyzowanych , ale mogą być również używane do przechowywania danych strukturalnych. Istnieje kilka różnych sposobów przechowywania danych strukturalnych w bazie danych NoSQL, a najbardziej odpowiednia metoda będzie zależeć od konkretnych danych i pożądanego wyniku. Jednym ze sposobów przechowywania danych strukturalnych w bazie danych NoSQL jest podejście zorientowane na dokumenty. Oznacza to, że dane są przechowywane w dokumentach, które następnie są organizowane w kolekcje. Innym sposobem przechowywania danych strukturalnych w bazie danych NoSQL jest zastosowanie podejścia klucz-wartość. Oznacza to, że dane są przechowywane w magazynie klucz-wartość, w którym każdy klucz odpowiada wartości. Wreszcie, podejście zorientowane na wykresy może być również wykorzystane do przechowywania danych strukturalnych w bazie danych NoSQL. Oznacza to, że dane są przechowywane na wykresie, w którym węzły reprezentują dane, a krawędzie reprezentują relacje między danymi.
Termin „dane nieustrukturyzowane” ma wiele konotacji i może oznaczać coś innego dla różnych osób. RDBMS, ponieważ oczekuje od ciebie zdefiniowania wszystkiego, oczekuje, że zrobisz to z góry (zwłaszcza. Na przykład trudno byłoby zarządzać danymi za pomocą nazwy i typu kolumny (takich jak ta). Kiedy użytkownik ostatnio odwiedził konkretnego kraju, chciałbyś wiedzieć, jak często go odwiedzali. W bazie danych No. SQL istnieje możliwość zamodelowania tabeli w taki sposób, aby nazwa komórki odpowiadała nazwie tabeli. BLOB może być bezpiecznie przechowywane w dowolnym systemie RDBMS, w tym w Oracle Database i innych relacyjnych bazach danych Wartość klucza nie może być określona w przypadkach CLOB i BLOB Ponieważ są one częściowo ustrukturyzowane (JSON, XML, nie wszystkie pola są znane), rozróżnia się je ze względu na ich nieustrukturyzowany charakter.
Bazy danych NoSQL są często używane do obsługi częściowo ustrukturyzowanych danych. Urządzenia IIoT generują ustrukturyzowane, nieustrukturyzowane i częściowo ustrukturyzowane dane w czasie rzeczywistym. Łatwo jest zarządzać i przetwarzać dane strukturalne, gdy struktura jest zdefiniowana przez sprzedawcę.
Hadoop może pomóc firmie w ustrukturyzowaniu i zrozumieniu wzorców i trendów ukrytych w ogromnych ilościach danych generowanych z różnych źródeł, zwłaszcza w dobie ogromnych ilości danych. Oczywiste jest, że doskonałe możliwości Hadoop w zakresie danych nieustrukturyzowanych są nie do przecenienia, ale można je również wykorzystać do rozwiązywania złożonych problemów z danymi strukturalnymi.
Dla firm, które przetwarzają i analizują ogromne ilości zróżnicowanych i nieustrukturyzowanych danych, takich jak Big Data, NoSQL jest lepszą opcją. Bazy danych NoSQL nie mają takich samych ograniczeń jak relacyjne bazy danych co do tego, jakie dane mogą być przechowywane.
Czy Mongodb może przechowywać dane strukturalne?

Tak, MongoDB może przechowywać dane strukturalne. Robi to za pomocą BSON (Binary JSON) do przechowywania danych w formacie binarnym. BSON jest nadzbiorem JSON, więc każdy dokument JSON może być przechowywany w bazie danych MongoDB .
Na przykład MongoDB zyskało na popularności w ostatnich latach z powodu różnych czynników. Aplikacja na dużą skalę, w której dane nie mogą być ustrukturyzowane i muszą być przechowywane w elastyczny sposób, dobrze nadaje się do przechowywania w chmurze. Ponieważ MongoDB jest klasyfikowany jako nieustrukturyzowana baza danych, stosuje inne podejście do przechowywania danych . Ponieważ JSON to typ danych, który można formatować na różne sposoby, pliki tekstowe i inne nieustrukturyzowane zasoby są przechowywane w tym formacie. MongoDB dobrze nadaje się do obsługi dużych ilości danych, ponieważ jest zbudowany do tego celu. MongoDB z łatwością poradzi sobie z dużymi wolumenami danych, ponieważ jest to fizycznie niemożliwe.
