
InfluxDB: baza danych szeregów czasowych
Opublikowany: 2022-11-18InfluxDB to baza danych szeregów czasowych napisana w Go i opracowana przez InfluxData. Został zaprojektowany tak, aby był skalowalny, z naciskiem na wysoką wydajność zapisu i szybkie wysyłanie zapytań. Jest to również open source, z wersją społecznościową i wersją korporacyjną. InfluxDB jest często używany w połączeniu z Grafana, narzędziem do wizualizacji danych typu open source. InfluxDB jest popularnym wyborem dla danych szeregów czasowych ze względu na wysoką wydajność zapisu i szybkie zapytania. Jest to również open source, co czyni go atrakcyjnym dla wielu programistów.
Aby przeprowadzić porównanie, skorzystaliśmy z prawdziwych recenzji użytkowników PeerSpot, aby porównać InfluxDB z Oracle NoSQL . W tym artykule porównamy funkcje, ceny, usługi i wsparcie, łatwość wdrożenia i zwrot z inwestycji baz danych NoSQL, aby dowiedzieć się, która z nich lepiej pasuje do Twojej firmy. Od 2012 roku z naszych badań skorzystało 648 701 profesjonalistów. InfluxDB, która jest ofertą opartą na chmurze, ma najlepszą cechę, jaką jest DB szeregów czasowych, szybkie zapytania zbiorcze w czasie i operacje na oknach. Występują pewne problemy z masowym interfejsem API dla InfluxDB, który jest niezgodny z danymi o dużej liczności. Skorzystaj z naszego bezpłatnego silnika rekomendacji, aby określić, która baza danych NoSQL najlepiej spełni Twoje potrzeby. InluxDB to darmowy program typu open source, który umożliwia programistom i firmom zarządzanie danymi szeregów czasowych.
InfluxDB umożliwia monitorowanie i analizowanie Internetu rzeczy (IoT), aplikacji, systemów, kontenerów i infrastruktury. Recenzent wymienił agregację danych i integrację z Grafaną jako najważniejsze funkcje. Baza danych Oracle NoSQL ma być bardzo dużym systemem baz danych o wysokiej dostępności. Dostępne są pełne operacje tworzenia, odczytu, aktualizacji i usuwania (CRUD), a także różnorodne gwarancje trwałości i spójności. Z czterema recenzjami InfluxDB zajmuje piąte miejsce na rynku baz danych NoSQL, wyprzedzając tylko Oracle No SQL, który zajmuje siódme miejsce z jednym. Jako najbardziej polecana baza danych ma bardzo prosty interfejs, jest lekka i wydajna.
InfluxDB nie jest relacyjną bazą danych, ponieważ nie zawiera żadnych kluczy podstawowych ani obcych, nie łączy pomiarów i tak dalej. tagi jako rozwiązanie: tagi są używane jako obejście w teorii, ale są odpowiednie tylko dla danych o niskiej liczności. Będziesz potrzebować dużej ilości pamięci, jeśli masz wiele rekordów z unikalnym znacznikiem ID.
Baza danych influxDB jest podobna do bazy danych SQL, ale istnieje kilka różnic. Ta baza danych jest specjalnie zaprojektowana do obsługi danych szeregów czasowych. Pomimo faktu, że relacyjne bazy danych mogą obsługiwać dane szeregów czasowych, nie są one zoptymalizowane pod kątem typowych obciążeń związanych z szeregami czasowymi.
InfluxDB Cloud to w pełni zarządzana, elastyczna platforma danych szeregów czasowych, która umożliwia użytkownikom szybkie rozpoczęcie i szybkie skalowanie w celu zaspokojenia ich potrzeb.
Baza danych szeregów czasowych (TSDB) stworzona przez InfluxData jest bazą danych typu open source. Dane szeregów czasowych, takie jak operacje, metryki aplikacji, dane z czujników Internetu rzeczy i analizy w czasie rzeczywistym, można przechowywać i pobierać za pomocą tej biblioteki w Go.
Czy Graphql to Sql czy Nosql?
W GraphQL używamy systemu typów do wydajnego zwracania danych w zapytaniach dynamicznych, które są językiem zapytań opartym na typach. SQL (strukturalny język zapytań) to starszy, szerzej stosowany standard projektowania, wdrażania i zarządzania strukturami danych w tabelarycznych i hierarchicznych bazach danych. Jeśli chcesz używać bazy danych NoSQL dla swojego API, wybierz GraphQL.