Jakie rodzaje danych przechowuje Nosql?
Bazy danych NoSQL są używane do przechowywania danych, które nie mają struktury, co oznacza, że nie pasują one do tradycyjnego formatu tabeli. Może to obejmować posty w mediach społecznościowych, komentarze, obrazy lub cokolwiek innego, co nie pasuje do tradycyjnej struktury bazy danych . Ponieważ bazy danych NoSQL są bardziej elastyczne, mogą być dobrym wyborem dla aplikacji wymagających szybkiego i łatwego dostępu do dużych ilości danych.
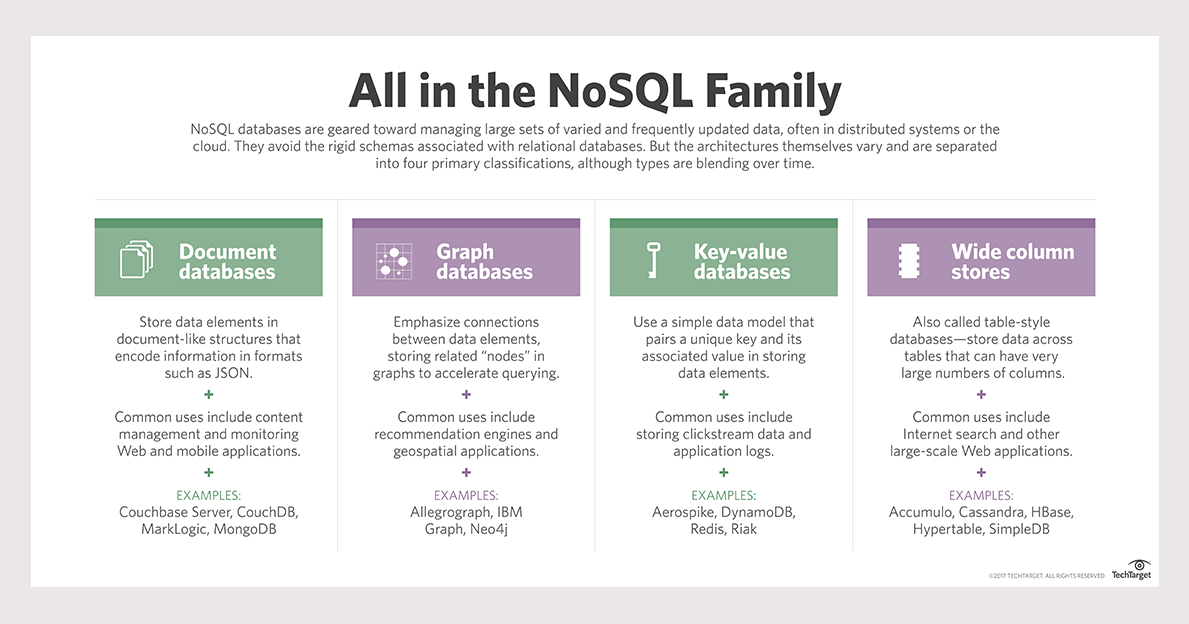
Termin „nierelacyjna baza danych” odnosi się do bazy danych, która nie ma ustalonej struktury. Bazy danych magazynu klucz-wartość, zorientowane na kolumny, oparte na dokumentach, grafach i grafach to najpowszechniejsze typy baz danych. W świecie NoSQL bazy danych klucz-wartość należą do najprostszych typów baz danych w użyciu. Dane są przechowywane, gromadzone i usuwane za pomocą prostego zestawu funkcji. Baza danych magazynu klucz-wartość nie ma języka zapytań, którego można użyć. Rodzaje danych są określone przez wymagania aplikacji, które je przetwarzają. Najczęstszym przypadkiem użycia baz danych klucz-wartość jest rejestrowanie sesji w aplikacjach wymagających logowania.
Oprócz bardziej ogólnego zastosowania koszyk na zakupy umożliwia witrynom handlu elektronicznego przechowywanie danych o sesjach zakupowych każdego użytkownika. Gdy trwają wyprzedaże świąteczne i specjalne promocje, przydatna jest skalowalność sklepów typu klucz-wartość. Ponadto system ma wbudowaną redundancję, dzięki czemu żaden element z wózka nigdy nie zostanie utracony. Bazy danych klucz-wartość służą określonemu celowi i zawierają funkcje, które dodają wartości niektórym, a jednocześnie nakładają ograniczenia na inne.
Język programowania MongoDB jest nie tylko popularny, ale także niezwykle elastyczny. W rezultacie możesz zwiększyć liczbę serwerów, aby obsłużyć dodatkowe obciążenie. Oprócz tego funkcja replikacji MongoDB zapewnia, że dane są zawsze aktualne i znajdują się w wielu lokalizacjach. W rezultacie MongoDB jest bardzo atrakcyjną opcją dla dużych organizacji, które chcą zachować niezawodność i spójność danych.
Czy Nosql to dane nieustrukturyzowane czy częściowo ustrukturyzowane?
Nierelacyjne bazy danych są używane do przechowywania ustrukturyzowanych i nieustrukturyzowanych danych w NoSQL (a nie tylko ustrukturyzowane języki zapytań). Ze względu na wysoką skalowalność i łatwość wyszukiwania, NoSQL jest idealny dla danych nieustrukturyzowanych.

Dane mogą być przechowywane w różnych formatach, takich jak arkusze kalkulacyjne, tekst i wideo, a nawet pliki audio. Jest to rodzaj danych, które są przechowywane w magazynie i oczekuje się, że będą miały pewną predefiniowaną strukturę przed zapisaniem. Nieustrukturyzowany zestaw danych to taki, którego nie można przechowywać w relacyjnej bazie danych , ponieważ brakuje mu predefiniowanego modelu danych. Dane nieustrukturyzowane to termin odnoszący się do danych nieustrukturyzowanych, które nie mają struktury, ale zawierają pewną formę metadanych, których można użyć do znalezienia struktury danych lub hierarchii danych. Inżynierowie i naukowcy zajmujący się uczeniem maszynowym i sztuczną inteligencją analizują tego typu dane przy użyciu technik takich jak uczenie maszynowe i sztuczna inteligencja, aby wyodrębnić znaczenie (lub nawet strukturę wysokiego poziomu). Obejmuje e-maile i inne dokumenty w podobnym formacie, ale zawierają metadane, które umożliwiają użytkownikom dostęp do określonych informacji na określonym poziomie, niezależnie od formatu. W tym artykule omówiliśmy kilka rzeczywistych przykładów każdego z różnych typów danych, a także przyjrzeliśmy się, w jaki sposób są one używane w nowoczesnych organizacjach.
Dane strukturalne są zwykle przechowywane w bazach danych (które są później wykorzystywane do hurtowni danych). Dane nieustrukturyzowane są przechowywane w nierelacyjnych bazach danych lub jeziorach danych, ponieważ nie ma z góry zdefiniowanego schematu, którego należy przestrzegać, aby dane mogły zostać sklasyfikowane. W przypadku danych częściowo ustrukturyzowanych i opartych na hierarchii dobrym rozwiązaniem jest MongoDB.
Systemy bazodanowe NoSQL zyskały na popularności ze względu na ich skalowalność i elastyczność. Ta metoda przechowywania danych jest idealna dla danych nieustrukturyzowanych i częściowo ustrukturyzowanych, a także danych częściowo ustrukturyzowanych i nieustrukturyzowanych. Ponieważ łatwiej jest pracować z danymi w bardziej zwinny sposób, są one idealne do programowania iteracyjnego.
Nieustrukturyzowane przechowywanie danych
Nieustrukturyzowany system przechowywania danych to system plików, który nie narzuca żadnej struktury przechowywanym danym. Dane są po prostu przechowywane jako plik płaski, bez struktury narzuconej przez system plików. Ten typ systemu pamięci masowej jest zwykle używany do przechowywania danych tekstowych lub binarnych, takich jak obrazy, które nie muszą być zorganizowane w żaden szczególny sposób.