Zarówno bazy danych Type Mismatch, jak i GraphQL zostały stworzone przez Cochrane i Hermana Camarena. System typów można wprowadzić za pomocą GraphQL, a nie systemu NoSQL, ponieważ nadal możemy korzystać z zalet NoSQL. Struktura dokumentu w kolekcji GraphQL różni się nieznacznie w zależności od dokumentu, z pewnymi wyjątkami. Dzięki interfejsom API GraphQL programista może wybrać typy danych, które z grubsza odpowiadają typom backendów. Aby w pełni wykorzystać potencjał GraphQL, należy rozwiązać problem niezgodności typów. Jako język ma wiele zalet, które sprawiają, że problem niedopasowania jest mniej poważny. Korzystając z narzędzi takich jak JSON2SDL firmy StepZen, będziesz w stanie jeszcze bardziej zautomatyzować pracę.
Graphql jest niezależny od źródeł danych
Nie jest niezależne od żadnego źródła danych, dla którego zmiany są przechowywane lub pobierane. Dostęp do danych i manipulowanie nimi można uzyskać za pomocą dowolnych funkcji zwanych resolwerami.
Czy Influx Sql czy Nosql?
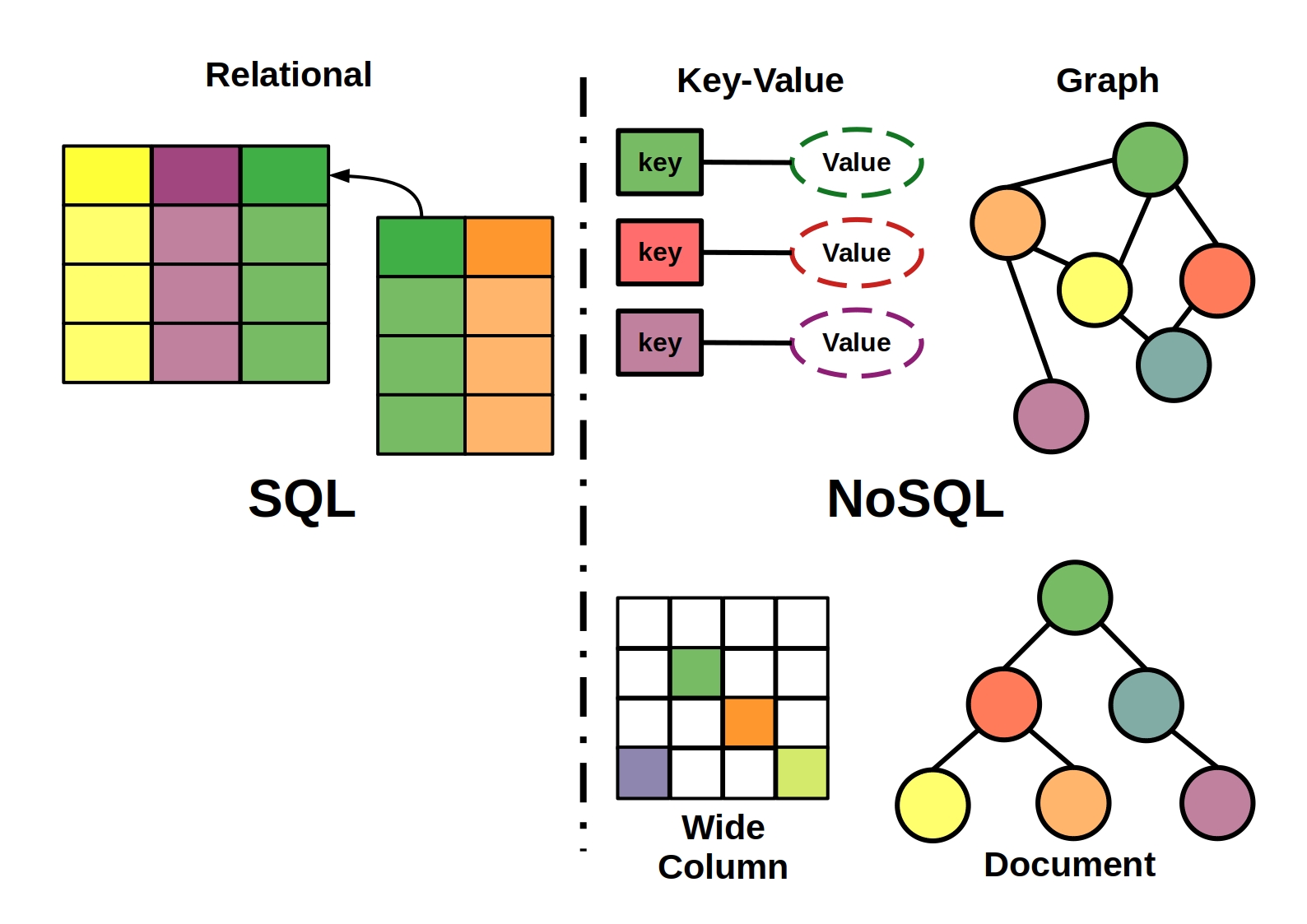
InfluxDB to relacyjna baza danych opracowana przez firmę InfluxData. to bezpłatna baza danych typu open source, która łączy duże zbiory danych , NoSQL i skalowalność. Charakteryzuje się wysoką dostępnością, dużą szybkością zapisu i jest dostępny na żądanie. InfluxDB, baza danych NoSQL, przechowuje zestaw punktów danych w czasie na podstawie serii punktów danych szeregów czasowych.
Jego celem jest wykorzystanie danych szeregów czasowych. Każda seria danych ma znacznik czasu, który identyfikuje pojedynczy punkt w jej obrębie. W tabeli bazy danych klucz podstawowy jest w tym przypadku zawsze ustawiany przez system, podobnie jak w bazach danych SQL. W większości przypadków dodanie nowego pola do pomiaru