Ta kategoria obejmuje około 80% danych nieustrukturyzowanych. Ilość, różnorodność i szybkość nieustrukturyzowanych danych utrudnia ich przechowywanie. Systemy pamięci masowej, które tradycyjnie były budowane do obsługi dużych ilości nieustrukturyzowanych danych, mogą nie być w stanie tego zrobić w przyszłości. W rezultacie Twoja infrastruktura przechowywania danych musi być w stanie obsłużyć dużą liczbę transakcji, a także skalować. Podczas opracowywania projektu dużych zbiorów danych bardzo ważne jest, aby firmy planowały z wyprzedzeniem przechowywanie nieustrukturyzowanych danych. Bardzo ważne jest, aby wybrać sprawną, ekonomiczną, skalowalną i dostosowaną do szerokiego zakresu zastosowań infrastrukturę pamięci masowej. Baza danych Nosql (Norelational) to doskonały sposób na przechowywanie tych informacji.
MongoDB Atlas lub inne bazy danych w chmurze , takie jak MongoDB as a Service (DaaS), to doskonałe opcje. Baza danych MongoDB przechowuje dane w formacie BSON (podobnym do json) na podstawie dokumentów. Atrybuty dokumentu różnią się w zależności od typu danych. Ponieważ kopie zapasowe danych są tworzone i mogą być replikowane, magazyny dokumentów są wysoce skalowalne i dostępne do projektowania. Platforma MongoDB Atlas baza danych jako usługa wykorzystuje główne platformy chmurowe, takie jak AWS, Azure i Google Cloud do przechowywania baz danych. Zanim będzie można uzyskać dostęp do hurtowni danych, na nieustrukturyzowanych danych należy wykonać etap wyodrębniania, przekształcania i ładowania (ETL). Hurtownie danych przetwarzają i przechowują dane z różnych źródeł, aby zapewnić ich gotowość do analizy. Jeziora danych przechowują wszystkie dane w swoim natywnym formacie, który jest mieszanką danych nieprzetworzonych i przetworzonych.
Ze względu na swoją prostotę, lekkość i łatwość przetwarzania JSON jest idealny do przechowywania nieustrukturyzowanych danych. Można go łatwo przekonwertować na różne formaty, w tym HDFS, Cassandra i MongoDB, z których wszystkie są obsługiwane przez tę aplikację. Ze względu na brak konieczności łączenia danych nasze rozwiązanie było proste w implementacji. Korzystając z funkcji json_archive, moglibyśmy utworzyć osobne pliki dla każdego obiektu JSON. Relacyjna baza danych może przechowywać nieustrukturyzowane dane na różne sposoby. Na początek relacyjne bazy danych to najskuteczniejszy sposób przechowywania i wysyłania zapytań do dużych ilości nieustrukturyzowanych danych. Umożliwiają wysoce wydajną kompresję dużych ilości danych, aw wielu przypadkach uwzględniane są języki zapytań, semantyka i inne mechanizmy obsługujące określone typy danych. Po drugie, struktura relacyjnej bazy danych ułatwia wyszukiwanie danych. Każdy rekord jest przechowywany jako pojedynczy obiekt JSON w relacyjnej bazie danych, a wszystkie jego dane są przechowywane jako jeden. Niezależnie od tego, czy szukasz konkretnego rekordu, czy pełnego zestawu rekordów, będziesz w stanie znaleźć potrzebne informacje. Trzecią zaletą relacyjnej bazy danych jest możliwość obsługi dużych ilości danych. Oprócz tego, że mogą przechowywać dziesiątki milionów rekordów, są w stanie obsługiwać złożone zapytania.
Dane nieustrukturyzowane: co, gdzie i jak je przechowywać
Pomimo faktu, że dane nieustrukturyzowane mogą być przechowywane w dowolnym formacie, zazwyczaj są one przechowywane w formacie tekstowym lub nietekstowym. Dane nieustrukturyzowane na ogół wymagają większej pojemności, ponieważ nie mieszczą się w predefiniowanej strukturze. Przechowywanie w chmurze zapewnia bezpieczeństwo i możliwość dostępu do danych z dowolnego miejsca, co czyni go doskonałą opcją dla danych nieustrukturyzowanych. Korzystanie z magazynu plików to dobry sposób na przechowywanie dużych ilości danych w celu ich uporządkowania. To oprogramowanie opiera się na przechowywaniu opartym na ścieżce, co oznacza, że do przechowywania danych używane są foldery i katalogi. Bardzo ważne jest, aby wiedzieć, gdzie dane znajdują się w systemie przechowywania plików, jeśli mają zostać znalezione.