można wykonać po prostu przez wpisanie dla niego punktu. Bardziej szczegółowe opisy terminów influxDB wspomnianych w tej sekcji można znaleźć w naszym Glosariuszu pojęć. Używając InfluxDB 1.8 z Flux, możesz uzyskać podstawowe zrozumienie jego składni i pojęć. InfluxQL, język zapytań podobny do SQL, służy do interakcji z influxDB.
Środowisko SQL zostało zaprojektowane tak, aby ci, którzy przybyli z innych środowisk, czuli się w nim swobodnie. Program nie obsługuje zaawansowanych operacji, takich jak UNION, JOIN lub HAVING. Bieżący znacznik czasu serwera może być używany z czasem względnym i now() do obliczania czasu względnego. To zapytanie generuje listę danych o dostawach żywności. Baza danych CR-ud nie jest pełną bazą danych CRUD, ale raczej taką, która bardziej przypomina afluxDB. Został zaprojektowany w celu nadania priorytetu generowaniu i odczytywaniu danych, a nie aktualizowaniu i niszczeniu danych.
InfluxDB i MySQL to dwie najczęściej używane bazy danych szeregów czasowych. Oba narzędzia typu open source są proste w użyciu i można je dostosowywać. InfluxDB to doskonały wybór do analizy danych szeregów czasowych, ponieważ jest prostszy niż jakikolwiek inny. InfluxDB zapewnia szereg zalet w stosunku do MySQL. MySQL jest bardziej wydajny pod względem pamięci i szybszy w rozwoju niż InfluxDB. Drugim powodem, dla którego InfluxDB jest lepszym narzędziem niż MySQL, jest to, że jest bardziej stabilny. Ponadto InfluxDB zapewnia lepszą obsługę analizy szeregów czasowych niż MySQL. Do analizy szeregów czasowych dobrym wyborem jest InfluxDB, ponieważ jest prosty w użyciu, wydajny pod względem pamięci i niezawodny. Wiele firm, w tym Cisco, Power Home Remodeling, AT&T i Windstream Communications, już korzysta z InfluxDB.
Plusy i minusy baz danych Nosql i Sql
Bazy danych SQL zapewniają lepsze przetwarzanie transakcji wielowierszowych niż bazy danych NoSQL dla danych nieustrukturyzowanych, takich jak dokumenty i JSON. Bazy danych SQL są również używane w starszych systemach, które zostały napisane w formacie relacyjnym. Dane InfluxDB są przechowywane w grupie fragmentów. Dane są przechowywane w grupie Shard i przechowywane ze znacznikami czasu, które są zdefiniowane w historii jako czas trwania fragmentu i są uporządkowane według zasad przechowywania (RP). Ponadto, w zależności od RP, czas trwania grupy odłamków można dostosować. Możesz zmienić czas trwania grupy fragmentów, przechodząc do Zarządzania zasadami przechowywania. InfluxDB ma wiele różnic pod względem struktury i działania w porównaniu do baz danych SQL. Celem InfluxDB jest przechowywanie danych historycznych. Dane szeregów czasowych mogą być przechowywane w relacyjnych bazach danych, ale te bazy danych nie są zoptymalizowane pod kątem rutynowych obciążeń związanych z szeregami czasowymi. Klient InfluxDBQL umożliwia wykonywanie zapytań SQL o dane bazy danych.

Jakim typem bazy danych jest Influxdb?
InfluxDB to baza danych szeregów czasowych typu open source, bez zewnętrznych zależności. Jest to przydatne do monitorowania metryk, zdarzeń i analizowania danych analitycznych.
Baza danych InflluxDB open source jest napisana w formacie szeregów czasowych i jest utrzymywana przez InfluxData. Ta platforma, która jest przeznaczona do przechowywania i pobierania danych szeregów czasowych, służy do monitorowania i rejestrowania metryk wydajności i analiz. Architektura bazy danych InfluxDB składa się z dwóch baz danych: indeksu szeregów czasowych (TSI) dla danych szeregowych oraz odwróconego indeksu dla metadanych pomiarów, znaczników i pól. InfluxDB, baza danych typu open source, przechowuje dane w formacie kolumnowym. Ponadto kolumny w magazynie danych mogą obsługiwać typowe zapytania dotyczące szeregów czasowych, takie jak skanowanie w czasie. Time-Structured Merge Tree (TSM) to struktura organizacyjna używana przez InfluxDB. FileStore służy również do zarządzania dostępem do wszystkich plików TSM na komputerze.
InfluxDB to wydajne, szybkie i ekonomiczne rozwiązanie do przechowywania danych, które można wykorzystać do analizy i monitorowania szeregów czasowych. Wykorzystuje kolumnowe dostarczanie danych, w którym wszystkie dane są dostarczane jednocześnie, eliminując konieczność czytania całych wierszy w celu wyodrębnienia określonych wartości danych. W rezultacie InfluxDB jest użytecznym narzędziem dla danych, które są często obszerne i gęste, takich jak dane z czujników i systemu. InfluxDB, podobnie jak większość baz danych, zapewnia wysoką przepustowość odczytu i zapisu, a także funkcjonalność kolumnową dzięki wykorzystaniu fragmentacji i indeksacji. Jest to przydatna funkcja, ponieważ dane z czujników lub dzienników systemowych, które muszą być przechowywane i pobierane regularnie, mogą być przechowywane i pobierane. InfluxDB to wydajne i elastyczne rozwiązanie do przechowywania danych, które doskonale nadaje się do analizy i monitorowania szeregów czasowych. Format obejmuje tablicę kolumnową, która dostarcza dane po jednej kolumnie na raz, dwukrotnie większą przepustowość odczytu i zapisu oraz możliwości indeksowania, które umożliwiają szybsze wyszukiwanie i skalowanie. InfluxDB to doskonały wybór dla szerokiego zakresu wymagań w zakresie przechowywania, w tym obszernych danych szeregów czasowych, jak również tych wymagających szybkiego i wydajnego rozwiązania do przechowywania danych.
Influxdb kontra Mongodb
Wyniki InfluxDB pokazały, że jest on znacznie lepszy od MongoDB, jeśli chodzi o pozyskiwanie danych i wydajność pamięci dyskowej. Pod względem pozyskiwania danych InfluxDB czterokrotnie przewyższa MongoDB. InfluxDB, w przeciwieństwie do MongoDB, oferował 20-krotną kompresję.
Po ponad 4 latach korzystania z couchbase przeszliśmy na MongoDB i nie moglibyśmy być szczęśliwsi. Otrzymaliśmy wsparcie dla przedsiębiorstw, ale doświadczenie było okropne, mimo że byliśmy wymienieni jako partner Couchbase. Aby go poprawnie uruchomić, będziesz potrzebować co najmniej sześciu serwerów przy ich minimalnych wymaganiach. Do produkcji potrzebnych będzie sześć serwerów. Mniejsza instancja Memcached jest dostarczana z instancją Couchbase w celu obsługi pamięci podręcznej w pamięci. Ten program ma 8 GB pamięci RAM i może obsłużyć 5000 dokumentów. Nie jestem tutaj żartobliwy. W instancji Couchbase było mniej niż 5000 dokumentów, mniej niż 20 indeksów i ponad 8 GB pamięci RAM.
Baza danych InfluxDB jest bardzo dobrym wyborem dla danych szeregów czasowych. W rezultacie jest to doskonały wybór do przechowywania wrażliwych danych, ponieważ pozwala programiście na pełną kontrolę nad bezpieczeństwem danych. Ponadto wsparcie społeczności InfluxDB jest doskonałe, co ułatwia kontakt z organizacją w razie potrzeby.
Dlaczego Orientdb jest najlepszą bazą danych wykresów
OrientDB, w przeciwieństwie do MongoDB, zapewnia szereg zalet.
Ponieważ OrientDB jest wolny od schematów, możesz z łatwością modelować swój model danych.
Ponieważ OrientDB jest zgodny z ACID, Twoje dane będą spójne i trwałe.
Wydajność OrientDB jest lepsza niż MongoDB, co czyni go doskonałym wyborem do przechowywania danych szeregów czasowych.
OrientDB może być dla Ciebie najlepszą opcją, jeśli szukasz bazy danych wykresów. Kiedy opanujesz True Graph Engine, nie będziesz musiał zajmować się żadnymi innymi typami danych ani wdrażać żadnych innych systemów.
Plusy Influxdb
Istnieje wiele powodów, dla których warto pokochać InfluxDB. Oto tylko kilka: – Po pierwsze, InfluxDB jest niezwykle łatwy w instalacji i uruchomieniu. W rzeczywistości instancję można uruchomić w ciągu zaledwie kilku minut przy bardzo niewielkiej konfiguracji. – Po drugie, InfluxDB ma doskonałą wydajność zapisu. Bez problemu radzi sobie z milionami punktów danych na sekundę. – Po trzecie, InfluxDB ma bardzo elastyczny model danych, który można łatwo dostosować do własnych potrzeb. – Po czwarte, InfluxDB ma bogaty język zapytań, który obsługuje wiele różnych typów zapytań. – Po piąte, InfluxDB dobrze integruje się z wieloma różnymi typami źródeł danych i aplikacji. Ogólnie rzecz biorąc, InfluxDB to doskonały wybór do danych szeregów czasowych. Jest łatwy w użyciu, ma doskonałą wydajność i jest bardzo elastyczny.
InflluxDB to baza danych szeregów czasowych. Aby zmaksymalizować wydajność w tym przypadku użycia, konieczne jest dokonanie kompromisów, przede wszystkim w zakresie funkcjonalności. Dane z bardzo aktualnymi znacznikami czasu stanowią zdecydowaną większość zapisów i są dodawane w porządku rosnącym. Dane, o których mowa, są rzadko aktualizowane, a sporne aktualizacje są rzadkie. Projektantom trudno było zwiększyć wydajność, zajmując się danymi efemerycznymi i nieciągłymi. Baza danych z dużą liczbą odczytów i zapisów musi być wystarczająco duża, aby ją obsłużyć.
Najpotężniejsza baza danych szeregów czasowych to usługa, która łączy chmurę InfluxDB i bazę danych szeregów czasowych. To bezpłatne narzędzie jest proste w użyciu, szybkie, bezserwerowe i elastyczne oraz obsługuje popularne narzędzia, takie jak Docker i Prometheus. Ze względu na popularność open source InfluxDB, firma stała się jedną z odnoszących największe sukcesy firm w branży. Rok przyniósł dramatyczny wzrost zasięgu InfluxData, z ponad 450 000 aktywnych instancji InfluxDB działających na całym świecie. Analitycy danych i inżynierowie, którzy potrzebują wydajnej bazy danych szeregów czasowych, która jest zarówno prosta, jak i szybka do wdrożenia, są idealnymi kandydatami do InfluxDB Cloud.